Guide pratique DevOps
-
- Partie 2 Par où commencer
- 5. Choisissez la chaîne de valeur appropriée comme point d'entrée
- 6. Comprendre, visualiser et appliquer les flux de valeur
- 7. Concevoir une structure organisationnelle en référence à la loi de Conway
-
- 7.1 Archétypes organisationnels
- 7.2 Les dangers d’une orientation fonctionnelle excessive (« optimisation des coûts »)
- 7.3 Former une équipe orientée marché (« optimisation de la vitesse »)
- 7.4 Rendre l'orientation fonctionnelle efficace
- 7.5 Intégrer les tests, les opérations et la sécurité des informations dans le travail quotidien
- 7.6 Faire des membres de l'équipe des généralistes
- 7.7 Investir dans des services et des produits, pas dans des projets
- 7.8 Fixer les limites des équipes en fonction de la loi de Conway
- 7.9 Créer une architecture faiblement couplée pour améliorer la productivité et la sécurité
- 7.10 Résumé
- 8. Intégrer l'exploitation et la maintenance dans le travail de développement quotidien
-
- 8.1 Créer des services partagés pour améliorer la productivité du développement
- 8.2 Intégrer les ingénieurs d'exploitation et de maintenance dans l'équipe de service
- 8.3 Attribuer une personne de contact pour l'exploitation et la maintenance à chaque équipe de service
- 8.4 Inviter les ingénieurs d'exploitation et de maintenance à participer aux réunions de l'équipe de développement
- 8.4.2 Inviter les ingénieurs d'exploitation et de maintenance à participer aux réunions d'examen
- 8.4.3 Utiliser le diagramme Kanban pour afficher les travaux d'exploitation et de maintenance
- 8.5 Résumé
Partie 2 Par où commencer
Comment faire le premier pas vers la transformation DevOps dans votre organisation ? Qui doit participer ? Comment constituer une équipe ? Comment s’assurer que les membres de l’équipe investissent leur énergie et maximisent leurs chances de réussite ? Ce chapitre répondra à ces questions.
Cette section se concentre sur les sujets suivants :
- Choisissez la chaîne de valeur appropriée comme point d’entrée ;
- Comprendre le travail dans la chaîne de valeur à transformer ;
- Concevoir une structure organisationnelle en référence à la loi de Conway ;
- Atteindre des résultats orientés vers le marché grâce à une collaboration plus efficace entre les équipes fonctionnelles dans la chaîne de valeur ;
- Protégez et responsabilisez votre équipe
Toute transformation est au début pleine d’incertitudes : le voyage que nous planifions a une destination merveilleuse, mais presque toutes les étapes intermédiaires sont inconnues. Les chapitres suivants sont destinés à guider la réflexion et la prise de décision et à fournir des mesures concrètes et des études de cas.
5. Choisissez la chaîne de valeur appropriée comme point d'entrée
Le choix de la bonne chaîne de valeur pour la transformation DevOps mérite une attention particulière. Il détermine non seulement la difficulté du processus de transformation, mais aussi les participants au processus de transformation ; il affecte non seulement la façon dont l'équipe est formée, mais aussi la manière dont l'équipe et ses membres peuvent y participer au mieux.
5.1 Projets greenfield et projets brownfield
Dans le monde de la technologie, un projet greenfield fait référence à un projet logiciel complètement nouveau. De tels projets en sont souvent aux premiers stades de planification ou de mise en œuvre, ce qui offre la possibilité de créer des applications et une infrastructure entièrement nouvelles sans trop de contraintes. Démarrer un nouveau projet logiciel est relativement simple, surtout lorsque le budget ou l’équipe du projet est déjà en place. De plus, comme nous partons de zéro, nous n’avons pas trop de soucis concernant la base de code, les processus et les équipes existants.
Les projets DevOps greenfield font généralement référence à des projets pilotes utilisés pour prouver la faisabilité de solutions de cloud public ou de cloud privé, ou pour essayer d'adopter des outils de déploiement automatisés ou des outils associés.
Les projets DevOps brownfield sont des produits ou des services qui sont au service des clients depuis des années, voire des décennies. De tels projets comportent généralement beaucoup de dettes techniques, comme l'absence de tests automatisés et l'exécution sur des plates-formes non entretenues. Les projets de friches industrielles peuvent être confrontés à d'énormes obstacles lors de leur transformation, en particulier s'il n'y a pas de tests automatisés ou si l'architecture étroitement couplée empêche les équipes de développer, tester et déployer de manière indépendante.
5.2 Considérez à la fois les systèmes d'enregistrement et les systèmes interactifs
L'informatique bimodale fait référence à la capacité des entreprises à prendre en charge différents types d'évolution de services. Dans l'informatique bimode, les systèmes traditionnels basés sur des enregistrements font référence à des systèmes similaires à l'ERP (tels que les systèmes MRP, les systèmes de ressources humaines, les systèmes d'états financiers, etc.), et l'exactitude de leurs transactions et données est cruciale ; les systèmes interactifs font référence aux systèmes interactifs pour les clients ou les employés, tels que les systèmes de commerce électronique et les logiciels de bureautique
Les systèmes d'enregistrement évoluent généralement plus lentement et sont soumis à des exigences réglementaires et de conformité (telles que SOX). Gartner appelle ce type de système « Type 1 », qui se concentre sur « bien faire les choses ».
Les systèmes interactifs évoluent souvent rapidement car ils nécessitent une réponse rapide aux commentaires et à l'expérimentation pour trouver la meilleure façon de répondre aux besoins des clients. Gartner appelle ce type de système « Type 2 », qui vise à « faire les choses rapidement » .
Une telle division peut être pratique, mais il existe une contradiction de longue date entre « bien faire les choses » et « faire les choses rapidement », et DevOps peut résoudre efficacement cette contradiction.
Lors de l’amélioration des systèmes de friches industrielles, nous devons non seulement nous efforcer de réduire la complexité et d’améliorer la fiabilité et la stabilité, mais également de rendre le système plus rapide, plus sûr et plus facile à modifier. Le simple fait d'ajouter de nouvelles fonctionnalités à un nouveau système interactif crée souvent des problèmes de fiabilité pour les systèmes basés sur les enregistrements des friches industrielles sur lesquels il s'appuie. Permettre aux systèmes en aval d’effectuer des changements plus sûrs peut aider l’ensemble de l’organisation à atteindre ses objectifs plus rapidement et de manière plus sécurisée.
