hive principle
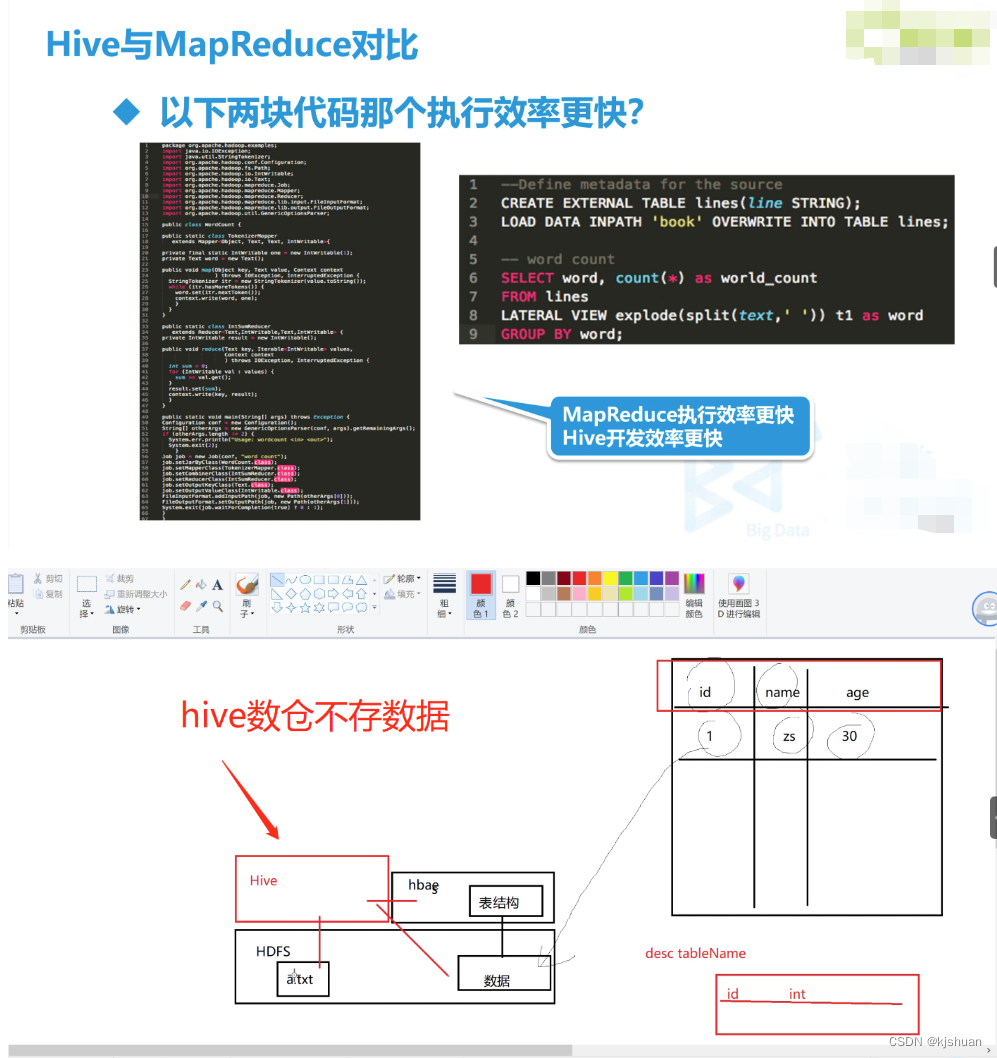
Hive is a data warehouse tool based on Hadoop . It can map structured data files into a database table and provide complete SQL query functions. It can convert SQL statements into MapReduce tasks for running. Its advantage is that the learning cost is low, simple MapReduce statistics can be quickly realized through SQL-like statements , and there is no need to develop special MapReduce applications. It is very suitable for statistical analysis of data warehouses . Hvie is a data warehouse infrastructure built on Hadoop. It provides a series of tools that can be used to perform data extraction transformation loading (ETL), which is a mechanism that can store, query and analyze large-scale data stored in Hadoop. Hive defines a simple SQL-like query statement called HQL, which allows users familiar with SQL to query data. At the same time, this language also allows developers familiar with MapReduce to develop custom mappers and reducers to handle complex analysis tasks that the built-in mappers and reducers cannot complete. Since Hive uses SQL's query language HQ L, it is easy to understand Hive as a database. In fact, from a structural point of view, apart from having similar query languages, Hive and database have nothing in common. This article will explain the differences between Hive and databases from many aspects. Databases can be used in Online applications, but Hive is designed for data warehouses. Knowing this will help you understand the characteristics of Hive from an application perspective.

