[CSP-S 2021] Palindrome
Title description:
Given a positive integer n and a sequence of integers a1,a2,…,a2n, in these 2n numbers, 1, 2,…, n each appear exactly 2 times. Now perform 2n operations, the goal is to create a sequence b1,b2,…,b2n with the same length of 2n, initially b is an empty sequence, and one of the following two operations can be performed each time:
- Adds the first element of sequence a to the end of b and removes it from a.
- Adds the end element of sequence a to the end of b and removes it from a.
Our purpose is to make b a palindrome sequence , that is, to satisfy all 1≤i≤n, bi=b2n+1−i.
Please judge whether the goal can be achieved. If yes, please output the operation plan with the smallest lexicographical order, which is explained in [ Output Format ].
Input format:
Each test point contains multiple sets of test data.
The first line of input contains an integer T representing the number of test data sets. For each set of test data:
The first line, contains a positive integer n.
The second line contains 2n integers a1, a2,..., a2n separated by spaces.
Output format:
Output one line of answers for each set of test data.
If the palindrome sequence cannot be generated, output a line ‐1, otherwise output a line with a length of 2n, consisting of characters L or R strings (without spaces), which L means operation 1 of removing the first element, and R operation 2.
You need to output the one with the smallest lexicographical order among the strings corresponding to all schemes.
The comparison rules for lexicographic order are as follows:
A string s1∼2n of length 2n is lexicographically smaller than t1∼2n if and only if there is a subscript 1≤k≤2n such that for each 1≤i<k there is si=ti and sk <tk.
Input and output samples
Input #1:
2 5 4 1 2 4 5 3 1 2 3 5 3 3 2 1 2 1 3
Output #1:
LRRLLRRRRL -1
Input #2:
See palin/palin2.in in the attachment
Output #2:
See palin/palin2.ans in the attachment
Instructions/Tips
[Example Explanation #1]
In the first set of data, the generated b sequence is [4, 5, 3, 1, 2, 2, 1, 3, 5, 4], it can be seen that this is a palindrome sequence.
Another possible action scheme is LRRLLRRRRR, but lexicographically larger than the answer scheme.
【data range】
Let ∑n denote the sum of n in all T sets of test data.
Guarantee 1≤T≤100, 1≤n, ∑n≤5×10^5 for all test points.
| Test point number | T≤ | n≤ | ∑n≤ | special properties |
|---|---|---|---|---|
| 1∼7 | 10 | 10 | 50 | none |
| 8∼10 | 100 | 20 | 1000 | none |
| 11∼12 | 100 | 100 | 1000 | none |
| 13∼15 | 100 | 1000 | 25000 | none |
| 16∼17 | 1 | 5×10^5 | 5×10^5 | none |
| 18∼20 | 100 | 5×10^5 | 5×10^5 | have |
| 21∼25 | 100 | 5×10^5 | 5×10^5 | none |
Special properties:
If we delete two adjacent and equal numbers in a each time, there is a way to puncture the sequence (eg a = [1, 2, 2, 1]).
download attachment:
palin. zip 4.25KB
Ideas:
The solution to this problem is very clear (that is, the violence is added with a bunch of optimizations and then passed), and it may be different compared to std.
At first glance, palindrome, yes, Hash - but it is not.
As we all know, the best way to understand a question is to push the sample (nonsense), so let's push it by hand.
a and b of the first set of data in sample 1:

Then hand model how to generate b:

Well, I didn't even want to watch it, so I went to do T4.
This is of course impossible, but it really doesn't make sense to look at it this way.
Think about what hints there are in the title...
b is a palindromic sequence.
Since b is an easy-to-observe palindrome sequence, let's start with b.
b If the front and back are equal, then separate the front and back?

There seems to be nothing.
No, look at the second half of b.
This consists of consecutive segments of a.
Think about it, no matter what the second half of b is composed of a continuous sequence of length n in a.
like this:

(Please ignore the inaccurate length)
With this, we can start our graceful violence.
1. Violently enumerate the position of each second half interval.
2. To judge whether it is legal.
3. Output.
Then at this time someone will come up and say, your violence is O(n^3) not O(n^2).
( n^3: Enumerate n intervals, record n numbers in each interval, and judge whether it is legal or not requires n judgments)
So we need to optimize violence.
Optimization one:
First of all, we think that if an interval in the second half has a chance to become a solution, then the necessary condition is...
Of course, this interval contains 1,2,...,n (otherwise how would you palindrome).
Then when we enumerate an interval in the second half, we can check whether it contains 1, 2,..., n by the way. If not, we will jump directly to the next interval. is the smallest lexicographically.
