Click on the blue word to follow us
Follow and star
never get lost
Institute of Computer Vision


Public ID|Computer Vision Research Institute
Learning group|Scan the QR code to get the joining method on the homepage

Paper address: https://arxiv.org/pdf/2111.13824.pdf
Project code: https://github.com/megvii-research/FQ-ViT
Computer Vision Research Institute column
Column of Computer Vision Institute
Quantizing and model-transforming algorithmic networks can significantly reduce the complexity of model inference and have been widely used in practical deployments. However, most existing quantization methods are mainly developed for convolutional neural networks and suffer severe dropouts when applied on fully quantized vision transformers. Today we will share a new technology to achieve high-precision quantitative Vit deployment. Is it still far from us to use AI large models?

01
Overview
Transformer is the basis of the hot AIGC pre-training large model, and ViT (Vision Transformer) is the real sense of bringing the Transformer in the field of natural language processing to the field of vision. From the development process of Transformer, it can be seen that from the proposal of Transformer to the application of Transformer to vision, in fact, it took three years of dormancy in the middle. It took almost two or three years from the application of Transformer to the visual field (ViT) to the popularity of AIGC. In fact, the popularity of AIGC has been slack since the end of 2022. At that time, some AIGC interesting algorithms were gradually released. Up to now, AIGC interesting projects are really emerging one after another.
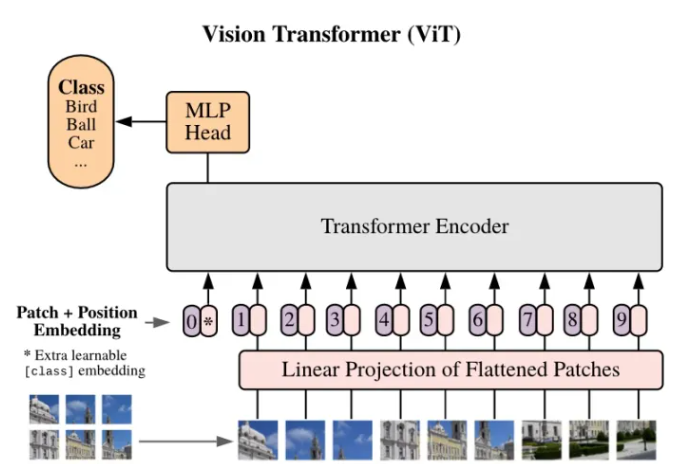
With the in-depth research on the Visual Transformer model (ViT) in the past two years, the expressive ability of ViT has been continuously improved, and it has achieved substantial performance breakthroughs in most basic visual tasks (classification, detection, segmentation, etc.). However, many practical application scenarios require high real-time reasoning capabilities of the model, but most lightweight ViTs still cannot achieve the same speed as lightweight CNNs (such as MobileNet) in multiple deployment scenarios (GPU, CPU, ONNX, mobile terminals, etc.).
Therefore, the 2 exclusive modules of ViT were revisited, and the reasons for the degradation were found as follows:
-
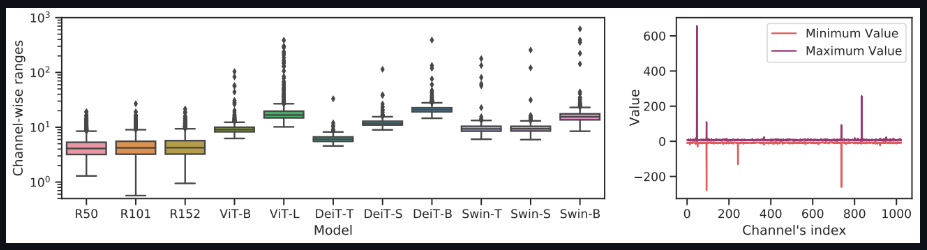
The researchers found that the channel-to-channel variation of the LayerNorm input is severe, and the range of some channels even exceeds 40 times the median value. Traditional methods cannot handle such large activation fluctuations, which will lead to large quantization errors
-
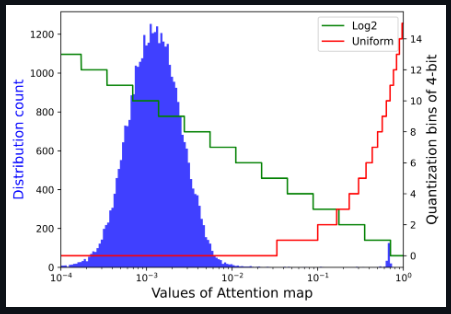
It is also found that the values of the attention map have an extremely uneven distribution, most of the values are clustered between 0 and 0.01, and a few high attention values are close to 1
Based on the above analysis, the researchers proposed Power-of-Two Factor (PTF) to quantify the input of LayerNorm. In this way, the quantization error is greatly reduced, and the overall computational efficiency is the same as that of layered quantization due to the Bit-Shift operator. Also proposed is Log Int Softmax (LIS), which provides higher quantization resolution for small values and more efficient integer inference for Softmax. Combining these approaches, this paper achieves post-training quantization of a fully quantized Vision Transformer for the first time.
