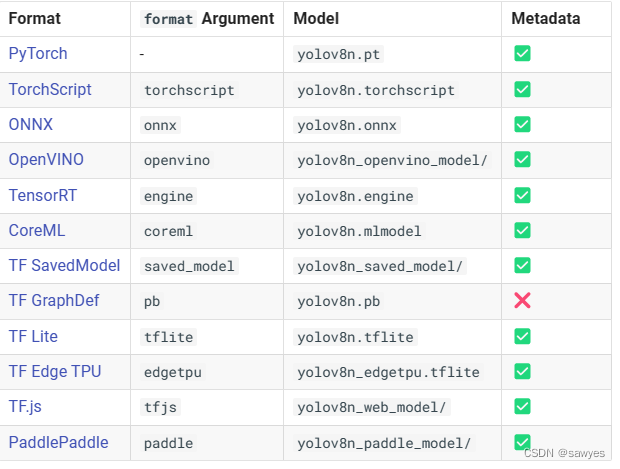
Article directory
material
- Docs: https://docs.ultralytics.com
- Community: https://community.ultralytics.com
- GitHub: https://github.com/ultralytics/ultralytics
- COCO dataset https://cocodataset.org/#download
- Kaggle cloud platform dataset
Model introduction (or weights)
Install
install ultralytics (yolo)
https://docs.ultralytics.com/quickstart/#install
方式一:https://docs.ultralytics.com/quickstart/
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e .
方式二:
pip install ultralytics
yolo -v
8.0.105
Torch
torch test, False means the driver is not good, enter the python command line
# cuda支持检查
import torch
print(torch.cuda.is_available())
https://pytorch.org/get-started/previous-versions/
Execute a similar command to install a versioncuXXX
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
test command
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg
Downloading https:\github.com\ultralytics\assets\releases\download\v0.0.0\yolov8n.pt to yolov8n.pt...
100%|█████████████████████████████████████████████████████████████████████████████| 6.23M/6.23M [00:01<00:00, 4.59MB/s]
Ultralytics YOLOv8.0.105 Python-3.10.11 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
Speed: 18.1ms preprocess, 191.7ms inference, 8.0ms postprocess per image at shape (1, 3, 640, 640)
Downloading https:\ultralytics.com\images\bus.jpg to bus.jpg...
100%|███████████████████████████████████████████████████████████████████████████████| 476k/476k [00:00<00:00, 2.36MB/s]
image 1/1 G:\ultralytics\bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 191.7ms
Speed: 18.1ms preprocess, 191.7ms inference, 8.0ms postprocess per image at shape (1, 3, 640, 640)
Results saved to runs\detect\predict
analyze
- Version Information
Ultralytics YOLOv8.0.105Python-3.10.11torch-2.0.0+cu118 - If the model
yolov8n.ptdoes not exist, it will be downloaded, and the predicted image bus.jpg - The default task is
detect, target detection - Graphics Computing, NVIDIA GeForce RTX 3090
cliForecast information includes4 persons, 1 bus- The forecast results are automatically saved to the directory
runs\detect\predict, and multiple productions will be createdpredict1,predict2…
Comparing the performance of GPU and CPU, the gap is still obvious

CLI command line
CLI getting started documentation: https://docs.ultralytics.com/usage/cli/
yolo TASK MODE ARGS
Where TASK (optional) is one of [detect, segment, classify]
MODE (required) is one of [train, val, predict, export, track]
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
Experience yolov8 through the COCO128 dataset
Label
The training and reasoning process will print out the recognized content, 0-79 (similar to person), what are they? ? How come, you can see this file, https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco128.yaml
