Click the card below to follow the " CVer " official account
AI/CV heavy dry goods, delivered in the first time
Click to enter —> [Multimodal and Transformer] exchange group
Reprinted from: Heart of the Machine
For a long time, everyone has been very curious about GPT-4's model architecture, infrastructure, training data sets, costs and other information.
However, OpenAI's mouth is too strict. For a long time, everyone has only guessed these data.
Not long ago, "genius hacker" George Hotz (George Hotz) revealed a gossip in an interview with an AI technology podcast called Latent Space, saying that GPT-4 is an integrated system composed of 8 mixed expert models, Each expert model has 220 billion parameters (slightly more than GPT-3's 175 billion parameters), and these models are trained on different data and task distributions.
Although this news cannot be verified, its popularity is very high, and it is also considered very reasonable by some industry insiders.
Recently, more news seems to have leaked out.
Today, SemiAnalysis released a paid subscription content that "revealed" more information about GPT-4.

According to the article, they collected a lot of information about GPT-4 from many sources, including model architecture, training infrastructure, inference infrastructure, parameter volume, training data set composition, token volume, number of layers, parallel strategy, multimodal vision Adaptation, the thought process behind different engineering trade-offs, unique implementation techniques, and how to alleviate bottlenecks related to inferencing huge models, etc.
According to the authors, the most interesting aspect of GPT-4 is understanding why OpenAI made certain architectural decisions.
In addition, the article also introduces the training and inference costs of GPT-4 on A100, and how to expand to the next-generation model architecture H100.
We compiled the following data information about GPT-4 based on a tweet (now deleted) by Yam Peleg, founder of Deep Trading (an algorithmic trading company). Interested readers can study it carefully.
However, please note that this is not officially confirmed data, and you can judge its accuracy by yourself.
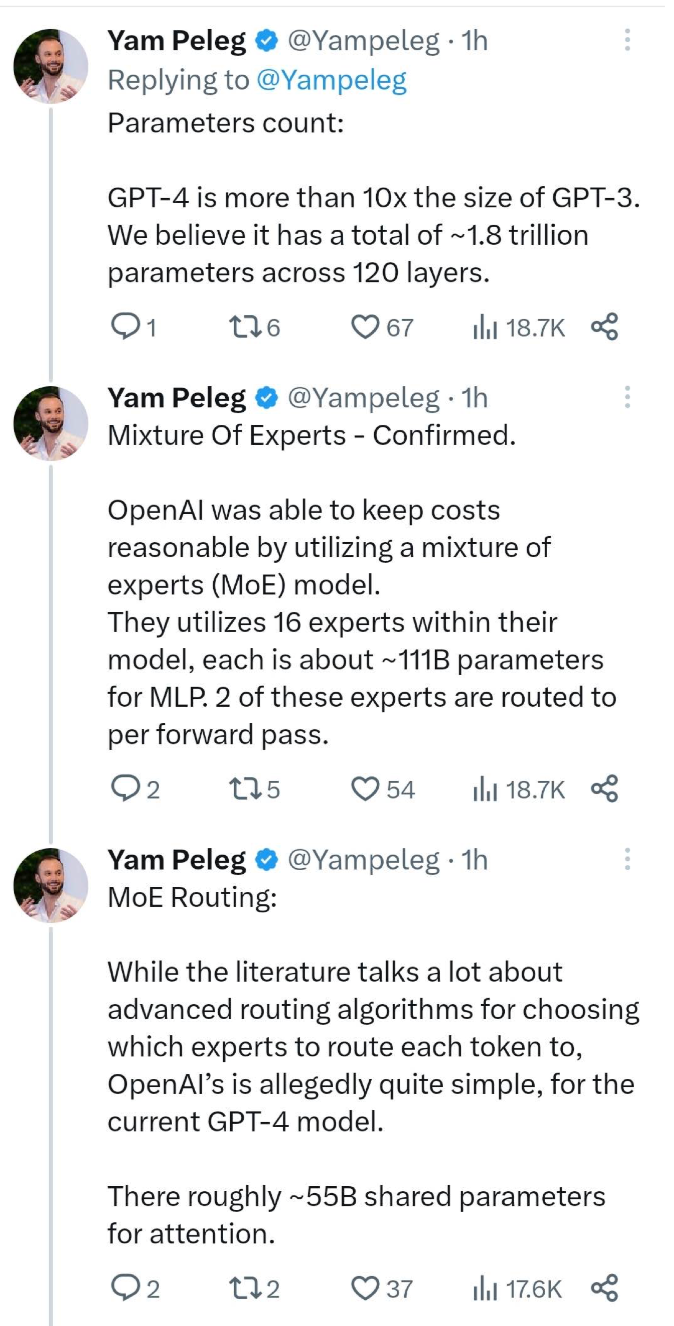
1. The amount of parameters : the size of GPT-4 is more than 10 times that of GPT-3. The article considers a total of 1.8 trillion parameters in its 120-layer network.
