Table of contents
Residual block (residual block) and shortcut connections (shortcut connection)
bottleneck block - bottleneck block
DenseBlock+Transitio structure
Main Contributions and Inspiration
ALexNet(2012
Research Background
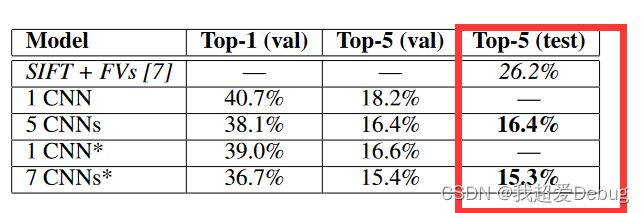
This paper proposes to use a deep convolutional neural network for image classification. This deep convolutional neural network (AlexNet) participated in the ImageNet large-scale visual recognition challenge held on September 30, 2012, reaching a minimum of 15.3% Top-5 The error rate is 10.8 percentage points lower than the second place (as shown in Figure 1).
The left panel of Figure 2 is the eight ILSVRC-2010 test images and the five labels that our model considers most likely. The correct label is written below each image, and the probability assigned to the correct label is also shown with a red bar (if it happens to be in the top 5). The image on the right can be understood as identifying images with similar feature vectors and grouping them together

ideas and main process
network model
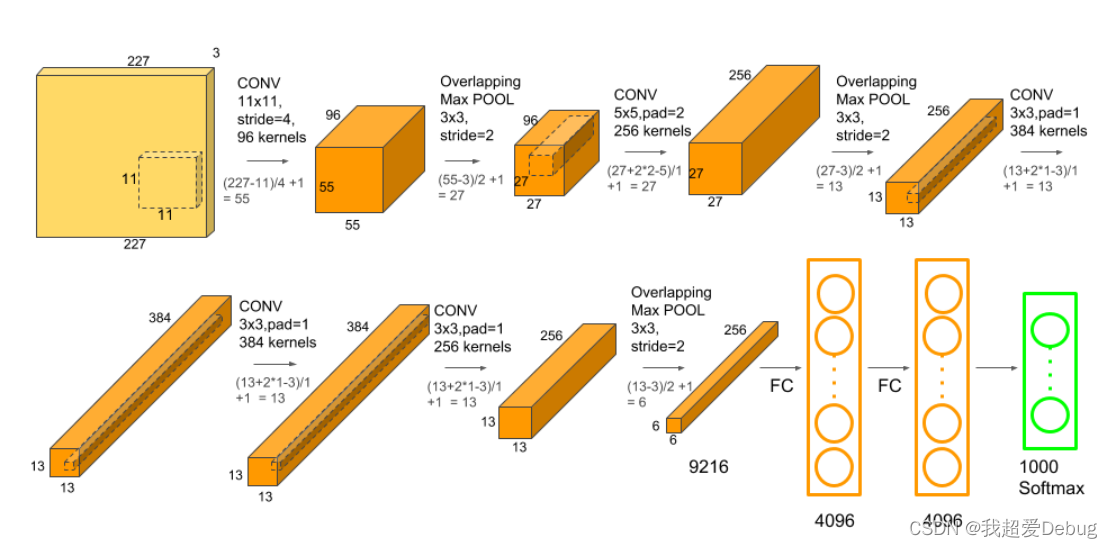
- The network structure is divided into two parts, upper and lower parts, and trained on two GPUs
- A total of eight layers, the first five layers are convolutional layers, the last three layers are fully connected layers, and the last is the 1000-way classification activation function softmax (for multi-class classification
- Here you can see that only the third layer of the convolutional layer has done a fusion in the channel dimension, that is, both the upper and lower GPUs of the previous layer are used as the input of this layer
- A fully connected layer is connected to all neurons in the previous layer
Here we can see that our input image has changed from a 227*227 image to a 4096 semantic vector. This is a process in which spatial information is compressed and semantic information is slowly increased.
data augmentation
1. This is achieved by randomly extracting 224×224 images from the 256×256 images, and training our network on these extracted images. This will increase the size of our training set by a factor of 2048. But there is a problem that cannot be said to be 2048 times, because many pictures are similar
2. Using PCA to make some changes to the channel of the RGB image, the image has undergone some changes, thereby expanding the data set
main contribution
1. Use the ReLU activation function to speed up convergence
2. Use GPU parallelism to accelerate training. It also lays the foundation for the subsequent group convolution theory
3. Proposed Local Response Normalization (LRN) to increase the generalization characteristics (although it was proved invalid by later generations)
4. Use overlapping pooling
(Overlapping Pooling) Prevent overfitting and propose Dropout
5. Data enhancement and other means to prevent overfitting
ResNet(2015
Research Background
Before ResNet was proposed, all neural networks were composed of convolutional layers and pooling layers. Theoretically, as the number of convolutional layers and pooling layers increases, the more complete the image feature information that the neural network can obtain, the better the learning effect. But in actual experiments, the effect was the opposite. There are two reasons for this
- Vanishing Gradients and Exploding Gradients
- Gradient disappears: If the error gradient of each layer is less than 1, the deeper the network is, the closer the gradient is to 0 during backpropagation
- Gradient explosion: If the error gradient of each layer is greater than 1, the deeper the network is, the larger the gradient will be during backpropagation
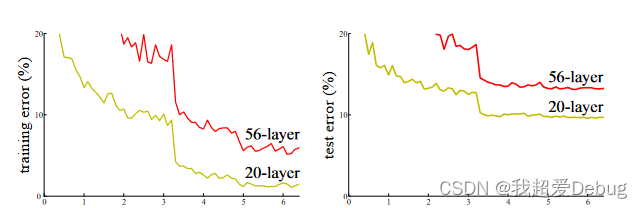
- degradation problem
- As the number of layers increases, the prediction effect becomes worse and worse.
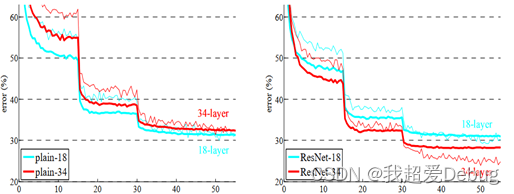
In order to effectively improve the degradation problem, He Kaiming and others proposed the ResNet model. The effect is shown in the figure below. With the increase of the number of neural network layers, the effectiveness does not decrease, and the ResNet model won the first place in the classification task in the ImageNet competition that year. The goal The first place in detection; won the first place in object detection and image segmentation in the COCO dataset.
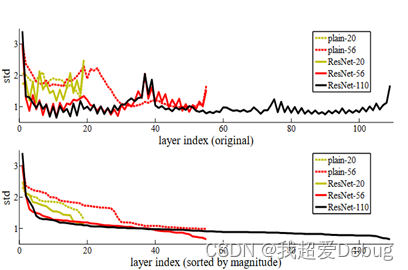
ideas and main process
Residual block (residual block) and shortcut connections (shortcut connection):
residual:
Residual value F(x)=solved mapping value H(x)-estimated value x
That is, from the traditional calculation of the mapping value of each layer, it is converted to interpolation between the mapping value and the estimated value, that is, the residual value.
Advantages of the residual structure?
1. The residual structure converges towards the direction of identity mapping
In a deep network we train, some redundant layers (even counterproductive) cannot be avoided. What we expect is that the influence of these layers on the network is approximately zero, and the input results will not change, that is, this Sometimes we hope that the input x and output H(x) passing through these layers are approximate, which is called identity transformation. At this time, F(x)=0. At this time, the network structure will follow the direction of identity mapping (identity mapping) To converge, alleviate the degradation problem to a certain extent
2. The mapping after introducing the residual is more sensitive to the change of the output
for example:
Before introducing residuals, input x = 6 function to be fitted H ( x ) = 6.1
After introducing the residual, our learning goal is the residual value F(x) of 0.1
When the function value of the next layer is H'(x)=6.2, compared with the original method, H(x) is changed from 6.1 to 6.2, which is an increase of 1.6%.
But for ResNet, the value of F(x) changed from 0.1 to 0.2, increasing to 100%
Obviously, the change of the output in the residual network has a greater impact on the adjustment of the weight, which means that the gradient value of backpropagation is larger and the training is easier.
shortcut connections shortcut connections:
The biggest difference between ordinary convolutional blocks and deep residual networks is that
The deep residual network has many bypass branches that directly connect the input to the subsequent layer, so that the latter layer can directly learn the residual. These branches are called shortcuts.
When the traditional convolutional layer or fully connected layer transmits information, there will be more or less problems such as information loss and loss. ResNet solves this problem to some extent, by directly bypassing the input information to the output to protect the integrity of the information, the entire network only needs to learn the part of the difference between the input and output, simplifying the learning objectives and difficulty.
bottleneck block - bottleneck module:
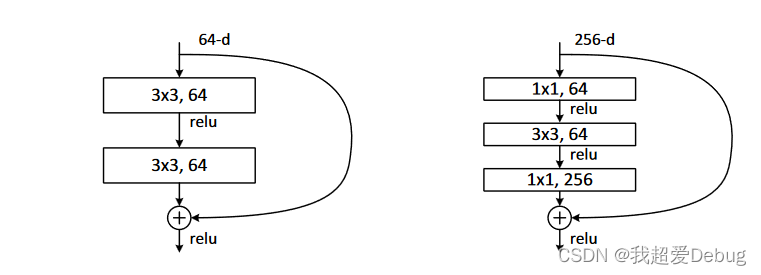
These two structures are for ResNet34 (left picture) and ResNet50/101/152 (right picture), and the whole structure is generally called a "building block".
The purpose of "bottleneck design" is clear at a glance. It is to reduce the number of parameters. The first 1x1 convolution reduces the 256-dimensional channel to 64 dimensions, and then restores it through 1x1 convolution at the end. The overall number of parameters used: 1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632, if you don't use the bottleneck, it will be two 3x3x256 convolutions, the number of parameters: 3x3x256x256x2 = 1179648, a difference of 16.94 times
Main contribution points:
It not only utilizes the deep neural network but also avoids the problems of gradient dissipation and degradation.
Resnet looks very deep but the number of network layers that actually work is not very deep. Most of the network layers are preventing model degradation and the error is too large. Moreover, the residual can not completely solve the problem of gradient disappearance or explosion, network degradation, it can only alleviate
Denset(2017
Research Background
Recent studies have shown that the shorter the connection between the layer near the input and the layer near the output, the convolutional neural network can be made deeper, with higher accuracy and more efficient training. The Dense network is proposed on this basis to adopt a dense connection method between layers.
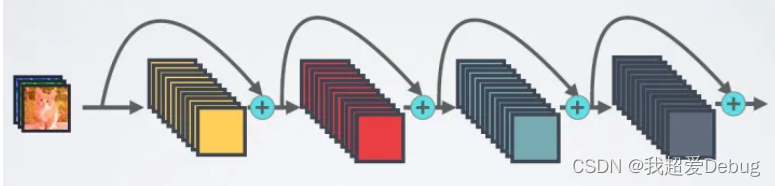
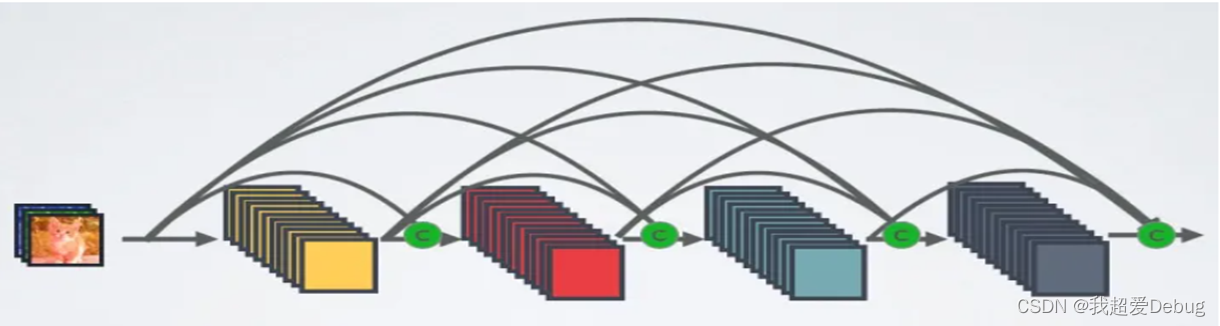
For an L-layer network, DenseNet contains a total of L (L+1)/2 connections, which is a dense connection compared to ResNet
DenseNet directly concats feature maps from different layers, which can realize feature reuse and improve efficiency. This is the main difference between DenseNet and ResNet
ideas and main process
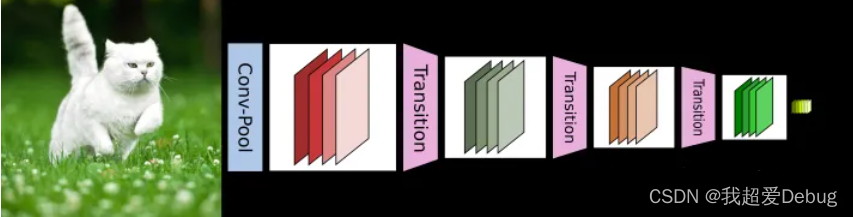
DenseBlock+Transitio structure
The CNN network generally needs to reduce the size of the feature map through Pooling or Conv with stride>1
However, the dense connection method of DenseNet requires the size of the feature map to be consistent. In order to solve this problem, the structure of DenseBlock+Transition is used in the DenseNet network, where DenseBlock is a module containing many layers, and the size of the feature map of each layer is the same. A dense connection is used between them. The Transition module connects two adjacent DenseBlocks, and reduces the size of the feature map through Pooling. Figure 4 shows the network structure of DenseNet, which contains a total of 4 DenseBlocks, and each DenseBlock is connected through Transition
Main Contributions and Inspiration
DenseNet has the following compelling advantages: alleviating the problem of gradient disappearance, enhancing feature propagation, encouraging feature reuse, and greatly reducing the amount of parameters.
1. Fewer parameters compared with traditional CNNs because it does not need to learn redundant features
2. Improve the information flow and gradient in the entire network, making training easier
3. Dense connection has a regularization effect, which can reduce the overfitting phenomenon of tasks with small training set size
Summary and reflection
ALexNet is the foundation of modern deep CNN and the first deep convolutional neural network. The ResNet model is proposed to solve the degradation problem of the deep neural network, and the residual idea itself also simplifies the learning goal of the model to a certain extent, making model training easier. The DenseNet network is based on ResNet, the idea of dense connection between layers is proposed, and because of the realization and enhancement of feature reuse, the number of parameters is reduced to a certain extent