All are based on the classification results of Microsoft coco dataset pre-training
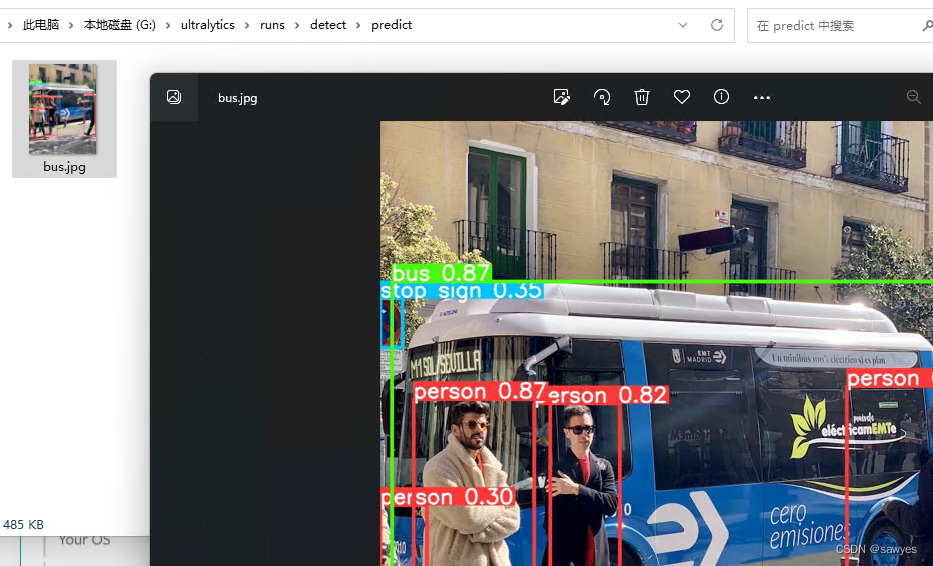
predict
Use commands directly to predict (predict)
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
Ultralytics YOLOv8.0.105 Python-3.10.11 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients
Found https:\ultralytics.com\images\bus.jpg locally at bus.jpg
image 1/1 G:\ultralytics\bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 185.4ms
Speed: 5.7ms preprocess, 185.4ms inference, 7.0ms postprocess per image at shape (1, 3, 640, 640)
Results saved to runs\detect\predict2
The image output is as follows

segment
Note that the usage model isyolov8n-seg
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg'
Implementation process
(yolo) G:\ultralytics>yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg'
Downloading https:\github.com\ultralytics\assets\releases\download\v0.0.0\yolov8n-seg.pt to yolov8n-seg.pt...
100%|█████████████████████████████████████████████████████████████████████████████| 6.73M/6.73M [00:01<00:00, 6.63MB/s]
Ultralytics YOLOv8.0.105 Python-3.10.11 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
YOLOv8n-seg summary (fused): 195 layers, 3404320 parameters, 0 gradients
Found https:\ultralytics.com\images\bus.jpg locally at bus.jpg
image 1/1 G:\ultralytics\bus.jpg: 640x480 4 persons, 1 bus, 1 skateboard, 245.6ms
Speed: 5.2ms preprocess, 245.6ms inference, 8.1ms postprocess per image at shape (1, 3, 640, 640)
Results saved to runs\segment\predict
The image output is as follows

Download the COCO 2017 dataset
# Download COCO val
import torch
torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)
!unzip -q tmp.zip -d datasets && rm tmp.zip # unzip
Val
Using the COCO128validation yolov8n.ptmodel, the data set coco2017valis not available in this step
# Validate YOLOv8n on COCO128 val
yolo val model=yolov8n.pt data=coco128.yaml
Implementation process
(yolo) G:\ultralytics>yolo val model=yolov8n.pt data=coco128.yaml
Ultralytics YOLOv8.0.105 Python-3.10.11 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients
Dataset 'coco128.yaml' images not found , missing paths ['G:\\ultralytics\\datasets\\coco128\\images\\train2017']
Downloading https:\ultralytics.com\assets\coco128.zip to G:\ultralytics\datasets\coco128.zip...
Download failure, retrying 1/3 https://ultralytics.com/assets/coco128.zip...
################################################################################################################ 100.0%-################################################################################################################ 100.0%
Unzipping G:\ultralytics\datasets\coco128.zip to G:\ultralytics\datasets...