02
new frame
The two figures below show that there is severe channel-to-channel variation in visual transformers compared to CNNs, which leads to unacceptable quantization errors for layered quantization.
First the network quantization notation is explained. Assuming that the quantization bit width is b, the quantizer Q(X|b) can be formulated as a function that maps a floating-point number X∈R to the nearest quantization bin:
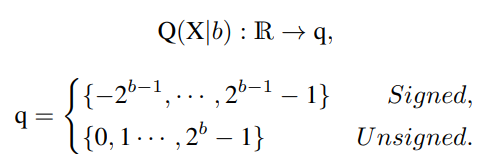
Uniform Quantization
Uniform Quantization is well supported on most hardware platforms. Its quantizer Q(X|b) can be defined as:
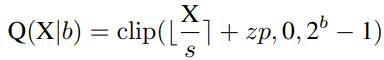
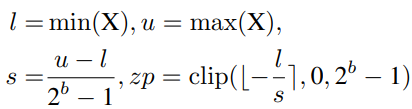
where s (scale) and zp (zero point) are quantization parameters determined by the lower bound l and upper bound u of X, which are usually the minimum and maximum values.
Log2 Quantization
Log2 Quantization converts the quantization process from linear to exponential. Its quantizer Q(X|b) can be defined as:
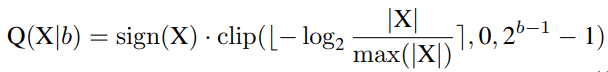
In order to achieve a fully quantized visual transformer, the researchers quantized all modules, including Conv, Linear, MatMul, LayerNorm, Softmax, etc. In particular, use uniform Min-Max quantization for Conv, Linear and MatMul modules, and the following methods for LayerNor and Softmax.
Power-of-Two Factor for LayerNorm Quantization
During inference, LayerNorm computes the statistics µX, σX at each forward step and normalizes the input X. Then, the affine parameters γ, β rescale the normalized input to another learned distribution.
As explained at the beginning of the analysis, unlike BatchNorm commonly used in neural networks, LayerNorm cannot be folded to the previous layer due to its dynamic calculation characteristics, so it must be quantized separately. However, a significant performance drop is observed when post-training quantization is applied to it. Looking at the input of the LayerNorm layer, it is found that there is severe inter-channel variation.
The researchers proposed a simple and effective layer norm quantification method, namely Power-of-Two Factor (PTF). The core idea of PTF is to equip different channels with different factors, not different quantization parameters. Given the quantization bit width b, input activity X∈RB×L×C, layer-by-layer quantization parameters s, zp∈R1, and PTFα∈NC, the quantization activity XQ can be formulated as:
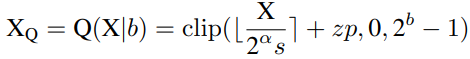
Some of the parameters are as follows:
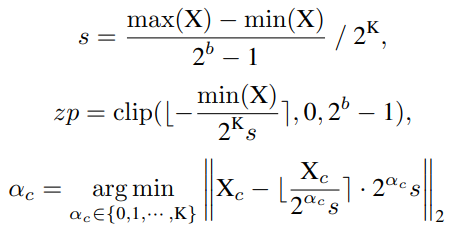
Softmax quantized with Log-Int-Softmax (LIS)
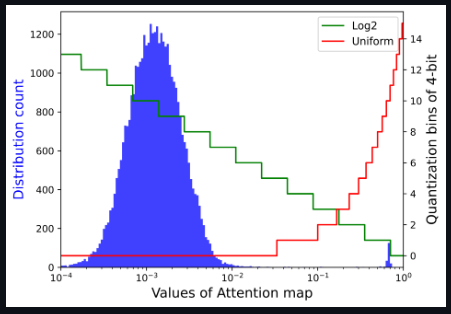
Note that the storage and calculation of the graph is the bottleneck of the transformer structure, so researchers hope to quantize it to an extremely low bit width (for example, 4 bits). However, if 4-bit uniform quantization is implemented directly, serious accuracy degradation will occur. We observe that the distribution is centered on a fairly small value of the Softmax output, while only a few outliers have larger values close to 1. Based on the following visualization, for small-valued intervals with a dense distribution, Log2 preserves more quantized intervals than uniform.
