Table of contents
2. Forward propagation process
2. The basic module STT Block in each stage
1. Network construction
The original structure in the paper
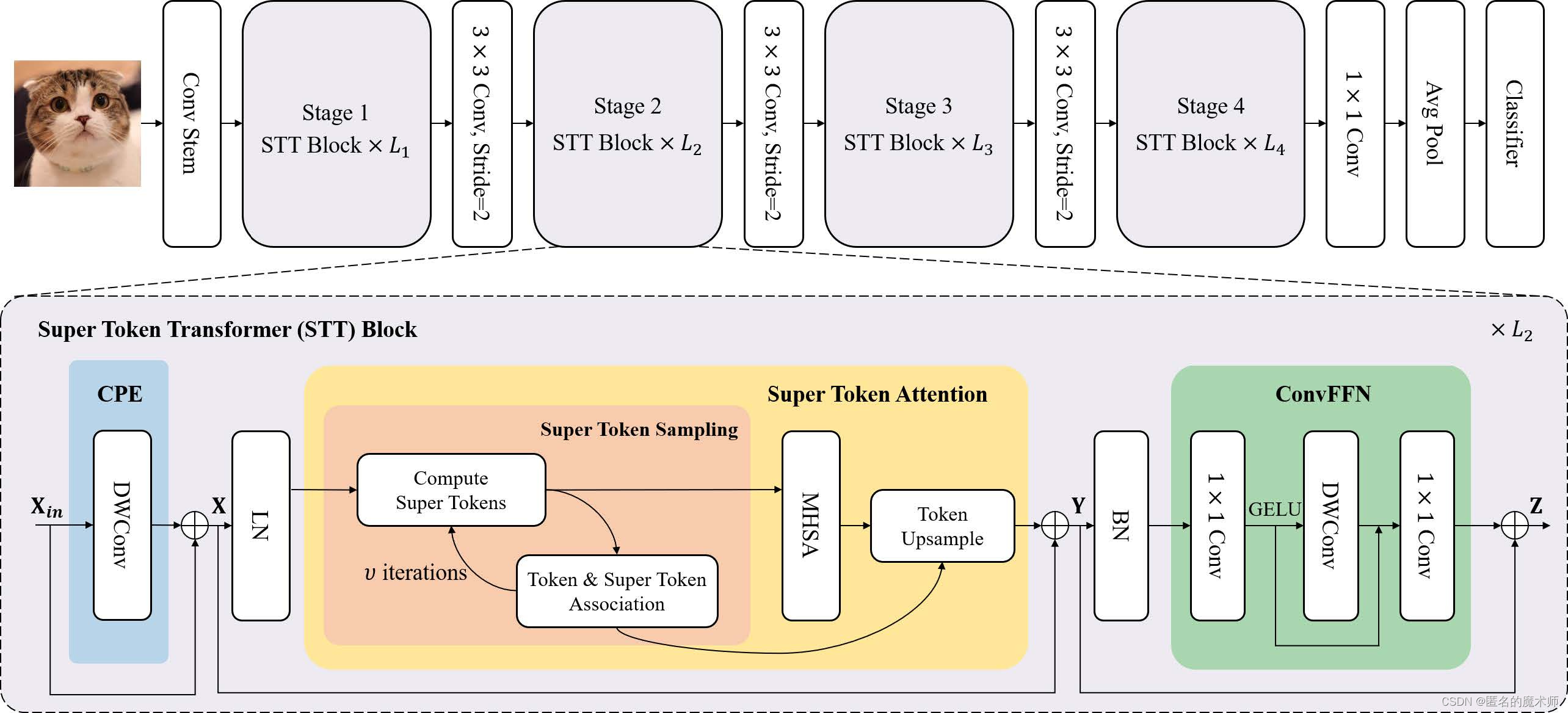
basic module
1、Conv Stem
(patch_embed): PatchEmbed(
(proj): Sequential(
(0): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): GELU()
(2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GELU()
(5): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): Conv2d(48, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(7): GELU()
(8): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GELU()
(11): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(pos_drop): Dropout(p=0.0, inplace=False)2. Modules in each stage
MouleList >> BasicLayer >> StokenAttentionLayer
In the source code, the basic module that constitutes each stage is this StokenAttentionLayer
in
CPE >> ResDWC
ResDWC(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96)
)LN >> LayerNorm2d
STA >> StokenAttention
StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)BN >> BatchNorm2d
ConvFFN >> Mlp
Mlp(
(fc1): Conv2d(96, 384, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(384, 96, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384)
)3. 3X3 convolution
PatchMerging(
(proj): Sequential(
(0): Conv2d(96, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)2. Forward propagation process
Take random inputs:
input_try = torch.rand(1, 3, 512, 512)
Model for SViT-S
1、Stem
Stem consists of 4 connected Conv2d-GELU-BN layers without position encoding, and the output vector shape is
x (1,64,128,128)
Followed by a Dropout layer, the drop rate is determined by the parameter args.drop
2. The basic module STT Block in each stage
1) CPE module
class ResDWC(nn.Module):
def __init__(self, dim, kernel_size=3):
super().__init__()
self.dim = dim
self.kernel_size = kernel_size
self.conv = nn.Conv2d(dim, dim, kernel_size, 1, kernel_size//2, groups=dim)
self.shortcut = nn.Parameter(torch.eye(kernel_size).reshape(1, 1, kernel_size, kernel_size))
self.shortcut.requires_grad = False
def forward(self, x):
return F.conv2d(x, self.conv.weight+self.shortcut, self.conv.bias, stride=1, padding=self.kernel_size//2, groups=self.dim) # equal to x + conv(x)Its forward pass includes this process
F.conv2d(x, self.conv.weight+self.shortcut, self.conv.bias, ......