Dataset download success (21.7s), saved to G:\ultralytics\datasets
val: Scanning G:\ultralytics\datasets\coco128\labels\train2017... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████
val: New cache created: G:\ultralytics\datasets\coco128\labels\train2017.cache
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 8/8 [00:06<0
all 128 929 0.64 0.537 0.605 0.446
person 128 254 0.796 0.677 0.764 0.537
bicycle 128 6 0.513 0.333 0.315 0.263
car 128 46 0.814 0.217 0.273 0.168
....截断
toothbrush 128 5 0.745 0.6 0.638 0.374
Speed: 0.8ms preprocess, 9.0ms inference, 0.0ms loss, 2.4ms postprocess per image
coco128.yamlIt will be downloaded automatically, 128 means thatdatasets\coco128\images\train2017there are 128 pictures
View verification results
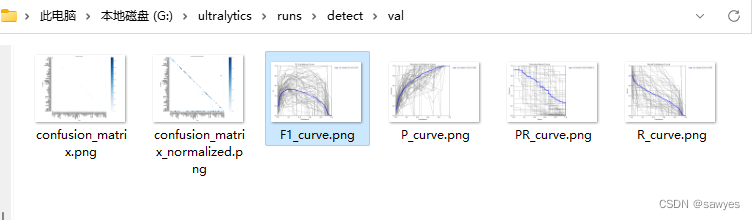
Train
Training YOLO based on the dataset coco128(automatically downloaded earlier)
yolo train model=yolov8n.pt data=coco128.yaml epochs=3 imgsz=640
process record
Ultralytics YOLOv8.0.105 Python-3.10.11 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
yolo\engine\trainer: task=detect, mode=train, model=yolov8n.pt, data=coco128.yaml, epochs=3, patience=50, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=None, exist_ok=False, pretrained=False, optimizer=SGD, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=0, resume=False, amp=True, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, show=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, vid_stride=1, line_width=None, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, boxes=True, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0, cfg=None, v5loader=False, tracker=botsort.yaml, save_dir=runs\detect\train
Downloading https:\ultralytics.com\assets\Arial.ttf to C:\Users\Administrator\AppData\Roaming\Ultralytics\Arial.ttf...
100%|███████████████████████████████████████████████████████████████████████████████| 755k/755k [00:00<00:00, 3.64MB/s]
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
16 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
19 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 1 493056 ultralytics.nn.modules.block.C2f [384, 256, 1]
22 [15, 18, 21] 1 897664 ultralytics.nn.modules.head.Detect [80, [64, 128, 256]]
Model summary: 225 layers, 3157200 parameters, 3157184 gradients
Transferred 355/355 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias
train: Scanning G:\ultralytics\datasets\coco128\labels\train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██
val: Scanning G:\ultralytics\datasets\coco128\labels\train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|████
Plotting labels to runs\detect\train\labels.jpg...
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs\detect\train
Starting training for 3 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/3 2.51G 1.182 1.409 1.214 218 640: 100%|██████████| 8/8 [00:04<00:00, 1.89
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:02<0
all 128 929 0.635 0.564 0.626 0.463
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/3 2.5G 1.137 1.319 1.239 205 640: 100%|██████████| 8/8 [00:01<00:00, 7.10
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:01<0
all 128 929 0.67 0.548 0.635 0.472
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/3 2.49G 1.172 1.293 1.219 161 640: 100%|██████████| 8/8 [00:01<00:00, 7.51
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:02<0
all 128 929 0.663 0.59 0.663 0.496
3 epochs completed in 0.006 hours.
Optimizer stripped from runs\detect\train\weights\last.pt, 6.5MB
Optimizer stripped from runs\detect\train\weights\best.pt, 6.5MB
Validating runs\detect\train\weights\best.pt...
Ultralytics YOLOv8.0.105 Python-3.10.11 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
Model summary (fused): 168 layers, 3151904 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:02<0
all 128 929 0.664 0.589 0.663 0.496
person 128 254 0.814 0.685 0.767 0.552
bicycle 128 6 0.658 0.325 0.327 0.25
car 128 46 0.782 0.217 0.329 0.194
motorcycle 128 5 0.685 0.879 0.938 0.747
airplane 128 6 0.774 0.833 0.903 0.673
...
