Trees and binary trees in data structures are two extremely important concepts in establishing nonlinear data structures. They can not only simulate the complex relationships of various practical problems in life, but are also often used to implement algorithms such as search, sorting, and lookup, and even become infrastructure in some large-scale software and systems.
Whether you are a beginner or an advanced person, this article will provide you with simple, easy-to-understand, practical and feasible knowledge points to help you better grasp the importance of trees and binary trees in data structures and algorithms, thereby improving the ability of algorithms to solve problems. ability. Next, let us embark on a wonderful journey of data structures and algorithms.
Table of contents
The definition and properties of binary tree
Trees and forest concept
Definition of tree: A tree is a non-linear data structure consisting of nodes and edges. The basic concept of a tree is to organize and represent data in a hierarchical structure.
In a tree, there is a special node called the root node, which is the top node of the tree. All other nodes are directly or indirectly connected to the root node. In addition to the root node, each node can have zero or more child nodes (child), and child nodes can have their own child nodes, forming a branch structure of the tree. Nodes without child nodes are called leaf nodes (leaf) or leaf nodes, and they are located at the lowest level of the tree. The connections between nodes are called edges, and edges describe the relationships between nodes. Each node can have zero to many edges connected to its child nodes. There is a unique path between any two nodes through which one can reach another node.
The structure of a tree has the followingcharacteristics:
- A tree can consist of zero or more nodes.
- There is one and only one root node, which is the starting point of the tree.
- Each node can have zero or more child nodes.
- Nodes are connected through edges to form a hierarchical structure.
- Each node, except the root node, has one and only one parent node.

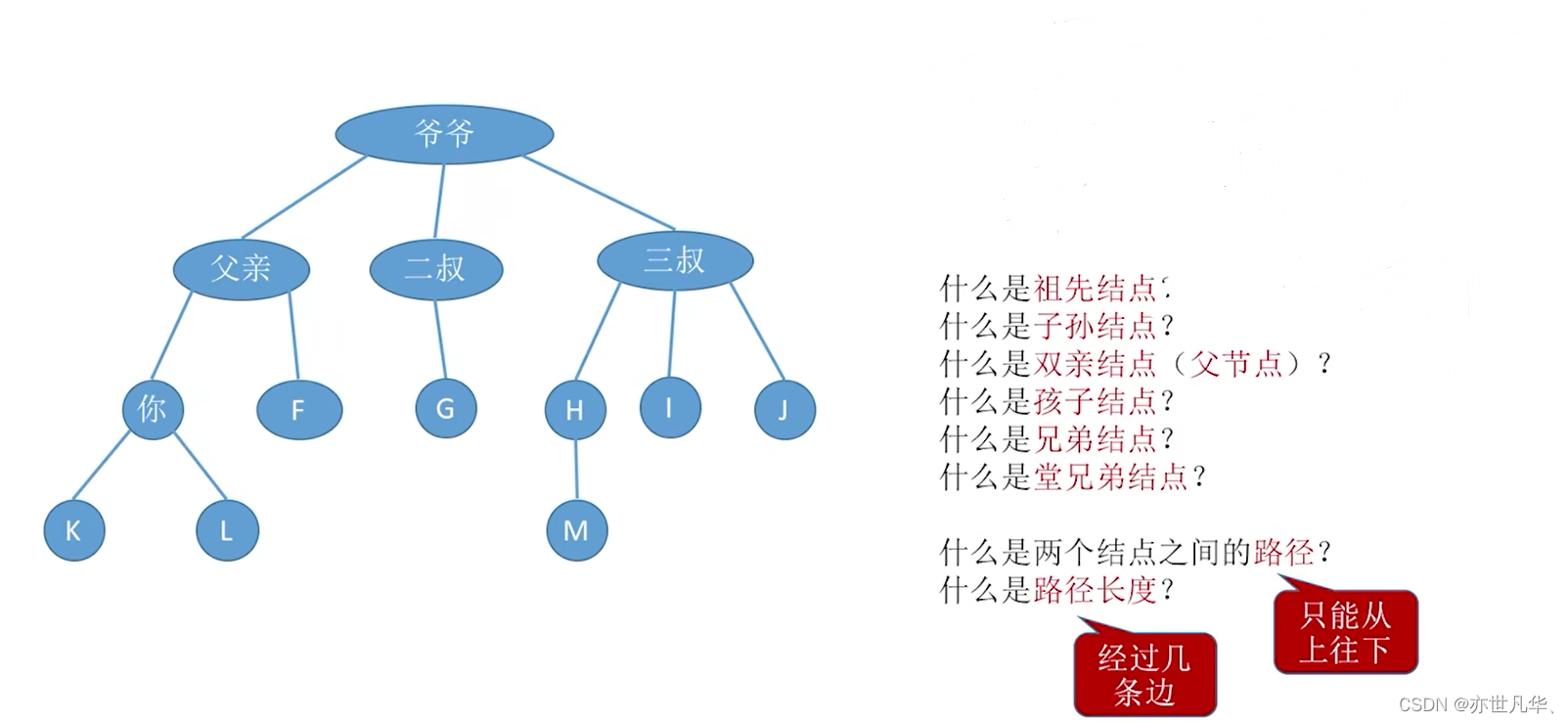
Basic terminology for trees:
Description of relationships between nodes
Root Node: The top-level node of the tree is called the root node. The root node is the starting point of the tree. It has no parent node. All other nodes are directly or indirectly connected to the root node.
Ancestor Node: For a node, all its superior nodes (including parent nodes, parent nodes of parent nodes, etc.) are called ancestor nodes of the node.
Descendant Node: For a node, all its subordinate nodes (including child nodes, child nodes of child nodes, etc.) are called descendant nodes of the node.
Parent Node: The node directly above a node is called its parent node. Each node can have zero or more child nodes, but can only have one parent node (except the root node).
Child Node: The next-level node directly connected to a node is called its child node. A node can have zero or more child nodes.
Sibling Node: Nodes with the same parent node are called sibling nodes. Sibling nodes are on the same level.
Leaf Node: Also called leaf node, it is a node without child nodes and is located at the bottom of the tree.
Level: The root node is on the first level, its direct child nodes are on the second level, and so on. The number of levels at which a node is located is the level of the node.
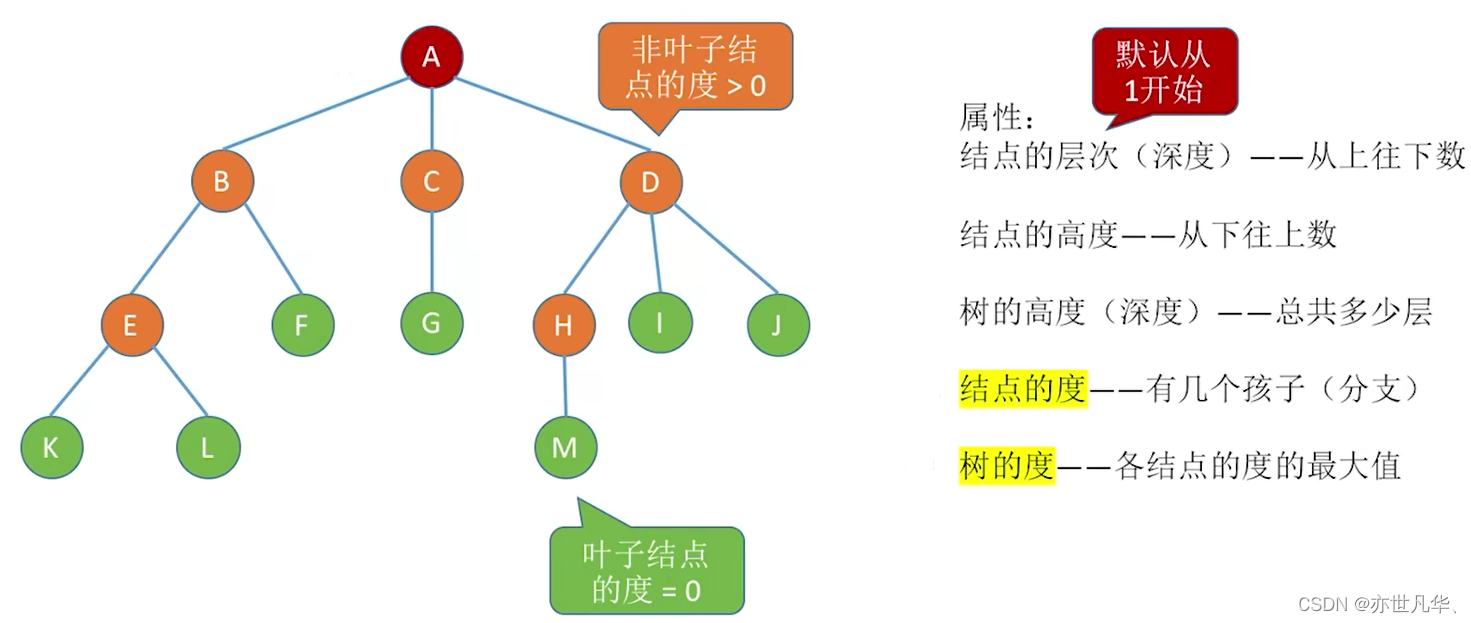
Attribute description of nodes and trees
Node Value: Each node can carry a value or data, indicating the actual meaning or information represented by the node.
Node Depth: Node depth refers to the path length from the node to the root node, that is, the number of edges from the root node to the node. The depth of the root node is 0.
Node Height: Node height refers to the path length from the node to its farthest leaf node, that is, the number of edges from the node to the farthest leaf node. The height of leaf nodes is 0.
Subtree: For a node in a tree, the subtree that can be formed with the node as the root is called the subtree of the node.
Tree Size: refers to the total number of nodes contained in the tree.
Tree Height: refers to the maximum height of any node in the tree. It can also be understood as the maximum value of the path length from the root node to the farthest leaf node.
Ordered tree, unordered tree
Ordered Tree: An ordered tree means that there is a clear order relationship between the child nodes in the tree. In an ordered tree, each child node has a well-defined position and needs to be considered in order when traversing and representing the tree. For example, siblings in a family tree are generally listed in the order in which they were born.
Unordered Tree: An unordered tree means that there is no clear order relationship between the child nodes in the tree. In an unordered tree, all child nodes are equal and there is no priority. For example, the directory structure in a file system is an unordered tree in which subdirectories are in no particular order.
The difference between an ordered tree and an unordered tree lies in the arrangement of the child nodes. In an ordered tree, the order of child nodes is important and will affect the structure and meaning of the tree; in an unordered tree, the order of child nodes is not important, you only need to know that they are the child nodes of the node.

