" This article and the previous article review recent research progress on the problem of hallucinations in language models, mainly focusing on research after the release of ChatGPT. The article discusses how to evaluate, track and eliminate hallucinations, and explores existing challenges and future directions. Hope This article can provide valuable resources for friends who are interested in LLM illusion problems and promote the practical application of LLM. "

01
—
The previous article " Song of the Siren in the Ocean of Artificial Intelligence: A Review of Illusion Research in Large-scale Language Model LLM (1) " talked about the types of hallucinations in large-scale artificial intelligence, their causes and evaluation standards. This article continues to introduce the current research on hallucinations in large-scale language models LLM Research and efforts to mitigate and avoid hallucinations.
As mentioned in the previous article, the generation of mitigating hallucinations runs through the three stages of large model pre-training, development and application.
02
—
Relief during the pre-training phase
The knowledge of LLM is mainly obtained in the pre-training stage. Noisy data in the pre-training corpus may destroy the parameter knowledge of LLM and cause hallucinations.
Therefore, reducing the pre-training corpus of unverifiable or unreliable data may be an intuitive way to alleviate the hallucination. Studies have shown that the factual knowledge acquired by LLM can be traced back to the data it was trained on.
Before the LLM era, people manually cleaned training data to reduce hallucinations. Both Gardent et al. and Wang used manual correction methods to effectively reduce hallucinations. Likewise, the process of manual refining of text within existing table-to-text data sets significantly reduces factual illusions. Parikh et al. constructed a data set by modifying sentences in Wikipedia and also achieved improved results.
With the advent of the LLM era, manual screening of training data has become increasingly challenging due to the huge size of the pre-training corpus.
As shown in the figure below, the data volume of the corpus used in several common large model pre-training
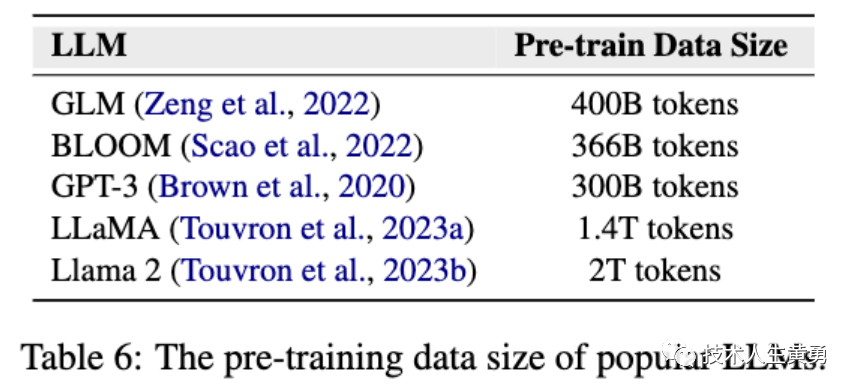
Llama2 has reached a data scale of approximately two trillion tokens. Therefore, compared with manual sorting, currently more practical methods are to automatically select reliable data or filter out noisy data.
GPT-3’s pre-training data is cleaned by using similarities.
Falcon extracts high-quality data from the network through clever heuristic rules and demonstrates that appropriately graded relevant corpora can generate powerful LLMs.
Llama2 extracts data from highly trusted sources such as Wikipedia when building its pre-training corpus.
Some studies add topic prefixes before sentences in factual documents, so that each sentence is treated as an independent fact during pre-training, with the document name as the topic prefix. Practical results show that this method improves the performance of LLM on the TruthfulQA evaluation benchmark (an illusion evaluation benchmark).
In short, during the pre-training process, the key to reducing the "halo" phenomenon is to effectively organize the pre-training corpus. Given the huge size of existing pre-training corpora, current research mainly adopts simple heuristic rules to select and filter data . A possible future research direction is to design more effective selection or filtering strategies.
03
—
Relief in SFT stage
SFT: Self-Supervised Fine-Tuning, self-supervised fine-tuning. A common approach is to have the model generate a relevant task based on the input data, and then use the output of this task to train the model.
Current LLMs typically undergo a process of supervised fine-tuning (SFT) to leverage the knowledge they gain from pre-training and learn how to interact with users. The general steps of SFT are to first annotate or collect a large amount of task guidance data, and then use maximum likelihood estimation (MLE) to fine-tune the pre-trained LLMs. By employing carefully designed SFT strategies, many recent studies claim to have constructed LLMs comparable to ChatGPT.