toothbrush 128 5 1 0.574 0.786 0.485
Speed: 1.0ms preprocess, 2.9ms inference, 0.0ms loss, 1.8ms postprocess per image
Results saved to runs\detect\train
The training result contains data such as weights
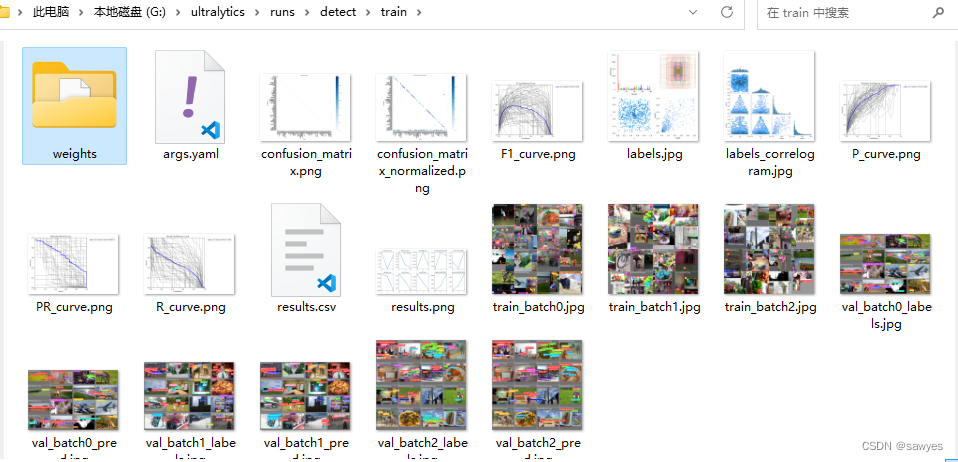
Single image training results
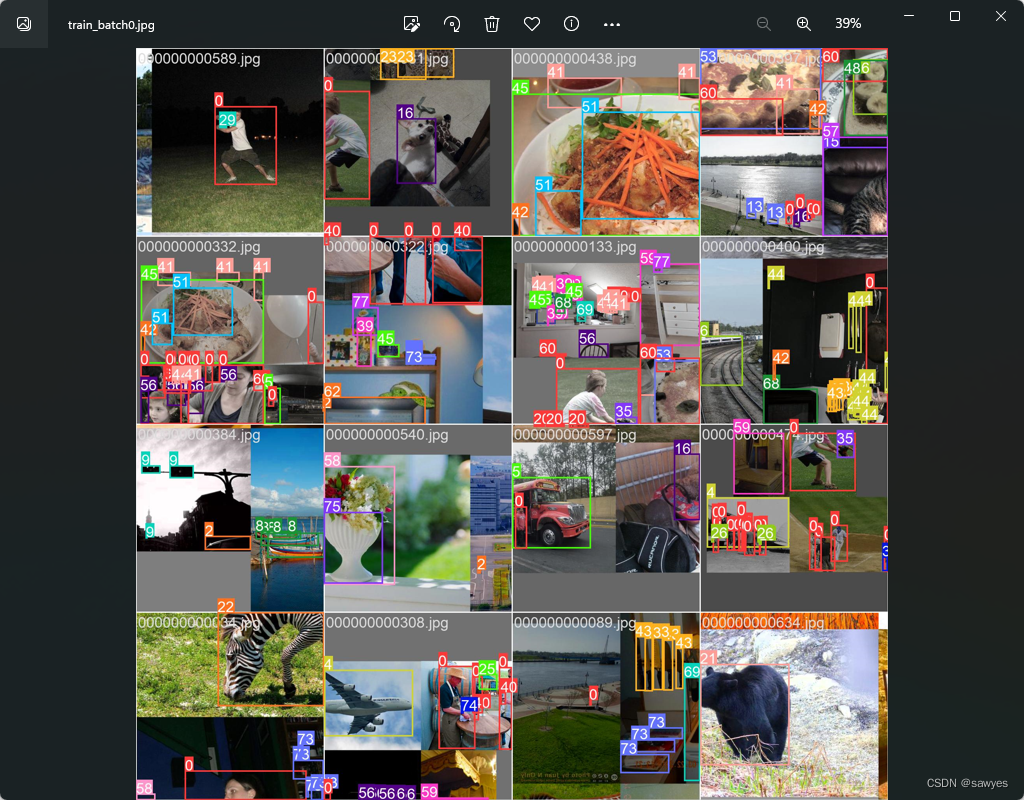
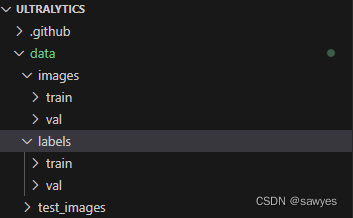
custom data set
Reference docs\yolov5\tutorials\train_custom_data.md, online documentation , also applies to v8
mkdir -p data/{images,labels}/{train,val}
mkdir -p data/test_images
imagesThe picture data to be trained are all placed here,trainwhich is the data to be trained andvalthe data to be verifiedlabelsAnnotated data is placed heretest_imagesTest Data
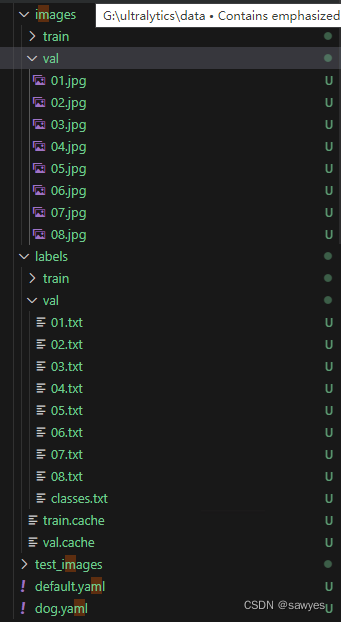
New dog.yaml, nc is the total number of categories of the object, it will be verified with names, and cannot be wrongly written. names is the name of the species, here I used huskies and labradors
train: G:\ultralytics\data\images\train
val: G:\ultralytics\data\images\val
# number of classes
nc: 2
# class names
names: ['hashiqi','labuladuo']
Copy ultralytics\yolo\cfg\default.yamlto datadirectory , or yolo copy-cfggenerate with
- detect target detection, train training
- model yolov8n yolo version 8 naco model (small, high performance)
- data data/dog.yaml The object defined above has training and labeling detection target image paths, verification image paths, classification objects and other information
