Over the past decade, the application of deep learning techniques in the field of computer vision has increased year by year. Among them, pedestrian detection and vehicle detection are the most popular. One of the reasons is the reusability of the pre-trained model .
Due to the excellent results of deep learning technology in these application scenarios, enterprises have now begun to use deep learning to solve their own problems.
But what do you do if the available pre-trained models are not suitable for your application?
A pre-trained model is able to detect apples, but it certainly cannot distinguish between "good apples" and "rotten apples" because it was never "taught" to do so.
So what do you do if this happens to you?
"Get tons of images of good and bad apples and train a custom detection model!"

A common challenge when creating a good custom detection model is data issues . Deep learning models require vast amounts of data to train their algorithms—as we have seen in models such as MaskRCNN, , YOLOand , which are trained on UNetexisting large datasets COCOand .ImageNet
How can I get data for training a custom detection model?
In this post, we'll explore 5 ways to collect a dataset to train a custom detection model.
1. Publicly available open labeled datasets
If you're lucky, you might get the labeled dataset you want on the internet. Here are a few image datasets that you can choose from in the field of computer vision.
-
ImageNet
ImageNetIt is a computer vision system recognition project and the largest image recognition database in the world. ImageNetIt was established by computer scientists from Stanford in the United States to simulate a human recognition system. Ability to recognize objects from pictures. ImageNetThe dataset has detailed documentation, is maintained by a dedicated team, and is very easy to use. It is widely used in research papers in the field of computer vision, and has almost become the "standard" dataset for the current deep learning image field algorithm performance test. ImageNetThere are currently 14,197,122a total of images in the database, which are divided into 21,841categories. Usually, what we call ImageNet a data set actually refers to a sub- dataset ISLVRC2012 for competitions. train There are 1,281,167 photos and labels in it 1000, and they are of the same category. There are two types of data, and there are sub-pictures, each type of data.1300val50,00050test100,000100

-
MS COCO
COCOThe data set is an image data set released by the Microsoft team recognition+segmentation+captioning. The data set collects a large number of daily scene pictures containing common objects, and provides pixel-level instance annotations to more accurately evaluate the effect of detection and segmentation algorithms. It is committed to Advances in Scene Understanding Research. Relying on this data set, an annual competition is held, which now covers the central tasks of machine vision such as detection, segmentation, key point recognition, and annotation. It is one of the most influential ImageNet Chanllengeacademic competitions since then.
COCOThe detection task contains 80a total of categories. The data scales released in 2014 are train/val/testdivided into two categories 80k/40k/40k. The more common division in academia is to use the subset of and as the training set ( ) train, use the rest as the test set ( ), and submit to the official Submit results ( ). In addition, the official also retains part of the data as the evaluation set of the competition.35kvaltrainval35kvalminivalevaluation servertest-devCOCOtest
-
Google Open Image

Open ImageIt is a dataset released by the Google team. It contains bounding boxes for object categories 190on 10,000 images , making it the largest existing dataset annotated with object locations. These boxes were largely drawn by hand by professional annotators to ensure accuracy and consistency. These images are very diverse, often containing complex scenes with multiple objects (on average per image ).60016M8.3
-
MNIST Handwritten Dataset
MNIST Handwriting Dataset: This dataset has a total of 70,000 images of handwritten digits and is a subset of a larger dataset provided by NIST. Figures are size normalized and centered within the fixed-size image.

-
DOTA
DOTA is a commonly used data set for remote sensing aerial image detection. It contains 1 aerial image
2806with a size of about 100000000000000000000000000000000000000000000 . Its marking method is a quadrilateral of arbitrary shape and direction determined by four points. Aerial images are different from traditional datasets and have their own characteristics, such as: greater scale variability; dense small object detection; and uncertainty in detecting targets. The data is divided into validation set, test set, and training set. The training and validation sets are currently released, with image sizes ranging from .4k×4k1518828214small vehiclelarge vehiclevehicle1/61/31/2800×8004000×4000

2. Crawl web images
Another option is to do an image search on the web and manually select images to download. This method is not very efficient due to the large amount of data required.
It is worth noting that images on the web may be subject to copyright. Remember to check the copyright of images before using them.
Or you could write a program to crawl the web and download the images you want. Also take care to check the copyright of each image.
3. Shoot
If you can't find images of the objects you want, you can collect them by taking pictures. This can be done manually, by taking each image yourself or by hiring someone else to do it for you.
Another way to collect real-world imagery is to have programmed cameras in your scene to automatically collect images.

4. Data Augmentation
We know that deep learning models require a lot of data. When you only have a small dataset, it may not be enough to train a good model. In this case, you can use data augmentation to generate more training data.
Geometric transformations such as flipping, cropping, rotation, and translation are some commonly used data augmentation techniques. Applying image data augmentation not only expands the dataset by creating variants, but also reduces overfitting.

△The left is the original image of the dog, and the right is the horizontally flipped image
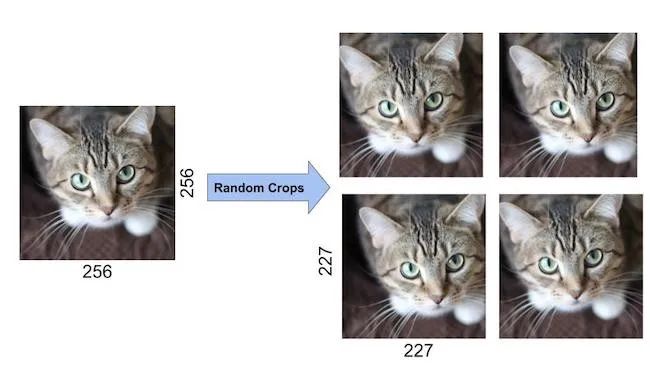
△ Original and randomly cropped images of cats

△ Original and rotated images of cats

△ Original and translated images of tennis balls
5. Data Generation
Sometimes real data may not be available. In this case, synthetic data can be generated to train a custom detection model. Due to its relatively low cost, the use of synthetic data generation has been increasing in machine learning.
Generative Adversarial Networks (GANs GAN) are one of many techniques for synthetic data generation. GANis a generative modeling technique in which artificial instances are created from a dataset in a way that preserves similar characteristics of the original set.

Summarize
Collecting a training dataset is the first step in training your custom detection model. In this post, we examine some of the techniques used to collect image data, including searching open source datasets, crawling the web, shooting manually or using programs, using data augmentation techniques, and generating synthetic datasets.