2. It is indeed a mixed expert model . OpenAI was able to keep costs reasonable by using a Mixture of Experts (MoE) model. They used 16 expert models in the model, each expert model has about 111B parameters. 2 of these expert models are routed to each forward pass.
3. MoE Routing : Although there is a lot of discussion in the literature on advanced routing algorithms for choosing which expert model to route each token to, OpenAI is said to employ a fairly simple routing approach in the current GPT-4 model. The model uses approximately 55 billion shared parameters for attention calculations.
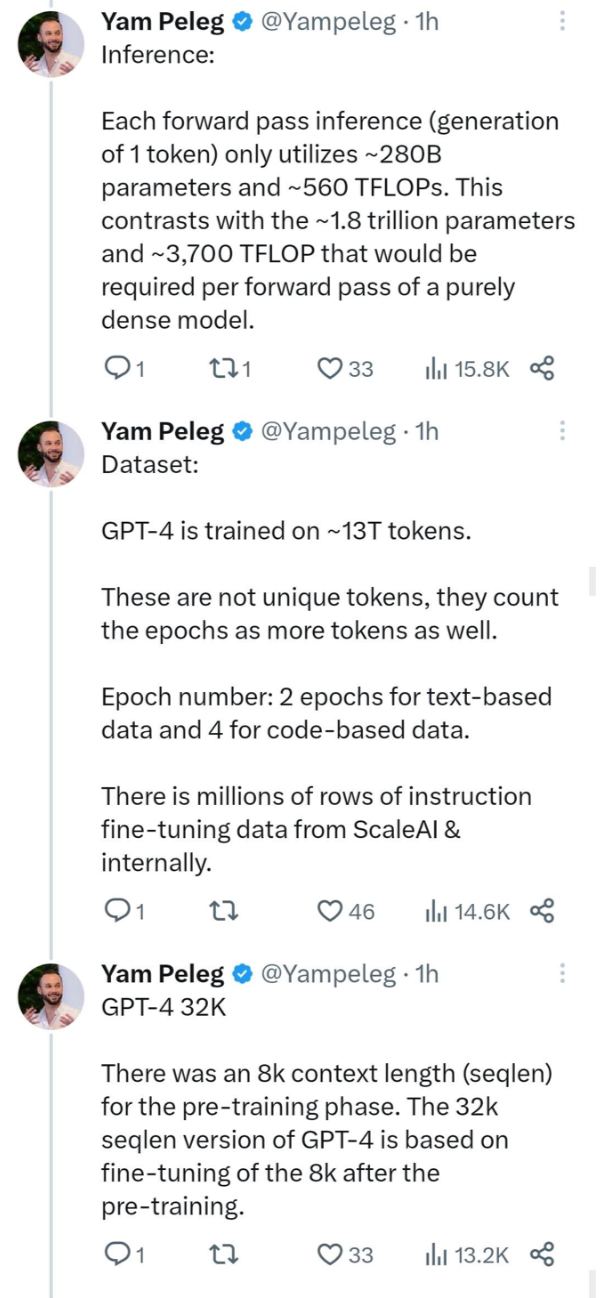
4. Inference : The inference of each forward pass (generating 1 token) only uses about 280 billion parameters and about 560 TFLOPs of calculation. In contrast, the pure dense model requires about 1.8 trillion parameters and about 3700 TFLOPs of computation per forward pass.