beeline configuration
beeline configuration cd /opt/soft/hive110/conf/ vim hive-site.xml hive's hive-site.xml configuration file <property> <name>hive.server2.authentication</name> <value>NONE</value> <description> Expects one of [nosasl, none, ldap, kerberos, pam, custom]. Client authentication types. NONE: no authentication check LDAP: LDAP/AD based authentication KERBEROS: Kerberos/GSSAPI authentication CUSTOM: Custom authentication provider (Use with property hive.server2.custom.authentication.class) PAM: Pluggable authentication module NOSASL: Raw transport </description> </property> <property> <name>hive.server2.thrift.client.user</name> <value>root</value> <description>Username to use against thrift client</description> </property> <property> <name>hive.server2.thrift.client.password</name> <value>root</value> <description>Password to use against thrift client</description> </property> core-site.xml configuration of hadoop <configuration> <!--Specify the address of namenode--> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.11.207:9000</value> </property> <!--Used to specify the storage directory for files generated when using hadoop --> <property> <name>hadoop.tmp.dir</name> <!--<value>file:/usr/local/kafka/hadoop-2.7.6/tmp</value>--> <value>file:/home/hadoop/temp</value> </property> <!--Used to set the maximum time for checkpoint backup logs--> <!-- <name>fs.checkpoint.period</name> <value>3600</value> --> <!-- Represents the proxy user who sets hadoop --> <property> <!--Indicates the group the proxy user belongs to--> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <!--Indicates that any node using the proxy user hadoop of the hadoop cluster can access the hdfs cluster--> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> </configuration>

sql deduplication
1 distinct
select distinct name,age from test
2 group by
select name,age from test group by name,age;
3 Pseudo column deduplication
select id,name,age from test t1 where t1.rowid in (select min(rowid) from test t2 where t1.name=t2.name and t1.age=t2.age);
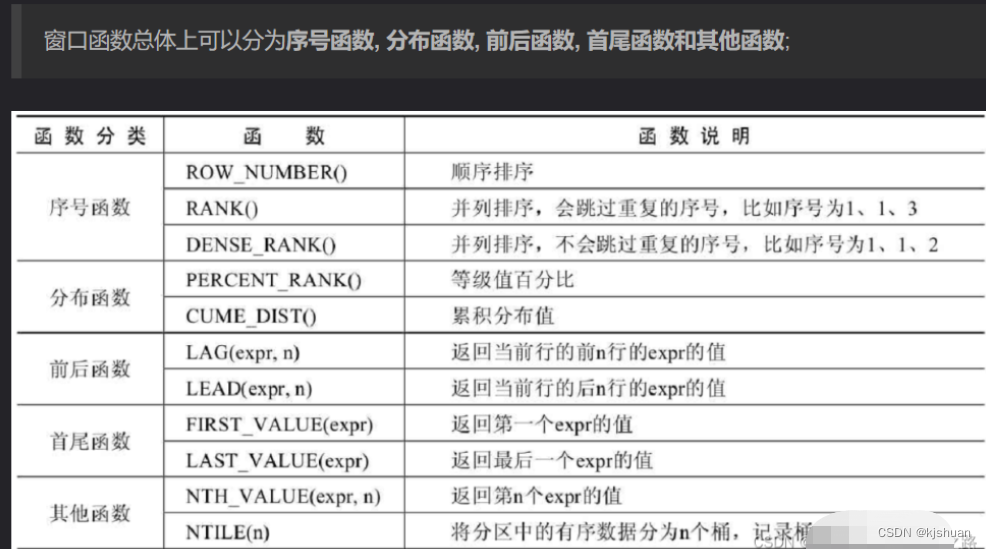
4 window function over (partition by)
select t.id ,t.name,t.age from (select row_number() over(partition by name,age order by age) rank,test.* from test)t where t.rank = 1;
important point
The above are the four common deduplication methods in Oracle. The first method is not recommended because the efficiency is very low when the amount of data is very large. In Mysql versions before 8.0, window functions are not supported, so it is recommended to use group by to remove duplicates , you can happily use window functions after 8.0 . Applicable scenarios for window functions: In the scenario where each record in the grouped statistical results is calculated, it is better to use the window function. Note, it is each record!! Because the result of MySQL's ordinary aggregate function (such as group by) is each group There is only one record!!!

