2021
Summary
Dominant multimodal named entity recognition (MNER) models do not take full advantage of the fine-grained semantic correspondence between different modal semantic units, which has the potential to refine multimodal representation learning.
introduction
How to make full use of visual information is one of the core issues of MNER, which directly affects the performance of the model.
Attempts:
(1) Encode the entire image into a global feature vector (Fig. 1(a)), which can be used to enhance each word representation (Moon, Neves, and Carvalho 2018), or guide words to learn visually perceptual representations (Lu 2018; Zhang et al. 2018); (就是节点级分类那种实现方式,比如一张人脸图像整体得到一个嵌入)
(2) segment the entire image into multiple regions evenly (Fig. 1(b)), and interact with text sequences based on the transformation framework (Yu et al. 2020). (就是图级实现的一种方式,类似超像素图块,ZSL还有ViT说的那个patch那种处理)
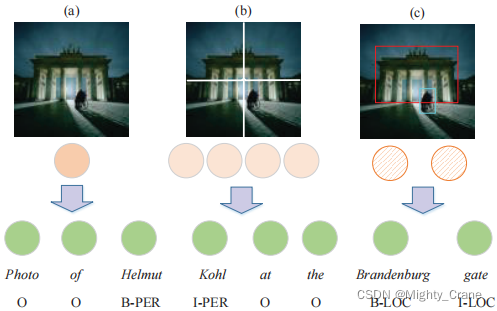
They do not make full use of the fine-grained semantic correspondence between semantic units in the input sentence-image pair.
For example, a map is implicit global information,
and b map is local information that contains multiple averagely segmented regions, but it is still implicit.
These two kinds of information propagate the cue of "gate" to the textual representation differently. The failure to develop this important thread may be due to two major challenges: 1) how to construct a unified representation to bridge the semantic gap between two different modalities; 2) how to achieve semantic interaction based on the unified representation.
So use c(这种目标检测就有点任务特定了,是图像中明确可以boundingbox的那种)
method
composition
node
Text or words as nodes,
vision is the bounding box
even side
The intra nodes are fully connected, and the inter nodes are connected corresponding to the same thing
fusion
intra self-attention, inter gating(和a novel那篇一毛一样)