5. Dataset : The training data set of GPT-4 contains about 13 trillion tokens. These tokens are the result of repeated calculations, and tokens from multiple epochs are counted.
Number of Epochs: Training was performed for 2 epochs on text-based data and 4 epochs on code-based data. In addition, there are millions of rows of instruction fine-tuning data from ScaleAI and internally.
6. GPT-4 32K : In the pre-training phase, GPT-4 uses a context length (seqlen) of 8k. The 32k sequence length version of GPT-4 is obtained by fine-tuning the 8k version after pre-training.
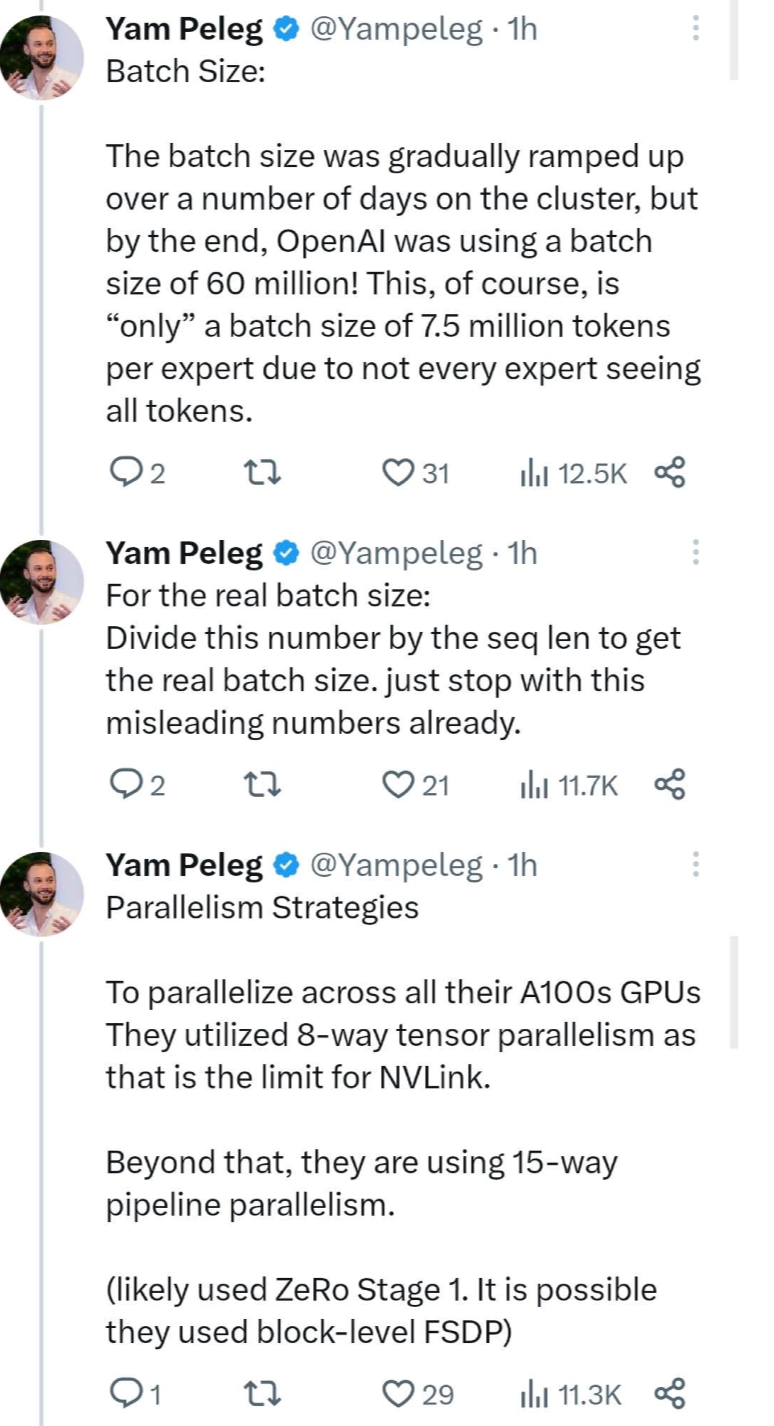
7. Batch Size : On the computing cluster, the batch size gradually increased in a few days, and finally, OpenAI used the batch size to reach 60 million! Of course, since not every expert model can see all tokens, this is only a batch size of 7.5 million tokens per expert model.