hive installation
cd /opt/jar
tar -zxf hive-1.1.0-cdh5.14.2.tar.gz
mv hive-1.1.0-cdh5.14.2 /opt/soft/hive110
cd /opt/soft/hive110/conf
vim hive-site.xml #Add the following code
====================================
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
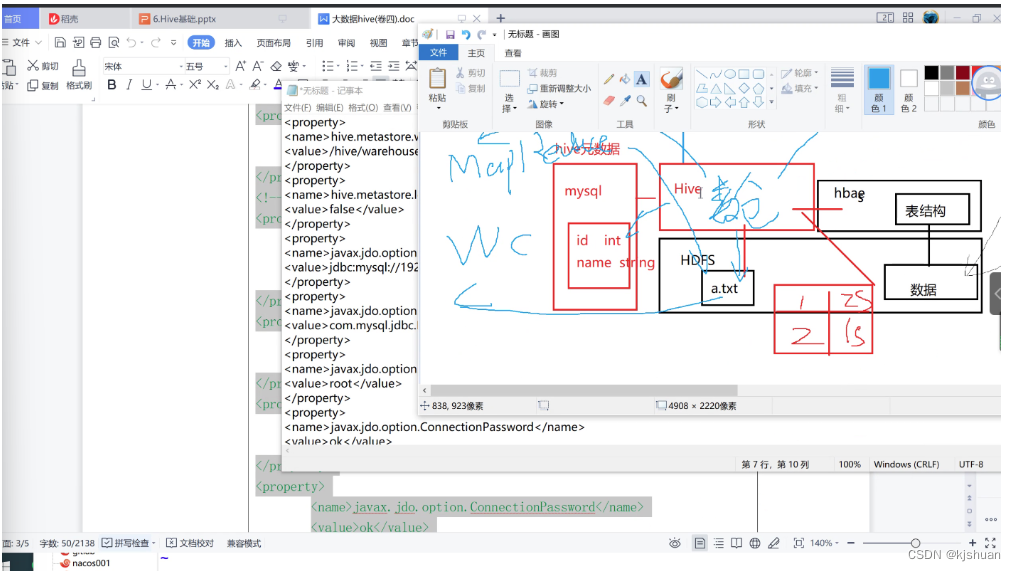
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.64.210:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>3090_Cmok</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>root</value>
</property>
</configuration>
<!-- mysql database password <value>3090_Cmok</value> Use your own 3090_Cmok>
<!-- password=root equals no password login to facilitate connection>
<!-- If it is a remote mysql database, you need to write the remote IP or hosts here -->
====================================
2 hadoop configuration core-site.xml (note that there are 5 in total, no more or less!!!)