- epochs training pictures start at least 1k, generally 500 iterations are almost the same
task: detect # YOLO task, i.e. detect, segment, classify, pose
mode: train # YOLO mode, i.e. train, val, predict, export, track, benchmark
# Train settings -------------------------------------------------------------------------------------------------------
model: yolov8n.pt # path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: data/dog.yaml # path to data file, i.e. coco128.yaml
epochs: 500 # number of epochs to train for
patience: 400 # epochs to wait for no observable improvement for early stopping of training
batch: 128 # number of images per batch (-1 for AutoBatch)
imgsz: 1024 # size of input images as integer or w,h
save_period: 100 # Save checkpoint every x epochs (disabled if < 1) 一般按迭代的20%保存一次完全够了
resume: True # resume training from last checkpoint
...
label
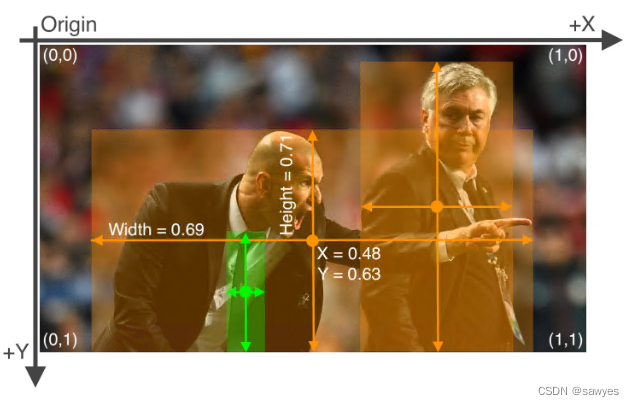
- one object per line
- The format of each line is
class x_center y_center width height - The file is
*.txt(labelimg has yolo format) /images/Mark the file path convention, replace the picture/labels/, the txt file name is equal to the picture name, as shown below
Understand the parameters of the label, as shown in the figure below
Labeling software labelimg
https://github.com/heartexlabs/labelImg/releases, directly download the windows version