Real batch size: Divide this number by the sequence length (seq len) to get the real batch size. Please stop using such misleading numbers.
8. Parallel strategy : In order to perform parallel computing on all A100 GPUs, they adopted 8-way tensor parallelism because this is the limit of NVLink. In addition, they also adopted 15 parallel pipelines. (Most likely ZeRo Stage 1 was used, and possibly block-level FSDP).

9. Training cost : OpenAI used about 2.15e25 FLOPS in the training of GPT-4, used about 25,000 A100 GPUs, trained for 90 to 100 days, and the utilization rate (MFU) was about 32% to 36%. This extremely low utilization is partly due to the high number of failures that require restarting checkpoints.
If they cost about $1 per hour per A100 GPU in the cloud, that would cost about $63 million for this training session alone. (Today, pre-training with about 8192 H100 GPUs drops to about 55 days at a cost of $21.5 million, billed at $2 per hour per H100 GPU.)
10. Tradeoff when using the expert mixture model : There are many aspects of tradeoff when using the expert mixture model.
For example, dealing with MoE during inference is very difficult because not every part of the model is utilized at every token generation. This means that while some parts are being used, other parts may be idle. This can severely impact resource utilization when serving users. Researchers have shown that using 64 to 128 experts can achieve better loss than using 16 experts, but this is only the result of research.
There are several reasons for choosing fewer expert models. One of the reasons OpenAI chose 16 expert models is that in many tasks more expert models are harder to generalize and possibly harder to converge.
Due to such large-scale training, OpenAI chose to be more conservative in the number of expert models.
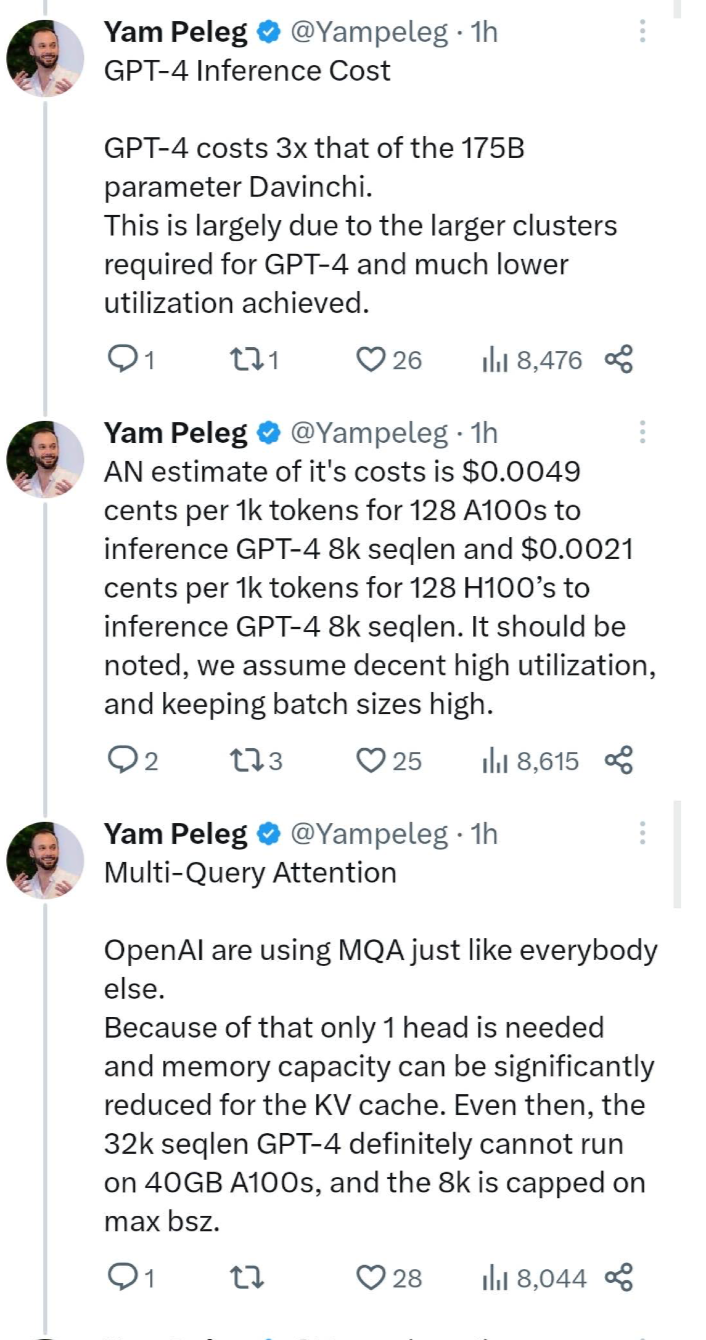
11. Inference cost : The inference cost of GPT-4 is 3 times that of the Davinci model with 175 billion parameters. This is mainly because GPT-4 requires a larger cluster and achieves a much lower utilization.