cd /opt/soft/hadoop260/etc/hadoop/
vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.64.210:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/temp</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
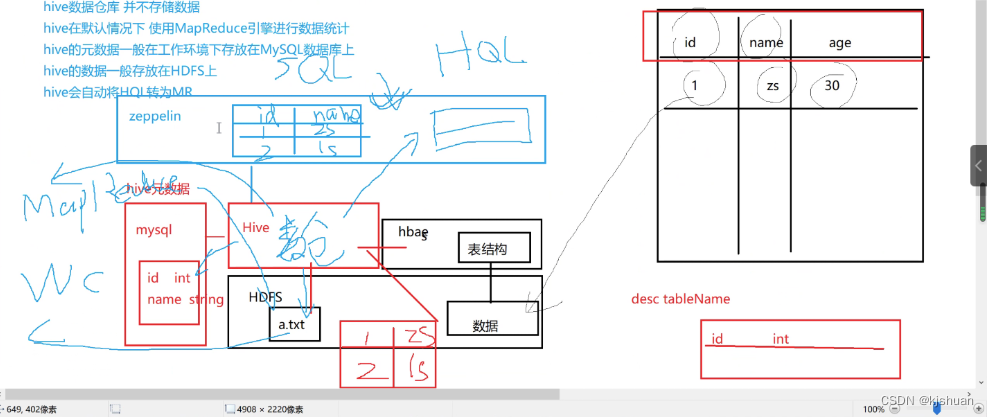
3. Drag in the mysql driver
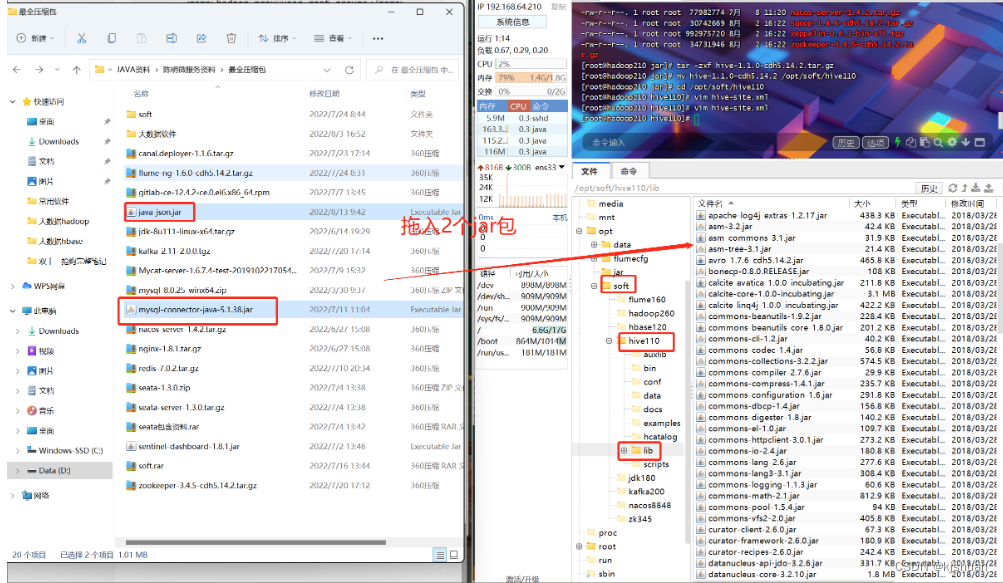
4. Configure environment variables
vim /etc/profile
#Hive
export HIVE_HOME=/opt/soft/hive110
export PATH=$PATH:$HIVE_HOME/bin
:wq
source /etc/profile
5Initialize the database
schematool -dbType mysql -initSchema
6. Start
zkServer.sh start start-all.sh hive --service metastore hive --service hiveserver2 hive
