Multi-Grained Vision Language Pre-Training: Aligning Texts with VisualConceptsMulti-Grained Vision Language Pre-Training: Aligning Texts with VisualConcepts
Contributions to this article
- Multi-granular visual language pre-training is proposed to handle the alignment problem between text and visual concepts.
- proposed an optimization model (X-VLM) by locating visual concepts in images and simultaneously aligning text with visual concepts, where the alignment is multi-granular.
- Empirically verified, our method effectively leverages the learned multi-granularity alignment in fine-tuning. X-VLMbase with 256×256 image resolution achieves substantial improvements over existing state-of-the-art methods on many downstream V+L tasks.
Summary
Most existing visual language pre-training methods rely on object-centered features extracted through object detectors and perform fine-grained alignment between the extracted features and text. Learning relationships between multiple objects is challenging for these methods. To this end, we propose a new method called X-VLM for "multi-granularity visual language pre-training". The key to learning multi-granularity alignment is to localize visual concepts in images given relevant text, while simultaneously aligning text with visual concepts, where the alignment is multi-granular . Experimental results show that X-VLM effectively leverages the learned multi-granularity alignment to perform many downstream visual language tasks and consistently outperforms state-of-the-art methods.
Introduction
Existing methods for learning visual language alignment can be divided into two types, as shown in Figure 1. Most detect objects in images and align text with fine-grained (object-centered) features. They either leverage pre-trained object detectors or perform real-time object detection during pre-training. Other methods do not rely on object detection, but only learn the alignment between coarse-grained features of text and images.

Figure 1: (a) Comparison of (a) existing object detection-based methods, (b) methods for aligning text to the entire image, and (c) our method.
The multi-granularity model, X-VLM, consists of an image encoder, a text encoder, and a cross-modal encoder that performs cross-attention between visual features and linguistic features to learn visual-linguistic arrangements. X-VLM utilizes a simple hybrid attention mechanism to implement the image encoder, so the encoder produces an image representation with full attention and a region/object representation with local attention. The learning of X-VLM is optimized by locating visual concepts in images given relevant text, while aligning text with visual concepts, such as through contrastive loss, matching loss and masked language modeling loss, where the alignment is multi-granular , as shown in Figure 1(c). During fine-tuning and inference, without bounding box annotations in the input image, X-VLM can still leverage the learned multi-granularity alignment to perform downstream V+L tasks.
Related work
Existing visual language pre-training work falls into two categories: fine-grained and coarse-grained.
Most existing methods are fine-grained, which rely on object detection. The object detector first identifies all regions that may contain objects and then classifies each region as an object. An image is then represented by dozens of object-centered features of the identified region. The challenge with this approach is that VLMs based on object-centered features cannot represent the relationships between multiple objects in multiple regions. Furthermore, it is not easy to define the categories of objects in advance, which is helpful for learning VLMs.
Coarse-grained methods build VLMs by extracting and encoding overall image features through convolutional networks or visual transformers. While object-centric features are only relevant to certain objects, fine-grained features appear to be crucial for learning VLMs. To solve this problem, Huang uses online clustering on the overall image features to obtain a more comprehensive representation, Kim uses a more advanced visual transformer, namely Swin-Transformer, for image encoding, and ALBEF combines contrastive learning and momentum distillation. However, these improvements still fail to close the gap with refined methods when the training corpus is of the same order of magnitude. Unlike previous works that adopted either fine-grained or coarse-grained approaches, we propose multi-granularity visual language pre-training.
method
X-VLM consists of an image encoder (I-trans), a text encoder (T-trans) and a cross-modal encoder (X-trans). All encoders are Transformer based. We reformulate the widely used pre-training dataset so that an image can have multiple regions surrounded by bounding boxes, and each region is associated with text describing the object or region, denoted as (I,T,{( V j ,T j )} N ). Note that some images have no associated text, i.e. T is NaN, and some images have no bounding box, i.e. N=0. Here, V j is an object or region in the image, which is associated with the bounding box b j = (cx, cy, w, h), represented by the normalized center coordinates, width and height of the box.
image encoder
We propose a simple hybrid attention mechanism based on the visual transformer shown in Figure 2. It produces multi-granularity visual concept representations in images with low computational overhead.
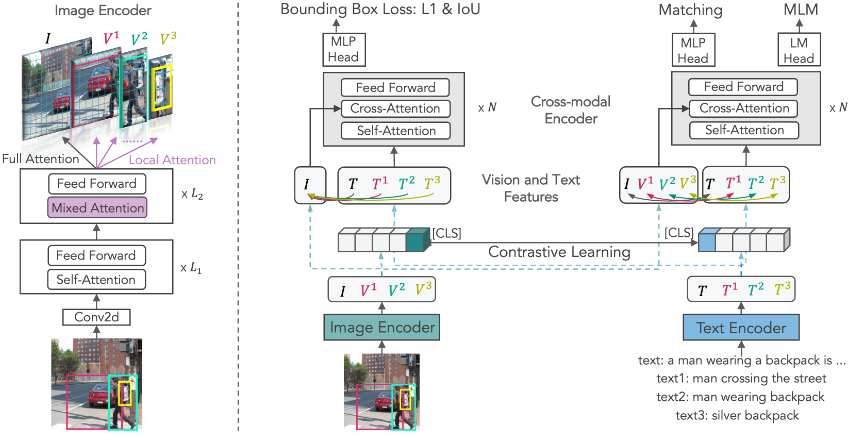
Figure 2: Schematic diagram of the proposed multi-granularity visual language pre-training method
The encoder first divides an image into non-overlapping 16x16 blocks and linearly embeds all blocks to obtain {v01,…,v0NI}. For a 256x256 resolution image, we have N I =256. We denote the embedding of [CLS] as v0 cls to represent the entire image. In the first L1 layer , we perform bidirectional attention on all blocks, i.e. full attention. If there are N regions in the image, we copy the block representation of the context {vL1cls, vL11,…,vL1NI} into N+1 copies, where we apply full attention to one copy and to the other copies in the following L 2 layers Apply local attention.
A region V j corresponds to a set of image patches, which we denote as {pj1,…,pjM}. We add a self-attention mask in the L1 + 1 to L1 + L2 conversion layer to achieve local attention.
Cross-modal modeling
As shown in Figure 2, we locate visual concepts in images, give corresponding text descriptions, and align text and visual concepts at the same time, where the alignment is multi-granular.
Pre-training goals of X-VLM: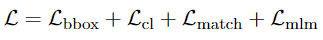
Bounding Box Prediction (Bounding Box Prediction) We let the model preset the bounding box bj of the visual concept Vj, and give full attention to the image representation and text representation, where bj = (cx, cy, w, h). By locating different visual concepts in the same image, we expect the model to better learn fine-grained visual-linguistic arrangements.
Contrastive Learning is similar to CLIP, and X-VLM also uses contrastive loss. We predict (visual concept, text) pairs, representation (V, T), from within-batch negations. Note that visual concepts include objects, regions, and images. Randomly sample N image-text pairs (1 batch), (V, T) is a positive sample, and V and other texts T i in the same batch form N-1 negative samples.
Matching Prediction We determine whether a pair of visual concepts and text match. For each visual concept in a mini-batch, sample hard negative text in a batch. We also extract a hard negative visual concept for each text. We use the output [CLS] embedding of the cross-modal encoder to predict the match probability p^match.
Masked Language Modeling: We predict task words in text based on visual concepts. We randomly mask the input tokens with a probability of 25%, and the replacement tokens are 10% random tokens, 10% invariant tokens, and 80% [MASK]. We use the output of the cross-modal encoder and append a linear layer followed by softmax prediction.
experiment
Pre-training data set
Following UNITER and other existing works, we build our pre-training data using two in-domain datasets, COCO and Visual Genome (VG), and two out-of-domain datasets, SBU Cap-tions and Conceptual Cap-tions (CC). The total number of single images is 4.0M and the number of image-text pairs is 5.1M. Following ALBEF, we also utilize the noisier Conceptual 12M dataset (CC-12M), increasing the total number of images to 14M. Image annotations are from COCO and VG, which contain 2.5 million object annotations and 3.7 million region annotations for 200K images.
Existing methods exploit the data by training object detectors or using region annotations, assuming that they can describe the entire image. Instead, we treat object labels as textual descriptions of objects, and reformulate image annotations so that an image has multiple regions surrounded by bounding boxes, each region associated with a text. Since most downstream V+L tasks are built on top of COCO and VG, we exclude all images that also appear in the validation and test sets of downstream tasks to avoid information leakage. We also excluded all co-occurring Flickr30K images via URL matching, since both COCO and VG are from Flickr and there is some overlap.
Implementation details
The image encoder is a 12-layer ViT base with 86M parameters, initialized with weights pretrained on ImageNet-1k by Touvron et al. The text encoder and cross-modal encoder are each a six-layer BERT base with a total of 124M parameters. The text encoder is initialized using the first six layers of the BERT base , while the cross-modal encoder is initialized using the last six layers. For text input, we set the maximum number of tokens to 25.
X-VLM base accepts 256×256 resolution images as input. The image encoder splits an image into 16×16 overlapping parts. We employ full attention for the first eight layers and hybrid attention for the last four layers. During the fine-tuning process, we increase the image resolution to 384×384 and perform mutual inference on the position embeddings of image patches.
We pre-trained the model 50 times with mixed precision on 32 NVIDIA V100 GPUs. The batch size is set to 3072, and we sample the data by having half of the images in a batch contain bounding box annotations. Training with 4 million images takes three days. We use the AdamW optimizer with a weight decay of 0.02. The learning rate warms up from 1e-5 to 1e-4 in the first 1/5 iterations and then decays to 1e-5 times following a cosine schedule.