Of course, this optimization has huge benefits for random data, and can greatly reduce the n of judgments so that it can be regarded as O(n^2), because it reduces a lot of unnecessary judgments; but for constructed data, such as this:
1,2,...,10000,1,2,...,10000
Then this optimization is useless, and it directly degrades to O(n^3).
optimization two
So another obvious optimization: each interval is just moved from the previous interval, so you can directly make changes on the basis of the previous interval, so that the n that records the number of each interval is eliminated. Now, this is a complete O(n^2) violence. Coupled with the previous optimization, for random data, it can directly run to approximately O(n) multiplied by a large constant.
(The folk data can be AC, I have to say that it is really a bit watery) Now only 80 points are sad
Optimize the second code:
#include<bits/stdc++.h>
using namespace std;
int t,n,tot,now,check,qrs;
int num[1000001],cnt;
int in[1000001];
char ans[1000001],maybeans[1000001];
stack<int>castle_3;
stack<int>lancet_2;
int main()
{
// freopen("palin.in","r",stdin);
// freopen("palin.out","w",stdout);
cin>>t;
while(t--)
{
memset(ans,0,sizeof(ans));
memset(in,0,sizeof(in));
cnt=0;
qrs=0;
cin>>n;
for(int i=1;i<=2*n;i++)
{
cin>>num[i];
}
int l=1,r=n;
for(int i=l;i<=r;i++)
{
in[num[i]]++;
if(in[num[i]]==1)
{
cnt++;
}
}
while(r<=2*n)
{
if(cnt==n)
{
memset(maybeans,0,sizeof(maybeans));
check=0;
for(int i=1;i<l;i++)
{
castle_3.push(num[i]);
}
for(int j=2*n;j>r;j--)
{
lancet_2.push(num[j]);
}
int ll=l,rr=r;
int a,b;
int now=0;
while(ll<=rr)
{
a=-1;
b=-1;
if(castle_3.size()) a=castle_3.top();
if(lancet_2.size()) b=lancet_2.top();
if(b==num[ll])
{
maybeans[n-now]='R';
maybeans[n+1+now]='L';
lancet_2.pop();
now++;
ll++;
}
else if(b==num[rr])
{
maybeans[n-now]='R';
maybeans[n+1+now]='R';
lancet_2.pop();
now++;
rr--;
}
else if(a==num[ll])
{
maybeans[n-now]='L';
maybeans[n+1+now]='L';
castle_3.pop();
now++;
ll++;
}
else if(a==num[rr])
{
maybeans[n-now]='L';
maybeans[n+1+now]='R';
castle_3.pop();
now++;
rr--;
}
else
{
check=1;
break;
}
}
if(!check)
{
if(!qrs)
{
for(int i=1;i<=n*2;i++)
{
ans[i]=maybeans[i];
}
qrs=1;
}
else
{
int i=1;
int checks=0;
for(;i<=n*2;i++)
{
if(ans[i]!=maybeans[i])
{
checks=1;
break;
}
}
if(maybeans[i]=='L'&&checks)
{
for(int j=1;j<=n*2;j++)
{
ans[j]=maybeans[j];
}
}
}
}
while(!lancet_2.empty()) lancet_2.pop();
while(!castle_3.empty()) castle_3.pop();
}
in[num[l]]--;
if(!in[num[l]]) cnt--;
l++;
r++;
in[num[r]]++;
if(in[num[r]]==1) cnt++;
}
if(!qrs)
{
cout<<-1<<endl;
}
else
{
for(int i=1;i<=n*2;i++)
{
cout<<ans[i];
}
cout<<endl;
}
}
}Judging feasibility explanation: Use two stacks to record the first half on the left and the first half on the right, and then try to match with the second half. Add them to the maybeans plan for each successful match. For this "matching", please read carefully, because the second half of the optimization is based on this "matching".
Code explanation: The in array is used to record the number of all numbers in the interval, and the cnt is used to record the number of different numbers in the interval; it is easy to understand why the change rule of in and cnt is like this. Then let each interval generate the optimal solution: because we need to make the operation R as late as possible, then we first let the right end of the first half match first, so that for the second half interval of each enumeration, the generated answer is the local optimal solution
Then FJN, the boss of the computer room, was very sad because he did not play violent T3, and then heard that I played a randomized data that can run O(n), and the structure can run O(n^2) violent, so he came to me to look at the code.
After looking at it, he said: You can optimize it to O(n).
Yes, this is the last optimization.
Optimization three
To sum it up: enumerate the second half of the interval in reverse order, and when the first solution is found, it must be the optimal solution.
why?
First of all, we think about a basic fact: if there are 2 or more qualified second-half intervals in a, then they must have overlapping parts.