Maximum Likelihood Estimation (MLE) is a commonly used parameter estimation method in statistics. Its basic idea is to maximize the probability of observation data by adjusting the parameters of the model given the observation data, that is, to find the parameter values that are most likely to produce observation data.

In order to reduce the hallucinations in the SFT stage, it can be done by filtering the training data. As shown in the figure above, the SFT data volume is relatively small (maximum 210K), and both manual and automatic filtering are viable options.
Some studies use instruction tuning data sets annotated by human experts, or utilize LLMs as evaluators or design specific rules to automatically select high-quality instruction tuning data.
Experimental results show that in hallucination-related benchmarks, LLMs fine-tuned using filtered instruction data have higher levels of authenticity and factuality (such as Truth-fulQA) than LLMs fine-tuned using unfiltered data.
In addition, some studies have proposed integrating domain-specific knowledge into SFT data, aiming to reduce hallucinations due to lack of relevant knowledge.
The SFT process may cause hallucinations in LLMs because they learn through behavioral cloning. Behavioral cloning is a concept in reinforcement learning that simply imitates the behavior of an expert without learning a strategy to achieve the final goal.
The SFT process of LLMs can be viewed as a special case of behavioral cloning, where they learn the format and style of interaction by imitating human behavior. However, although LLMs have encoded a large amount of knowledge into their parameters, there is still knowledge beyond their capabilities. Therefore, performing SFT by cloning human behavior may cause hallucinations in LLMs.
Behavior cloning is a concept in reinforcement learning. The problem is that behavior cloning simply imitates behavior without learning a strategy to achieve the ultimate goal.
The SFT process of LLMs can be regarded as a special case of behavioral cloning. By cloning the human behavior in the SFT process, when answering questions, the model will tend to respond positively without considering the scope of its own knowledge. This may cause the model to produce incorrect answers when answering questions related to unlearned knowledge.

To solve this problem, some honest samples can be introduced, that is, responses that admit inability to answer. By tuning on these honest examples (referring to responses that admit one's incompetence, such as "Sorry, I don't know", which is what we often call refusal), the model can learn to refuse to answer specific questions, thus reducing the number of incorrect answers . .
To reduce the hallucinations in the SFT stage, filtering the training data is one approach. A recent manual inspection found a large number of illusory answers in some commonly used synthetic SFT data, which requires researchers to pay attention when building self-guided SFT data sets.
Summary: The SFT process may introduce hallucinations because it forces LLMs to answer questions that are beyond their knowledge. Collating training data is a way to reduce hallucinations during the SFT stage and can be manually curated by human experts. Another option uses honesty-oriented SFT as a solution.
There are two main problems with the honesty-oriented SFT method:
It has limited generalization ability for out-of-distribution (OOD: Out-of-Distribution, indicating data outside the data distribution seen by the model when training the model).
Honest samples only reflect the annotators' incompetence and uncertainty, not the knowledge boundaries of LLMs.
These challenges make solving this problem in the SFT process less than ideal.
04
—
Remission of RLHF stage
RLHF: Reinforcement Learning from Human Feedback, that is, reinforcement learning from human feedback.
In RLHF, humans provide a signal to evaluate model performance, such as a reward signal, to guide the training of the model. This allows the model to more efficiently explore and improve policies during the learning process.
Many researchers now try to further improve supervised fine-tuning LLMs through reinforcement learning with human feedback . This process consists of two steps:
Train a reward model as a proxy for human preference, aiming to assign an appropriate reward value to each text;
Use the RLHF algorithm to fine-tune LLMs to maximize the output of the reward model.
Human feedback can bridge the gap between machine-generated content and human preferences, helping language models stay consistent with desired standards. The currently commonly used standard is "3H", which is Help, Honest and Harmless. Honesty is about reducing illusions in language model answers.
Existing large language model LLMs, such as InstructGPT, ChatGPT, GPT4 (Ope-nAI, 2023b) and Llama2-Chat, already take this aspect into account in the RLHF process.
For example, GPT4 uses synthetic hallucination data to train reward models and perform RL (reinforcement learning), thereby increasing the accuracy of Truth-fulQA (hallucination benchmark) from about 30% to 60%.
Additionally, process supervision can be used to detect and reduce hallucinations in reasoning tasks and provide feedback for each intermediate reasoning step.
