GitHub - yuxiangsun/RTFNet: RGB-Thermal Fusion Network for Semantic Segmentation of Urban Scenes
GitHub - haqishen/MFNet-pytorch: MFNet-pytorch, image semantic segmentation using RGB-Thermal images
GitHub - huaaaliu/RGBX_Semantic_Segmentation
GAMUS: A Geometry-Aware Multimodal Semantic Segmentation Benchmark for Remote Sensing Data
The geometric information in the normalized digital land surface model is highly correlated with the semantic categories of land cover. Jointly exploiting two modalities (RGB and nDSM (height)) has great potential to improve segmentation performance. However, it remains an underexplored field in remote sensing due to the following challenges. First, the size of existing datasets is relatively small, and the limited diversity in existing datasets limits the power of validation. Second, comprehensive evaluation and analysis of existing multimodal fusion strategies of convolutional networks and Transformer-based networks based on remote sensing data. Furthermore, we propose a novel and effective Transformer-based intermediary multi-modal fusion (TIMF) module, Transformer-based intermediary multi-modal fusion (TIMF).
The GAMUS dataset contains 11507 blocks collected from five different cities: Oklahoma, Washington DC, Philadelphia, Jacksonville, and New York City. These image tiles were collected using the data collection process described above and are shown in Figure 2. Each RGB image tile has a corresponding nDSM map with a spatial size of 1024×1024. We divide all image tiles into three subsets: a training set with 6304 tiles, a validation set with 1059 tiles and a test set with 4144 tiles. All image pixels are annotated with six different land cover types, including 1. 2. Low vegetation; 3. Buildings; 4. Water; 5. Roads; 6. Trees. The height statistics provided in nDSM are shown in Fig. 3. It can be seen from the figure that there is an obvious long-tailed distribution of heights, that is, the number of pixels with lower height values is significantly more than the number of pixels with higher height values. We also display statistics for the spatial distribution by averaging
CNN-based fusion methods: illustration of five different multimodal fusion paradigms, including 1) single modality, where only the RGB modality is used; 2) 1) single modality, where only the height modality is used; 3) multimodal modal early fusion, where image-level fusion is performed; 4) multimodal feature fusion, where features from different modalities are fused; 5) multimodal late fusion, where segmentation results from different modalities are combined. 

Illustration of six different multimodal fusion paradigms for Transformer-based fusion methods, including 1) single modality, where only RGB modality is used; 2) single modality, where only height modality is used; 3) multimodal early stage fusion, where image-level fusion is performed; 4) multimodal cross-feature fusion, where features from different modalities are fused via a cross-attention mechanism; 5) multimodal post-fusion, where segmentation results from different modalities are combined; 6) intermediate Fusion, where the proposed TIMF module is illustrated.


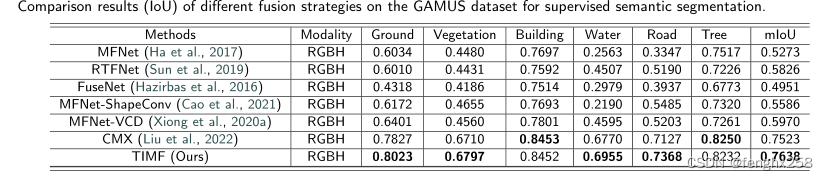
Comparison of different fusion strategies for supervised semantic segmentation on the GAMUS dataset (IoU)