(Exception: among 1,2,3,1,2,3, the previous 1,2,3 and the next 1,2,3 do not overlap, but you can tell at a glance that the latter answer is better.)
like this:
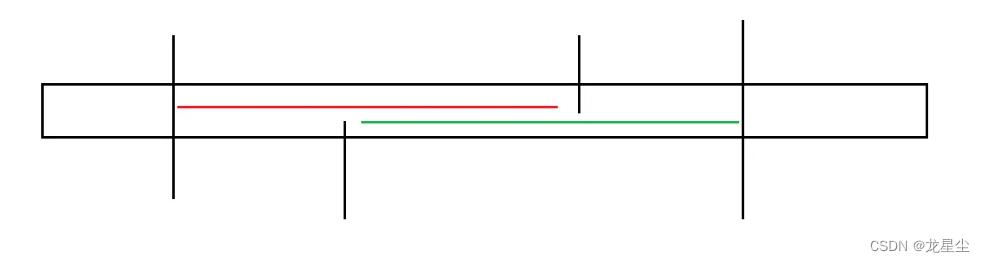
Why do they overlap? Because both intervals contain all numbers from 1 to n, and there are only two numbers from 1 to n, they must overlap.
The red and green line segments in the above figure are the two intervals in the second half that meet the requirements, so it is obvious that the parts that do not overlap are the same. (why you ask? AB=AB )
Then, when performing palindrome pairing, the red non-overlapping part must be paired with the green non-overlapping part. After all contain the same number.
Then, if we choose red as the second half of the interval, then the green non-overlapping part is popped up with the R operation. (if applicable)
If we choose green as the second half of the interval, then the red non-overlapping part is popped up with the L operation. (if available)
Looking back at the matching process, no matter whether we choose red or green, we must first match the parts that are not red or green with the overlapping parts of red and green (how can you match the middle if you don’t finish matching them), then they are in the plan The position and scheme are fixed, so there are only red and green parts that do not overlap.
If our choice is red and red is feasible, then here we will use all R for the remaining matches.
If it is green and green is feasible, then here we will use all L for the remaining matches.
Obviously, green is better.
Therefore, when the second half intervals of the two sections are both feasible, it is better to choose the latter section as the second half interval.
So, enumerate the intervals backwards, output the answer when encountering the first feasible interval, and the correctness is proved, so I am happy to cut off most of the judgment n. Combined with the previous optimizations, a method close to O(n) is created~
Of course, if you really want to specially construct data to card, of course it can degenerate to O(n^2) (sad)
Full code:
#include<bits/stdc++.h>
#define ooffof 1000001
using namespace std;
int t,n,tot,now,check,qrs;
int num[ooffof],cnt;
int in[ooffof];
char ans[ooffof],maybeans[ooffof];
int l[ooffof],r[ooffof],klk=0;;
int main()
{
// freopen("palin.in","r",stdin);
// freopen("palin.out","w",stdout);
cin>>t;
while(t--)
{
memset(ans,0,sizeof(ans));
memset(in,0,sizeof(in));
cnt=0;
qrs=0;
klk=0;
cin>>n;
for(int i=1;i<=2*n;i++)
{
cin>>num[i];
in[num[i]]++;
if(in[num[i]]==1)
{
cnt++;
}
if(i>n)
{
in[num[i-n]]--;
if(in[num[i-n]]==0)
{
cnt--;
}
}
if(cnt==n)
{
l[++klk]=i-n+1;
r[klk]=i;
}
}
for(int q=klk;q>=1;q--)
{
memset(maybeans,0,sizeof(maybeans));
check=0;
int ll=l[q],rr=r[q],sl=l[q]-1,rl=r[q]+1;
int a,b;
int now=0;
while(ll<=rr)
{
a=-1;
b=-1;
if(sl>=1) a=num[sl];
if(rl<=2*n) b=num[rl];
if(b==num[ll])
{
maybeans[n-now]='R';
maybeans[n+1+now]='L';
rl++;
now++;
ll++;
}
else if(b==num[rr])
{
maybeans[n-now]='R';
maybeans[n+1+now]='R';
rl++;
now++;
rr--;
}
else if(a==num[ll])
{
maybeans[n-now]='L';
maybeans[n+1+now]='L';
sl--;
now++;
ll++;
}
else if(a==num[rr])
{
maybeans[n-now]='L';
maybeans[n+1+now]='R';
sl--;
now++;
rr--;
}
else
{
check=1;
break;
}
}
if(!check)
{
for(int i=1;i<=n*2;i++)
{
cout<<maybeans[i];
qrs=1;
}
cout<<endl;
}
if(qrs)
{
break;
}
}
if(!qrs)
{
cout<<-1<<endl;
}
}
}Summarize:
T3, which is simpler than T2, is not much in this life...
It's a veritable sign-in question...
However, it is a very difficult process to optimize from violent n^3 to n.
Topic link:
[CSP-S 2021] Palindrome - Luogu https://www.luogu.com.cn/problem/P7915