As mentioned in the previous section: During the SFT stage, the phenomenon of behavioral cloning may lead to hallucinations. Some researchers have tried to solve this problem by integrating real samples into raw SFT data. However, this approach has some limitations: such as unsatisfactory out-of-distribution (OOD) generalization ability and inconsistency between human and LLM knowledge boundaries.
In order to solve this problem, Schulman (2023) designed a special reward function in the RLHF stage to alleviate the illusion. The details are shown in the figure below. The core idea is to encourage LLM to challenge premises, express uncertainty, and provide uninformative answers.

In reinforcement learning, a large model LLM interacts with the environment to learn a policy that helps the large model obtain the maximum cumulative reward in a specific task. The large model continuously tries different actions during the learning process and adjusts its strategy based on feedback from the environment.
“Unhedged/Hedged” indicates that the LLM provides an answer in a positive or hesitant tone.
"Correct/Wrong" means the answer is correct or wrong.
"Uninformative" means a safe answer like "I don't know."
As can be seen from the reward scores in the figure above, this reward function provides positive rewards for correct answers. Regardless of whether the model uses a positive or hesitant tone, this reward strategy encourages the model to maximize the exploration of the boundaries of knowledge while preventing The model answers questions beyond its capabilities.
This new learning method, honesty-oriented RL, can help the language model freely explore knowledge boundaries and improve its generalization ability for OOD situations, while reducing the need for manual annotation and the annotator guessing the knowledge boundaries. Difficulties.
Reinforcement learning can help language models refuse to answer questions beyond their capabilities and avoid making up false answers when exploring the boundaries of knowledge. However, there are challenges with this approach, such as the possibility of being overly conservative, leading to an imbalance in the balance between helpfulness and honesty.

As shown in the picture above, this is a real example of the over-conservative phenomenon of ChatGPT (July 2023 version): in the first Q&A, the user asked ChatGPT to introduce the movie "The Only Thing", and then asked what type "The Only Thing" is Movie?
But ChatGPT refused to answer what it already knew was a fairly clear answer: "It's a dramatic movie." Because in the first answer, ChatGPT has already stated in its answer that it has the answer to this question in its knowledge: the part marked in red in the screenshot.
05
—
Relief for the generative inference phase
Mitigating hallucinations during the inference phase may be more cost-effective and controllable than mitigating hallucinations during the training phase. Therefore, most existing research focuses in this direction: designing decoding strategies, leveraging external knowledge.
1. Design decoding strategy
The decoding strategy determines how we select output tokens from the probability distribution generated by the model. The paper proposes three improved decoding strategies: fact core sampling decoding, inference-temporal intervention (ITI) method, and context-aware decoding (CAD) strategy.
1. Fact core sampling decoding
Lee et al. performed a de facto evaluation of the content generated by LLMs and found that core sampling (i.e., top-p sampling) was inferior to greedy decoding in terms of de facto. They believe that this performance may be attributed to the randomness introduced by top-p sampling to increase diversity, but may inadvertently lead to hallucinations because LLMs tend to fudge information to generate different responses.
Top-p core sampling is a sampling method for generating text or sequences that is often applied to natural language processing tasks. p represents a probability threshold between 0 and 1.
First, the words in the vocabulary are sorted according to the output probability distribution of the model, and then the words with the highest probability sum are selected until the cumulative probability of these words exceeds the threshold p, forming a candidate word set. Next, the model randomly samples from the set of candidate words to generate the final words. This process can be performed at each time step to generate the complete sequence.
The advantage of Top-p core sampling is its ability to maintain diversity without producing an output that is too scattered or incoherent. By dynamically adjusting the threshold p, the constraints can be relaxed when diversity is required and tightened when tighter control is required. This sampling method is often used in natural language generation tasks, such as text generation and dialogue generation, helping the generator to maintain diversity while keeping the output reasonable.
Therefore, they introduced a decoding algorithm called "fact core sampling" , which aims to balance diversity and factuality more effectively by taking advantage of top-p and greedy decoding.
2. Reasoning time intervention
Li et al. proposed a novel Iterative Time Intervention (ITI: Iterative Time Intervention) method to improve the authenticity of LLM. This approach is based on the assumption that LLM has potentially interpretable substructures related to facts . The ITI method consists of two steps:
Fit a binary classifier on each attention head of the LLM to identify a set of heads with higher linear detection accuracy in answering factual questions,
Move model activations along these fact-relevant directions during reasoning.
