In fact, this article does not involve any high-level anti-climbing, but I really don’t know where to classify this article, so I will just throw it here.
Let me complain first: Mengniang Encyclopedia is definitely a website that I never want to visit a second time.
Second sentence: (Truth) Making the website more confusing and more confusing is the best anti-crawling method, which is more effective than any encryption.
Look at the requirements first:Crawl all the game character introductions in the Mengniang Encyclopedia
Normally for an encyclopedia website, once it gets this requirement, the first reaction is to make a list of game character names, and then search them one by one to crawl the returned page content. However, when I wanted to further ask for a list of game character names, the reply I got was: there are no ready-made game character names, just crawl the game characters on Mengniang.
Wrong day? ? ?
The idea at the beginning was to compile a list of game character names myself. Then I faced a big problem: I couldn't increase the quantity. Even with the help of Du Niang, I could only find a few game characters. After excluding some entries that Moe Niang did not include, there were not many left.
No choice, just stick to the website.
Then I found this:https://mzh.moegirl.org.cn/Special:Special Page
I once thought I had discovered a treasure, until I couldn't find the game character category I wanted among the confusing pages... What are these categories? It's so confusing.
Later I reluctantly found two more pages that looked crawlable and barely met my needs:https://mzh.moegirl.org.cn/Category: Category , https://mzh.moegirl.org.cn/Category:Video game character list
It's something. While this is certainly not a link to everything, it will alleviate some of my immediate concerns.
This also gives a new idea:When crawling this kind of encyclopedia website, you can try to locate the root directory of the website, and then follow the root directory from the root directory Search the website's classification tree level by level to grab all the links you need.
This was the first problem that the cute girl encountered, and it was barely solved.
During the crawling process, I found that at the bottom of each entry on Meng Niang, there will be a lot of related or reference links attached. Many game characters will be listed in a large table similar to the one below:

In addition to game characters, this big list also has a bunch of messy categories. Moreover, the big list under each page may be different, or of course it may be the same.
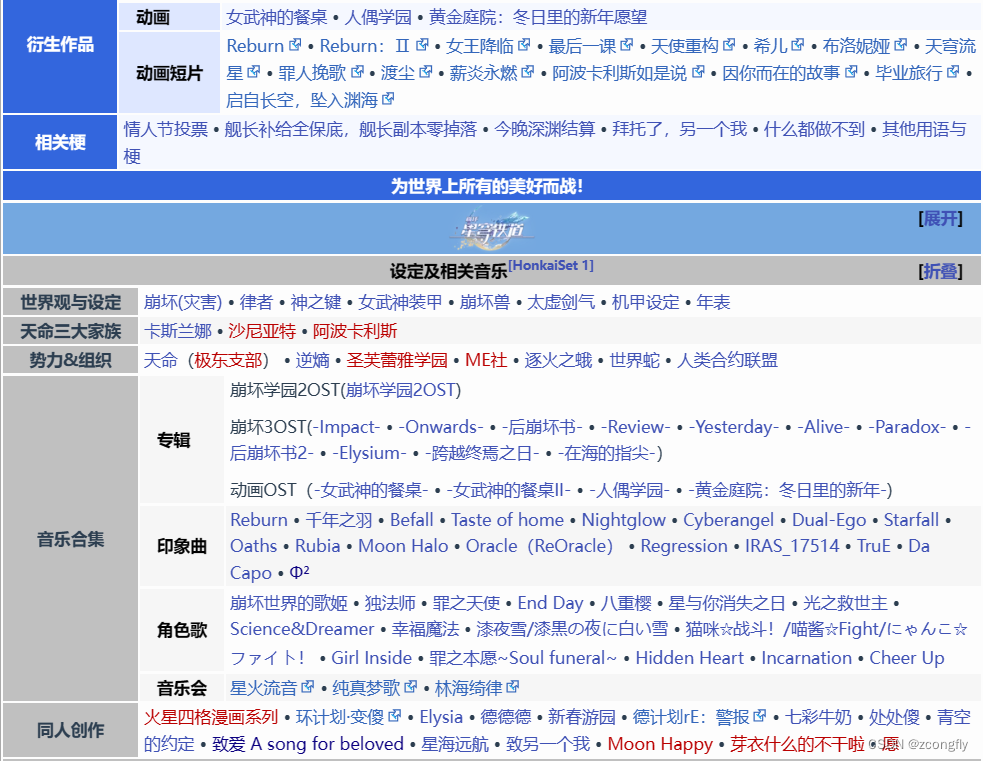
Then I only need the character name and link inside, what should I do?
Observing the source code of the page, we found that the first column of the table (that is, the title column with the word xx role) corresponds to the content on the right one-to-one, and they are both under the same tr tag. In other words, they are brother nodes.