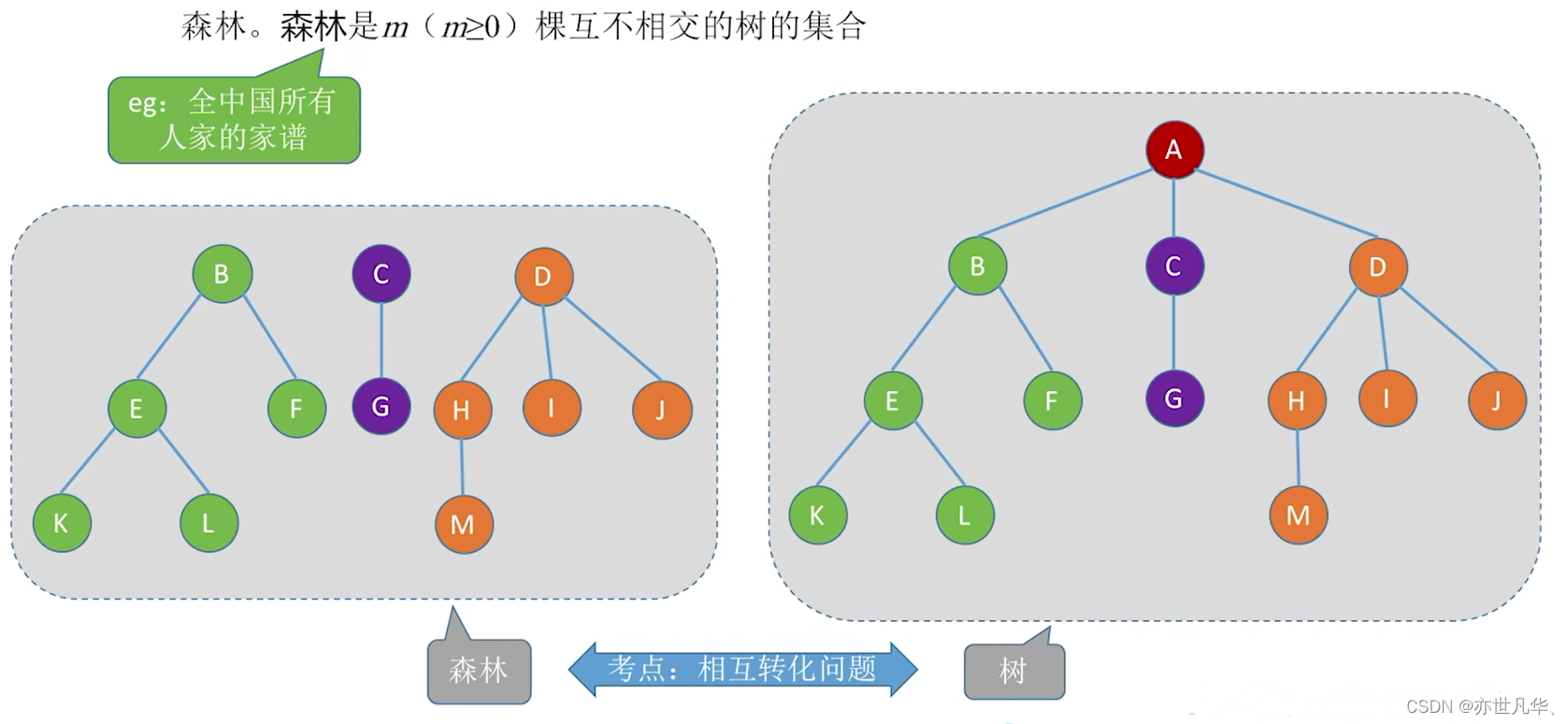
forest
Forest refers to a collection of multiple trees. Simply put, a forest can be viewed as a collection of independent trees.
The characteristic of a forest is that its trees are independent of each other and have no direct connections or relationships with each other. Each tree can be traversed and manipulated independently.
It should be noted that forest and tree hierarchy are different concepts. A tree is a hierarchical structure that has a unique root node and a definite path from the root node to other nodes; while a forest is a collection of multiple independent trees, and there is no direct connection between any two trees in the forest.
Abstract data type of tree:
The abstract data type of tree defines a set of basic operations for operating on trees, including the following common operations:
1) Create tree: Create an empty tree data structure.
2) Insert node: Insert a new node in the tree and establish relationships between nodes.
3) Delete node: Delete the specified node from the tree and adjust the relationship between nodes.
4) Traverse the tree: Access the nodes in the tree in a specific order, such as pre-order traversal, in-order traversal, post-order traversal, etc.