5.3 Commencer par les équipes les plus disposées à innover
Dans chaque organisation, différentes équipes ou individus auront des attitudes différentes envers l'innovation. Franchir le gouffre signifie surmonter les obstacles et trouver un groupe plus large que les innovateurs et les premiers adoptants (voir Figure 5-1).
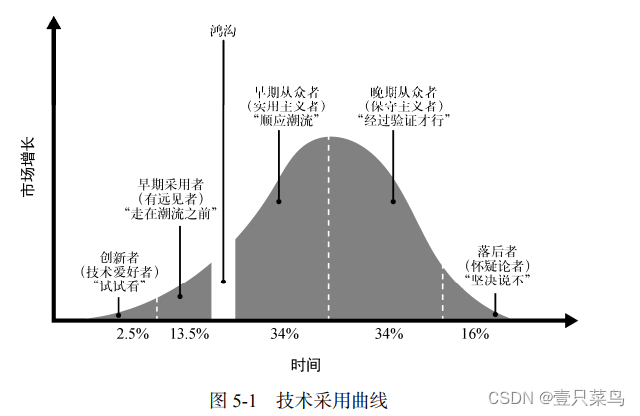
En d’autres termes, les innovateurs et les premiers adoptants ont tendance à adopter rapidement de nouvelles idées, tandis que d’autres sont plus conservateurs (qui peuvent être divisés en premiers adeptes, adeptes tardifs et retardataires). Notre objectif est de trouver des équipes qui croient aux principes et pratiques DevOps et qui ont la volonté et la capacité d'innover et d'améliorer les processus existants. Idéalement, ces groupes seront les champions (champions, champions) de la transformation DevOps.
Nous ne consacrons pas beaucoup de temps à essayer de convertir les groupes conservateurs, surtout au début. Au lieu de cela, concentrez vos efforts sur les équipes qui créent le succès et sont prêtes à prendre des risques, et élargissez progressivement la portée à partir de là (ce processus est abordé dans la section suivante). Même si vous bénéficiez d'un soutien de haut niveau, évitez une approche « big bang » (c'est-à-dire commencer en beauté) et concentrez-vous plutôt sur quelques domaines pilotes, assurez-vous qu'ils réussissent, puis développez-les au fil du temps.
5.4 Élargir la portée de DevOps
Quelle que soit la manière dont vous choisissez le point d’entrée, vous devez démontrer les résultats le plus tôt possible et les diffuser activement. Décomposez les grands objectifs d’amélioration en petites étapes progressives. Cela augmente non seulement la vitesse d’amélioration, mais permet également une détection précoce des sélections incorrectes de flux de valeur. En détectant les erreurs le plus tôt possible, les équipes peuvent rapidement revenir en arrière et réessayer, et prendre des décisions différentes en fonction de nouvelles expériences.
Sur la base des succès obtenus, étendez progressivement le champ d'application des plans DevOps. Suivez une séquence à faibles enjeux pour augmenter méthodiquement la crédibilité, l’impact et gagner l’adhésion.
- Découvrez les innovateurs et les premiers utilisateurs
- gagner la majorité silencieuse
- Identifier les « ménages cloués »
Mettre pleinement en œuvre DevOps au sein d’une organisation n’est pas une tâche facile. La transformation peut créer des risques pour les individus, les départements et l’ensemble de l’organisation.
5.5 Résumé
En choisissant soigneusement les points d'entrée de la transformation DevOps, nous expérimentons, apprenons et créons de la valeur dans certains domaines de l'organisation sans conséquences irréversibles pour l'ensemble de l'organisation. Dans le même temps, de cette manière, nous pouvons construire une base de masse solide et gagner l'opportunité de promouvoir DevOps dans l'organisation, gagnant ainsi la reconnaissance et la gratitude d'un plus grand nombre de partisans.
6. Comprendre, visualiser et appliquer les flux de valeur
Une fois que vous avez identifié la chaîne de valeur dans laquelle vous souhaitez appliquer les principes et modèles DevOps, vous devez avoir une compréhension approfondie de la manière de fournir de la valeur aux clients : quel travail est effectué ? Qui le fera ? Quelles mesures faut-il prendre pour améliorer le processus ?
Ce chapitre explorera ensuite les étapes suivantes : déterminer les équipes nécessaires pour créer de la valeur client ; dessiner une carte de la chaîne de valeur pour visualiser le travail nécessaire ; utiliser la carte de la chaîne de valeur comme guide pour aider l'équipe à créer de la valeur client mieux et plus rapidement.
6.1 Identifier l'équipe nécessaire pour créer de la valeur client
Après avoir sélectionné une application ou un service pilote DevOps, vous devez identifier tous les membres de la chaîne de valeur qui sont responsables de la création conjointe de valeur pour les clients. De manière générale, les membres suivants sont inclus.
- Product Owner : en tant que porte-parole du côté commercial, définissez les fonctions que le système doit mettre en œuvre.
- Équipe de développement : Responsable du développement des fonctions du système.
- Équipe d'assurance qualité : fournit des commentaires à l'équipe de développement et garantit que la fonctionnalité du système répond aux exigences.
- Équipe d’exploitation et de maintenance : Responsable de maintenir l’environnement de production et de s’assurer du bon fonctionnement du système.
- Équipe de sécurité de l’information : Responsable de la sécurité des systèmes et des données.
- Release Manager : responsable de la gestion et de la coordination des processus de déploiement et de publication de l'environnement de production.
- Responsable technique ou responsable de la chaîne de valeur : (selon la définition de la méthodologie Lean) Responsable de « garantir que le résultat de la chaîne de valeur répond ou dépasse les attentes du client (et de l'organisation) du début à la fin »
6.2 Dessiner une carte de la chaîne de valeur pour le travail d'équipe
Dans la chaîne de valeur, le travail initial consiste à déterminer les besoins du client ou l'idéation commerciale, ce qui est effectué par le propriétaire du produit ; ensuite, l'équipe de développement prend le relais, met en œuvre les fonctions pertinentes par le biais de la programmation et soumet le code au système de contrôle de version ; Ensuite, intégrez et testez les fonctionnalités dans un environnement de type production, et enfin déployez-les dans un environnement de production qui (idéalement) crée de la valeur pour les clients.
L’objectif de l’élaboration d’une carte de la chaîne de valeur n’est pas d’enregistrer toutes les étapes et tous les détails, mais d’identifier les liens qui entravent le flux rapide de la chaîne de valeur, réduisant ainsi les délais et améliorant la fiabilité. Idéalement, toutes les personnes impliquées dans l’atelier devraient avoir le pouvoir de modifier les pièces dont elles sont responsables (il est important de limiter le niveau de détail des informations, car le temps de chacun est précieux.)
Sur la base de toutes les informations fournies par l'équipe de participation à la chaîne de valeur, les deux types de travail suivants doivent être axés sur l'analyse et l'optimisation :
- Travaux qui nécessitent des semaines, voire des mois d'attente, comme la préparation d'un environnement de type production, le processus d'approbation des modifications ou le processus d'examen de sécurité ;
- Initier ou gérer des travaux qui impliquent des retouches importantes.
La version initiale de la cartographie de la chaîne de valeur ne doit contenir que les modules de processus importants. Même pour des flux de valeur complexes, les groupes participants peuvent généralement dessiner une carte de flux de valeur contenant 5 à 15 modules en quelques heures. Chaque module doit inclure au moins le délai de livraison et le temps de traitement de l'élément de travail (LT et VA respectivement dans la Figure 6-1 <Dans certains cas, le temps de traitement est également appelé temps à valeur ajoutée (Value Added Time)>), et le Mesuré par les consommateurs en aval%C/A
Les mesures d’une carte de flux de valeur peuvent être utilisées pour guider les efforts d’amélioration.
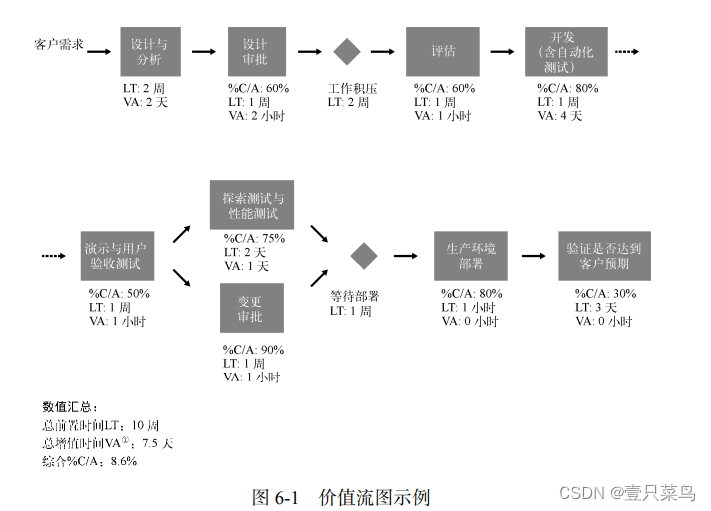
Dans certains maillons de travail, le temps de valeur ajoutée VA dans la figure est de 0. Cela ne signifie pas que le temps de traitement est de 0, mais cela signifie que ce travail n'ajoute pas de valeur aux clients et aux flux de valeur.
Les dirigeants aident à identifier les objectifs d'amélioration et guident les équipes pour réfléchir à des hypothèses et des mesures, explorer diverses hypothèses à travers des expériences, puis analyser les résultats pour déterminer si les hypothèses sont correctes. Grâce à des itérations et des itérations constantes, l'équipe applique l'expérience nouvellement acquise à l'expérience et à la vérification suivantes.
6.3 Former une équipe de transformation dédiée
Un défi inhérent à une transformation DevOps est le conflit avec les activités actuelles d'une entreprise, ce qui est inévitable et une conséquence naturelle de la croissance réussie d'une entreprise . Toute organisation qui fonctionne avec succès depuis de nombreuses années (années, décennies, voire siècles) a établi ses propres pratiques et mécanismes opérationnels, tels que le développement de produits, la gestion des commandes et les opérations de la chaîne d'approvisionnement.
Bien que cela soit idéal pour maintenir le statu quo, pour s'adapter aux changements du marché, il est souvent nécessaire de changer votre façon de travailler. Cela nécessite des perturbations et des innovations, qui entreront inévitablement en conflit avec les groupes actuellement responsables des activités quotidiennes et des processus internes, et ces derniers l'emporteront souvent.
Des équipes de transformation dédiées doivent être formées et rendues indépendantes des départements responsables des opérations quotidiennes (ils appellent les premières « équipes dédiées » et les secondes « moteurs de performance »). Plus important encore, cette équipe doit être responsable de la réalisation d'objectifs clairement définis et mesurables au niveau du système (par exemple, réduire de 50 % le délai entre la soumission du code et le déploiement en production). Pour ce faire, les mesures suivantes doivent être prises :
- Dédier les membres de l'équipe de transformation à effectuer le travail de transformation DevOps (plutôt que de les laisser continuer à faire leur travail précédent mais de consacrer 20 % de leur temps à la transformation DevOps) ;
- Sélectionner des généralistes familiers avec plusieurs domaines en tant que membres de l'équipe ;
- Sélectionner comme membres de l'équipe des personnes qui entretiennent de bonnes relations à long terme avec d'autres départements ;
- Si possible, trouvez un espace de bureau séparé pour l'équipe afin que les membres puissent interagir autant que possible les uns avec les autres et maintenir une distance appropriée avec les autres départements.
Former une équipe de transformation dédiée est non seulement bénéfique pour l’équipe elle-même, mais aussi pour le « moteur de performance ». En faisant tester de nouvelles pratiques par des équipes indépendantes, le reste de l’organisation est protégé des risques potentiels de l’innovation.
6.3.1 Avoir un objectif commun
Le premier élément de tout plan d’amélioration est de fixer des objectifs mesurables pour les 6 prochains mois à 2 ans. Afin d'atteindre les objectifs, l'équipe doit déployer des efforts considérables, et la réalisation des objectifs doit créer une valeur significative pour l'ensemble de l'organisation et les clients.
Les objectifs et les délais doivent être fixés par la direction et communiqués à tous les membres de l'organisation. De plus, trop d’initiatives d’amélioration devraient être limitées en même temps pour éviter de surcharger l’organisation et la direction. Voici quelques exemples d’objectifs d’amélioration :
- Réduire de 50 % le budget pour le support produit et les travaux imprévus ;
- Pour 95 % des modifications, assurez-vous que le cycle allant de la soumission du code à la publication de la version est raccourci à une semaine, voire moins ;
- Veiller à ce que la publication puisse avoir lieu pendant les heures de bureau et sans interruption de service ;
- Intégrez tous les efforts de validation de la sécurité des informations dans le pipeline de déploiement pour répondre aux exigences de conformité requises.