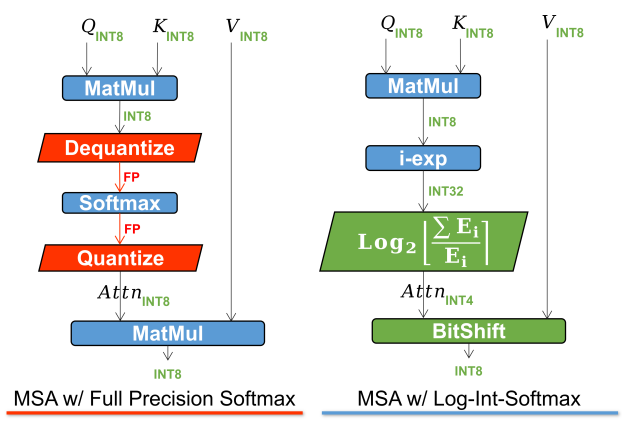
Combining Log2 quantization with i-exp (a polynomial approximation of the exponential function proposed by i-BERT), we propose LIS, an integer-only, faster, and low-power Softmax.
The whole process is shown below.
03
Experiment & Visualization
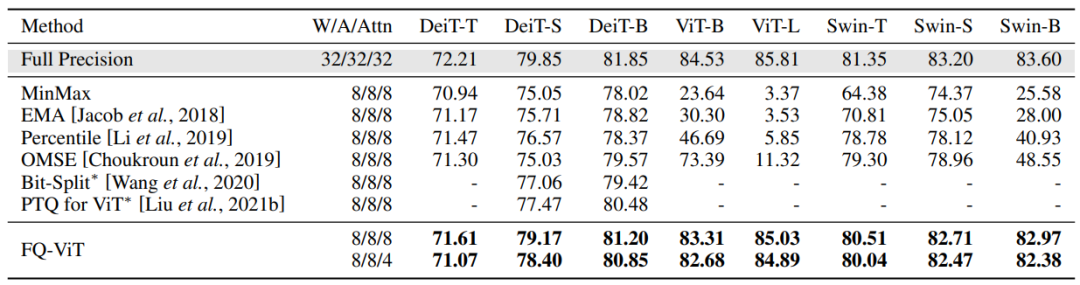
Comparison of the top-1 accuracy with state-of-the-art methods on ImageNet dataset
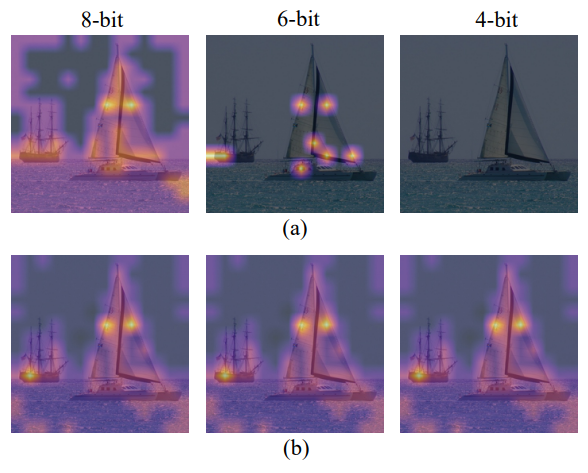
Visualize the attention map to see the difference between uniform quantization and LIS, as shown above. When both use 8 bits, uniform quantization focuses on high activation regions, while LIS preserves more texture in low activation regions, which preserves more relative rank of the attention map. In the case of 8 bits, this difference doesn't make much of a difference. However, when quantizing to lower bit widths, as shown in the 6-bit and 4-bit cases, uniform quantization degrades dramatically, even invalidating all regions of interest. In contrast, LIS still exhibits acceptable performance similar to 8-bit.