5) Find node: Find the specified node in the tree.
6) Get the attributes of the tree: Get the height, number of nodes, root node and other attribute information of the tree.
The abstract data type of a tree does not focus on the specific implementation, but defines the operations that can be performed on the tree and the expected behavior of these operations.
Reviewing the key points, the main contents are summarized as follows:
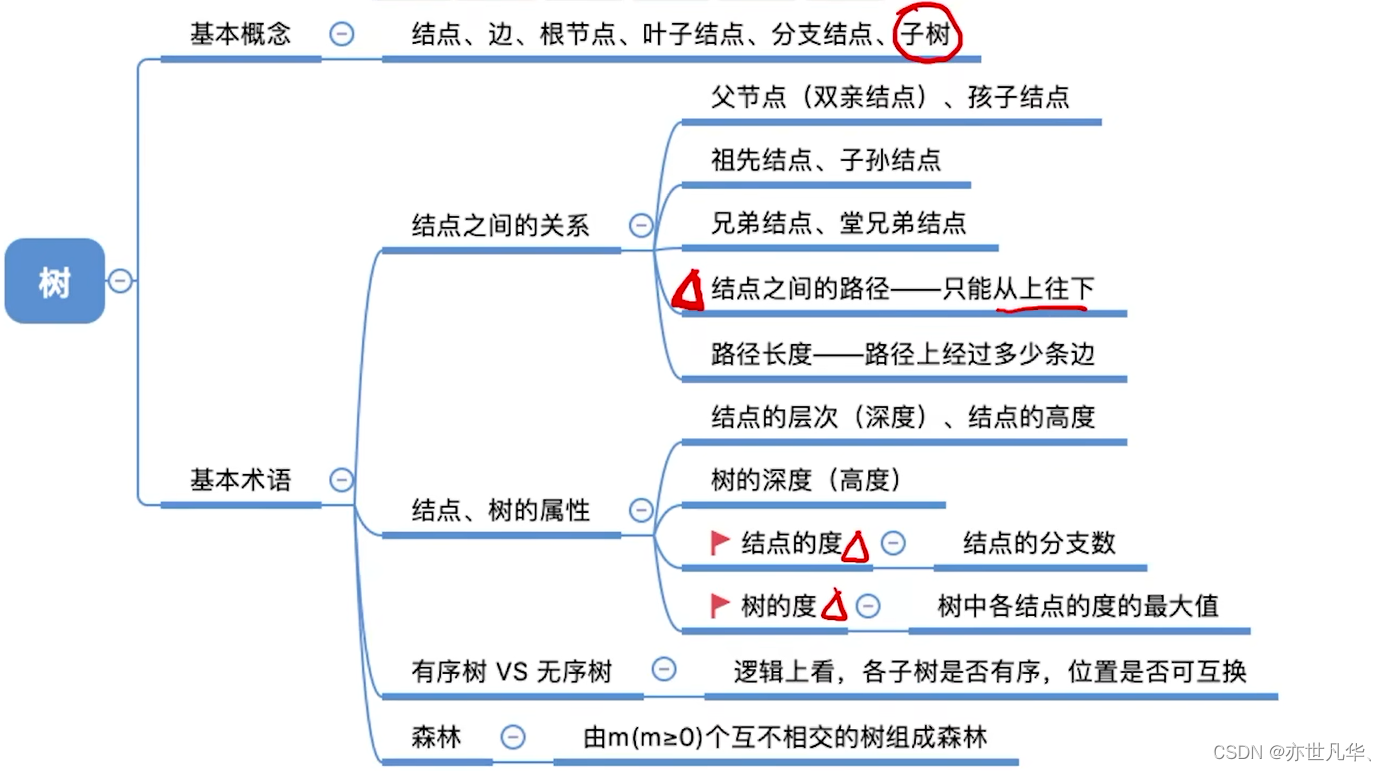
Common properties of trees
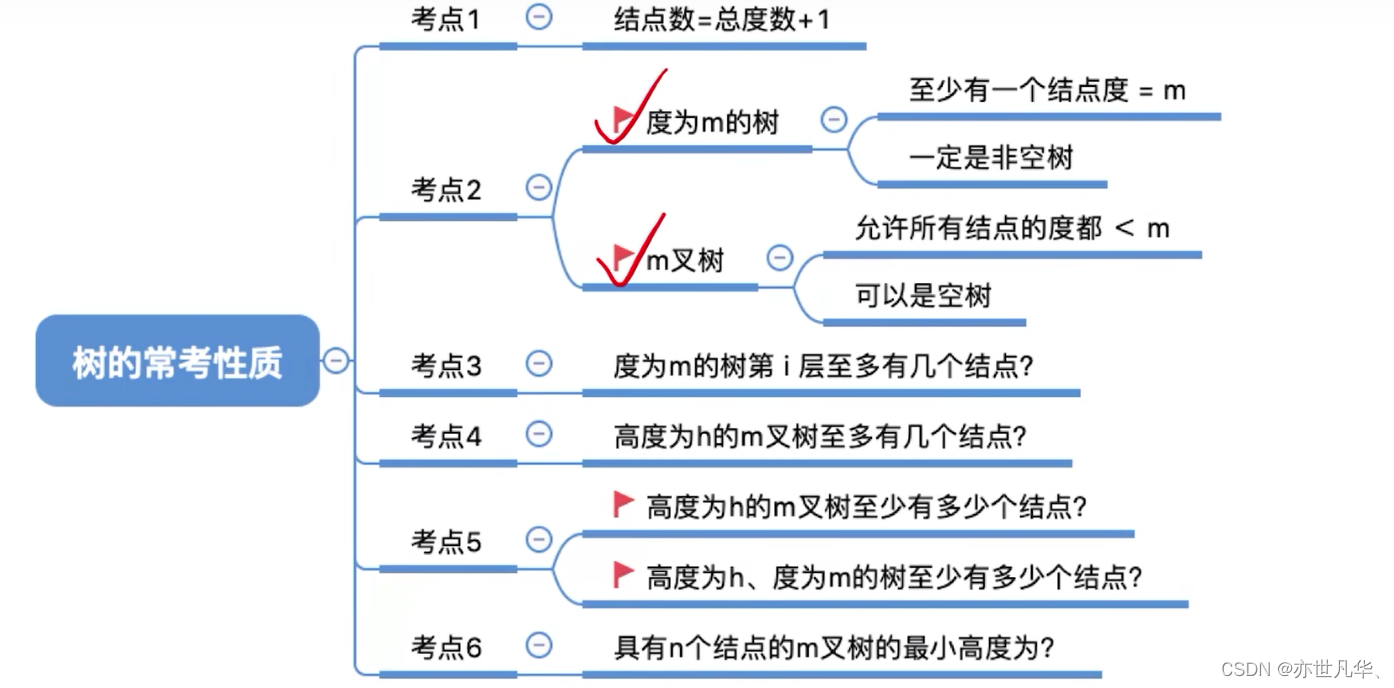
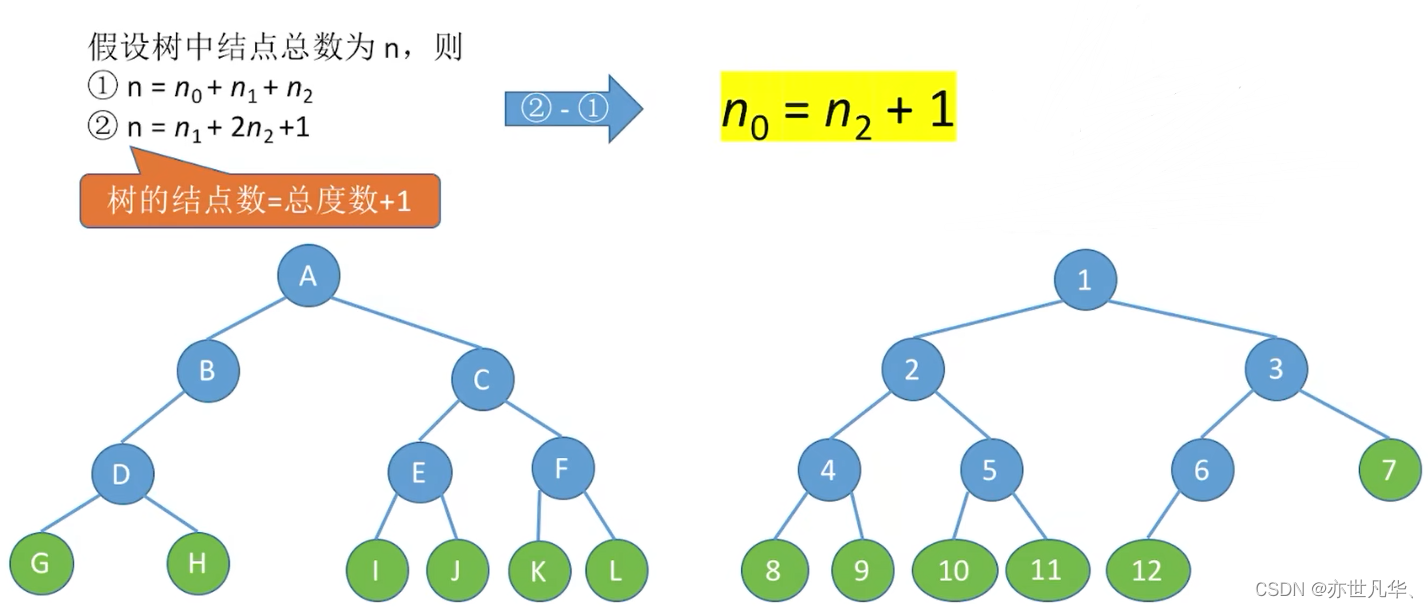
Common test point 1: Number of nodes = total degree + 1
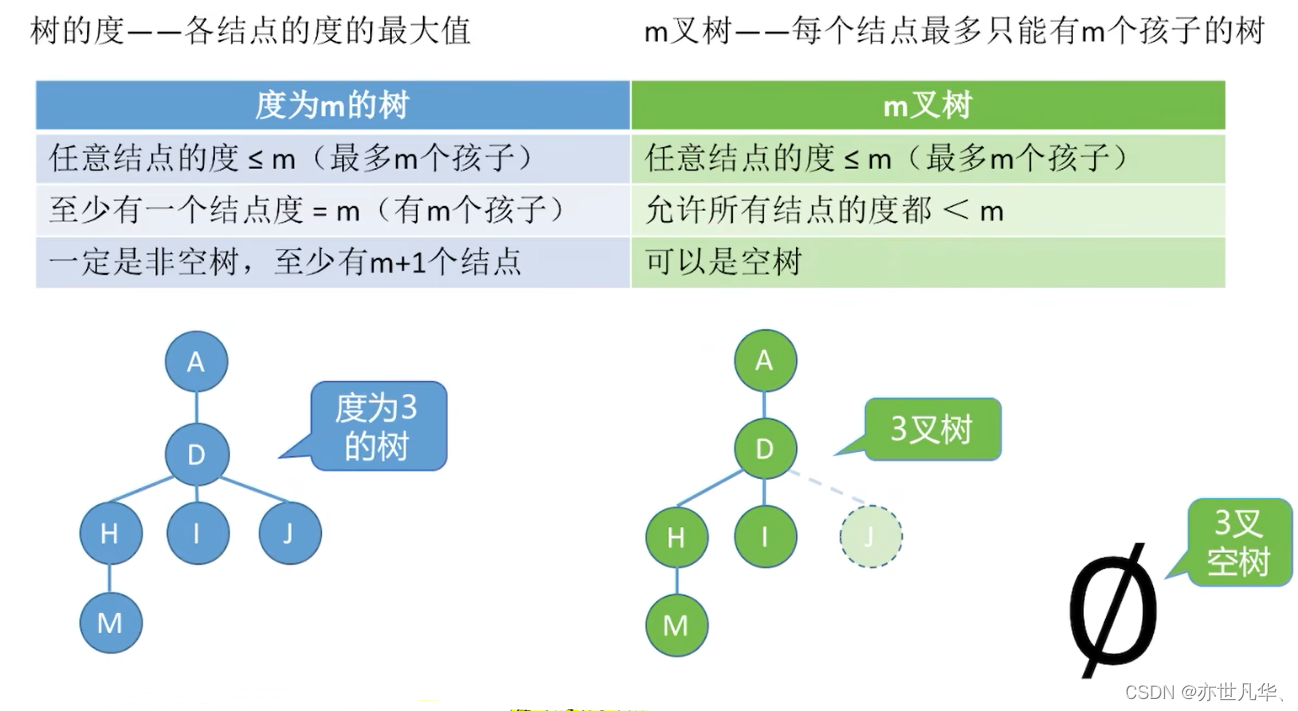
Common test point 2: The difference between a tree of degree m and an m-ary tree
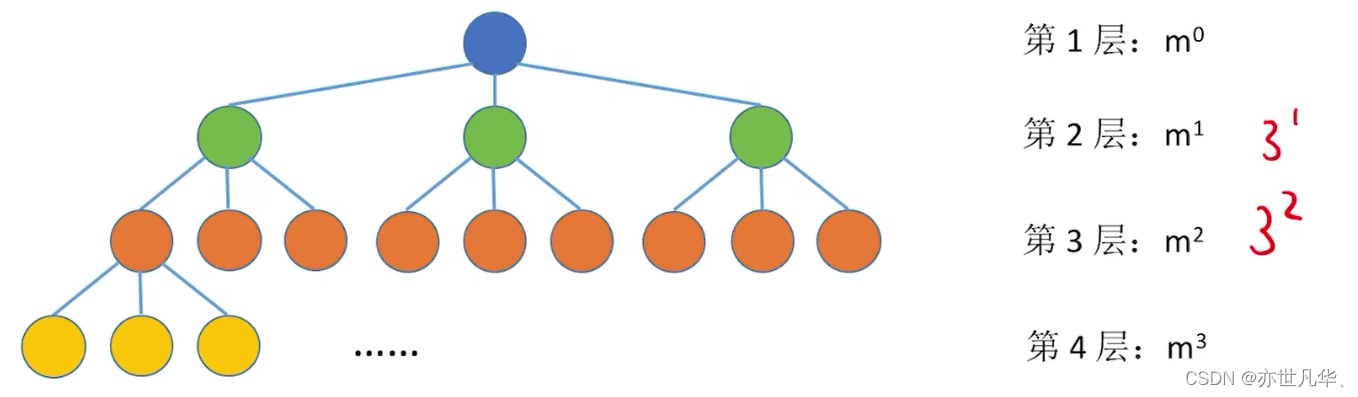
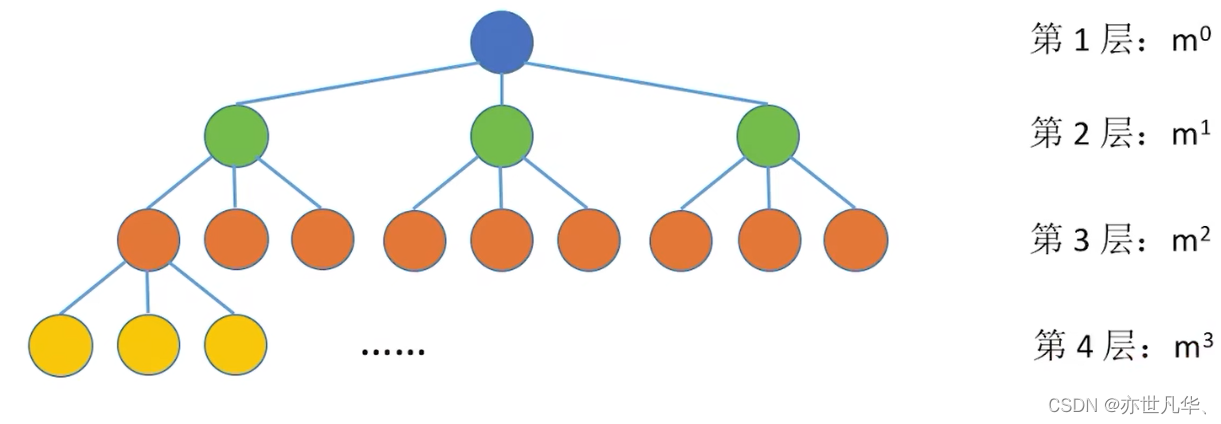
Common test point 3: The i-th level of a tree with degree m has at most
nodes (i
1), the same is true for m-ary trees The i-th layer has at most
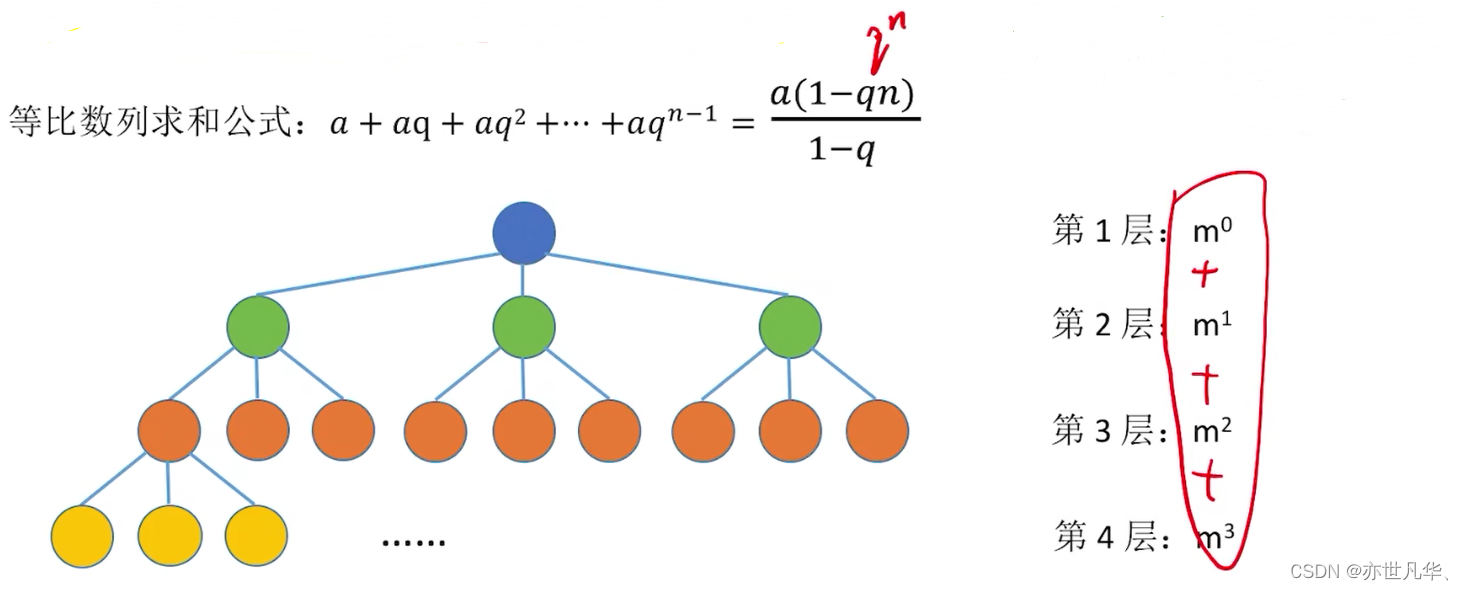
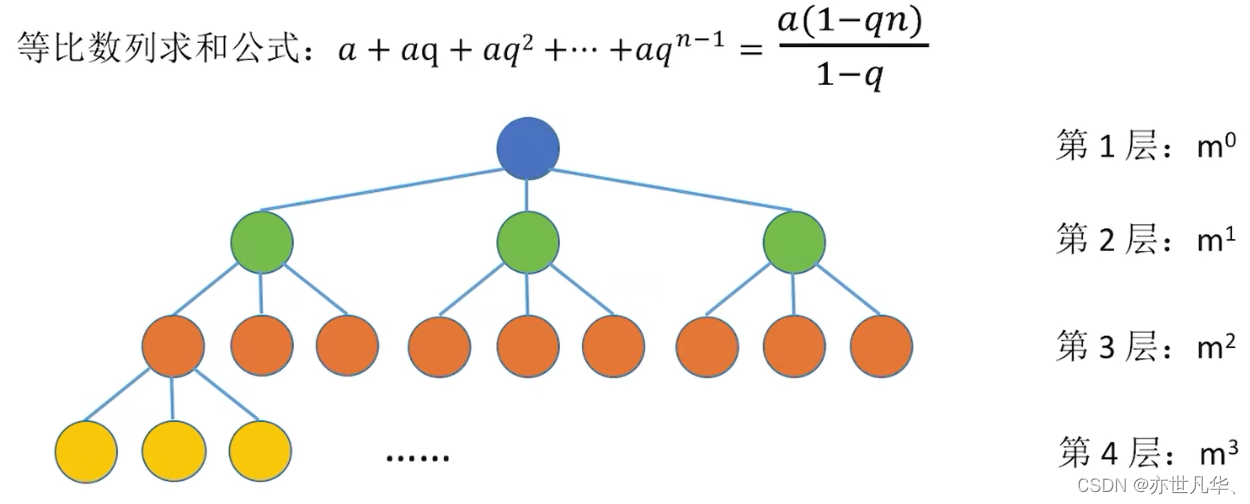
Common test point 4: An m-ary tree with height h has at most
nodes.
Common test point 5: An m-ary tree with height h has at least h nodes. A tree of height h and degree m has at least h+m-1 nodes.