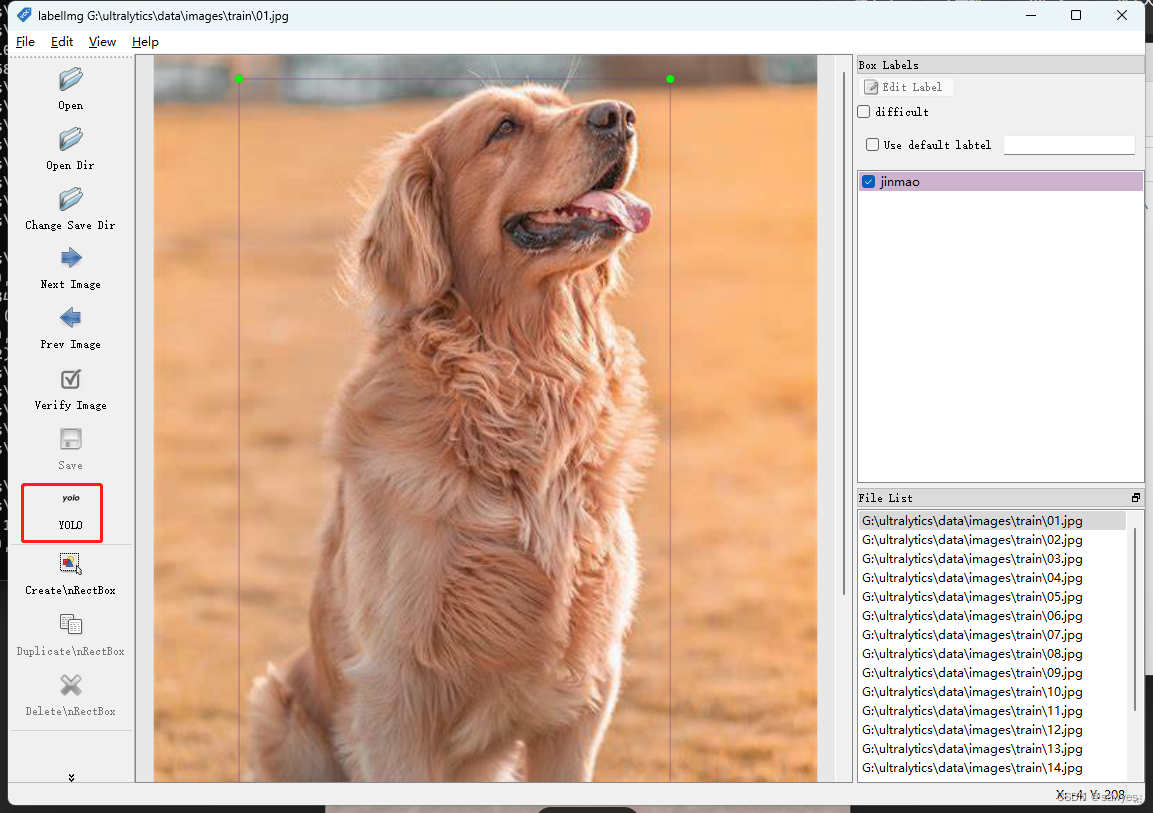
Use labelimg to label yolo image data
Training, here I have only 24 pictures, so I increased the epoch to 50000 (normally, it starts with 1000, but the labeling is really troublesome), after training, you will get an optimal model file such asruns\detect\train7\weights\best.pt,
yolo cfg=data/default.yaml
The training process log, it took about 4 hours, and the actual starting mechanism stopped training at about 42000 (patiece 40000)
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
42199/50000 8.08G 0.08059 0.08471 0.7974 163 1024: 100%|██████████| 1/1 [00:00<00:00, 3.21
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<0
all 8 16 0.917 0.718 0.849 0.463
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
42200/50000 8.14G 0.09538 0.1015 0.7966 215 1024: 100%|██████████| 1/1 [00:00<00:00, 3.15
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<0
all 8 16 0.917 0.718 0.849 0.463
Stopping training early as no improvement observed in last 40000 epochs. Best results observed at epoch 2200, best model saved as best.pt.
To update EarlyStopping(patience=40000) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping.
42200 epochs completed in 10.187 hours.
Optimizer stripped from runs\detect\train7\weights\last.pt, 6.3MB
Optimizer stripped from runs\detect\train7\weights\best.pt, 6.3MB
Validating runs\detect\train7\weights\best.pt...
