NeRF is an article published in ECCV 2020 and won the title of Best Paper that year. This technology amazed everyone as soon as it was proposed. NeRF is currently also a very interesting and hot research direction in the field of computer vision. The blogger's subsequent research direction will also focus on NeRF. Everyone who is interested in neural radiation fields is welcome to communicate and learn together!
Paper: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Code: https://github.com/bmild/nerf
What is NeRF?
The full name of NeRF is Neural Radiance Fields. It uses neural radiation fields as scene representation to synthesize new views. As a project using neural networks, NeRF uses a relatively simple multi-layer perceptron (MLP) as the network part, so it is a differentiable rendering method. The simple understanding of differentiable rendering is in the technology it uses. Its operation part can be differentiated or derived.
The reason why NeRF has received a lot of attention is that it renders great effects and fine details. NeRF mainly uses volume rendering technology. Volume rendering is a method of tracing rays and integrating or accumulating rays to generate images. NeRF uses MLP to encode points on the light into color and density values, and stores the represented scene in the weight of the MLP. The input is a lot of pictures with known camera poses, which are trained to obtain scene representations, which can then be rendered . Pictures from a perspective never seen before.
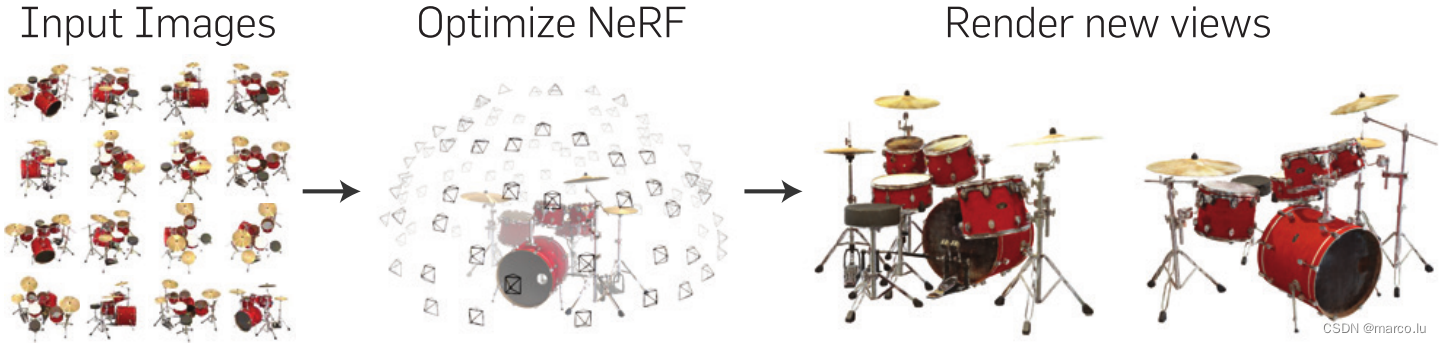
core content:
- Volume Rendering
- MLP
- Positional Encoding
- Hierarchical Sampling
NeRF principle
The input of NeRF is a set of 5-dimensional data: three-dimensional coordinates and two-dimensional viewing direction
.