Downstream tasks
Image-text retrieval has two subtasks: text retrieval (TR) and image retrieval (IR). We evaluate X-VLM on the MSCOCO and Flickr30K benchmark datasets. We have optimized and fine-tuned L cl and L match . In inference, we first calculate (I,T) for all images and texts, then take the top k candidates and calculate p match (I,T) for ranking. According to ALBEF, MSCOCO's k is set to 256 and Flickr30K's k is set to 128.
Evaluation of image-text retrieval
Table 1 compares X-VLM with SoTA methods on MSCOCO and Flickr30K. Under the setting of 4M, X-VLM outperforms all previous methods based on object-centered features or overall image features by a large margin, demonstrating the effectiveness of our multi-granularity approach. Furthermore, when trained with more instances (14M), X-VLM also achieves new SoTA results by a large margin, surpassing all existing methods, including ALIGN trained with an in-house 1.8B dataset. X-VLM (14M) also achieves considerable improvement compared to X-VLM (4M), which shows that our method is scalable with more network data.
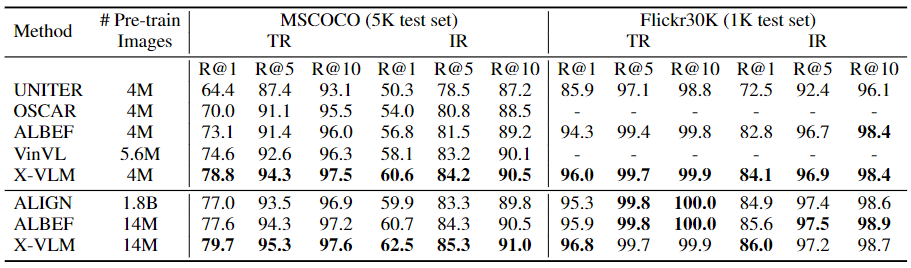
Table 1: Image-text retrieval results for MSCOCO and Flickr30K datasets. IR: image retrieval, TR: text retrieval
ablation study
Table 3 provides the results of ablation studies on X-VLM (4M). We use R@1 as the evaluation index for retrieval tasks and Meta-Sum as the general index. We report two Meta-Sum scores: one is the sum of all scores, and the other is marked with * and does not include the results of supervised RefCOCO+. First, we evaluate the effectiveness of visual concepts at different granularities, namely object-free and region-free. The results show that training without using these two concepts hurts performance, illustrating the necessity of learning multi-granularity alignment. Furthermore, we can observe that,without regions degrades the performance more,compared to objects. Furthermore, ablation studies show that bounding box prediction is an important component of X-VLM, as no bounding box loss results in the lowest Meta-Sum. Especially for RefCOCO+, there was a decrease of 3.6% (average of the indicator). As shown in Table 3, the hybrid attention mechanism also brings performance improvements.
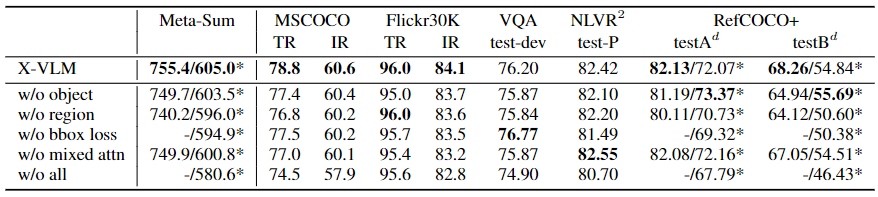
Table 3: Ablation study on X-VLM: w/o object refers to training without object concept; w/o region refers to training without region concept; w/o bbox loss refers to no bounding box prediction; w/o Mixed attn refers to the complete application of local attention to obtain refined conceptual representation; w/o all means the removal of all the above components.
With hybrid attention, object or region representations encoding image context information are more accurate. Hybrid attention is also an efficient implementation, which can save 50% of GPU memory. Overall, although different components in X-VLM perform differently in various downstream V+L tasks, they all contribute to improved overall performance and/or efficient implementation.
We also report "exclusive of all" results. Although only 5.0% of images in the 4M setting have dense annotations, X-VLM can exploit this data and greatly improve the performance of downstream V+L tasks (Meta-Sum from 580.6 to 605.2 ) . As mentioned above, X-VLM (14M) can still achieve considerable improvements over X-VLM (4M) when trained with more image-text pairs. It is worth noting that in the 14M setting, only 1.4% of the images are annotated. The results show that our X-VLM method can scale to large-scale data. We can also see that fine-grained visual concepts, such as objects, are much less diverse than images. However, they are still an integral part of the image and have a significant impact on learning visual language alignment.
in conclusion
Existing visual language models either utilize fine-grained object-centered image features or coarse-grained overall features of the image. Although effective, both methods still have some drawbacks. In this paper, we reconstruct existing datasets into image/region/object-text pairs and propose X-VLM, a new method for multi-granularity visual language pre-training. The training of the model is driven by locating visual concepts in images and aligning text with related visual concepts, where the alignment is multi-granular. Experiments on many V+L tasks show that X-VLM achieves substantial improvements over existing SoTA methods.
Recommended reading: X-VLM