 XPath
XPathfollowing-sibling axis can select sibling nodes after the current node:
from lxml import etree
# 使用XPath选择包含"角色"文字的td标签,并获取其下一个兄弟节点的内容
selected_elements = tree.xpath('//td[contains(text(), "角色")]/following-sibling::td[1]')
In the XPath expression, //td[contains(text(), "角色")]/following-sibling::td[1] means selecting the td tag containing the "role" text, and then obtaining the content of its next sibling node.
The final code is as follows:
def get_table_links(url):
headers = {
'User-Agent': random.choice(USER_AGENTS_LIST),
'Referer': url
}
resp = requests.get(url, headers=headers)
text = resp.text
html = etree.HTML(text)
# 所有罗列了游戏角色的表格定位
hrefs = html.xpath('(//table[@class="navbox"])[1]//td[contains(text(), "角色")]/following-sibling::td[1]//a[not(@class="new") and not(starts-with(@href, "http"))]/@href')
return hrefs
Among them,//a[not(@class="new") and not(starts-with(@href, "http"))] means to get all the links under the a tag whose class is not "new". The reason why this class should be excluded is because in Mengniang, class=" new" means that the page does not exist.
Finally, I feel that I really, really, really admire the designer of the Mengniang website, the kind of person who worships her.
Supplementary: When grabbing web content, I need to grab all the text under the div in the web page, but I always catch some messy css code, js code and the like. After checking, I found that some fonts in Mengniang were used. Boldness, color and other style modifications, and some also set different display modes (for example, the text will be displayed only when the mouse stays in the blackened area, which is quite interesting). In the source code of the reaction island page, the text under the p tag is followed by a style tag or script tag, similar to the following:
<p>
在这个世界中,「崩坏」是一种
<span>周期性
<style>.vue3-marquee{
display:flex!important;position:relative}.vue3-marquee.horizontal{
overflow-x:hidden!important;flex-direction:row!important;</style>
</span>
灾难,它伴随文明而生,以毁灭文明为最终目标。
</p>
Directly use xpath to capture all the text under the p tagtree.xpath('//div[@class="mw-parser-output"]//text(), which will also capture the messy things under the style or script tags (I ran this for a few times at first) I found that a page always catches a bunch of things I don’t want). I checked the information on the Internet and added a not at the end according to the xpath syntax to filter out the unwanted tags:
selected_elements = html.xpath('//div[@class="mw-parser-output"]//text()[not(ancestor::style) and not(ancestor::script)]')
To summarize here, following-sibling is looking for sibling nodes. Generally, this is written under the xpath path for path positioning; ancestor is looking for is the ancestor node (literal translation hhhh), which can be placed at the end of the xpath expression to clean irrelevant tags. In addition, the not and and statements in xpath can be used in combination with @class and @href, according to (For examplea) The attributes within the tag filter and filter the tag.
Finally, I would like to add a digression,All data serve the subsequent algorithms, so when storing data, we must consider whether it is convenient for subsequent codes to read the data, and whether You can write a general code to read all the data. Therefore, when saving data, if it is not written to the database temporarily, it is best to save it by row txt or jsonl The specific file format depends on the complexity of the data. Simply save a link or keyword and use txt, and save it as jsonl if the fields are more complex. Especially for crawler data, do not savejsonfiles easily! Because when the file written with too much content is too large (I have not tried the upper limit, my guess depends on the running memory of your computer), json the file cannot be loaded at once. If python reads it directly, the program will report an error, so in the end you have to read the json file line by line, and then there is the fear of being dominated by all kinds of weird newline characters and left and right brackets, and finally Have to climb again (if you have other solutions, please kick me).
Taking Mengniang as an example, record the general process of our discussion of data storage format and fields to be retained:
First edition:
{
"title":页面总标题,
"目录1":内容1,
"目录2":内容2,
...
}
No, the directory of each page of Mengniang is not exactly the same, so it cannot be read later.
second edition:
{
"title":页面总标题,
"content":{
"目录1":内容1,
"目录2":内容2,
...
},
}
This one is passable (in fact, this is the version that was finally finalized), but I always feel that something is missing.
The third version modified by myself:
{
"title":页面总标题,
"content":{
"category":{
1:"目录1",
2:"目录2",
...
}
"目录1":内容1,
"目录2":内容2,
...
},
}
This can be done through"category" to first locate the directory of each piece of data, and then further locate the content. But even without adding "category", the for loop can directly traverse the key to find each directory and then further locate it, with no more than a few lines of code. If you save the directory separately, you may be trading space for time.
Finally, in order to facilitate data tracing, some other fields are added:
{
"title":页面总标题,
"content":{
"category":{
1:"目录1",
2:"目录2",
...
}
"目录1":内容1,
"目录2":内容2
...
},
"url":当前链接,
"referer_title":上一级标题,
"referer":上一级链接,
}