Common test point 6: The minimum height of an m-ary tree with n nodes is
The case of minimum height - all nodes have m children:
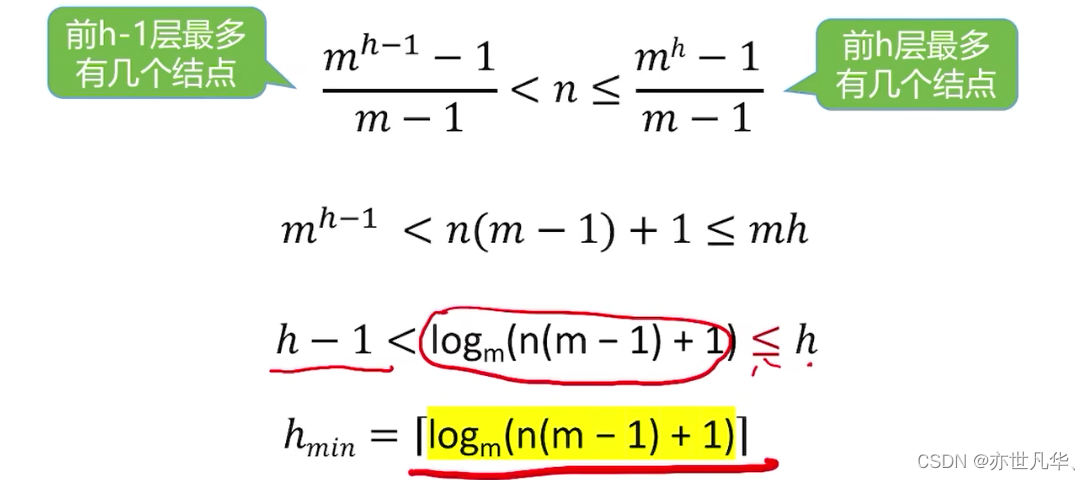
Reviewing the key points, the main contents are summarized as follows:
The definition and properties of binary tree
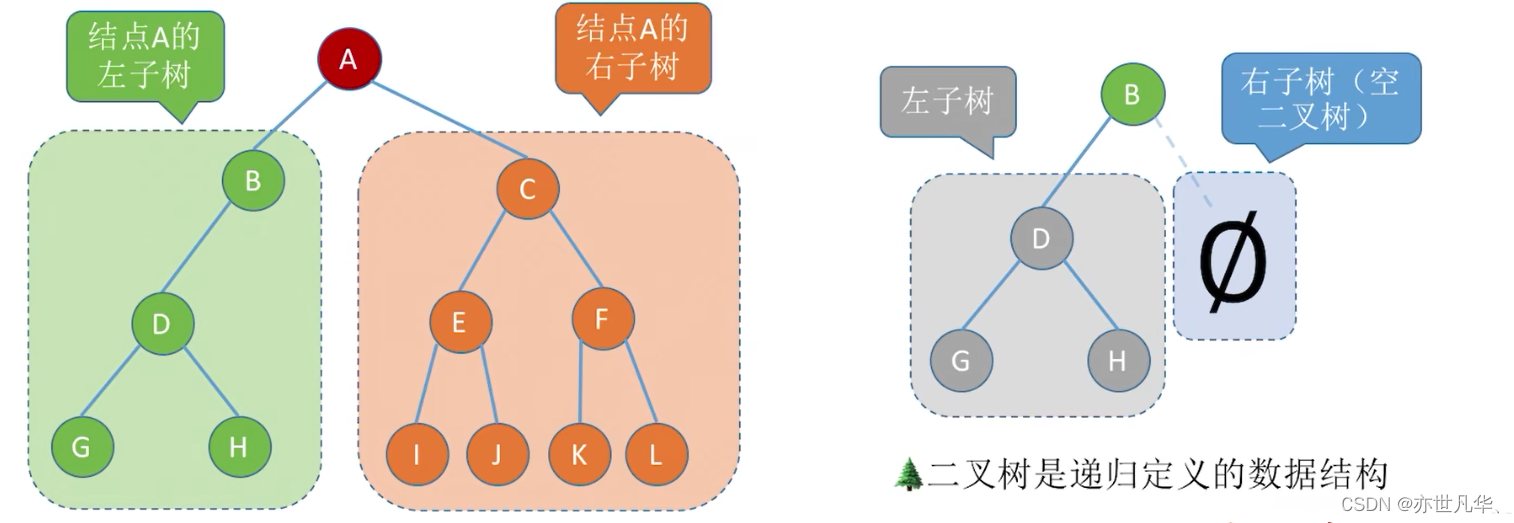
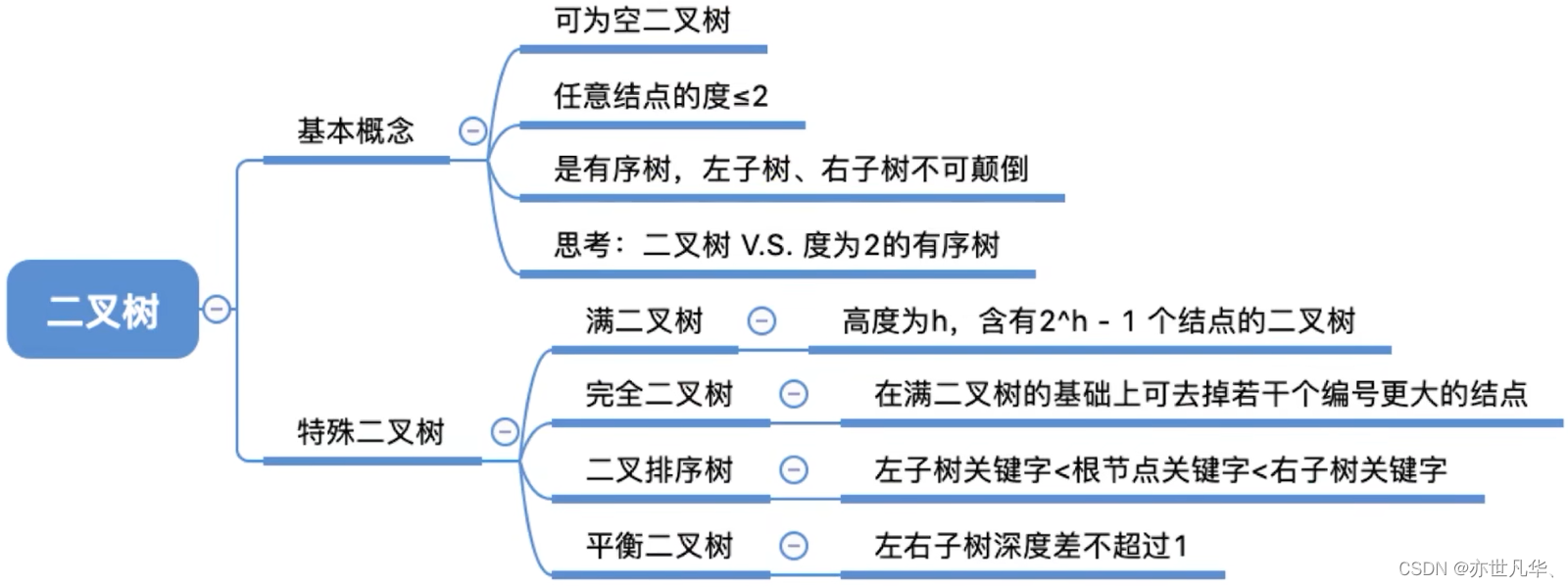
Forked Tree:
A binary tree is a finite set of n(n
0) nodes. It has the following two situations:
1) It is an empty binary tree, that is, when n = 0
2) It consists of a root node and two disjoint left subtrees and right subtrees called roots. The left subtree and the right subtree are respectively a binary tree.
Characteristics: Each node has at most two subtrees; the left and right subtrees cannot be reversed.
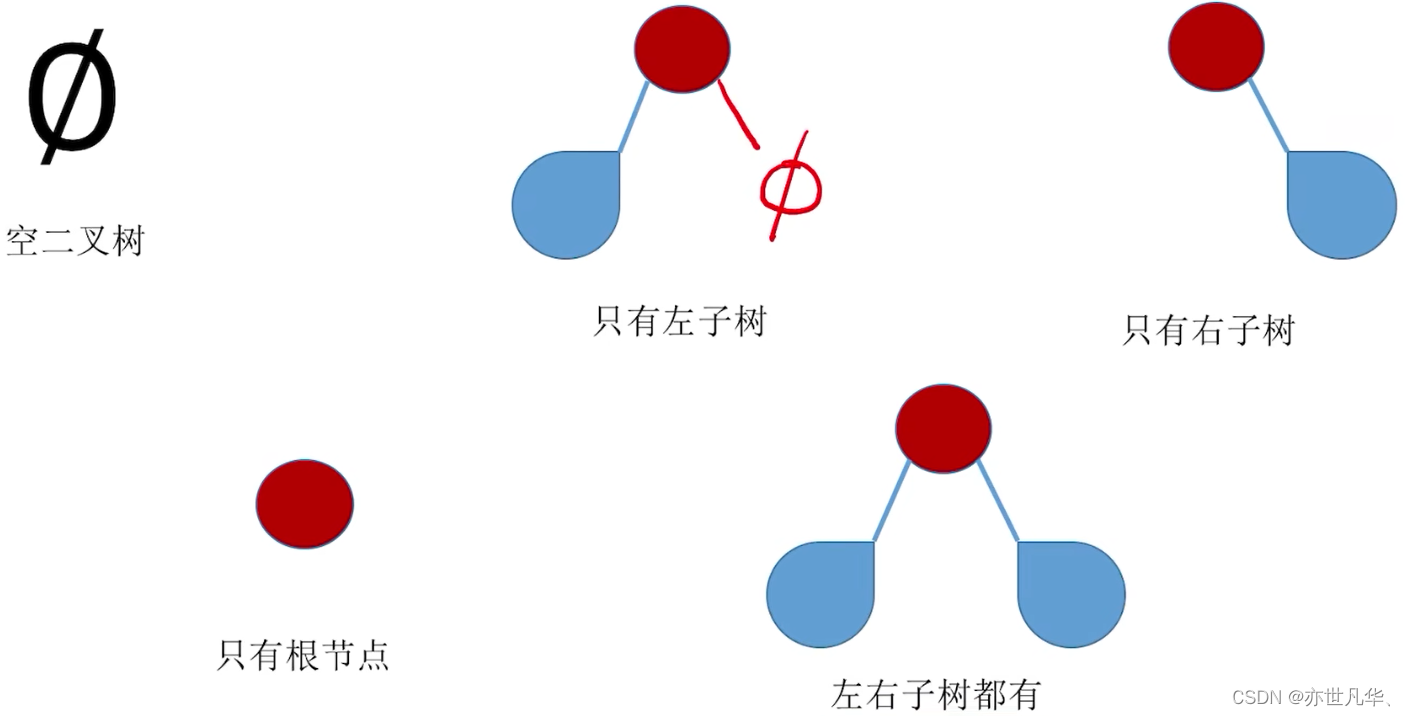
Five states of binary tree:
Several special binary trees:
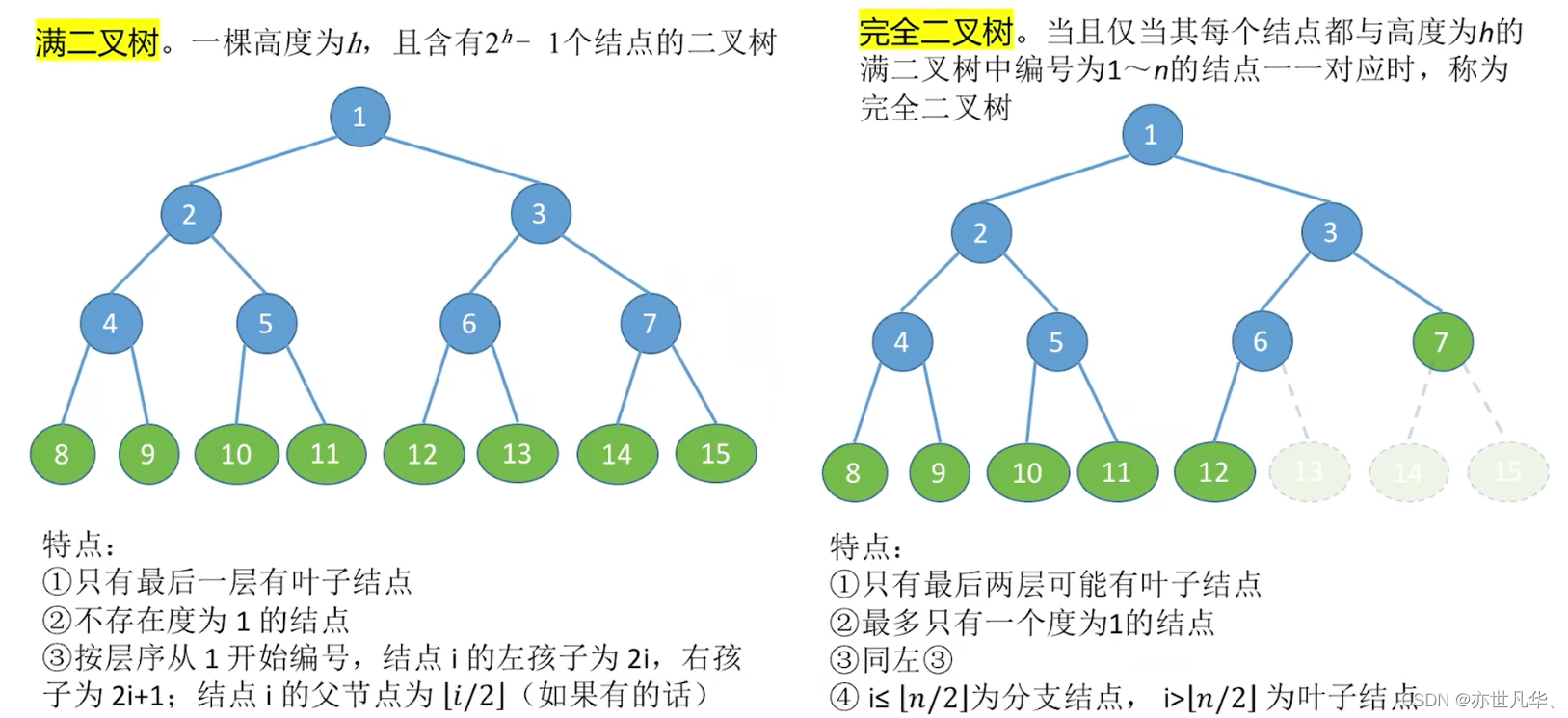
Full binary tree: A binary tree in which all leaf nodes are at the same level and all non-leaf nodes have two child nodes is called a full binary tree.