7.hql
show databases; create database mydemo; use mydemo; create table userinfos(userid int,username string,birthday string); insert into userinfos values(1,'zs',30); select * from userinfos;
Zeppelin installation
tar -zxf zeppelin-0.8.1-bin-all.tgz -C /opt/soft/ hdfs dfs -cat /hive/warehouse/mydemo.db/userinfos/000000_0 cd /opt/soft/ ls mv zeppelin-0.8.1-bin-all/ zeppelin081 ls cd /opt/soft/zeppelin081/conf/ ls cp zeppelin-site.xml.template zeppelin-site.xml vim zeppelin-site.xml ============================== <property> <name>zeppelin.helium.registry</name> <value>helium</value> </property> ============================== cp zeppelin-env.sh.template zeppelin-env.sh vim zeppelin-env.sh ============================== export JAVA_HOME=/opt/soft/jdk180 export HADOOP_CONF_DIR=/opt/soft/hadoop260/etc/hadoop ============================== cp /opt/soft/hive110/conf/hive-site.xml /opt/soft/zeppelin081/conf/
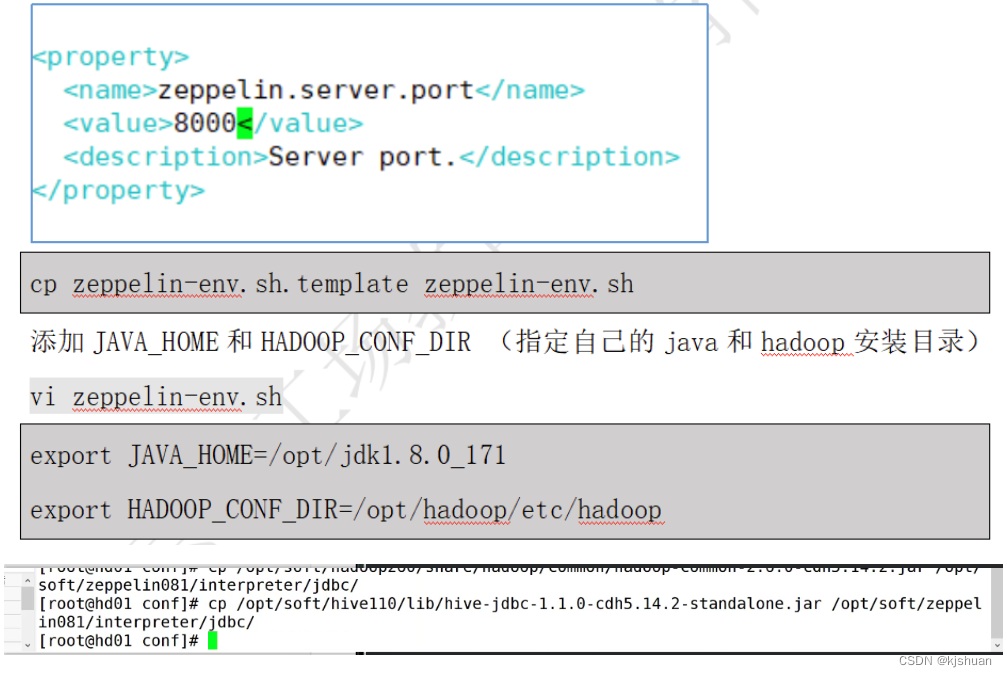
1.Copy files
cp /opt/soft/hadoop260/share/hadoop/common/hadoop-common-2.6.0-cdh5.14.2.jar /opt/soft/zeppelin081/interpreter/jdbc/ cp /opt/soft/hive110/lib/hive-jdbc-1.1.0-cdh55.14.2-standalone.jar /opt/soft/zepplin081/interpreter/jdbc/
2. Configure environment variables
vim /etc/profile
#Zeppelin