Une fois les objectifs généraux clairs, l’équipe doit élaborer un plan détaillé et un rythme pour améliorer le travail. Tout comme les efforts de développement de produits, les efforts de transformation doivent être menés de manière itérative et progressive. En règle générale, chaque itération est terminée en 2 à 4 semaines. Pour chaque itération, l’équipe doit développer un ensemble de petits objectifs susceptibles de générer de la valeur et de se rapprocher de l’objectif à long terme. À la fin de chaque itération, l'équipe doit examiner les progrès et fixer de nouveaux objectifs pour la prochaine itération.
6.3.2 Maintenir un plan d'amélioration à petite échelle
Dans tout projet de transformation DevOps, vous devez maintenir un plan d'amélioration à petite échelle, tout comme une startup effectuant du développement de produits ou de clients. Vous devez vous efforcer d’obtenir des améliorations mesurables ou des données utilisables en quelques semaines (au pire, en mois).
En raccourcissant la durée de planification et l'intervalle d'itération, vous pouvez effectuer les opérations suivantes :
- Capacité et flexibilité pour replanifier et modifier les priorités ;
- Réduire le délai entre la mise en œuvre et l’efficacité du travail, renforçant ainsi les boucles de rétroaction, sera plus susceptible de renforcer les comportements souhaités : les succès initiaux peuvent conduire à un investissement accru ;
- Gagnez de l'expérience grâce aux itérations plus rapidement et appliquez-les à l'itération suivante ;
- Des améliorations peuvent être obtenues avec moins d’effort ;
- Obtenez plus rapidement des améliorations significatives et différenciées dans votre travail quotidien ;
- Réduisez le risque que les projets soient interrompus avant qu’ils n’obtiennent des résultats.
6.3.3 Réserver 20 % du temps de développement aux exigences non fonctionnelles afin de réduire la dette technique
Comment définir les priorités de manière appropriée est un problème courant dans les efforts d’amélioration des processus. Après tout, la plupart des organisations qui ont désespérément besoin d’améliorer leurs processus n’ont pas assez de temps. Cela est encore plus vrai pour les organisations techniques, qui doivent également rembourser leur dette technique.
Pour gérer de manière proactive la dette technique, assurez-vous de consacrer au moins 20 % de votre temps de développement et d'exploitation aux efforts de refactorisation, d'automatisation, d'optimisation architecturale et aux exigences non fonctionnelles (parfois appelées « attributs de qualité ») telles que la maintenabilité, la gérabilité, l'évolutivité, fiabilité, testabilité, déployabilité et sécurité, etc. (voir Figure 6-2) Grâce à

cet investissement de 20 %, les développeurs et le personnel d'exploitation et de maintenance peuvent résoudre les problèmes rencontrés dans le travail quotidien. Fournir des contre-mesures à long terme aux problèmes identifiés et garantir que les techniques la dette n’entrave pas un développement et des opérations rapides et sûrs. Dans le même temps, alléger la pression de l’endettement technique des salariés peut également réduire l’épuisement professionnel.
6.3.4 Améliorer la visibilité du travail
Afin de pouvoir déterminer si l’équipe progresse vers ses objectifs, il est nécessaire que tous les membres de l’organisation comprennent l’état actuel du travail. Il existe de nombreuses façons de visualiser le statut, mais le plus important est d'afficher efficacement le dernier statut et de le réviser constamment pour garantir que l'équipe est au courant des derniers progrès.
6.4 Utiliser des outils pour renforcer les comportements attendus
Notre objectif est de souligner que les développeurs et les opérations partagent non seulement les mêmes objectifs, mais également la même liste de tâches. Idéalement, les listes de tâches sont stockées dans un système de travail commun, utilisent une terminologie unifiée et peuvent être hiérarchisées à l'échelle mondiale.
De cette façon, les développeurs et le personnel opérationnel peuvent créer des files d'attente de travail partagées au lieu d'utiliser différents outils. L'avantage majeur de cette solution est que lorsqu'un incident de production est visible dans le système de travail du développeur, il est clair quand l'incident affectera d'autres travaux. Ceci est particulièrement évident lors de l'utilisation de diagrammes Kanban.
Un autre avantage d'une file d'attente partagée est qu'elle unifie la liste des tâches, permettant à chacun de réfléchir aux choses les plus prioritaires dans une perspective globale et de sélectionner le travail qui est le plus précieux pour l'organisation ou qui maximise le remboursement de la dette technique. Lorsque vous découvrez une dette technique, vous pouvez l’ajouter à votre liste de tâches si elle ne peut pas être résolue immédiatement. Pour les problèmes en suspens, vous pouvez utiliser les 20 % de temps réservés aux exigences non fonctionnelles pour les résoudre.
Pour renforcer les objectifs communs, des salons de discussion peuvent également être utilisés, tels que les canaux IRC, HipChat, Campfire, Slack, Flowdock et OpenFire. Les salons de discussion permettent le partage rapide d'informations (plutôt que de traiter des formulaires via des flux de travail prédéfinis), la possibilité d'inviter d'autres personnes à rejoindre le chat à la demande et la possibilité d'enregistrer automatiquement le contenu du chat et de l'analyser après coup. Établissez des mécanismes et permettez aux membres de l’équipe de s’entraider et même aux membres d’autres équipes. Cela entraînera des changements étonnants : le temps nécessaire aux gens pour obtenir des informations ou terminer un travail sera réduit de quelques jours à quelques minutes. De plus, comme tout est effectivement enregistré, les utilisateurs n’ont plus besoin de demander de l’aide aux autres plus tard, mais doivent simplement rechercher dans l’historique des discussions.
6.5 Résumé
Ce chapitre explore comment identifier les équipes qui prennent en charge la chaîne de valeur et découvre le travail requis pour fournir de la valeur aux clients grâce à la cartographie de la chaîne de valeur. Une carte de la chaîne de valeur montre non seulement une image de base de l'état actuel du travail (y compris des mesures telles que le délai de livraison et le % C/A), mais guide également l'équipe dans l'identification des objectifs d'amélioration futurs.
Cela permet aux équipes de transformation d’itérer rapidement et d’améliorer leur efficacité grâce à l’expérimentation. L'équipe alloue suffisamment de temps pour corriger les défauts connus et résoudre les problèmes architecturaux, y compris les exigences non fonctionnelles, etc. En identifiant les problèmes dans la chaîne de valeur et en remboursant continuellement la dette technique, des améliorations significatives peuvent être obtenues sur des aspects tels que les délais de livraison et la qualité.