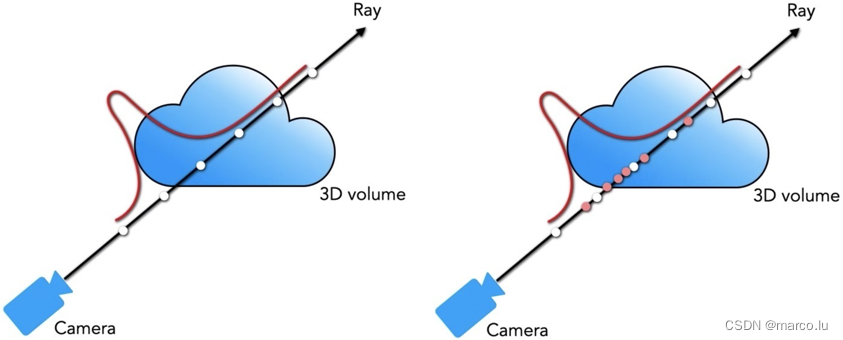
Radiation Field-Volume Rendering
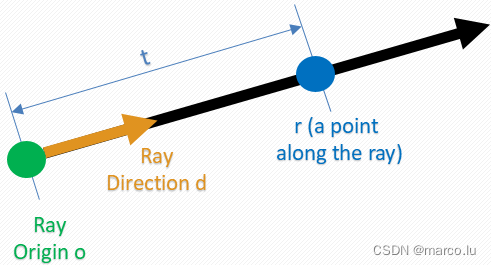
Ray formula:
where o is the starting position of the light, t is the distance traveled by the light, and d is the direction of the light. The two-dimensional viewing angle direction can be obtained according to the ray formula .
The color value formula of light:
![]()
C(r) is the color displayed by a light ray. This formula is the optical model in volume rendering. Sigma is the volume density (extinction coefficient), c is the light intensity at the t position on r to the d direction, and T is the accumulated transparency from tn to t .
For the derivation of the formula here, you can refer to another expert’s blog: Derivation of mathematical formulas in NeRF
Positional Encoding
The paper mentions two methods for optimizing the neural radiation field. The first is high-frequency position encoding . If the five-dimensional data is directly input into the neural network, the rendering will be poorly represented in the high-frequency areas of color and geometry, because the characteristic of the neural network is that it tends to learn low-frequency functions. If there is a lack of high-frequency information in the network, this phenomenon will will be more obvious. The author maps all five-dimensional data to vectors containing high-frequency signals.
![]()
![]()
This method is similar to the Fourier transform. In the article, the author obtained through experiments: the three terms of the spatial coordinates are L=10 , and the two terms of the direction are L=4. In this way, the input of spatial coordinates becomes 3*2*10=60 input quantities, and the input of direction becomes 3*2*4= 24 input quantities (here θ and φ are mapped to a three-dimensional space vector, so it is three-dimensional enter).
The difference between using positional encoding and not using positional encoding:
Hierarchical Sampling
Another method to optimize the neural radiation field is hierarchical sampling. If an average of 64 points are sampled for a ray, many points may not reach the target (in the air), and the area containing the object may be undersampled. If it is purely linear Increasing sampling points does not fundamentally solve the problem.
Stratified sampling uses two layers of MLP to calculate two batches of sampling points. The sampling points of the second batch are based on the output results of the first network. The first network is called a coarse network ( coarse ), and the second network is called a fine network ( Fine ).
Stratified sampling: divide [tn,tf] into N uniform intervals

Light color estimate:
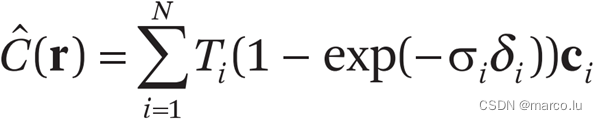

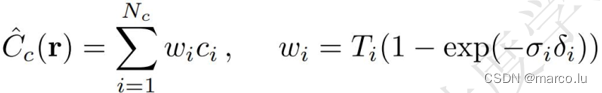
The weights can be viewed as piecewise constant probability density functions (Piecewise-constant PDF) along the ray.
Network
NeRF's network consists of 8 layers of MLP, the input is (x, y, z, θ, φ), and the output is RGB and volume density σ.

Loss
The loss function of NeRF is a mean square error:
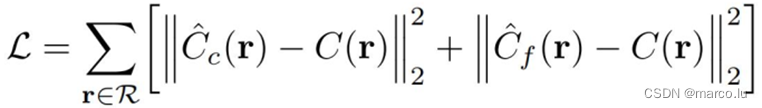
Disadvantages of NeRF
- Its training and inference speed are very slow. I use a 2080ti and it takes 8.5h to train, and the inference speed is about 1s per frame;
- Can only handle static scenes;
- The handling of lighting is not ideal;
- The trained models can only represent one scene and have no generalization ability.
Summarize
Putting aside the shortcomings of NeRF, its effect is still very cool, and with the deepening of research, many optimized versions of NeRF have been born. The integration of NeRF with SLAM, autonomous driving and other directions is still a very interesting research direction.
The blogger will continue to publish blogs that reproduce NeRF in the future. Interested friends are welcome to pay more attention, discuss and learn!