The ITI method significantly improves performance on the TruthfulQA benchmark.
3. Context-aware decoding CAD
Other studies have explored the problem of language models in retrieval-enhanced settings and found that language models sometimes fail to pay sufficient attention to retrieved knowledge when processing downstream tasks, especially when the retrieved knowledge conflicts with parameterized knowledge.
In order to solve this problem, the research proposes a context-aware decoding strategy, namely Context-Aware Decoding, CAD method . By comparing two generation probability distributions, the language model is prompted to pay more attention to contextual information, thereby reducing factual hallucinations in downstream tasks. . Experimental results show that the CAD method effectively improves the language model's ability to utilize the retrieved knowledge.
Designing decoding strategies to alleviate the hallucinations of LLM during inference does not require large-scale retraining or adjustment of the model and is usually a plug-and-play approach. Therefore, this approach is easy to deploy and has potential for practical applications.
For this approach, most existing work requires access to token-level output probabilities: this means we want to know the model’s predicted probability for each possible word or symbol at each position when generating text. This is crucial for selecting the next word or character.
However, due to limitations in computing resources and model design, most existing large language models (LLMs) may not be able to provide complete token-level output probability information. Instead, they may only return a generated sequence without providing probabilistic information for all words at each position. This makes some tasks that require fine-grained control potentially subject to some limitations.
For example, models like ChatGPT return generated content via an API, but do not provide a detailed probability distribution of all possible words at each position.
Therefore, when designing decoding strategies, researchers may need to take into account the model's output limitations in order to select an appropriate strategy to generate text.
2. Use external knowledge
Use external knowledge as auxiliary evidence to help LLMs provide authentic answers. The method consists of two steps:
The first step is to acquire knowledge : accurately acquire knowledge related to user instructions;
The second step is to leverage knowledge : use this knowledge to guide the generation of answers.

Table 10: Summary of some recent research on alleviating hallucinations with the help of external knowledge. QA (Question and Answer), FV (Fact Verification) and LM (Language Modeling).
1. Acquire knowledge
LLMs internalize a large amount of knowledge through extensive pre-training and fine-tuning, which can be called parameter knowledge. However, incorrect or outdated parameter knowledge can easily lead to hallucinations. To solve this problem, researchers propose to obtain reliable, up-to-date knowledge from reliable sources as hot-patching for LLMs. The two main sources of this knowledge are trusted sources and human experts.
Two ways to improve the authenticity of LLM: internal searches and external tools.
Internal retrieval: Existing work mainly retrieves information from external knowledge bases, including large-scale unstructured corpora, structured databases, Wikipedia, etc. and the entire Internet. The process of retrieving information usually employs various sparse (such as BM25) or dense (such as PLM-based methods) searchers.
Sparse retriever (such as BM25): Sparse retriever is a statistical and rule-based method that performs information retrieval by calculating the similarity between query terms and documents. BM25 is a commonly used sparse retrieval model that evaluates the relevance of documents based on information such as term frequency and document frequency between query terms and documents. This approach usually uses less feature or lexical information for retrieval, hence it is called sparse.
Dense retriever (such as PLM-based approach): Dense retriever is a neural network model-based approach that uses a pretrained large language model (PLM, Pretrained Language Model) to understand and process the semantics between queries and documents information. These methods use neural networks to model the representation of text, often involving training on a large number of parameters. Because they utilize a large number of parameters and deep neural network structures, they are called dense methods.
External tools include FacTool and CRITIC, which can provide valuable evidence to enhance the authenticity of LLM.
Among them, FacTool targets specific downstream tasks and utilizes different tools to help detect hallucinations in LLM, such as a search engine API for knowledge-based quality assurance, a code executor for code generation, and Google Scholar for scientific literature review. API.
CRITIC enables LLM to interact with multiple tools and autonomously revise its responses, effectively improving authenticity.
2. Knowledge utilization
Knowledge utilization can be applied at different stages to alleviate hallucinations in LLMs. Existing knowledge utilization methods can be broadly divided into two categories: context-based correction corrects previously generated non-factual claims by leveraging contextual knowledge. Post hoc correction corrects the illusion by constructing auxiliary repair procedures.
Context-based correction : Directly connecting the retrieved knowledge or tool feedback with user queries and then inputting them into LLMs is an effective and easy-to-implement method. This knowledge is also called contextual knowledge. Existing research shows that LLMs have strong contextual learning capabilities and are able to extract and utilize valuable information.