7. Concevoir une structure organisationnelle en référence à la loi de Conway
" La conception du système est limitée par la propre structure de communication de l'organisation. Plus l'organisation est grande, moins elle est flexible et plus ce phénomène devient évident. " " L'architecture du logiciel est cohérente avec la structure de l'équipe logicielle
. pour le dire franchement : « Si vous laissez 4 équipes développer le même compilateur, le compilateur se retrouvera avec 4 étapes d'exécution. »
7.1 Archétypes organisationnels
Dans le domaine des sciences de la décision, il existe trois principaux types de structures organisationnelles : fonctionnelle, matricielle et marchande. Ils peuvent servir de référence pour concevoir des flux de valeur DevOps à l'aide de la loi de Conway.
- Les structures organisationnelles fonctionnelles se concentrent sur l’amélioration des compétences professionnelles, l’optimisation de la division du travail ou la réduction des coûts. Ces organisations se concentrent sur les compétences professionnelles, contribuent à promouvoir l’avancement de carrière et le développement des compétences et disposent souvent de structures organisationnelles à plusieurs niveaux. Les services opérationnels utilisent souvent cette structure organisationnelle (c'est-à-dire que les administrateurs de serveurs, les administrateurs réseau, les administrateurs de bases de données, etc. sont tous divisés en groupes distincts).
- La structure organisationnelle matricielle tente de combiner les types fonctionnels et de marché. Cependant, comme l’ont constaté beaucoup de ceux qui ont géré ou été impliqués dans des organisations matricielles, ces structures organisationnelles sont souvent très complexes. Par exemple, un employé peut relever de deux ou plusieurs gestionnaires. Parfois, les organisations matricielles ne peuvent atteindre les objectifs ni d’une structure fonctionnelle ni d’une structure de marché.
- Une structure organisationnelle orientée marché vise à répondre rapidement aux besoins des clients. Ce type d'organisation a souvent une structure plate, composée de plusieurs départements interfonctionnels (tels que les départements de marketing et d'ingénierie, etc.), et il peut souvent y avoir des redondances dans l'ensemble de l'organisation. De nombreuses organisations exceptionnelles mettant en œuvre DevOps adoptent cette structure. Donnez deux exemples extrêmes. Chez Amazon et Netflix, chaque équipe de service est responsable non seulement de la fourniture des fonctionnalités, mais également du support technique.
Après avoir compris les trois types de structures organisationnelles ci-dessus, explorons plus en détail pourquoi une orientation fonctionnelle excessive (en particulier dans le département des opérations) peut avoir un impact négatif sur la chaîne de valeur technologique, tout comme le prédit la loi de Conway.
7.2 Les dangers d’une orientation fonctionnelle excessive (« optimisation des coûts »)
Pour compliquer encore davantage le problème, les personnes qui effectuent le travail ne comprennent souvent pas vraiment le lien entre leur travail et les objectifs de la chaîne de valeur (« J'ai configuré ce serveur parce que quelqu'un d'autre me l'a demandé »). Cela empêche les employés d'être créatifs et proactifs.
Le problème est exacerbé si chaque équipe fonctionnelle du service des opérations doit servir plusieurs flux de valeur (c'est-à-dire plusieurs équipes de développement) en même temps, car le temps de toutes les équipes est précieux.
En plus d'entraîner de longues attentes et des délais de livraison allongés, cette situation peut également entraîner de mauvais transferts, des retouches importantes, une qualité de livraison réduite, des goulots d'étranglement et des retards.
Cette impasse empêche les organisations d’atteindre des objectifs importants qui dépassent de loin le désir de réduire les coûts.
7.3 Former une équipe orientée marché (« optimisation de la vitesse »)
D'une manière générale, pour réaliser DevOps, il est non seulement nécessaire de réduire l'impact négatif de l'orientation fonctionnelle (« optimisation des coûts »), mais aussi de mieux utiliser les effets de l'orientation marché (« optimisation de la vitesse »), de sorte que de nombreuses petites les équipes peuvent être en sécurité et indépendantes. Travailler efficacement et apporter rapidement de la valeur aux clients.
Dans les cas extrêmes, les équipes orientées marché sont responsables non seulement du développement des fonctionnalités, mais également des tests, de la sécurité, du déploiement et des opérations de l'environnement de production tout au long du cycle de vie de l'application. Ces équipes interfonctionnelles peuvent fonctionner de manière indépendante : elles sont capables de concevoir et de mener des expériences utilisateur, de créer et de fournir de nouvelles fonctionnalités, de déployer et d'exécuter des services en production et de corriger les défauts sans dépendre d'autres équipes, ce qui permet d'agir plus rapidement.
7.4 Rendre l'orientation fonctionnelle efficace
La section précédente suggérait de former une équipe orientée marché, mais il convient de mentionner que l'orientation fonctionnelle peut également conduire à une organisation efficace (voir Figure 7-1). La formation d’équipes interfonctionnelles et orientées marché est un moyen d’obtenir un flux rapide et fiable, mais ce n’est pas le seul. Tant que tous les acteurs de la chaîne de valeur sont conscients des objectifs du client et de l’organisation, peu importe où ils se trouvent dans l’organisation, ils peuvent atteindre les résultats DevOps attendus grâce à une orientation fonctionnelle.
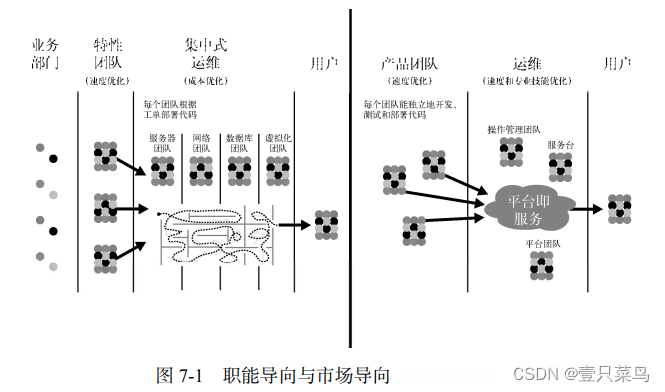
Le côté gauche est orienté fonctionnel : tout le travail passe par l'équipe centralisée d'exploitation et de maintenance informatique ; le côté droit est orienté vers le marché : toutes les équipes produit peuvent déployer des composants faiblement couplés dans l'environnement de production en libre-service.