Complete binary tree: A binary tree in which all nodes except the last level node have two child nodes, and the nodes in the last level are aligned to the left, is called a complete binary tree.
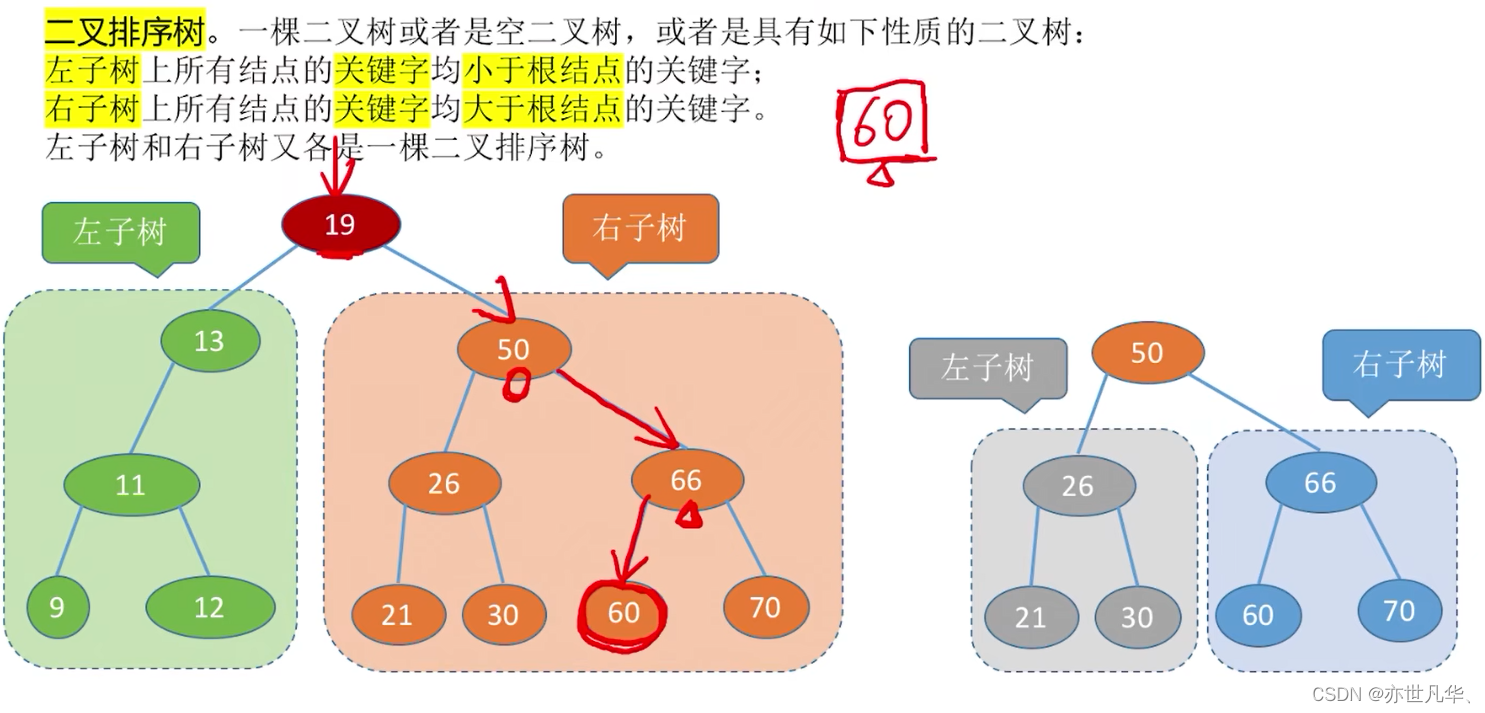
Binary sorting tree: (for example, find the node with the key 60)
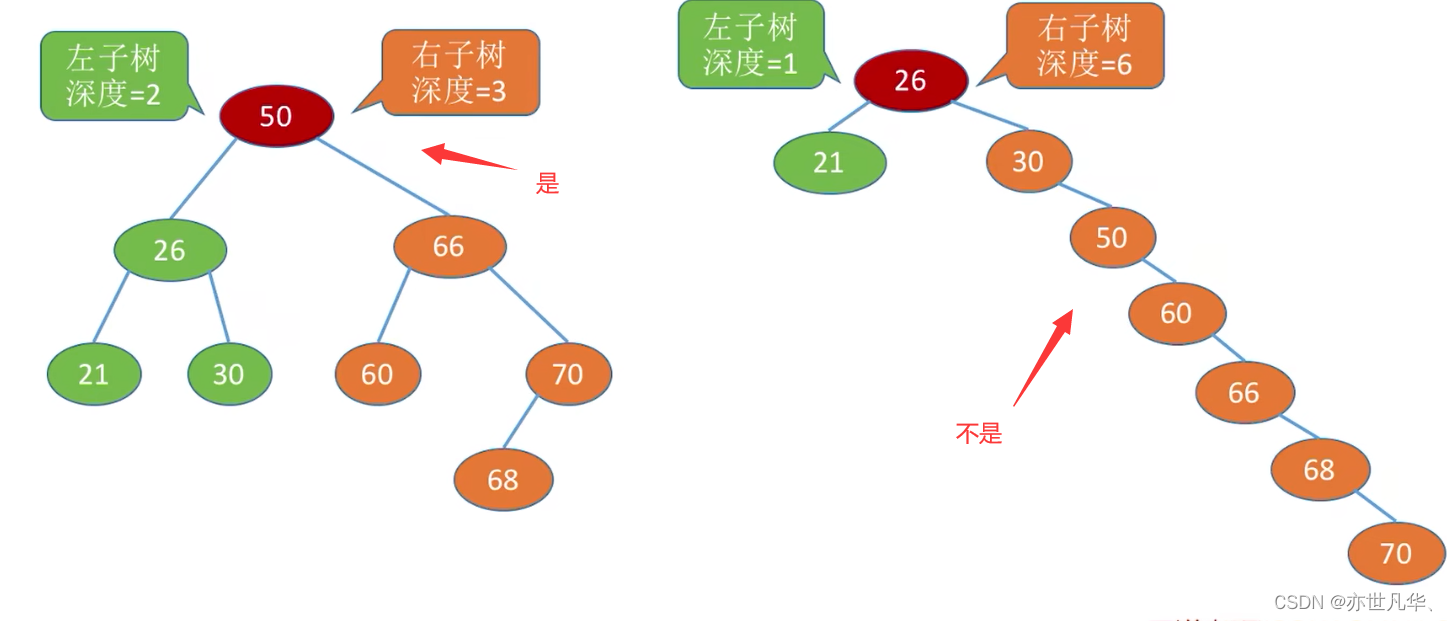
Balanced binary tree: The depth difference between the left subtree and the right subtree of any node in the tree does not exceed 1.
Reviewing the key points, the main contents are summarized as follows:
Commonly examined properties of binary trees:
Common test point 1: Suppose the number of nodes with degrees 0, 1 and 2 in a non-empty binary tree are
respectively, then
There is one more leaf node than the two-branch node.
Common test point 2: The i-th level of a binary tree has at most
nodes (i
Common test point 3: A binary tree with height h has at most
nodes (full binary tree)
The m-ary tree with height h has at most
Commonly examined properties of complete binary trees:
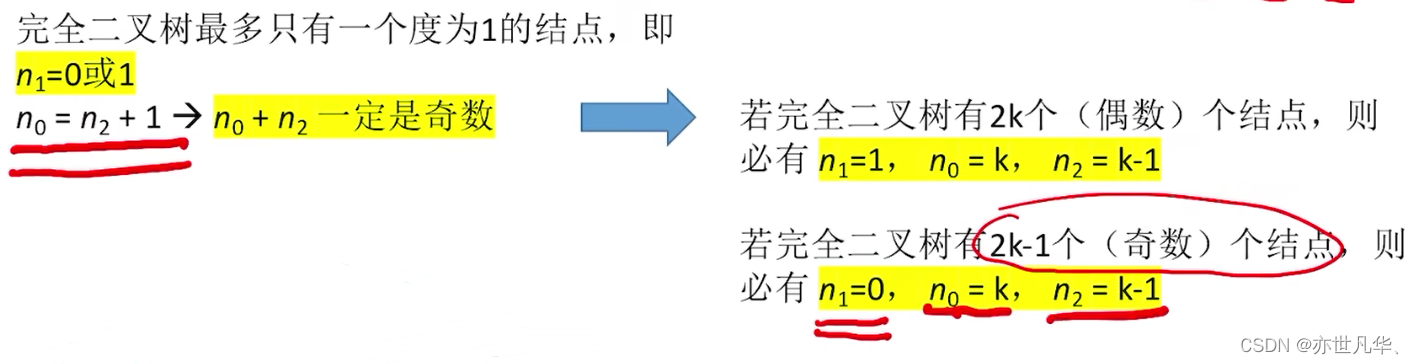
Common test point 1: The height h of a complete binary tree with n (n>0) nodes is
or
Common test point 2: For a complete binary tree, the number of nodes with degrees 0, 1 and 2 can be deduced from the number of nodes n as
,
and
Reviewing the key points, the main contents are summarized as follows:

Representation of binary tree
In data structures, binary trees can be implemented in two ways: array representation and linked list storage representation. The following is a brief description of these two representations:
Number combination display:
Array representation stores the nodes of a binary tree in a one-dimensional array in a certain manner. In general, an array can store the nodes of a binary tree in the order of hierarchical traversal. Assuming that the root node is stored at the position of array subscript 0, then for any node index i, the index of its left child node is 2i+1 and the index of its right child node is 2i+2. If a location is empty, a specific null value can be used to indicate it.