The cost of inference on the 8k version of GPT-4 is estimated to be 0.0049 cents per 1,000 tokens using 128 A100 GPUs for inference. Using 128 H100 GPUs for inference, the same 8k version of GPT-4 inference costs 0.0021 cents per 1,000 tokens. It is worth noting that these estimates assume high utilization and keep the batch size high.
12. Multi-Query Attention : OpenAI, like other institutions, is also using Multi-Query Attention (MQA). Since only one attention head is needed using MQA, and the memory capacity for KV cache can be significantly reduced. Even so, GPT-4 with a sequence length of 32k definitely cannot run on a 40GB A100 GPU, and the model with sequence length of 8k is limited by the maximum batch size.
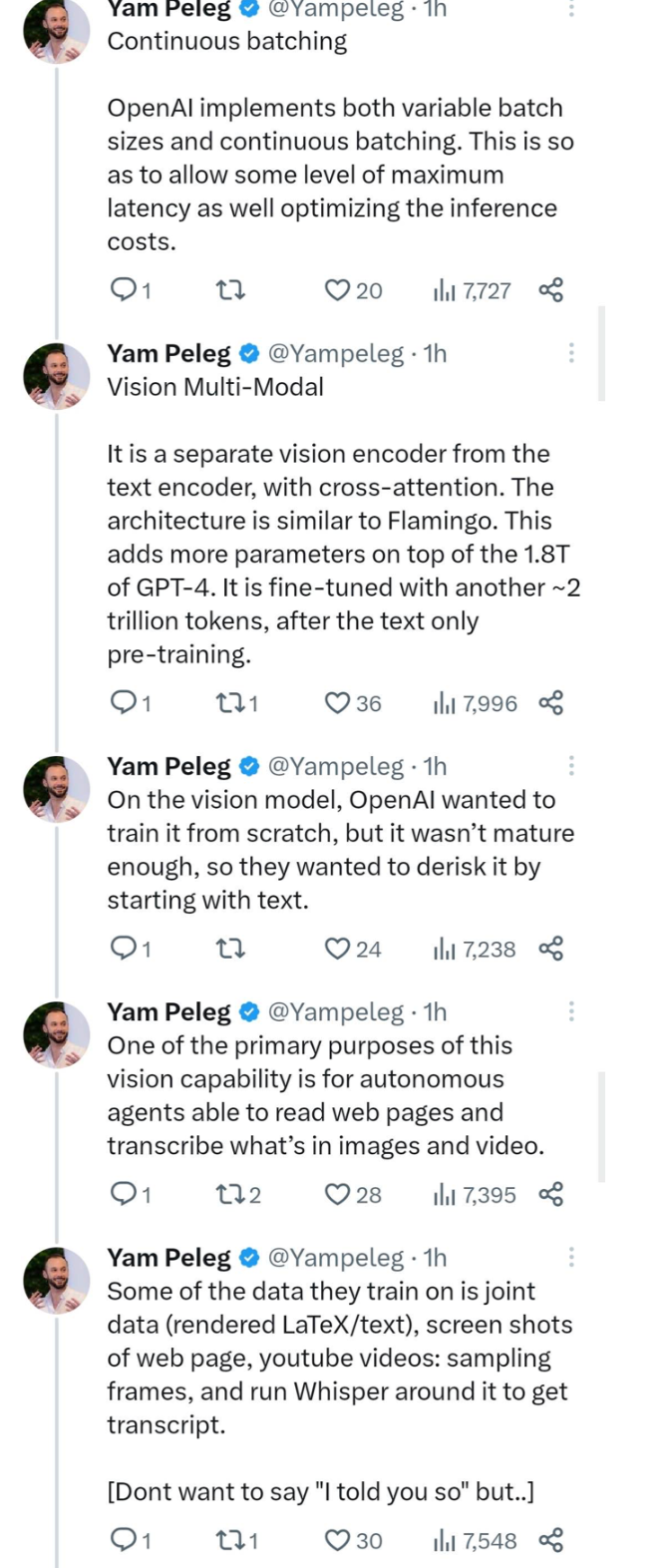
13. Continuous batching : OpenAI implements variable batch size and continuous batching. This is done to allow some degree of maximum latency, and to optimize inference cost.