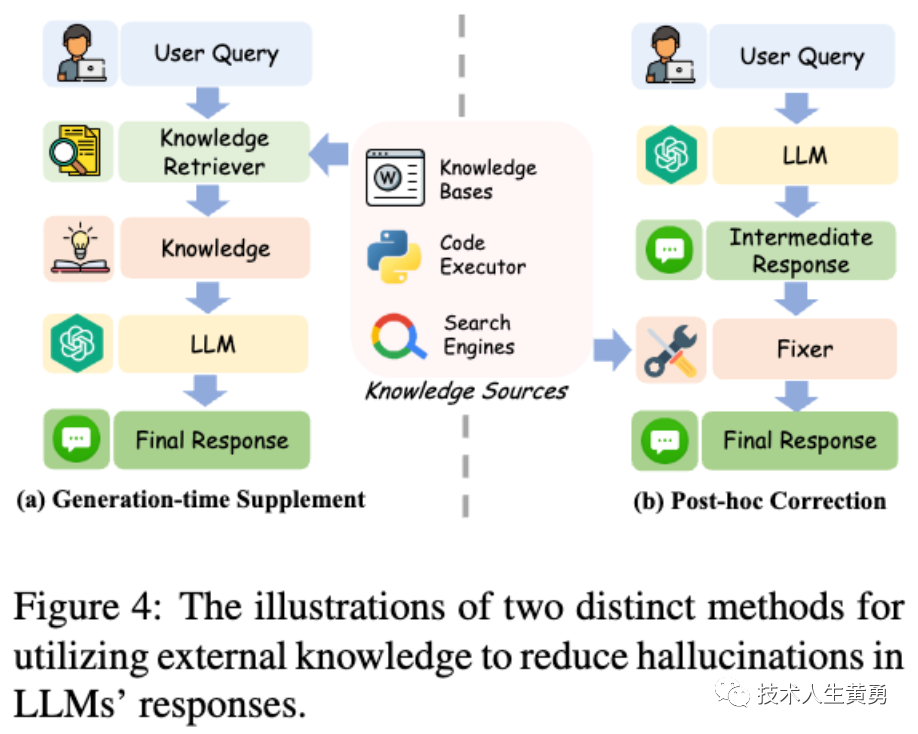
Schematic illustration of two different methods of using external knowledge to reduce hallucinations in LLMs' responses. Correct previously generated non-factual statements from contextual knowledge.
(Note: Most open source knowledge base + large model projects now implement the A idea: users first upload knowledge to the system, and the system vectorizes the knowledge and stores it in the vector knowledge base. When asking questions, vectorize the question first, and then pass Vector calculation extracts knowledge fragments that are similar to the question, then passes both the knowledge and the question to the large model, and finally the large model outputs the answer.)
Post-hoc correction : that is, constructing an auxiliary repair procedure in the post-processing stage to correct the illusion. These fixes can be to another language model or to a specific small model. They gather sufficient evidence by interacting with external knowledge sources and then make revisions. These fixes can leverage a variety of external tools to obtain evidence.
For example, RARR directly prompts LLM to ask questions about what needs to be corrected from multiple perspectives. It then searches again for relevant knowledge using a search engine.
Finally, the LLM-based correction procedure makes corrections based on the reacquired evidence. For example: the Verify-then-Edit method aims to post-edit the inference chain based on external knowledge obtained from Wikipedia, thus improving the authenticity of predictions.
For better performance, LLM-Augmenter prompts LLM to summarize the retrieved knowledge before feeding it into the repair program.
Using external knowledge to mitigate hallucinations in LLMs has several advantages:
Avoids the need to modify LLMs, making it more convenient.
It is a plug-and-play and efficient solution that can easily transfer proprietary knowledge and real-time updated information to LLMs.
The interpretability of the results generated by LLMs can be improved by tracing the generated results back to the source evidence.
However, this method still faces some problems that need to be solved:
How to verify the authenticity of knowledge retrieved from the Internet is a challenging problem.
Retrieval/repair performance and efficiency are critical to hallucination relief.
The retrieved knowledge may conflict with the parameterized knowledge stored by LLMs, and how to fully utilize contextual knowledge is an underexplored issue.
Uncertainty
Uncertainty is an important indicator for protecting and reducing illusions during reasoning. Typically, it refers to the confidence level in a model's results.