The self.shortcut is all 1, which is equivalent to
Corresponds to the calculation process in the paper
2) STA module
Implementation process
x = x + self.drop_path(self.attn(self.norm1(x)))Among them, self.norm1 is LN normalization, and the main process is implemented in self.attn.
in the paper

corresponding
hh, ww = H//h, W//w
Perform the following sampling to get S0
stoken_features = F.adaptive_avg_pool2d(x, (hh, ww))Equation 5 in the paper
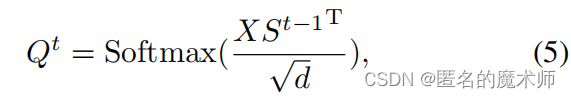
correspond
stoken_features = self.unfold(stoken_features) # (B, C*9, hh*ww) # (1, 576, 256) 采取周围的9个super token 进行association
stoken_features = stoken_features.transpose(1, 2).reshape(B, hh*ww, C, 9) # (1,256,64,9)
affinity_matrix = pixel_features @ stoken_features * self.scale # (B, hh*ww, h*w, 9) # (1,256,64,9)
affinity_matrix = affinity_matrix.softmax(-1) # (B, hh*ww, h*w, 9) (1,256,64,9) 论文中的 association map QtThe column-normalized process in the paper
if idx < self.n_iter - 1: # column-normalized 过程
stoken_features = pixel_features.transpose(-1, -2) @ affinity_matrix # (B, hh*ww, C, 9)
stoken_features = self.fold(stoken_features.permute(0, 2, 3, 1).reshape(B*C, 9, hh, ww)).reshape(B, C, hh, ww)
stoken_features = stoken_features/(affinity_matrix_sum + 1e-12) # (B, C, hh, ww)formula 6

stoken_features = pixel_features.transpose(-1, -2) @ affinity_matrixformula 9
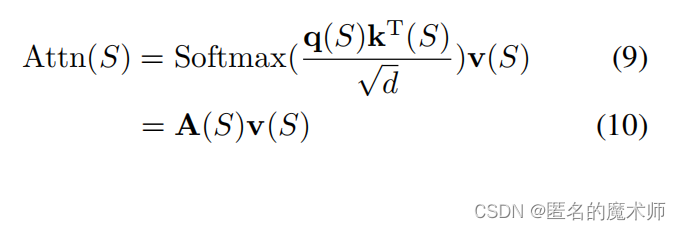
stoken_features = self.stoken_refine(stoken_features)The above is achieved with the MHSA process
formula 11
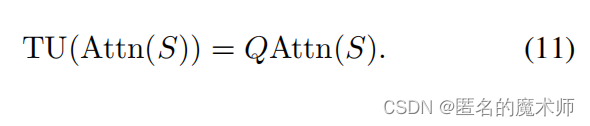
pixel_features = stoken_features @ affinity_matrix.transpose(-1, -2then proceed
x = x + self.drop_path(self.mlp2(self.norm2(x)))network structure
SViT-s
STViT(
(patch_embed): PatchEmbed(
(proj): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): GELU()
(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GELU()
(5): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(7): GELU()
(8): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GELU()
(11): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(pos_drop): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0): BasicLayer(
(blocks): ModuleList(
(0): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(64, 192, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): Identity()
(norm2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
)
)
)
(1): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(64, 192, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.016)
(norm2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
)
)
)
(2): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(64, 192, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.032)
(norm2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
)
)
)
)
(downsample): PatchMerging(
(proj): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(1): BasicLayer(
(blocks): ModuleList(
(0): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(128, 384, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.047)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
)
)
(1): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(128, 384, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.063)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
)
)
(2): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(128, 384, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.079)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
)
)
(3): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(128, 384, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.095)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
)
)
(4): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(128, 384, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.111)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
)
)
)
(downsample): PatchMerging(
(proj): Sequential(
(0): Conv2d(128, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(2): BasicLayer(
(blocks): ModuleList(
(0): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.126)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
(1): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.142)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
(2): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.158)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
(3): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.174)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
(4): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.189)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
(5): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.205)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
(6): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.221)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
(7): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.237)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
(8): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=320)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(320, 960, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.253)
(norm2): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
)
)
)
(downsample): PatchMerging(
(proj): Sequential(
(0): Conv2d(320, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(3): BasicLayer(
(blocks): ModuleList(
(0): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(512, 1536, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.268)
(norm2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2048, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2048)
)
)
)
(1): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(512, 1536, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.284)
(norm2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2048, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2048)
)
)
)
(2): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(512, 1536, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.300)
(norm2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2048, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2048)
)
)
)
)
)
)
(proj): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(norm): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(swish): MemoryEfficientSwish()
(avgpool): AdaptiveAvgPool2d(output_size=1)
(head): Linear(in_features=1024, out_features=1000, bias=True)
)=======================================================================
The following is the model of SViT-L, the larger one
STViT(
(patch_embed): PatchEmbed(
(proj): Sequential(
(0): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): GELU()
(2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): GELU()
(5): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): Conv2d(48, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(7): GELU()
(8): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): GELU()
(11): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(pos_drop): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0): BasicLayer(
(blocks): ModuleList(
(0): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((96,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): Identity()
(norm2): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(96, 384, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(384, 96, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384)
)
)
)
(1): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((96,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.003)
(norm2): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(96, 384, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(384, 96, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384)
)
)
)
(2): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((96,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.005)
(norm2): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(96, 384, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(384, 96, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384)
)
)
)
(3): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((96,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(96, 288, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.008)
(norm2): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(96, 384, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(384, 96, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384)
)
)
)
)
(downsample): PatchMerging(
(proj): Sequential(
(0): Conv2d(96, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(1): BasicLayer(
(blocks): ModuleList(
(0): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.011)
(norm2): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(192, 768, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