7.5 Intégrer les tests, les opérations et la sécurité des informations dans le travail quotidien
Dans les organisations très performantes, les individus partagent des objectifs communs. Assurer la qualité, la disponibilité et la sécurité n'est pas la responsabilité d'un seul service mais fait partie du travail quotidien de chacun.
"L'analogie que j'utilise maintenant est que les Ops sont le joueur de ligne offensive et que Dev est responsable de postes importants (comme le quart-arrière ou le receveur large). Le travail de Dev est de précipiter le ballon, et le travail des Ops est de s'assurer que Dev a suffisamment de temps pour avancer. se précipiter.
7.6 Faire des membres de l'équipe des généralistes
Une solution consiste à faire de chaque membre de l’équipe un généraliste (voir Tableau 7-1). Donnez aux ingénieurs la possibilité d'acquérir les compétences nécessaires pour construire et exploiter les systèmes dont ils sont responsables, et faites-les régulièrement alterner entre différents rôles. Le terme ingénieur full-stack fait désormais généralement référence aux généralistes qui connaissent ou au moins ont une compréhension approximative de l'ensemble de la pile d'applications (par exemple, le code, la base de données, le système d'exploitation, le réseau et le cloud).
Tableau 7-1 Experts, généralistes et talents de type E
| Type I (Expert) | Forme en T (généraliste) | Type E |
|---|---|---|
| maîtriser un certain domaine | maîtriser un certain domaine | Maîtrise de certains domaines |
| Peu de compétences ou d'expérience dans d'autres domaines | Posséder des compétences dans de nombreux domaines | Avoir une expérience pratique dans plusieurs domaines, une forte capacité d'exécution et une capacité à innover continuellement |
| Bientôt rencontré un goulot d'étranglement | Peut surmonter les goulots d’étranglement | Potentiel illimité |
| Insensible aux déchets et aux impacts en aval | Sensible aux déchets et aux impacts en aval | |
| Résistez aux forfaits flexibles ou variables | Aider à développer des plans flexibles et modifiables |
Les talents de type E font référence à des personnes exceptionnelles sous quatre aspects : l'expérience, l'expertise, la capacité d'exploration et la capacité d'exécution.
Nous voulons encourager les employés à apprendre, les aider à surmonter l’anxiété liée à l’apprentissage et à acquérir des compétences pertinentes, et leur permettre de planifier clairement leur carrière, etc. Cela contribue à développer un état d’esprit de croissance chez les employés. Après tout, une organisation apprenante a besoin de personnes désireuses d’apprendre. En encourageant chaque employé à apprendre et en lui fournissant formation et soutien, nous construisons des équipes solides de la manière la plus durable et la plus rentable.
7.7 Investir dans des services et des produits, pas dans des projets
Une autre façon d’atteindre des performances élevées consiste à constituer une équipe de service stable et à leur fournir un financement continu pour leur permettre d’exécuter leurs stratégies et leurs plans. Ces équipes doivent disposer d'ingénieurs dédiés à la réalisation de promesses spécifiques aux clients internes ou externes, telles que des fonctionnalités, des histoires, des tâches, etc.
Un modèle d'investissement basé sur les produits se concentre sur les performances organisationnelles et les résultats pour les clients, y compris les revenus de l'entreprise, la valeur à vie du client et l'adoption par le client, tout en minimisant les efforts (par exemple, le temps et les efforts, les lignes de code, etc.). Cela contraste fortement avec les mesures de projet traditionnelles, telles que la question de savoir si le projet est achevé dans les délais, le budget et la portée établis.
7.8 Fixer les limites des équipes en fonction de la loi de Conway
Une organisation déraisonnable d'une équipe peut avoir des conséquences néfastes, ce qui est l'effet secondaire de la loi de Conway. Il s'agit notamment de diviser les équipes par fonction (par exemple en plaçant les développeurs et les testeurs dans différents bureaux, ou d'externaliser entièrement les testeurs) et de diviser les équipes par couches architecturales (telles que la couche d'application, la couche de base de données, etc.)
Idéalement, l’architecture du logiciel devrait garantir que les petites équipes peuvent fonctionner de manière indépendante et être entièrement découplées les unes des autres, évitant ainsi trop de communication et de coordination inutiles.
7.9 Créer une architecture faiblement couplée pour améliorer la productivité et la sécurité
Dans les architectures logicielles étroitement couplées, même de petits changements peuvent entraîner des pannes massives. Par conséquent, les développeurs responsables d'un certain composant doivent constamment se coordonner et communiquer avec les développeurs responsables d'autres composants, notamment en passant par divers processus complexes de gestion des changements.
L'architecture orientée services (SOA) possède cette caractéristique. Le concept d'architecture orientée services a été proposé dans les années 1990. Il s'agit d'une approche architecturale qui prend en charge les tests et le déploiement indépendants de services. Sa caractéristique typique est qu'elle consiste en des services faiblement couplés avec des contextes délimités.
Une architecture faiblement couplée signifie qu'un service peut être mis à jour indépendamment dans un environnement de production sans mettre à jour d'autres services. Le service doit être découplé des autres services et bases de données partagées (les services de bases de données peuvent être partagés, mais ils doivent s'assurer qu'ils n'ont pas de schéma de base de données commun)
L'idée derrière le contexte limité est que les développeurs doivent être capables de comprendre et de mettre à jour le code d'un service sans avoir à connaître la logique interne de son service homologue. Les services interagissent uniquement via des API et n'ont donc pas besoin de partager des structures de données, des schémas de base de données ou d'autres représentations internes d'objets. Les contextes délimités garantissent que les services sont divisés en parties indépendantes avec des interfaces clairement définies, ce qui facilite également les tests.
Garder les équipes petites (le « principe des deux pizzas »)
En 2002, Amazon a utilisé le « principe des deux pizzas » pour garder les équipes petites alors qu'elles tentaient de s'éloigner d'une base de code unique : deux pizzas suffisent pour tous les membres de l'équipe, donc L'équipe compte généralement de 5 à 10 personnes.
La loi de Conway nous aide à fixer les limites des équipes en fonction des modèles de communication souhaités, mais encourage également des équipes plus petites, moins de communication entre les équipes et le maintien du domaine d'expertise d'une équipe petit et délimité.
Cette limitation d’échelle a les quatre fonctions importantes suivantes :
- Cela garantit que les membres de l’équipe ont une compréhension claire et partagée du système. À mesure que les équipes s’agrandissent, la quantité d’informations qui doivent être communiquées augmente de façon exponentielle si chacun veut comprendre l’état du système.