Uncertainty can help users determine when to trust LLMs. If the uncertainty of LLMs' responses can be accurately characterized, users can filter or correct claims for LLMs with high uncertainty.
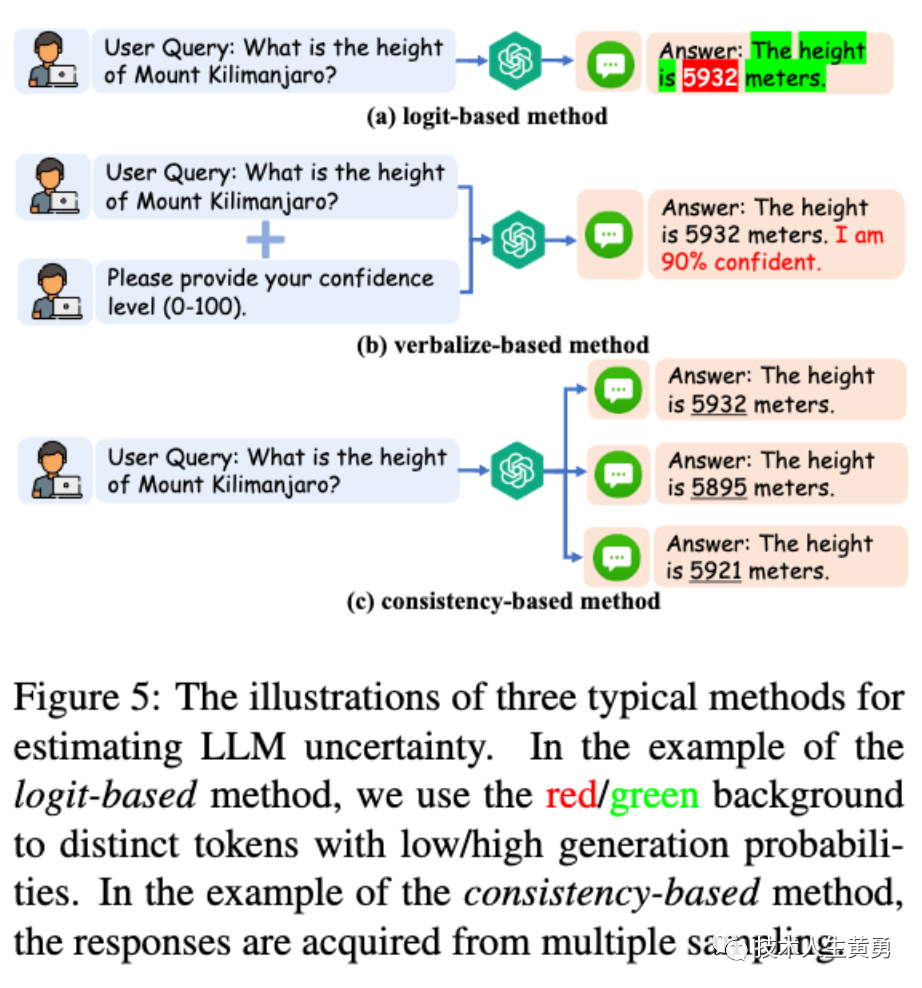
LLM uncertainty estimation methods can be divided into three categories, namely: confidence interval logit-base, verbalize-based and consistency-based methods . Examples of these methods can be seen in the image above.
Confidence based on logit : This is a logarithm-based method that requires taking the logarithm of the model, usually by calculating token-level probabilities or entropy to determine uncertainty.
Oral-based : Directly ask the LLM to express its uncertainty, for example using the following prompt: "Please answer and provide your confidence score (from 0 to 100)". This method is effective because LLM's ability to express language and obey instructions is very strong. This method can also be enhanced using thought chain prompts.
Consistency-based : This approach is based on the assumption that when LLMs are indecisive and hallucinating about facts, they are likely to give logically inconsistent answers to the same question. For example:
Calculations are performed using BERTScore, QA-based metrics, and n-gram metrics, and combining these methods yields the best results.
An additional LLM is directly used to determine whether there are logical contradictions in two LLM responses in the same context. Another LLM can be used to correct this self-contradictory illusion in the two responses.
Leverage existing procedural oversight to assign a risk score to LLM responses, which can serve as an indicator of hallucinations.
