1. Numeric pointer: If a pointer points to an array, we call it an array pointer.
- The array pointer points to a specific element in the array, not the entire array, so the type of the array pointer is related to the type of the array element.
- Sizeof(p) / sizeof(int) cannot be used when finding the length of an array, because p is just a pointer to type int. The compiler only knows that it points to an integer but does not know that it is an integer (array).
A pointer to an array, for example:
int arr[] = { 99, 15, 100, 888, 252 };
int *p = arr;
2. Pointer array: If all elements in an array store pointers, then we call it a pointer array.
The brackets indicate that arrayName is an array containing length elements. The brackets indicate that the type of each element is dataType *, which is an address that stores dataType data.
int *a[10];
3. A function always occupies a continuous memory area. The function name in the expression is sometimes converted to the first address of the memory area where the function is located, which is very similar to the array name. We can assign the first address (or entry address) of the function to a pointer variable, so that the pointer variable points to the memory area where the function is located, and then the function can be found and called through the pointer variable. This kind of pointer is a function pointer
returnType (*pointerName)(param list);
int (*a)(int)
4. A function pointer array is an array whose elements are function pointers. Make it clear that each array element is a pointer to the function entry address.
int (*a[10]) (int)
5. Summary
A pointer is the address of memory. C language allows a variable to be used to store a pointer. This variable is called a pointer variable. Pointer variables can store the addresses of basic type data, as well as the addresses of arrays, functions, and other pointer variables.
What the program needs during running is the address of data and instructions. Variable names, function names, string names and array names are essentially the same. They are all mnemonics for addresses: in the process of writing code, we think The variable name represents the data itself, while the function name, string name and array name represent the first address of the code block or data block; after the program is compiled and linked, these names will disappear and be replaced by their corresponding addresses.
1) Pointer variables can perform addition and subtraction operations, such as p++, p+i, p-=i. The addition and subtraction of pointer variables is not simply adding or subtracting an integer, but is related to the data type pointed to by the pointer.
2) When assigning a value to a pointer variable, you must assign the address of a piece of data to it. It cannot be assigned directly to an integer. For example, int *p = 1000; is meaningless and will generally cause the program to crash during use.
3) Pointer variables must be initialized before using them, otherwise it will be impossible to determine where the pointer points. If the memory it points to does not have permission to use, the program will crash. For pointers that do not currently point to, it is recommended to assign NULL.
4) Two pointer variables can be subtracted. If two pointer variables point to an element in the same array, the result of the subtraction is the number of elements between the two pointers.
5) Arrays also have types. The original meaning of the array name is to represent a group of data of the same type. When defining an array, or when used with the sizeof and & operators, the array name represents the entire array. The array name in the expression will be converted into a pointer to the first address of the array.
6. C language byte alignment
1. What is alignment?
The memory space in modern computers is divided into bytes. In theory, it seems that access to any type of variable can start from any address, but the actual situation is that when accessing a specific variable, it is often at a specific memory address. Access, which requires various types of data to be arranged spatially according to certain rules, rather than arranged one after another sequentially, is alignment.
2. Why do computers need to be aligned?
Each hardware platform handles storage space very differently. Some platforms can only access certain types of data from certain addresses. This may not be the case on other platforms. But the most common thing is that if the data storage is not aligned according to the requirements suitable for its platform, it will cause a loss in access efficiency. For example, some platforms start every read from an even address. If an int type (assumed to be 32 bits) is stored at the beginning of the even address, it can be read out in one read cycle. If it is stored at the beginning of the odd address, It may take 2 read cycles and piece together the high and low bytes of the two read results to get the int data, which obviously reduces the reading efficiency a lot. This is also a game of space and time. In network programs, it is very important to master this concept: if a binary stream (such as a structure) is passed between different platforms (such as between Windows and Linux), then the same definition must be used between the two platforms. alignment, otherwise some inexplicable errors will occur, but it will be difficult to troubleshoot.
3. Implementation of alignment:
Usually, when we write a program, we don't need to consider alignment issues. The compiler will choose an alignment strategy suitable for the target platform for us. Of course, we can also notify the compiler to pass precompiled instructions to change the alignment method of the specified data, such as writing the precompiled instruction #pragma pack (2), which tells the compiler to align by two bytes.
However, just because we generally do not need to care about this issue, if the editor has aligned the data storage and we do not understand it, we will often be confused by some issues. The most common one is the sizeof result of the struct data structure, such as the following program:
#include<stdio.h>
int main(void)
{
struct A
{
char a;
short b;
int c;
};
printf("The memory occupied by structure type A is: %d bytes.\n",sizeof(struct A));
return 0;
}
The output result is: 8 bytes.
If we slightly change the declaration location of the variables in the structure (without changing the variables themselves), please look at the following program again:
#include<stdio.h>
int main(void)
{
struct A
{
short b;
int c;
char a;
};
printf("The memory occupied by structure type A is: %d bytes.\n",sizeof(struct A));
return 0;
}
The output result is: 12 bytes.
The problem arises. They are all the same structure. Why do they occupy different memory sizes? To do this, we need to know something about alignment algorithms.
4. Alignment algorithm:
Due to differences between platforms and compilers, we will now take the 32-bit, vc++6.0 system as an example to discuss how the compiler aligns each member of the struct data structure.
First, we give four concepts:
1) The alignment value of the data type itself: It is the self-alignment value of the basic data type. For example, the self-alignment value of the char type is 1 byte, and the self-alignment value of the int type is 4 bytes.
2) Specify the alignment value: the alignment value value specified by the precompilation command #pragma pack (value).
3) The self-alignment value of the structure or class: the value with the largest self-alignment value among its members. For example, the alignment value of struct A above is 4.
4) The effective alignment value of data members, structures and classes: the smaller of the own alignment value and the specified alignment value.
Assume the structure is defined as follows:
struct A
{
char a;
short b;
int c;
};
a is char type data, which occupies 1 byte of memory; short type data, occupies 2 bytes of memory; int type data, occupies 4 bytes of memory. Therefore, the self-alignment value of structure A is 4. Therefore, a and b need to form 4 bytes in order to align with the 4 bytes of c. And a has only 1 byte, so there is an empty byte between a and b. We know that structure type data is stored in order and the structures are arranged one after another backwards, so its storage method is:
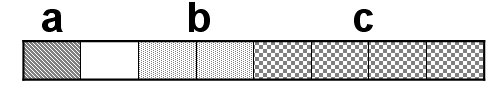
The blank squares have no data and are a waste of memory space, occupying a total of 8 bytes of memory.
In fact, to express "alignment" more clearly, we can imagine the above structure as the following row arrangement:
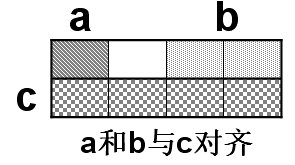
For another structure definition:
struct A
{
short b;
int c;
char a;
};
Its memory storage method is:
![]()
Also think of it as a row arrangement:
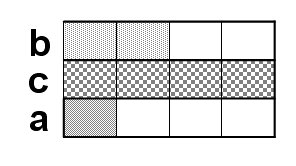
It can be seen that more space is wasted.
In fact, in addition to the structure, the entire program will follow the alignment mechanism when allocating memory to each variable, which will also cause a waste of memory space. But we need to know that this waste is worth it, because it results in increased efficiency.
The above analysis is based on the default alignment value of the program. We can customize the alignment value by adding the predefined command #pragma pack(value), such as #pragma pack(1), the alignment value becomes 1 , at this time the memory is compact and there will be no memory waste, but the efficiency is reduced. The reason why the efficiency is reduced is because: if there is a variable with a larger number of bytes (larger than 1), such as the int type, multiple read cycles are needed to piece together an int data.