)
)
)
(1): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.014)
(norm2): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(192, 768, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
)
)
)
(2): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.016)
(norm2): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(192, 768, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
)
)
)
(3): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.019)
(norm2): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(192, 768, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
)
)
)
(4): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.022)
(norm2): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(192, 768, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
)
)
)
(5): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.024)
(norm2): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(192, 768, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
)
)
)
(6): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((192,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(192, 576, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.027)
(norm2): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(192, 768, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
)
)
)
)
(downsample): PatchMerging(
(proj): Sequential(
(0): Conv2d(192, 448, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(2): BasicLayer(
(blocks): ModuleList(
(0): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.030)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(1): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.032)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(2): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.035)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(3): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.038)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(4): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.041)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(5): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.043)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(6): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.046)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(7): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.049)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(8): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.051)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(9): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.054)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(10): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.057)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(11): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.059)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(12): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.062)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(13): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.065)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(14): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.068)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(15): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.070)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(16): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.073)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(17): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.076)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
(18): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(448, 448, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=448)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((448,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(448, 1344, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(448, 448, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.078)
(norm2): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(448, 1792, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(1792, 448, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(1792, 1792, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1792)
)
)
)
)
(downsample): PatchMerging(
(proj): Sequential(
(0): Conv2d(448, 640, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(3): BasicLayer(
(blocks): ModuleList(
(0): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((640,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(640, 1920, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.081)
(norm2): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(640, 2560, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2560, 640, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2560, 2560, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2560)
)
)
)
(1): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((640,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(640, 1920, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.084)
(norm2): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(640, 2560, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2560, 640, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2560, 2560, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2560)
)
)
)
(2): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((640,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(640, 1920, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.086)
(norm2): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(640, 2560, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2560, 640, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2560, 2560, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2560)
)
)
)
(3): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((640,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(640, 1920, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.089)
(norm2): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(640, 2560, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2560, 640, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2560, 2560, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2560)
)
)
)
(4): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((640,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(640, 1920, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.092)
(norm2): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(640, 2560, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2560, 640, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2560, 2560, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2560)
)
)
)
(5): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((640,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(640, 1920, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.095)
(norm2): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(640, 2560, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2560, 640, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2560, 2560, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2560)
)
)
)
(6): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((640,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(640, 1920, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.097)
(norm2): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(640, 2560, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2560, 640, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2560, 2560, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2560)
)
)
)
(7): StokenAttentionLayer(
(pos_embed): ResDWC(
(conv): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=640)
)
(norm1): LayerNorm2d(
(norm): LayerNorm((640,), eps=1e-06, elementwise_affine=True)
)
(attn): StokenAttention(
(unfold): Unfold()
(fold): Fold()
(stoken_refine): Attention(
(qkv): Conv2d(640, 1920, kernel_size=(1, 1), stride=(1, 1))
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))
(proj_drop): Dropout(p=0.0, inplace=False)
)
)
(drop_path): DropPath(drop_prob=0.100)
(norm2): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(mlp2): Mlp(
(fc1): Conv2d(640, 2560, kernel_size=(1, 1), stride=(1, 1))
(act1): GELU()
(fc2): Conv2d(2560, 640, kernel_size=(1, 1), stride=(1, 1))
(drop): Dropout(p=0.0, inplace=False)
(conv): ResDWC(
(conv): Conv2d(2560, 2560, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2560)
)
)
)
)
)
)
(proj): Conv2d(640, 1024, kernel_size=(1, 1), stride=(1, 1))
(norm): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(swish): MemoryEfficientSwish()
(avgpool): AdaptiveAvgPool2d(output_size=1)
(head): Linear(in_features=1024, out_features=1000, bias=True)
)