- Cela limite le taux de croissance du produit ou du service en cours de développement. En limitant la taille de l’équipe, la vitesse à laquelle le système peut évoluer est également limitée, ce qui permet également de garantir que les membres de l’équipe ont la même compréhension du système.
- Il décentralise le pouvoir et permet l’autonomie. Chaque équipe de Two Pizza travaille de la manière la plus autonome possible. Le chef d'équipe relève directement de la direction, qui détermine les indicateurs clés d'affaires (également appelés fonctions de conditionnement physique) relevant de la responsabilité de l'équipe et les utilise comme critères d'évaluation globaux des pratiques de l'équipe. Les équipes sont alors en mesure de prendre des mesures autonomes pour maximiser cette métrique.
- Diriger une équipe Two-Pizza est un moyen pour les employés d’acquérir une expérience en leadership. Dans un tel environnement, l’échec ne serait pas catastrophique.
7.10 Résumé
Nous pouvons constater l’énorme impact de l’architecture et de la conception organisationnelle. Lorsque la loi de Conway est bien utilisée, les équipes peuvent développer, tester et fournir de la valeur aux clients en toute sécurité et de manière indépendante ; lorsqu'elle est mal utilisée, elle peut avoir des conséquences indésirables et conduire à la destruction de la sécurité et de l'agilité.
8. Intégrer l'exploitation et la maintenance dans le travail de développement quotidien
Notre objectif est d'être axé sur le marché et de permettre aux petites équipes d'apporter de la valeur aux clients de manière rapide et indépendante. Mais atteindre cet objectif est un défi dans une équipe opérationnelle centralisée et orientée fonctionnellement, qui doit répondre aux besoins disparates de nombreuses équipes de développement. En conséquence, les travaux d'exploitation et de maintenance nécessitent un long cycle de livraison, la priorité des travaux doit être ajustée à plusieurs reprises et les résultats du déploiement sont toujours insatisfaisants.
En dotant les équipes de développement de capacités opérationnelles plus solides, elles peuvent créer des résultats commerciaux davantage orientés vers le marché et, à terme, améliorer l'efficacité et la productivité.
Comment les équipes opérationnelles centralisées obtiennent des résultats axés sur le marché. Voici 3 stratégies générales :
- Créez des fonctionnalités en libre-service pour aider les développeurs à améliorer leur productivité ;
- Intégrer les ingénieurs d’exploitation et de maintenance dans l’équipe de service ;
- Si le nombre d’ingénieurs d’exploitation et de maintenance est restreint, le modèle de contact d’exploitation et de maintenance peut être adopté.
8.1 Créer des services partagés pour améliorer la productivité du développement
Si le service d'exploitation et de maintenance souhaite obtenir des résultats orientés marché, une approche consiste à créer une plate-forme centralisée et un ensemble d'outils afin que toutes les équipes de développement puissent améliorer la productivité en utilisant cette plate-forme et ce service, comme la création d'un environnement de production, le déploiement pipeline, outils de tests automatisés, console de télémétrie de l'environnement de production, etc. De cette façon, les équipes de développement peuvent consacrer plus d’énergie et de temps à la création de fonctionnalités au lieu d’acquérir l’infrastructure nécessaire pour fournir et prendre en charge les fonctionnalités en production.
Dans un monde idéal, toutes les plates-formes et services fournis par l'exploitation et la maintenance devraient être entièrement automatisés et disponibles à la demande. Les développeurs n'ont pas besoin de soumettre des ordres de travail et d'attendre ensuite que l'équipe d'exploitation et de maintenance les gère manuellement. Cela garantit que l'exploitation et la maintenance la maintenance ne devient pas des clients.
Les équipes internes de services partagés doivent continuer à explorer les chaînes d’outils qui peuvent être largement utilisées au sein de l’organisation, déterminer celles qui peuvent être fournies via des plateformes centralisées et les rendre accessibles à tous. En général, découvrir des outils éprouvés et étendre leur utilisation a plus de chances de réussir que de créer ces capacités à partir de zéro.
8.2 Intégrer les ingénieurs d'exploitation et de maintenance dans l'équipe de service
Une autre façon d'obtenir des résultats axés sur le marché consiste à rendre les équipes produit autonomes en intégrant des ingénieurs d'exploitation, réduisant ainsi la dépendance à l'égard des opérations centralisées. Ces équipes produit peuvent assumer l’entière responsabilité de la prestation de services et du support.
En intégrant des ingénieurs d'exploitation dans l'équipe de développement, leurs priorités de travail sont presque entièrement déterminées par les objectifs de leur équipe produit, plutôt que de se concentrer sur la résolution de leurs propres problèmes. En conséquence, les ingénieurs d’exploitation sont davantage connectés à leurs clients internes et externes. De plus, les équipes produit disposent souvent de budgets dédiés à l'embauche de ces ingénieurs d'exploitation, même si les décisions d'entretien et d'embauche peuvent toujours être prises par une équipe d'exploitation centralisée pour garantir la cohérence et la qualité des employés.
Pour les nouveaux projets de développement à grande échelle, des ingénieurs d’exploitation et de maintenance peuvent être intégrés au projet dès la phase de démarrage. Leur travail consiste à participer à l'aide aux décisions sur ce qu'il faut faire et comment le faire, à influencer l'architecture des produits, à aider à la sélection de technologies internes et externes, à créer de nouvelles fonctionnalités de plates-formes internes et même à générer de nouvelles capacités d'exploitation et de maintenance. Une fois le produit lancé, les ingénieurs d’exploitation et de maintenance peuvent aider l’équipe de développement à assumer les responsabilités d’exploitation et de maintenance.
Ce paradigme présente un avantage important : une coopération et une collaboration étroites entre les équipes de développement et les ingénieurs d'exploitation et de maintenance sont un moyen extrêmement efficace d'intégrer les connaissances d'exploitation et de maintenance dans l'équipe de service grâce à une formation croisée, et peuvent également transformer progressivement les connaissances d'exploitation et de maintenance en Automatisation. code pour le rendre plus fiable et plus largement réutilisable
8.3 Attribuer une personne de contact pour l'exploitation et la maintenance à chaque équipe de service
Pour diverses raisons (telles que le coût ou le manque de ressources), il peut ne pas être possible d'affecter des ingénieurs d'exploitation et de maintenance à chaque équipe produit, mais vous pouvez affecter une personne de contact pour l'exploitation et la maintenance à chaque équipe produit. peut également obtenir des résultats similaires.