14. Visual Multimodal : It is a visual encoder independent of the text encoder with cross-attention between the two. The architecture is similar to Flamingo. This adds more parameters on top of GPT-4's 1.8 trillion parameters. After pre-training on plain text, it was fine-tuned on another ~2 trillion tokens.
For the vision model, OpenAI originally wanted to train from scratch, but since it is not yet mature, they decided to start training from text first to reduce the risk.
One of the main purposes of this vision capability is to enable autonomous agents to read web pages and transcribe content from images and videos.
Part of the data they trained on was joint data (including rendered LaTeX/text), screenshots of webpages, YouTube videos (sampled frames), and ran it through Whisper to get the transcribed text.
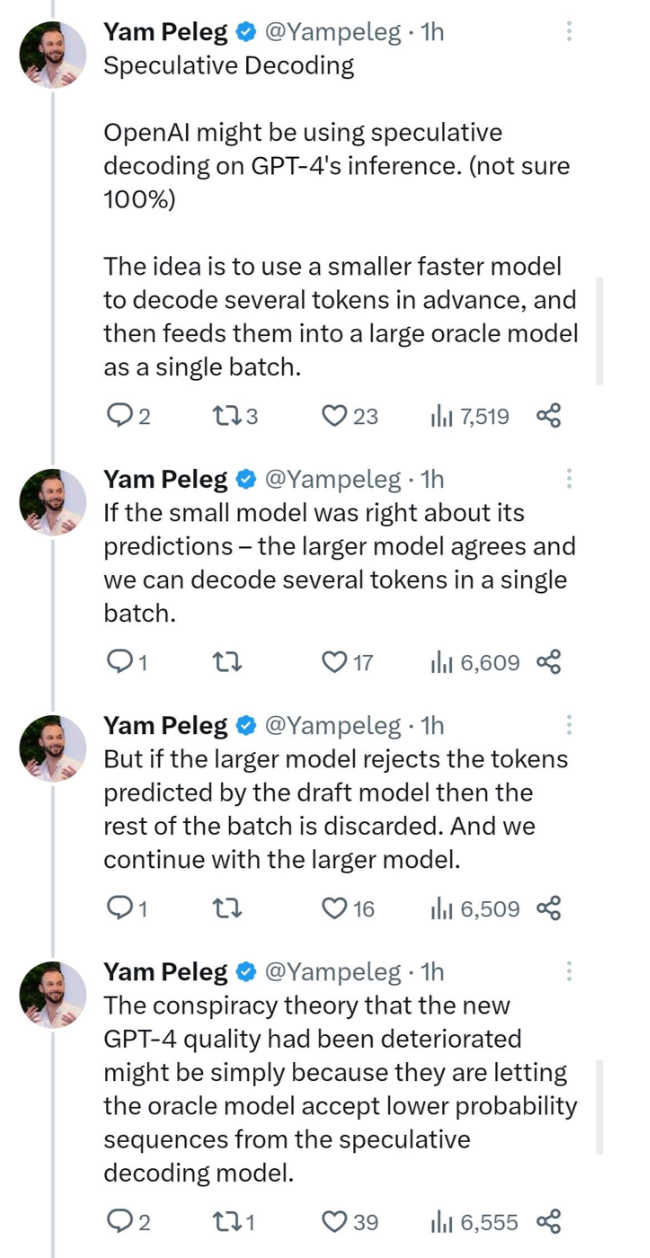
15. Speculative Decoding : OpenAI may have used speculative decoding technology in the reasoning process of GPT-4 (not sure if it is 100%). The approach is to use a smaller and faster model to decode multiple tokens ahead of time and feed them as a single batch into a large predictive model (oracle model).