Ultralytics YOLOv8.0.105 Python-3.10.11 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
Model summary (fused): 168 layers, 3006038 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 1/1 [00:00<0
all 8 16 1 0.875 0.956 0.791
hashiqi 8 13 1 0.751 0.916 0.719
labuladuo 8 3 1 0.998 0.995 0.864
Speed: 1.1ms preprocess, 15.7ms inference, 0.0ms loss, 2.0ms postprocess per image
Results saved to runs\detect\train7
Inference, using the best trained model to prepare for inference
yolo detect predict model=runs\detect\train5\weights\best.pt source=data\test_images save=True
inference effect
(yolo) G:\ultralytics>yolo detect predict model=runs\detect\train7\weights\best.pt source=data\test_images save=True
Ultralytics YOLOv8.0.105 Python-3.10.11 torch-2.0.0+cu118 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
Model summary (fused): 168 layers, 3006038 parameters, 0 gradients
image 1/5 G:\ultralytics\data\test_images\11111.jpg: 1024x1024 2 hashiqis, 2 labuladuos, 10.4ms
image 2/5 G:\ultralytics\data\test_images\111121.jpg: 672x1024 2 hashiqis, 1 labuladuo, 167.6ms
image 3/5 G:\ultralytics\data\test_images\1111211.jpg: 640x1024 (no detections), 145.9ms
image 4/5 G:\ultralytics\data\test_images\11112211.jpg: 800x1024 1 hashiqi, 6 labuladuos, 153.9ms
image 5/5 G:\ultralytics\data\test_images\1d6e8adbb5d18f57.jpg: 704x1024 (no detections), 162.3ms
Speed: 8.1ms preprocess, 128.0ms inference, 2.7ms postprocess per image at shape (1, 3, 1024, 1024)
Results saved to runs\detect\predict6
Analyzing training results
find runs\detect\train7the image below
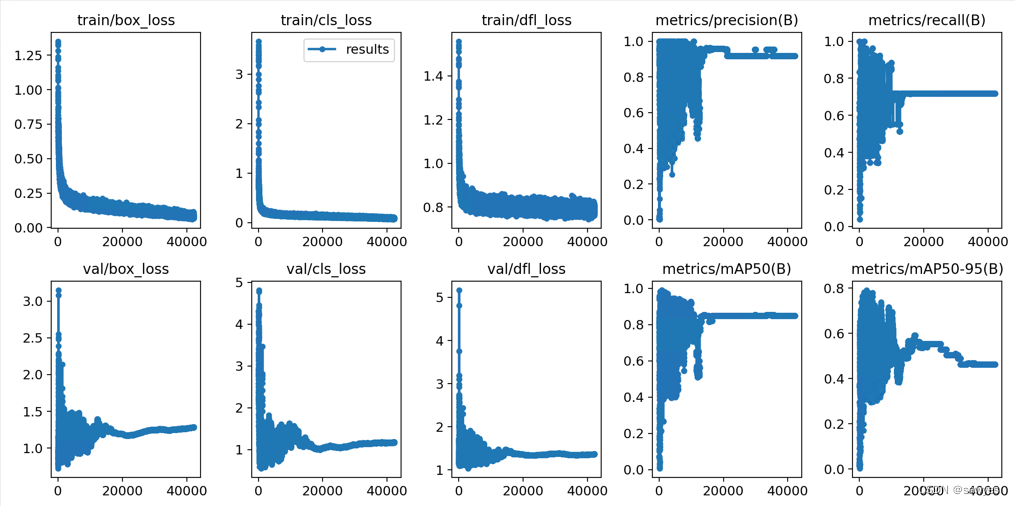
- recall : The higher the recall, the fewer missed detections. At this time, the number of positive cases predicted as negative cases is less. It can be understood that the more positive cases are picked out, and the number of steps tends to be stable around 15,000
- mAP@[0.5:0.95] , the larger the prediction frame is, the more accurate it is
Tips for getting the best training results
https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results/
data:
- images for each class . ≥ 1500 images per class recommended
- The number of instances of each class . ≥ 10000 instances per class (labeled objects) are recommended
- Image diversity . Must represent a deployed environment. For real-world use cases, we recommend using images from different times of day, different seasons, different weather, different lighting, different angles, different sources (crawled online, collected locally, different cameras), etc.
- label consistency . All instances of all classes in all images must be marked. Some tags will not work.
- labeling accuracy . Labels must tightly surround each object. There should be no space between the object and its bounding box. No object should be missing a label.
- background image . Background images are images without objects, which are added to the dataset to reduce false positives (FP). We recommend about 0-10% background images to help reduce FP (COCO has 1000 background images for reference, 1% of the total). Background images don't need tags.