L'équipe des opérations centralisées gère toujours tous les environnements (pas seulement la production, mais aussi la pré-production) et est chargée d'assurer leur cohérence. L'ingénieur d'exploitation et de maintenance dépêché est chargé de comprendre les éléments suivants :
- Quelles sont les fonctions du nouveau produit et pourquoi ce produit devrait-il être développé ?
- Comment il fonctionne, dans quelle mesure il est opérationnel, dans quelle mesure ses capacités sont évolutives et de surveillance (des illustrations sont fortement recommandées) ;
- Comment suivre et collecter les indicateurs, et comment confirmer le bon fonctionnement de l'application ;
- L'architecture et les modèles sont-ils différents de ce qui a été fait dans le passé et quelles en sont les raisons ?
- S'il existe une demande supplémentaire pour l'infrastructure et comment son utilisation affecte la capacité de l'infrastructure ;
- Calendrier de sortie des fonctionnalités.
Par rapport au modèle d'intégration des ingénieurs d'exploitation et de maintenance, l'attribution de contacts d'exploitation et de maintenance peut prendre en charge davantage d'équipes de produits. Notre objectif est de garantir que les opérations ne deviennent pas un goulot d'étranglement pour les équipes produit. Si vous constatez que les équipes produit ne parviennent pas à atteindre leurs objectifs parce que la charge de travail du contact opérationnel est trop élevée, vous devrez peut-être réduire le nombre d'équipes supportées par chaque contact ou intégrer temporairement des ingénieurs opérationnels dans certaines équipes produit.
8.4 Inviter les ingénieurs d'exploitation et de maintenance à participer aux réunions de l'équipe de développement
Notre objectif est d'aider les ingénieurs d'exploitation et autres non-développeurs à mieux comprendre la culture de l'équipe de développement actuelle et à participer de manière proactive à la planification et au travail quotidien, afin que l'équipe des opérations puisse mieux intégrer les capacités opérationnelles dans l'équipe produit et mettre en œuvre le travail pertinent. avant le lancement du produit.
8.4.1 Inviter les ingénieurs d'exploitation et de maintenance à participer à des réunions debout quotidiennes
Le but du stand-up quotidien est de partager des informations au sein de l'équipe et de comprendre tout le travail effectué et à effectuer. En permettant aux membres de l’équipe de partager des informations entre eux, ils peuvent identifier les tâches difficiles puis recourir à l’entraide pour trouver des solutions pour faire avancer le travail dans son ensemble. De plus, la présence du chef d’équipe peut accélérer la résolution des conflits de priorités et de ressources.
Certaines informations sont dispersées au sein de l’équipe de développement, ce qui constitue un problème courant. Avec la participation des ingénieurs d'exploitation à la réunion, le service des opérations peut pleinement comprendre les activités de l'équipe de développement, permettant une meilleure planification et préparation.
8.4.2 Inviter les ingénieurs d'exploitation et de maintenance à participer aux réunions d'examen
Les ingénieurs d’exploitation peuvent fournir les commentaires suivants lors des réunions rétrospectives.
- "Il y a deux semaines, nous avons découvert un angle mort dans la surveillance et l'équipe est parvenue à un accord sur la manière de le résoudre. Le problème est désormais résolu. Mardi dernier, le système de surveillance a reçu un événement d'alarme et nous avons rapidement localisé le défaut. . Et prenez-en soin avant que le service client ne soit affecté. "
- "Le déploiement de la semaine dernière a été le plus difficile et le plus long de l'année. Voici quelques idées d'amélioration à partager avec vous."
- "Les promotions marketing menées la semaine dernière ont été beaucoup plus difficiles que prévu. Nous ne devrions pas organiser à nouveau des promotions similaires. Afin d'atteindre l'objectif de vente, nous pouvons en fait essayer d'autres solutions."
- "Lors du dernier déploiement, le plus gros problème était que les règles de pare-feu dans l'environnement de production comportaient déjà des milliers de lignes, ce qui rendait chaque modification très difficile et risquée. Nous devrions envisager de repenser les règles de contrôle du trafic réseau. . "
Les commentaires de l'équipe opérationnelle peuvent aider l'équipe produit à mieux reconnaître et comprendre l'impact des décisions qu'elle prend sur les équipes en aval. Lorsque des impacts négatifs se produisent, nous devons apporter les changements appropriés pour éviter que des situations similaires ne se reproduisent à l’avenir. Dans le même temps, les commentaires de l'équipe d'exploitation et de maintenance peuvent également aider à découvrir davantage de problèmes et de défauts, et peuvent même aider l'équipe à découvrir certains problèmes architecturaux.
Les rétrospectives d'équipe peuvent également identifier des améliorations telles que la correction de bugs, la refactorisation et l'automatisation des opérations manuelles.
8.4.3 Utiliser le diagramme Kanban pour afficher les travaux d'exploitation et de maintenance
Étant donné que le travail opérationnel fait partie de la chaîne de valeur, il doit être présenté sur le diagramme Kanban avec les autres travaux liés à la livraison du produit. De cette façon, l'équipe peut voir plus clairement tout le travail qui doit être effectué pour publier le code dans l'environnement de production et suivre toutes les opérations et travaux de maintenance liés au support produit. De plus, l'équipe peut voir à partir du tableau de bord quels travaux d'exploitation et de maintenance sont bloqués et quels domaines doivent être améliorés.
Les graphiques Kanban sont un outil idéal pour la gestion visuelle du travail. La visualisation est essentielle pour intégrer les efforts opérationnels dans la chaîne de valeur du produit. Si nous le faisons bien, nous pouvons obtenir des résultats axés sur le marché, quels que soient les changements dans la structure organisationnelle.
8.5 Résumé
Ce chapitre explore comment les opérations peuvent être intégrées dans le travail quotidien d'une équipe de développement et comment les opérations peuvent être visualisées. Il existe trois manières de procéder : créer des services partagés pour améliorer la productivité du développement ; intégrer des ingénieurs d'exploitation et de maintenance dans les équipes de service ; attribuer des contacts d'exploitation et de maintenance à chaque équipe de service. Enfin, le chapitre décrit comment les ingénieurs d'exploitation s'intègrent dans le travail quotidien de l'équipe de développement, notamment en participant à des stand-ups quotidiens, à des réunions de planification et à des rétrospectives.