export ZEPPLIN_HOME=/opt/soft/zeppelin081
export PATH=$PATH:$ZEPPELIN_HOME/bin
:wq
source /etc/profile
3. Start
cd /opt/soft/zeppelin081/bin/ ./zeppelin-daemon.sh start http://192.168.64.210:8080/ #Enter the address in the browser to enter zeppelin#http://192.168.64.210:50070/ #hadoopView


cd /opt/ mkdir dir rm -rf dir mkdir data
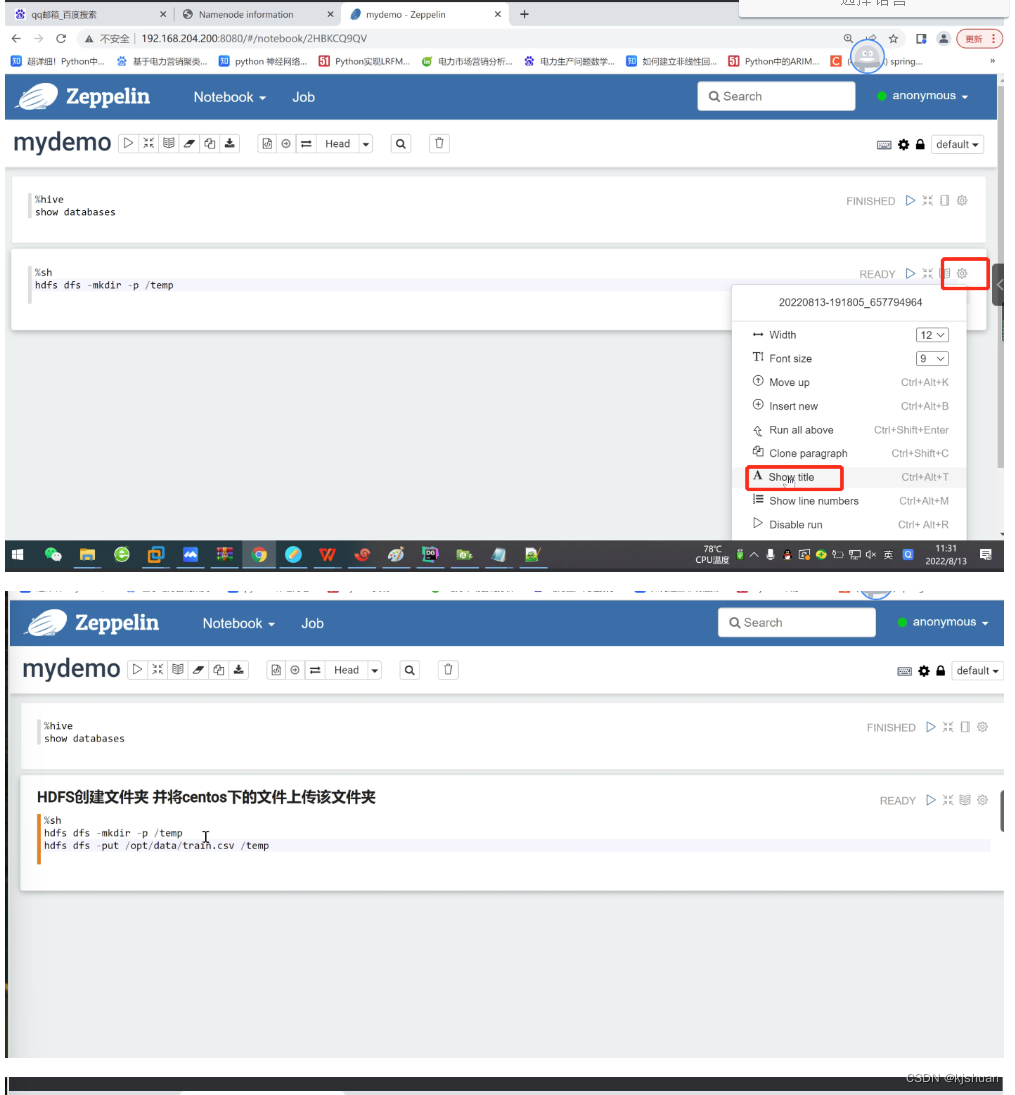



%hive
create external table mydemo.train(
userid string,
eventid string,
invited string,
partytime string,
interested string,
not_interested string
)
row format delimited fields terminated by ','
location '/temp'
TBLPROPERTIES("skip.header.line.count"="1")