If the small model is correct in its prediction, the large model will agree and we can decode multiple tokens in a single batch.
However, if the large model rejects a token predicted by the draft model, the remainder of the batch is discarded and we continue to decode using the large model.
Some conspiracy theories point to the fact that the new GPT-4 has been degraded in quality, and this may simply be the result of their misinterpretation by having their speculative decoding model pass sequences with lower probability to the predictive model.
16. Inference Architecture : Inference runs on a cluster consisting of 128 GPUs. Multiple such clusters exist in multiple data centers in different locations. The inference process uses 8-way tensor parallelism and 16-way pipeline parallelism. Each node consisting of 8 GPUs has only about 130 billion parameters.
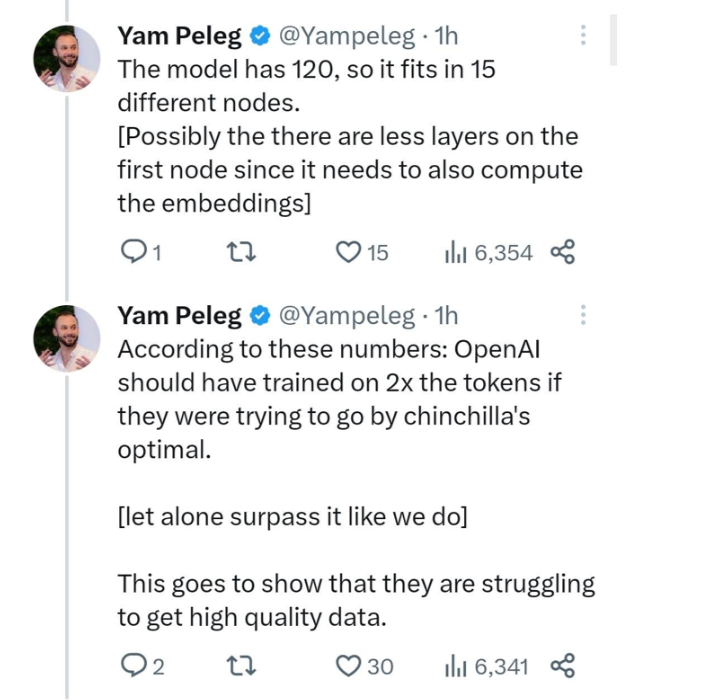
The model has 120 layers and thus fits on 15 different nodes. Probably the first node has fewer layers because it also needs to compute embeddings.
Based on these numbers, if OpenAI were trying to train on the best metric for chinchilla, they should be using twice as many tokens as they do now. This suggests that they are having difficulty obtaining high-quality data.
The last thing I want to say is that this should be the most detailed data reveal about GPT-4 so far. It is not yet possible to verify whether it is true, but it is worth researching. As the original author said, " The interesting aspect is understanding why OpenAI makes certain architectural decisions. "
What do you think about the architecture information of GPT-4?
For more information, please refer to the original text: https://www.semianalysis.com/p/gpt-4-architecture-infrastructure
Click to enter —> [Multimodal and Transformer] exchange group
The latest CVPR 2023 papers and code download
Background reply: CVPR2023, you can download the collection of CVPR 2023 papers and code open source papers
Background reply: Transformer review, you can download the latest 3 Transformer review PDFs
多模态和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-多模态或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号It's not easy to organize, please like and watch![]()