In general, using uncertainty to identify and alleviate LLM hallucinations is an effective research direction, but there are also some problems:
Logistic regression-based methods are increasingly unsuitable in modern commercial LLMs, as they are often closed-source and black-box, with no access to the logarithm of the output of the logistic regression and no logarithm of the model.
Regarding methods based on language expressions, researchers have observed that LLMs often show a high degree of overconfidence when expressing confidence, which means that the uncertainty expressed by the model itself is overestimated.
Effective measurement of consistency across responses remains an open question, and it is possible that multiple models generate the same illusion on the same question.
06
—
Other methods
In addition to the above methods, researchers have also proposed some other techniques to reduce hallucinations.
1. Multi-agent interaction
Multiple LLMs (agents) independently propose and collaboratively debate their answers to reach consensus. This approach can alleviate the problem of a single LLM producing illusory information.
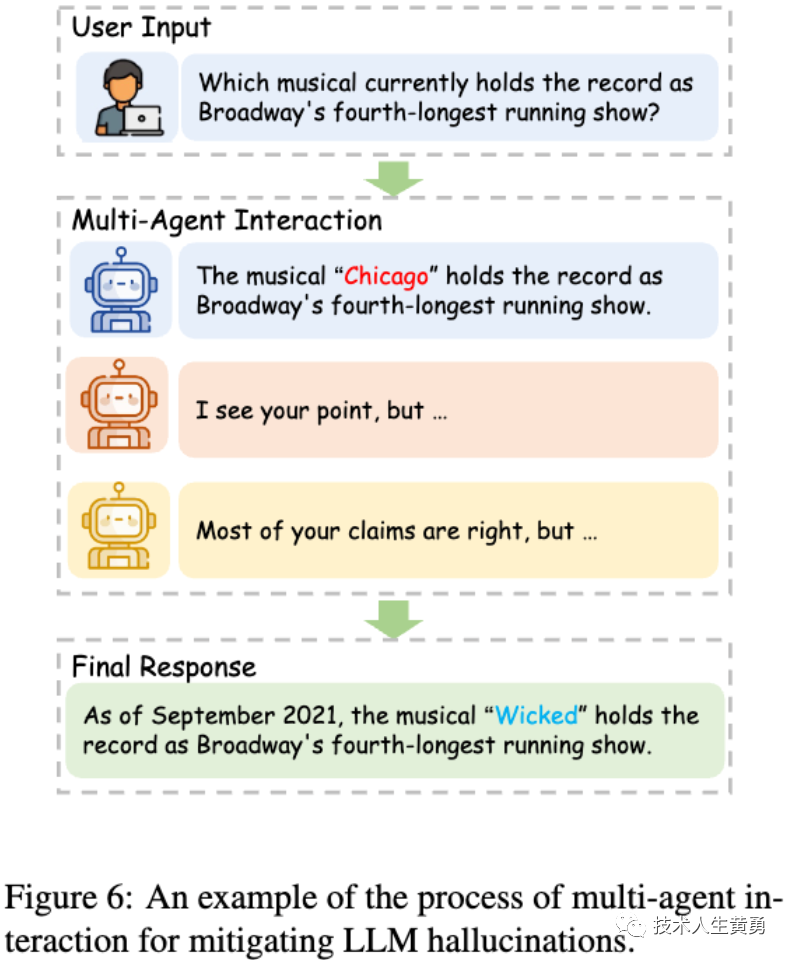
This illusion can be mitigated, for example, by involving multiple LLMs in debates to reach consensus. Having one LLM make claims (as EXAMINEE) and another LLM ask questions about those claims and check their veracity (as EXAMINER) can effectively reduce hallucinations at relatively low cost.
2. Prompt engineering
Research has found that the behavior of LLMs can be affected by user prompts, and hallucinations may occur. The LLM initially responded accurately, but when presented with different cues, the LLM began to hallucinate. Therefore, more effective cues can be designed to mitigate hallucinations.
To mitigate hallucinations, researchers used chain-thinking prompts, but this may also present new challenges. The popular approach now is to explicitly tell LLMs not to spread false information in the "system prompt" (i.e., the system parameter in ChatGPT's API).
For example, the system prompt for "Llama2-Chat": If you do not know the answer to the question, please do not share false information.
3. Check LLM's internal states Analyzing LLMs' internal states
Some research suggests that LLMs may be aware of their falsity, suggesting that their internal states could be used to detect hallucinations. They proposed sentence accuracy prediction based on language model activation, which can effectively extract this information by adding a classifier on each hidden layer to determine authenticity.
Experimental results show that the LLM may "know" when it generates false sentences, and the classifier can effectively obtain such information.
Some methods can intervene in model activation during inference and thus reduce hallucinations. These studies suggest that hallucinations in LLM may be due more to the generative technique than to the underlying representation.
4. Human-in-the-loop Human-in-the-loop
One potential cause of hallucinations in LLM may be the misalignment between knowledge and user questions, a phenomenon that is particularly prevalent in retrieval-augmented generation (RAG).
To solve this problem, the MixAlign framework is introduced, a human intervention loop framework that leverages LLMs to align user queries with stored knowledge and further encourages users to clarify this alignment. By iteratively adapting user queries, MixAlign not only reduces hallucinations but also improves the quality of generated content.
5. Optimize model architecture
Optimizing the model architecture can reduce language model artifacts, such as using methods such as multi-branch decoders, uncertainty-aware decoders, and bidirectional autoregressive architectures. Among them, the bidirectional autoregressive architecture can perform language modeling from left to right and right to left, effectively utilizing bidirectional information and helping to reduce hallucinations.
(Note: It is said that ChatGLM, which is open sourced by Tsinghua University in China, uses a two-way autoregressive architecture.)
07
—
Summary and Outlook
The paper discusses some unresolved challenges when investigating hallucinations in LLMs and provides insights into future research directions.
Current automatic measures for evaluating hallucination generation in LLM suffer from inaccuracies and require deeper exploration. Generative hallucination assessment and manual annotation are not entirely consistent, and the reliability of automatic measures also varies across different domains and LLMs, resulting in reduced generalization capabilities. Discriminative hallucination evaluation can relatively accurately assess the discriminative ability of a model, but the relationship between discriminative and generative abilities remains unclear.
Existing research on LLM hallucinations focuses primarily on English, but thousands of languages exist in the world. It is hoped that LLM can handle various languages uniformly. Some studies have found that LLM performance degrades when processing non-Latin languages. Guerreiro et al. observed that multilingual LLM exhibits hallucinations in translation tasks mainly in low-resource languages. LLMs such as ChatGPT provide accurate answers in English but hallucinate in other languages, leading to multi-language inconsistencies. The transfer of knowledge between LLMs from high-resource languages to low-resource languages is also interesting.

Recent research has proposed large-scale visual language models (LVLMs) to improve the performance of complex multi-modal tasks. However, the problem of multi-modal hallucination in LVLMs is also serious.
Some studies have shown that LVLMs inherit the hallucination problems of LLMs, such as object hallucination. To effectively measure the object illusion generated by LVLMs, the GAVIE benchmark and M-HalDetect datasets are proposed. In addition, some studies extend LLMs to other modalities, such as audio and video, which is also an interesting research direction.
In order to alleviate these hallucination problems in LLM with the minimum computational cost, people have introduced the concept of model editing and proposed the concept of model editing, including two methods: auxiliary subnetworks and direct modification of model parameters. Model editing can eliminate illusions by editing stored factual knowledge. However, this emerging field still faces many challenges, including editing black-box models, contextual model editing, and multi-hop model editing.
At the same time, research also shows that language models can induce hallucinations through carefully crafted prompts, which may violate relevant laws and result in the application being forced to close. Therefore, attack and defense strategies for inducing hallucinations are also an important research direction and are closely related to existing hallucination mitigation methods. At the same time, the real responsiveness of commercial language models also needs to be continuously improved.
- over-
Interested friends can refer to OpenAI’s research on large model alignment: "Is Artificial Intelligence Safe?" OpenAI is "aligning" large models with humans - ensuring that ChatGPT is smarter than humans while still following human intentions》
Previous article address: " Song of the Siren in the Ocean of Artificial Intelligence: A Review of Illusion Research in Large Language Model LLM (1) "
References
https://arxiv.org/abs/2309.01219
Reading recommendations:
The winner of the 100-model war will eventually be the open source model | Near Craftsman
Lei Jun: 99% of questions have standard answers. Find someone who knows and ask.
8.23 Notes on China’s Big Model “Top Group Chat”
The Chinese large model Chinese-LLaMA-Alpaca-2 is open source and can be used commercially
Embrace the future and learn AI skills! Follow me and receive free AI learning resources.