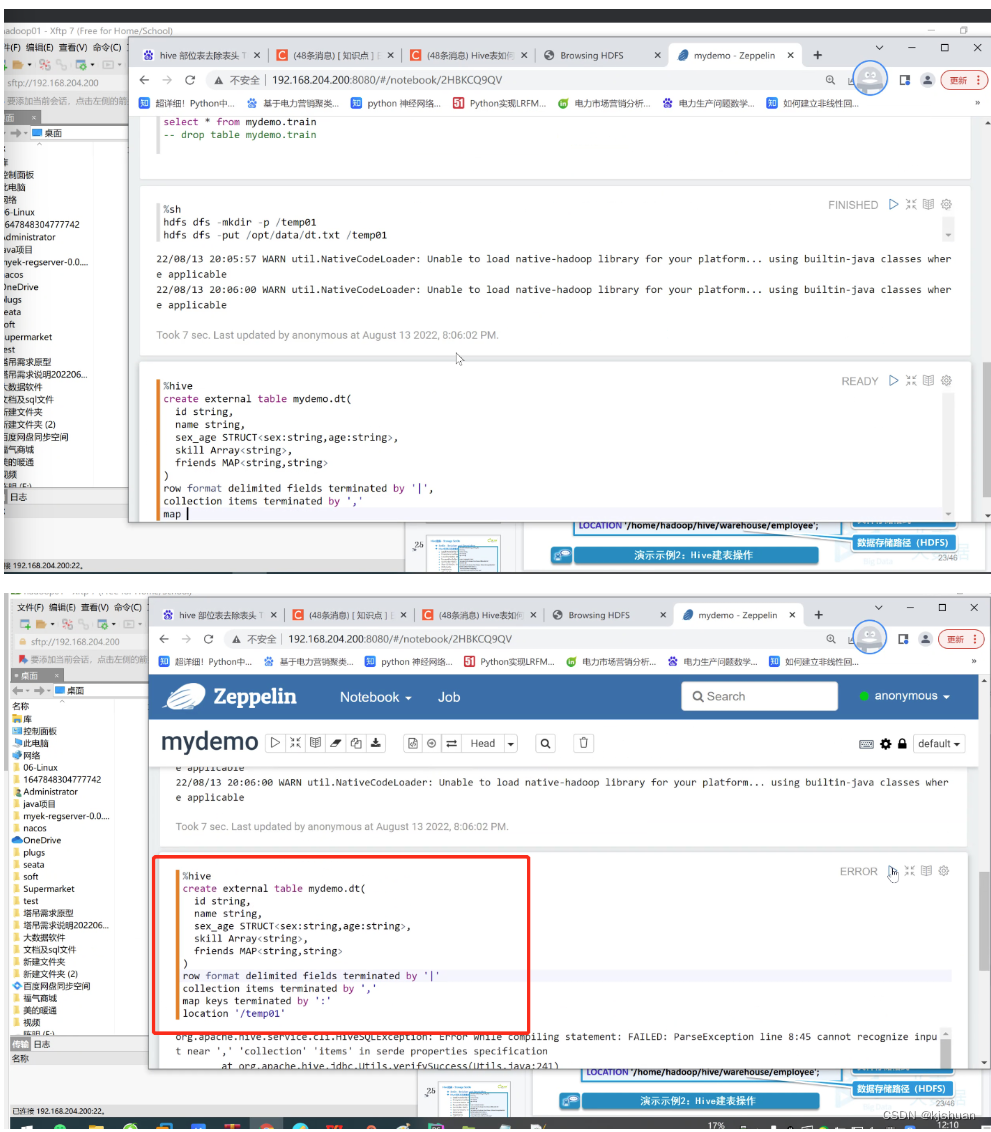
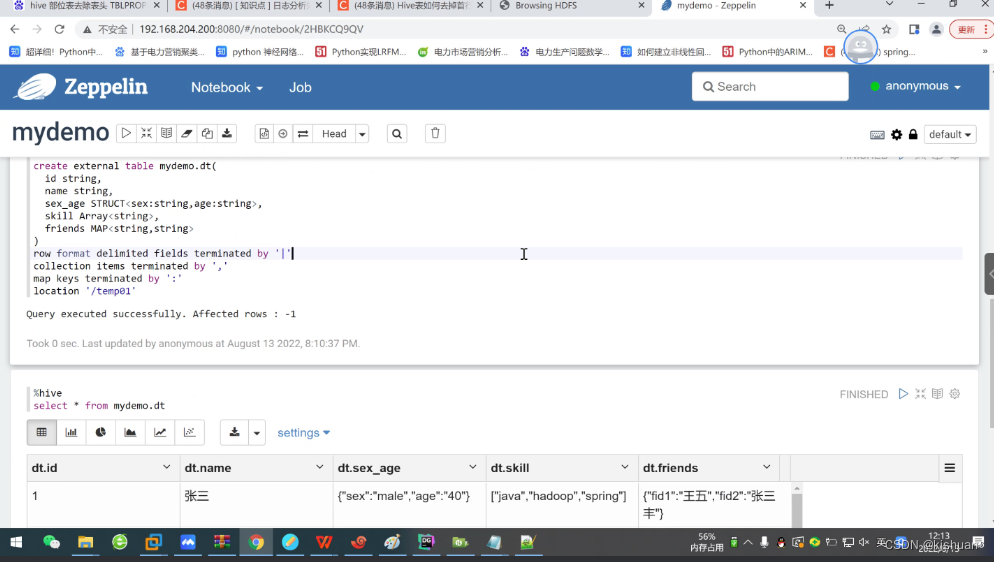
1 | zhangsan | male,40 | java,hadoop,spring | fid1:wangwu,fid2:zhangsanfeng 2 | lisi | female,30 | linux,centos | fid1:xiaolifeidao
%hive
create external table mydemo.train(
userid string,
eventid string,
invited string,
partytime string,
interested string,
not_interested string
)
row format delimited fields terminated by ','
location '/temp'
TBLPROPERTIES("skip.header.line.count"="1")

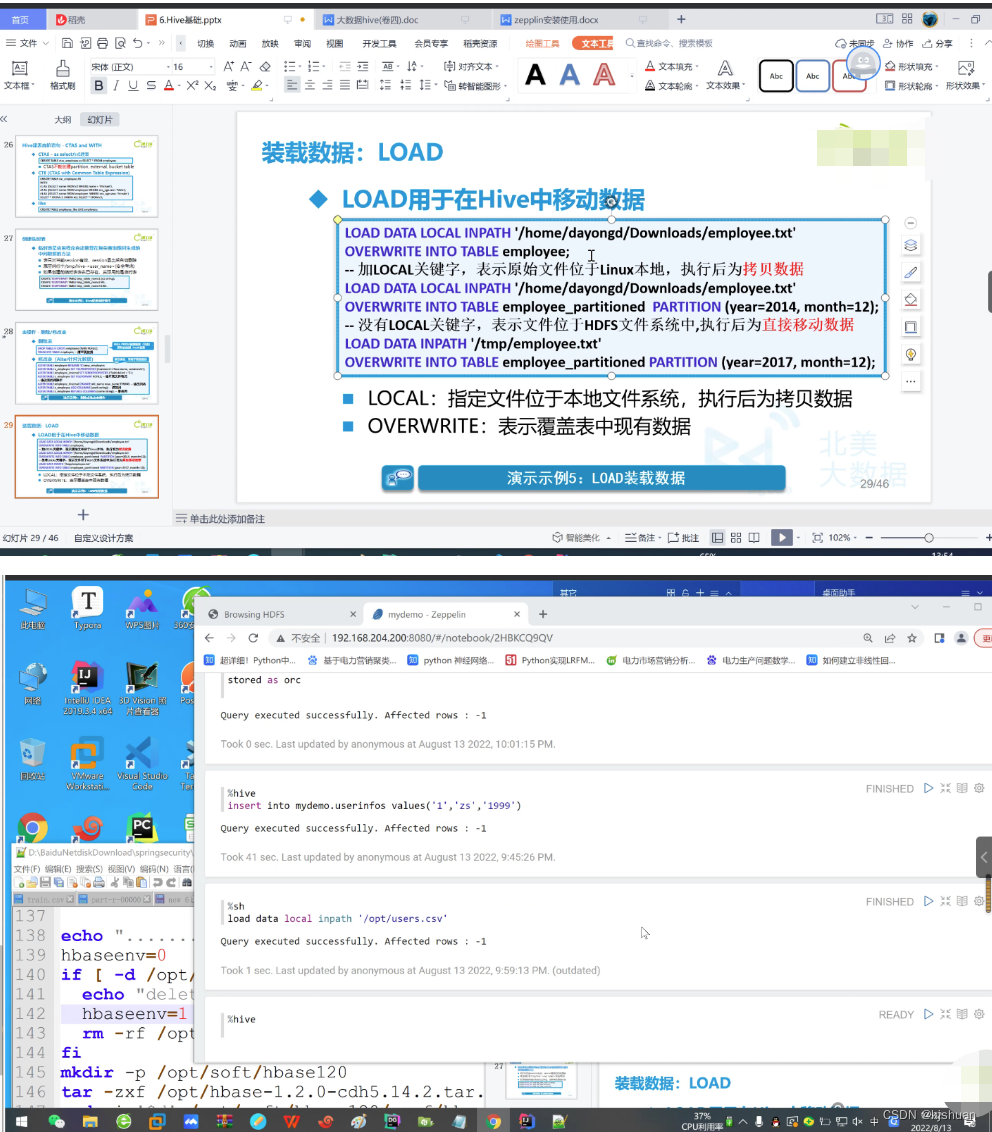



#Static installment loading of data requires users to specify partitions themselves #hive load data local inpath