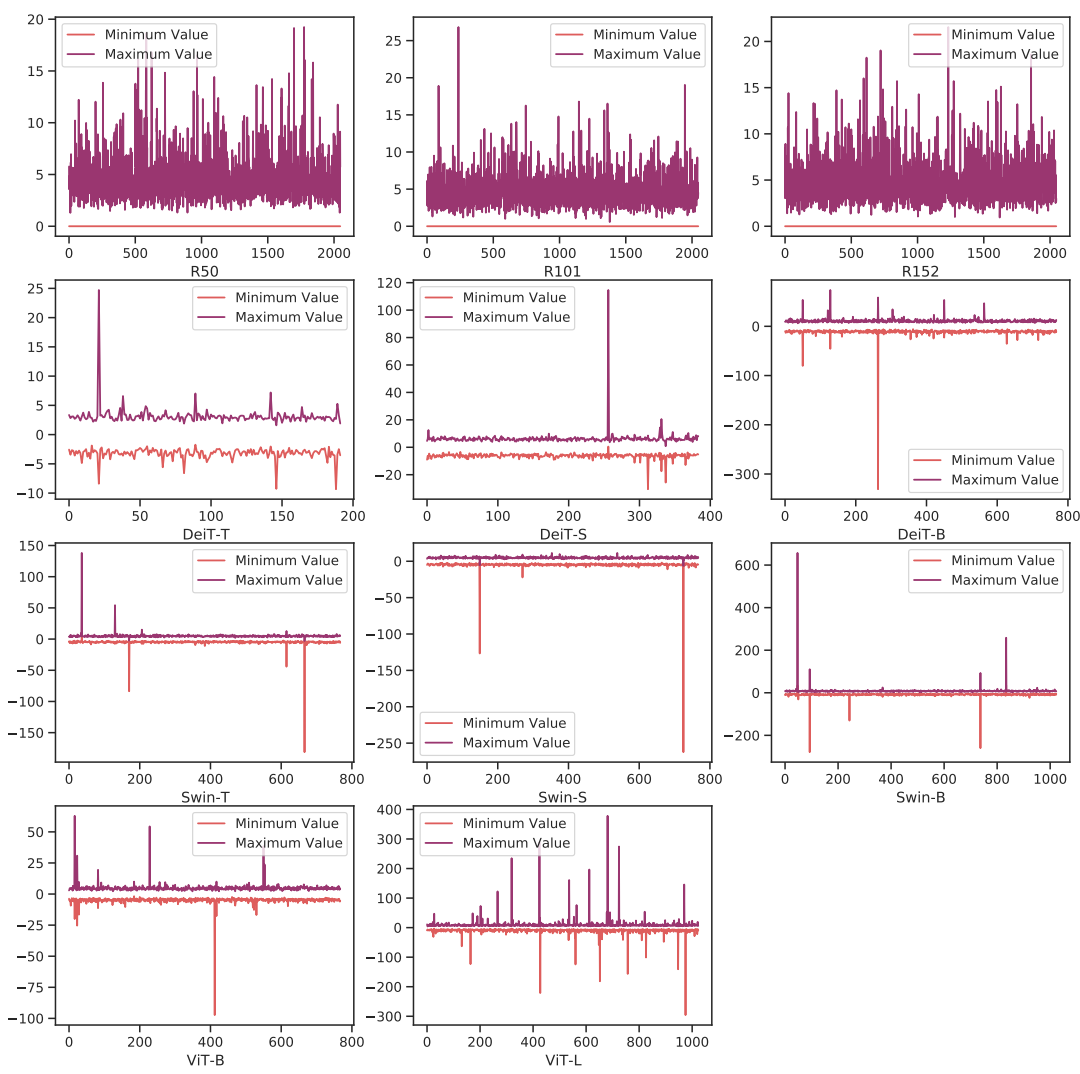
Channel-wise minimum and maximum values of Vision Transformers and ResNets
© THE END
For reprinting, please contact this official account for authorization

The Computer Vision Research Institute study group is waiting for you to join!

Click "Read the original text" to cooperate and consult immediately