Advantages of array representation:
The advantage of array representation is that storage is simple and any node can be quickly accessed through array indexing. The disadvantage is that when the shape of the binary tree changes, the array needs to be resized, which may involve a large number of element movements.
#include <stdio.h>
#include <stdlib.h>
// 二叉树节点结构体
struct TreeNode {
int val;
struct TreeNode* left;
struct TreeNode* right;
};
// 构建二叉树的数组表示
struct TreeNode* build_binary_tree(int arr[], int size) {
struct TreeNode** tree = malloc(sizeof(struct TreeNode*) * size);
for (int i = 0; i < size; i++) {
if (arr[i] != -1) {
struct TreeNode* node = malloc(sizeof(struct TreeNode));
node->val = arr[i];
node->left = NULL;
node->right = NULL;
tree[i] = node;
} else {
tree[i] = NULL;
}
}
for (int i = 0; i < size; i++) {
if (tree[i] != NULL) {
if (2 * i + 1 < size)
tree[i]->left = tree[2 * i + 1];
if (2 * i + 2 < size)
tree[i]->right = tree[2 * i + 2];
}
}
struct TreeNode* root = tree[0];
free(tree);
return root;
}
// 测试代码
int main() {
int arr[] = {1, 2, 3, 4, 5, 6, 7};
int size = sizeof(arr) / sizeof(arr[0]);
struct TreeNode* root = build_binary_tree(arr, size);
// 输出测试结果
printf("root: %d\n", root->val);
printf("left child of root: %d\n", root->left->val);
printf("right child of root: %d\n", root->right->val);
return 0;
}Linked list storage representation:
Linked list storage representation uses a linked list to represent a binary tree. Each node contains a pointer to its parent, a pointer to its left child, and a pointer to its right child.
Advantages of linked list storage representation:
The advantage of linked list storage representation is that nodes can be flexibly inserted and deleted without moving other nodes, and it is suitable for frequently changing binary tree structures. The disadvantage is that accessing a node requires traversing from the root node, which is relatively inefficient.
#include <stdio.h>
#include <stdlib.h>
// 二叉树节点结构体
struct TreeNode {
int val;
struct TreeNode* left;
struct TreeNode* right;
};
// 构建二叉树的链表存储表示
struct TreeNode* build_binary_tree(int arr[], int size) {
if (size == 0) {
return NULL;
}
struct TreeNode* root = malloc(sizeof(struct TreeNode));
root->val = arr[0];
root->left = NULL;
root->right = NULL;
struct TreeNode** queue = malloc(sizeof(struct TreeNode*) * size);
int front = 0;
int rear = 0;
queue[rear++] = root;
int i = 1;
while (i < size) {
struct TreeNode* node = queue[front++];
// 处理左子节点
if (arr[i] != -1) {
node->left = malloc(sizeof(struct TreeNode));
node->left->val = arr[i];
node->left->left = NULL;
node->left->right = NULL;
queue[rear++] = node->left;
}
i++;
// 处理右子节点
if (i < size && arr[i] != -1) {
node->right = malloc(sizeof(struct TreeNode));
node->right->val = arr[i];
node->right->left = NULL;
node->right->right = NULL;
queue[rear++] = node->right;
}
i++;
}
free(queue);
return root;
}
// 测试代码
int main() {
int arr[] = {1, 2, 3, 4, 5, 6, 7};
int size = sizeof(arr) / sizeof(arr[0]);
struct TreeNode* root = build_binary_tree(arr, size);
// 输出测试结果
printf("root: %d\n", root->val);
printf("left child of root: %d\n", root->left->val);
printf("right child of root: %d\n", root->right->val);
return 0;
}Binary tree traversal
Traversal: Visit all nodes in a certain order. According to the recursive characteristics of a binary tree, it is either an empty binary tree or a binary tree composed of "root node + left subtree + right subtree"
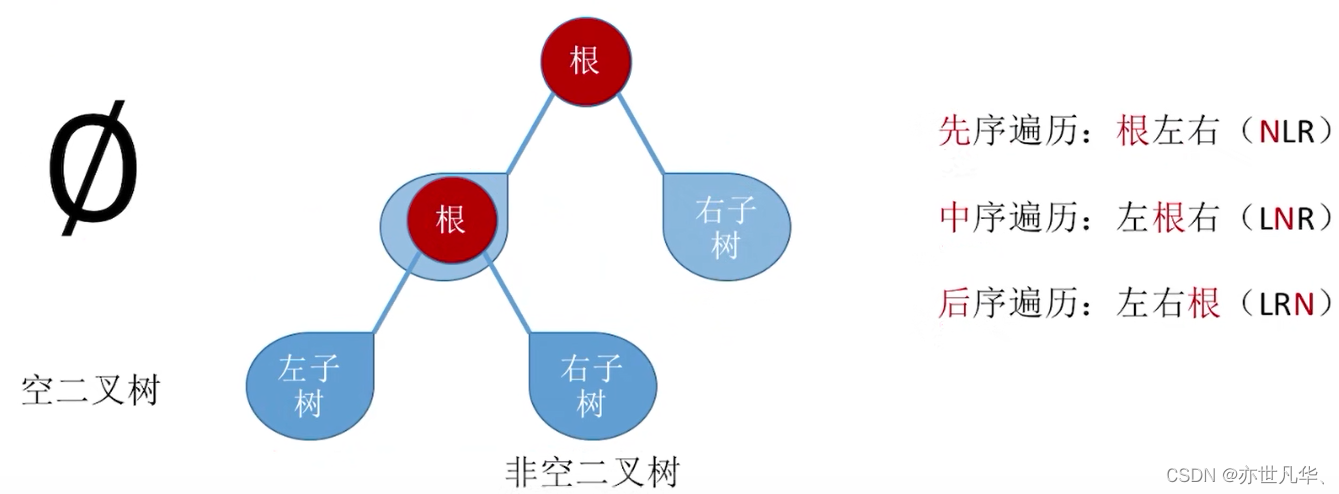
According to the three traversal rules of binary trees, the relevant specific cases are as follows:
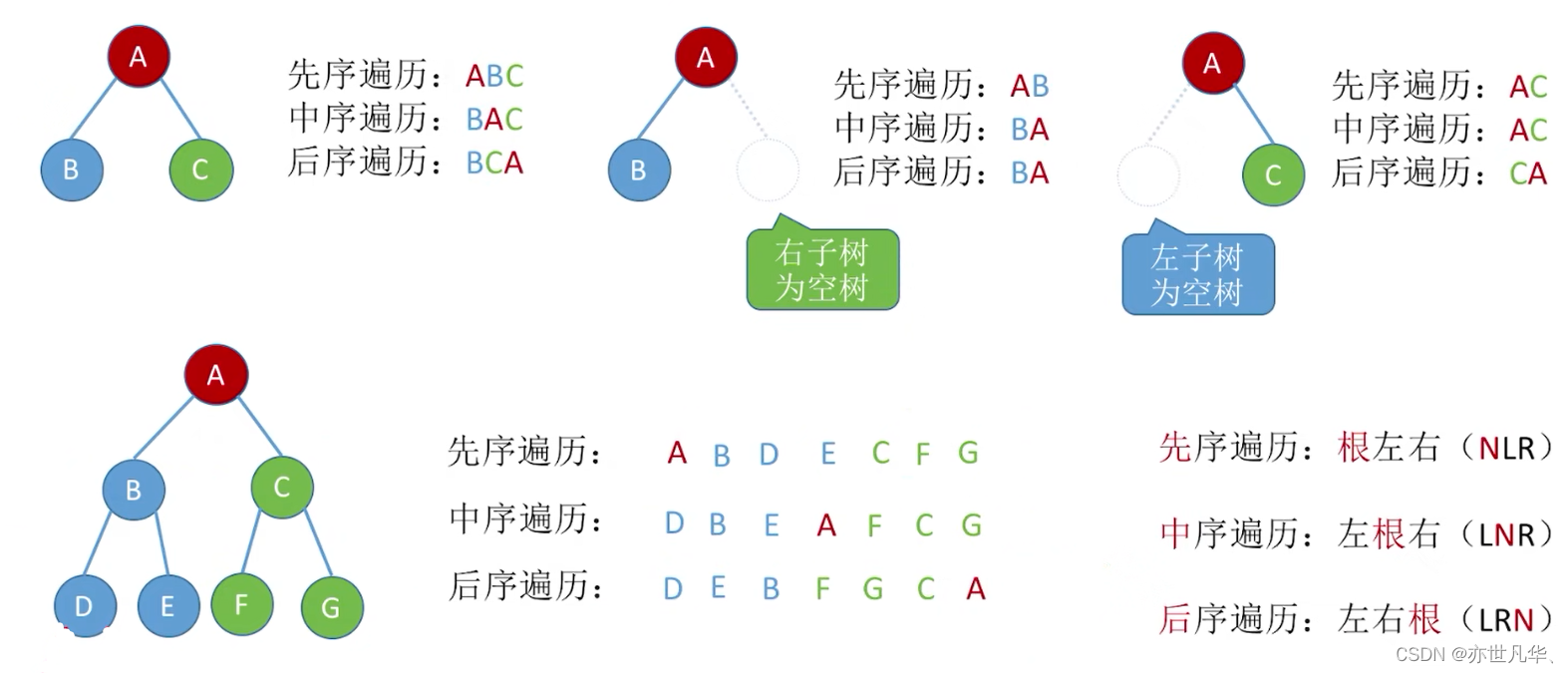
Let’s do the specific exercises again:

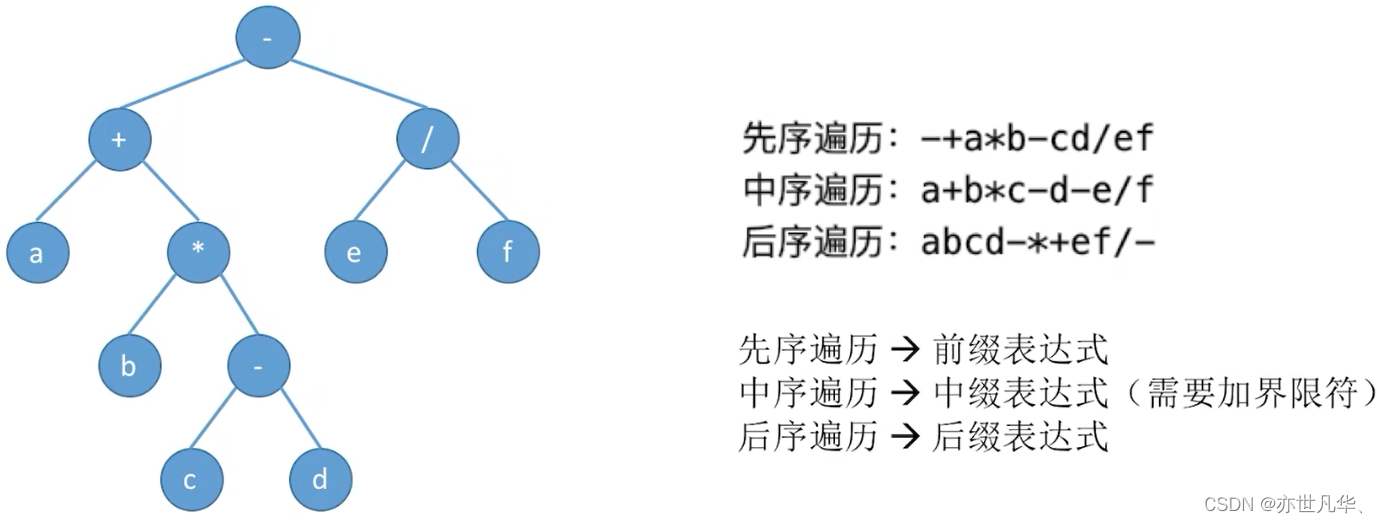
Reviewing the key points, the main contents are summarized as follows:
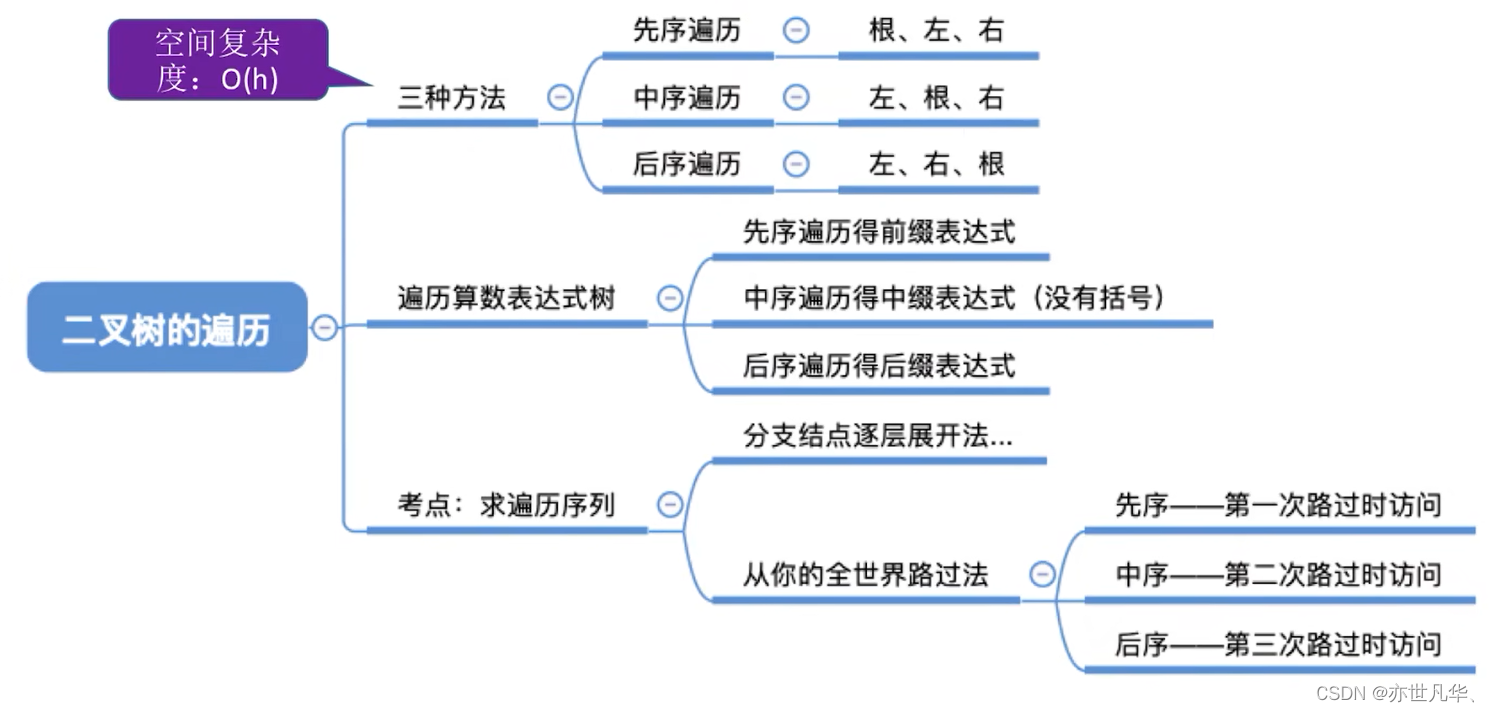
Level-order (times) traversal of a binary tree:
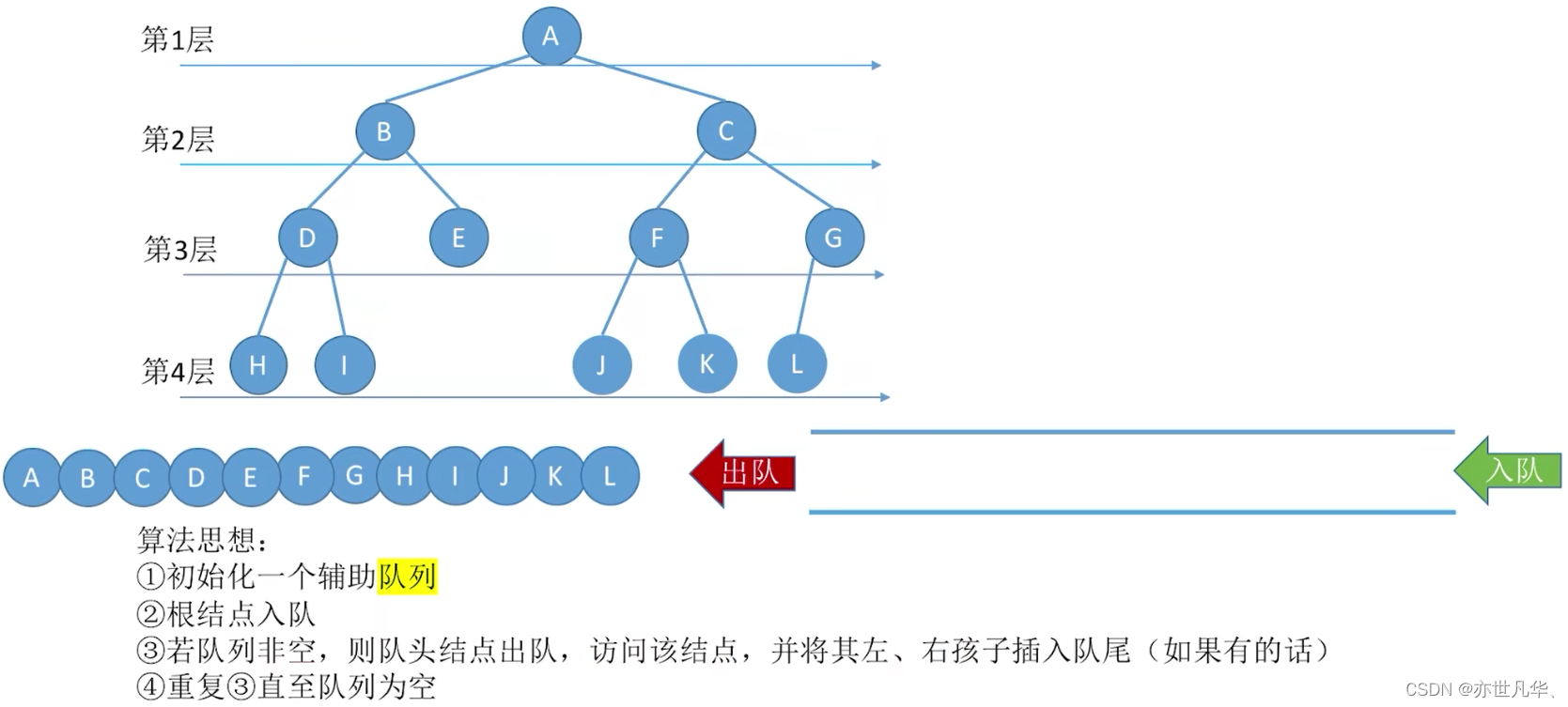
The corresponding code implementation is as follows:

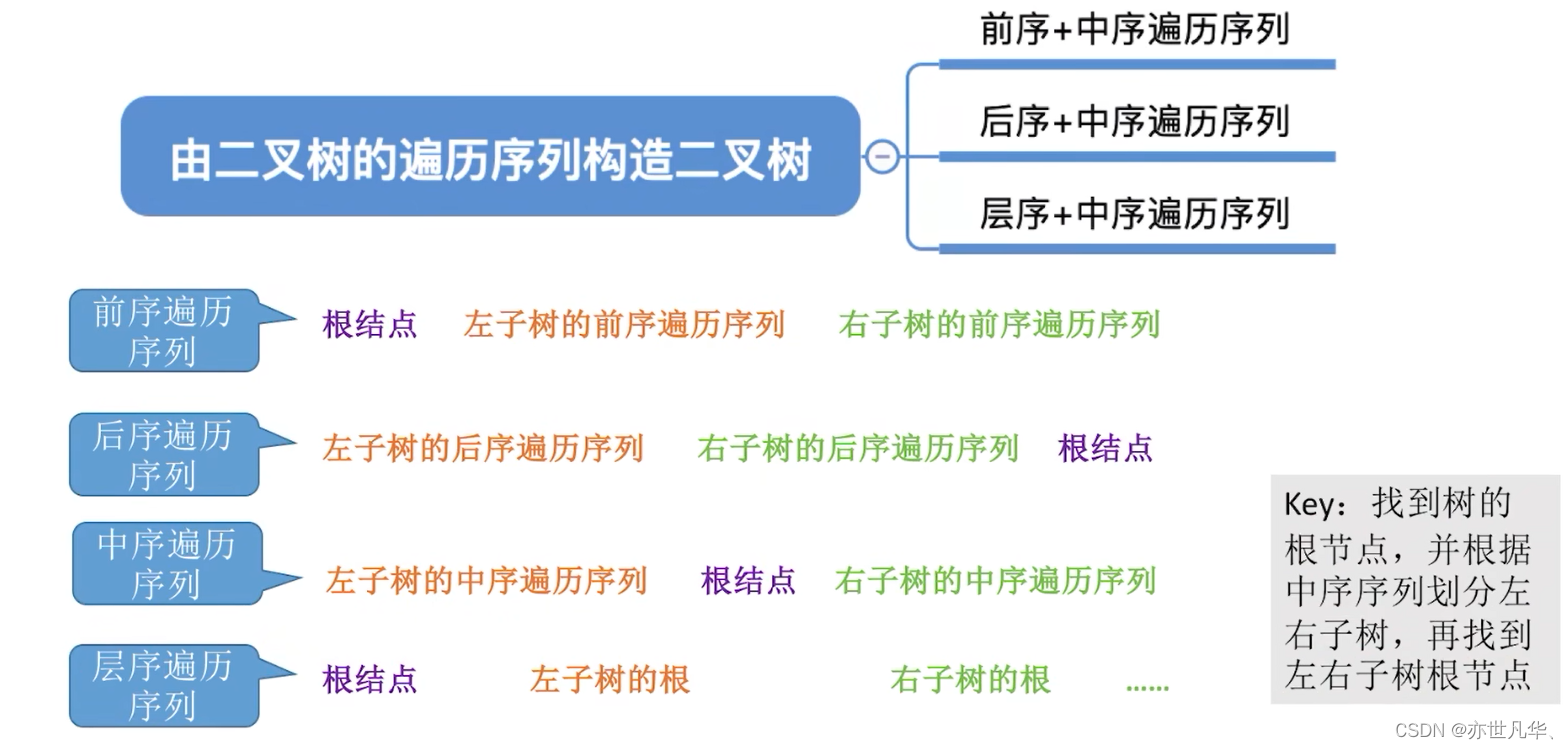
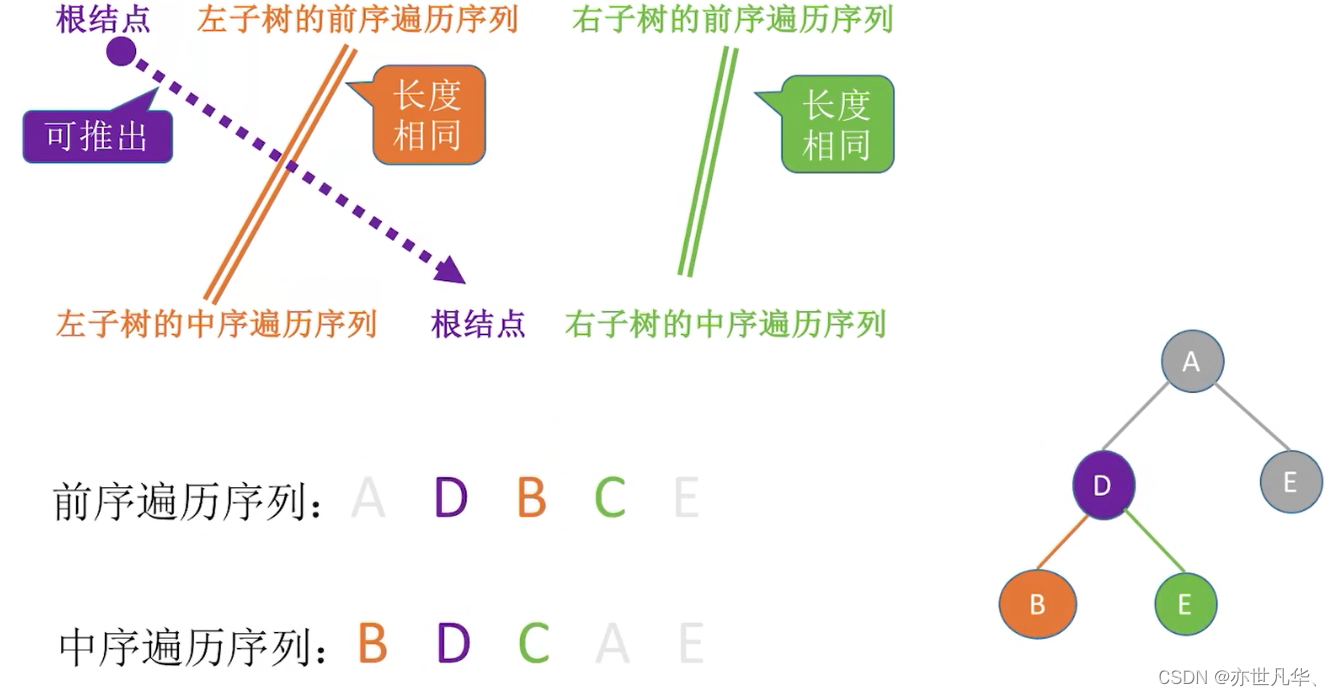
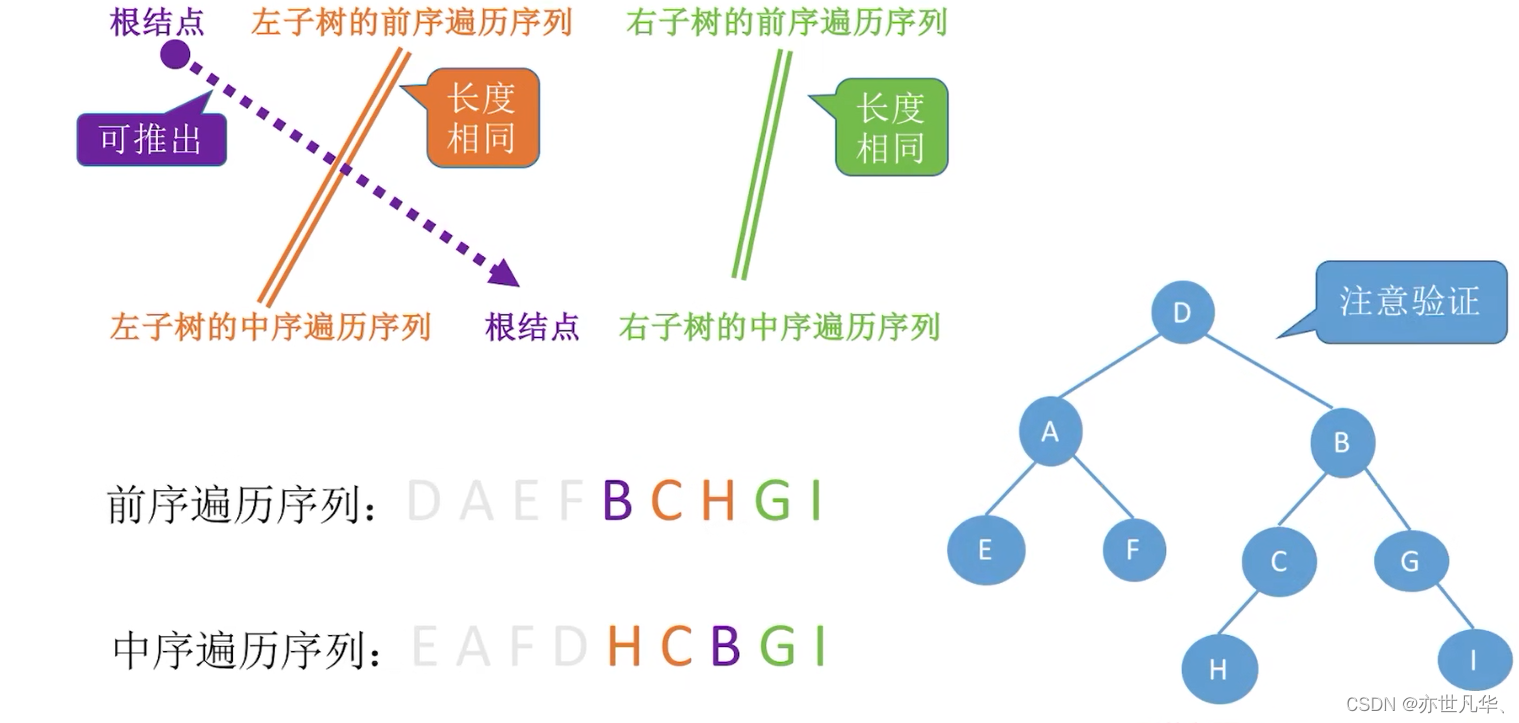
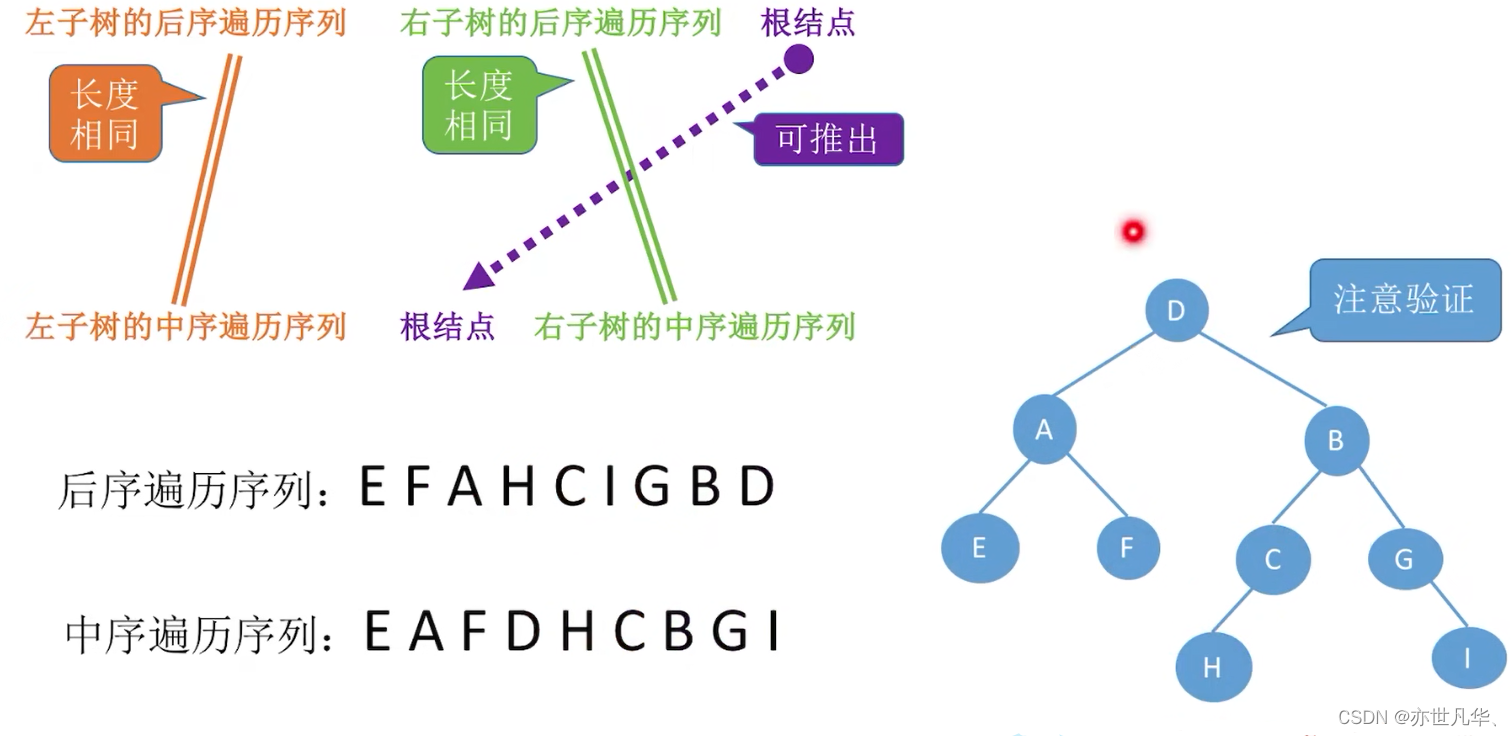
Construct a binary tree by traversing the sequence:
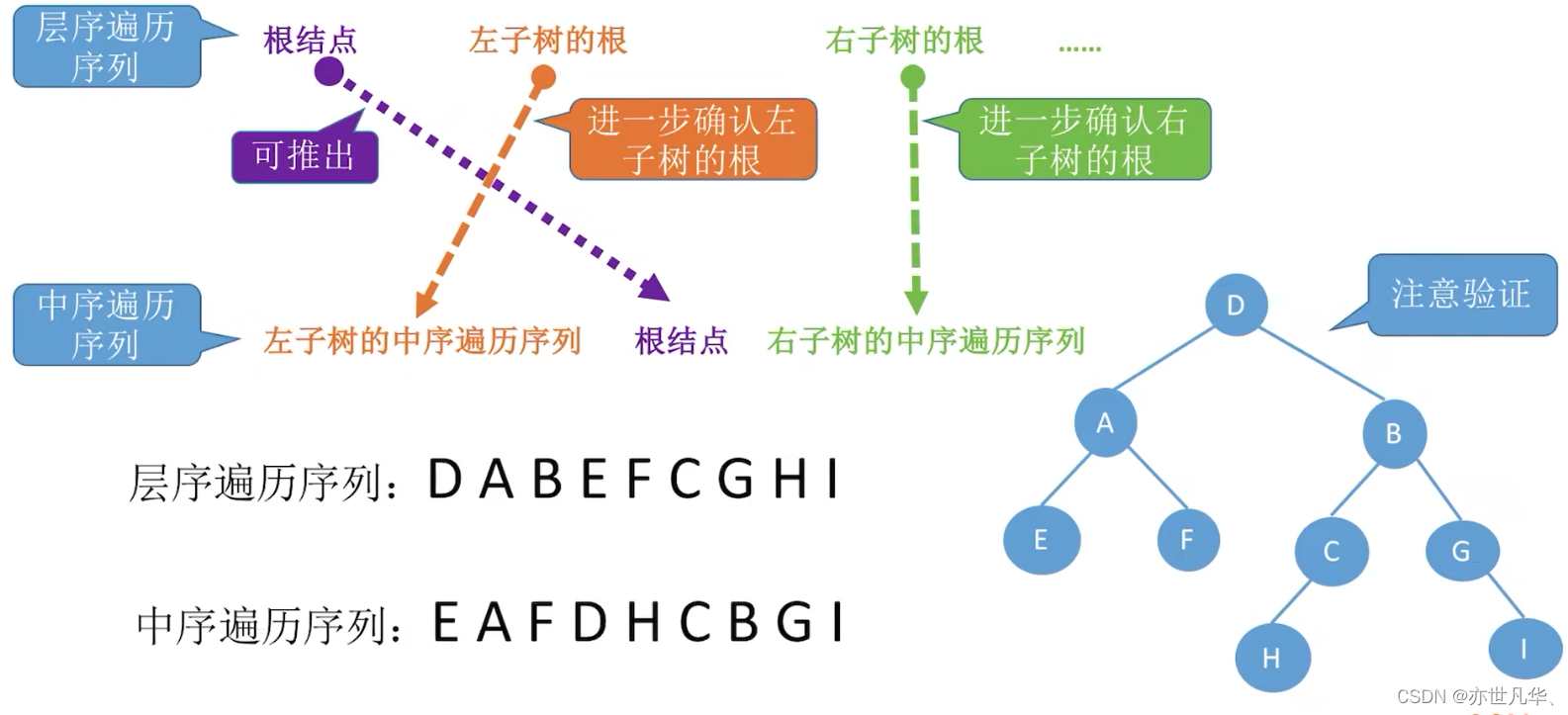

Reviewing the key points, the main contents are summarized as follows: