foreword
Recently, a super-resolution model is needed, and Real-ESRGAN is ready to be used after research. Hereby record the paper reading and actual combat process.
paper reading
Paper address: Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
Github: https://github.com/xinntao/Real-ESRGAN
Reference Video: https://www.bilibili.com/video/BV14541117y6
Main contributions:
- A high-order degradation process (high-order degradation process) is proposed to simulate the actual degradation, and the sinc filter is used to add Ringing artifacts (ringing artifacts, the feeling of surrounding shock waves) and Overshoot artifacts (overshooting artifacts) to the training pictures , such as the white border) to construct the training set
- Use U-net instead of VGG as the discriminator of GAN to improve discriminator ability and stabilize training dynamics
- Real-ESRGAN has better performance and better results
Effect comparison:

Dataset Construction:
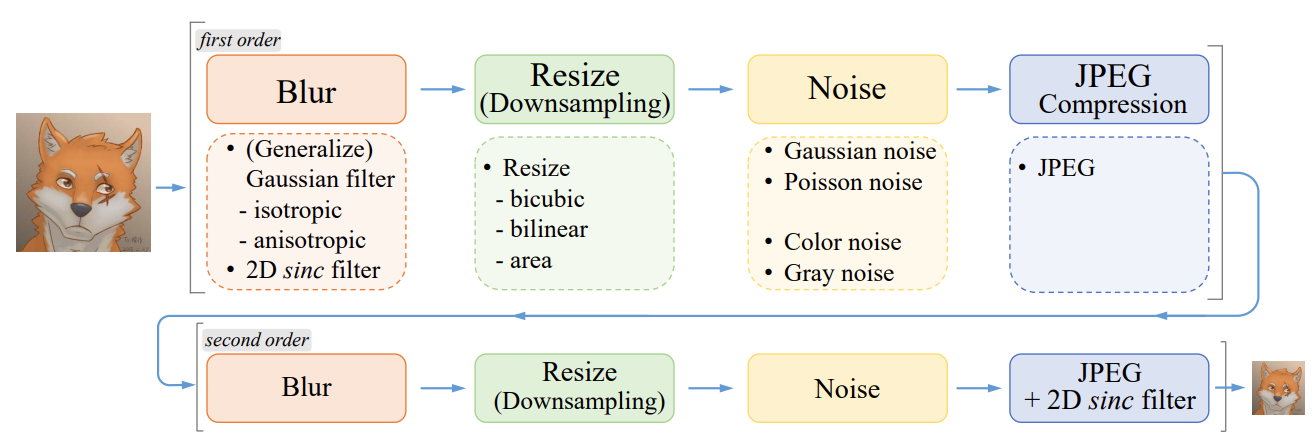
Second-Order Degenerate. The two stages go through blurring, downsampling, adding noise, and JPEG compression respectively. The sinc filter is used to add artifacts.
| Artifact type | example |
|---|---|
| ringing artifact |  |
| overshoot artifact |  |
Real-ESRGAN model structure:
- Generator : The structure is the same as ESRGAN, but he made a Pixel Unshuffle to reduce the length and width of the image and increase the channel size. The residual network sent to an RRDB is finally up-sampled to get the output.
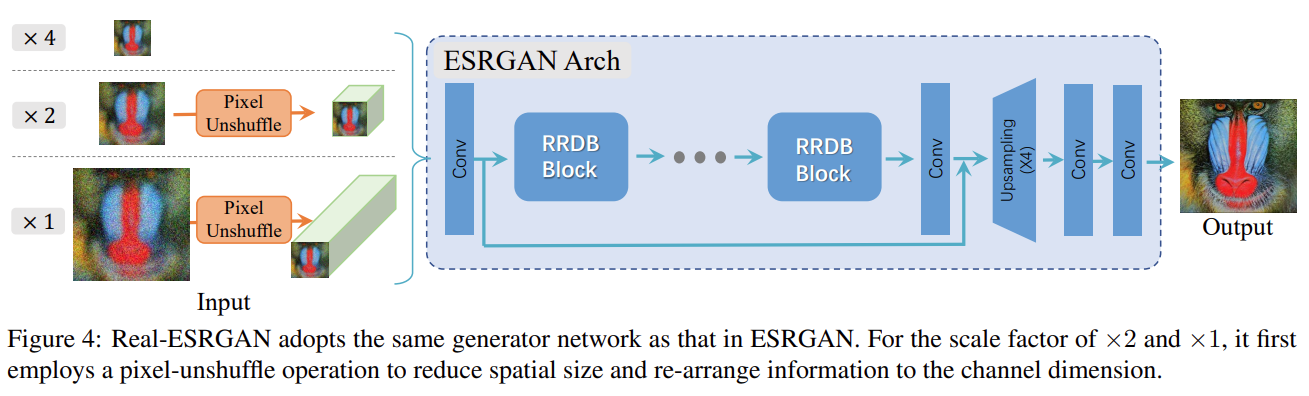
- Discriminator : The U-Net used (there is a connection between the downsampling and upsampling features, which can learn local texture information), unlike the original GAN discriminator output 0/1 (that is, whether the global is qualified), his output is and The size of the original image is the same, and the value of each pixel measures the authenticity feedback (that is, whether each part is qualified). In addition, using spectral norm (spectral normalization) can improve training stability and reduce artifacts.

Two-stage model training:
first, use L1 loss to train a small network (PSNR-oriented model) Real-ESRNet; then, use it to initialize the weight of the Generator, and use the combination of L1 loss, perceptual loss, and GAN loss to train the final model.
In addition, ground-truth is sharpened and a Real-ESRGAN+ is trained, which can improve the sharpness of image generation, but will not increase artifacts.
combat record
git clone https://github.com/xinntao/Real-ESRGAN.git
cd Real-ESRGAN
# Install basicsr - https://github.com/xinntao/BasicSR
# We use BasicSR for both training and inference
pip install basicsr
# facexlib and gfpgan are for face enhancement
pip install facexlib
pip install gfpgan
pip install -r requirements.txt
python setup.py develop
Requires the RealESRGANer class of the realesrgan module. Take the 4 times super score as an example:
import os
import cv2
import torch
import numpy as np
from PIL import Image
from basicsr.archs.rrdbnet_arch import RRDBNet
from realesrgan import RealESRGANer
ckpt_path = "./checkpoints/real-esrgan"
model_path = os.path.join(ckpt_path, "RealESRGAN_x4plus.pth")
model = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=23, num_grow_ch=32, scale=4)
netscale = 4
upsampler = RealESRGANer(
scale=netscale,
model_path=self.model_path,
dni_weight=self.dni_weight,
model=self.model,
tile=0, # Tile size, 0 for no tile during testing
tile_pad=10, # Tile padding
pre_pad=0, # Pre padding size at each border
half=not fp16,
device=device)
def enhance(image, width, height):
"""
image: PIL Image Obj
输出: PIL Image Obj
"""
try:
image_cv2 = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
output, _ = upsampler.enhance(image_cv2, outscale=self.outscale) # _ is RGB/RGBA
image_pil = Image.fromarray(cv2.cvtColor(output, cv2.COLOR_BGR2RGB)).resize((width, height)).convert('RGB')
# print(output, _, image_pil)
return image_pil
except Exception as e:
print("enhance Exception: ", e)
finally:
torch.cuda.empty_cache()
Test (before superscore):

After overscoring:
