- Introduction
- 1. Application scenarios and system block diagram
- 2. Build an intelligent customer service assistant based on ChatGPT
- 3. Classification of user problems in the second phase of optimization of the intelligent customer service system
- 4. Screening of business details and knowledge related to quality inspection items in the third phase of optimization of the intelligent customer service system
- 5. Summary
- 6. References
Introduction
The traditional customer service field relies heavily on manual labor and is data-intensive. Faced with a large number of user questions, human customer service needs to find data related to the user's problem from a large amount of data based on the user's question, and then organize the language to answer. The response time is limited by the work experience of the manual customer service and the complexity of the business scenario. If it takes a long time, it will seriously affect the user's shopping experience.
Intelligent customer service refers to using the excellent natural language processing and understanding capabilities of Large Language Model (LLM) to integrate private data to build an intelligent customer service system for specific scenarios, providing strong support for manual customer service and improving the service efficiency and service quality of manual customer service. .
1. Application scenarios and system block diagram
The product display interface that users see has detailed product parameters and quality inspection reports. The product parameters include basic information about the product. The quality inspection report is an authoritative inspection report issued by the quality inspection department to facilitate users to understand the true status of second-hand products.
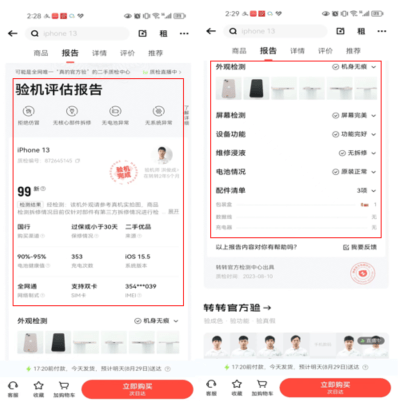
The content of conversations between users and customer service on the Zhuanzhuan App can be roughly divided into six categories: product parameter consultation, quality inspection report consultation, preferential activity consultation, platform policy consultation, after-sales consultation, and casual greetings. When manual customer service encounters users inquiring about product parameters and quality inspection reports, they need to find items related to customer problems from a wide variety of product details and quality inspection items, and then provide users with corresponding answers. Searching for answers from all the data on products clicked by users is time-consuming. It requires manual customer service to have a better understanding of the parameters of the products consulted by users in order to quickly respond to users' questions.
Let's use ChatGPT's natural language processing and understanding capabilities to assist human customer service to find the items that users are interested in from large sections of product details and quality inspection reports, and answer users' questions.
The block diagram of the entire intelligent customer service system is shown below: the user initiates a manual consultation dialogue, first assigns a customer service, the user's clicked product information is synchronized to the customer service, and then the intelligent customer service system gives auxiliary information, the customer service decides whether to adopt it, and provides the user with an answer. A session ends.
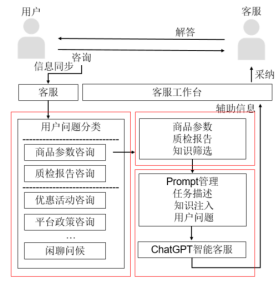
The intelligent customer service system is divided into three modules: user problem classification module, knowledge screening module and ChatGPT intelligent customer service module. The first phase of the system only has the ChatGPT intelligent customer service module, while the second and third phases of optimization added user problem classification modules and knowledge screening modules. Let's take a look at its creation process.
2. Build an intelligent customer service assistant based on ChatGPT
2.1 ChatGPT principle
ChatGPT is an LLM developed by Open AI. The full name of GPT is Generative Pre-Trained Transformer. ChatGPT belongs to the pre-trained language model of the GPT series. The GPT series models include GPT-1, GPT-2 and GPT-3. The parameters of the GPT series models are shown in the table below.
| Model | release time | Number of layers | Parameter quantity |
|---|---|---|---|
| GPT-1 | 2018-06 | 12 | 117 million |
| Bert | 2018-10 | 12 | 115 million |
| GPT-2 | 2019-02 | 48 | 1.5 billion |
| GPT-3 | 2020-05 | 96 | 175 billion |
The exponential expansion of the model size has brought about a qualitative leap in the model's understanding ability. But the model's understanding is not aligned with the user's intent. ChatGPT is based on GPT-3. The training network uses prompt learning (Prompt Learning) and reinforcement learning of human feedback to train the network so that the model can follow instructions and output answers that are useful, credible and harmless to humans [1-2] . Hint learning is a type of meta-learning, which trains the network to learn by telling the model task information. This method combines various NLP tasks into text generation tasks. Prompt learning explores the knowledge that the model itself has learned, and instructions (Prompt) can stimulate the completion ability of the model. Reinforcement learning based on human feedback trains a reward function based on human preference for predicted content. This reward function reflecting human preference is used as a reward for reinforcement learning, and the network strategy is trained through proximal policy optimization to make the reward maximum.
2.2 Prompt design
ChatGPT is like a knowledge base. If we want to obtain the knowledge we need from this knowledge base, we need clear instructions. Telling ChatGPT through clear instructions what work it wants to complete, as well as the detailed steps required to complete the work, and giving some simple examples can help ChatGPT better understand and execute our instructions. A standard instruction consists of the following five parts: (1) Task description
(2) Background knowledge injection
(3) Agreement on output format
(4) Give examples, including sample input and sample output
(5) Give input data
Here we take Zhuanzhuan Intelligent Customer Service as an example to design the prompt for this scenario:
Now that you are an e-commerce customer service, please answer the user's questions based on the product information and quality inspection information given below. When answering the question, give a concise answer based on the relevant items of the product information and quality inspection information. Product parameters: {$product_info}, quality inspection information: {$quality_info}.
AI: Do you have any questions to ask?
user: Is the battery repaired or replaced?
AI: According to the battery detection item in the quality inspection report, the battery was replaced by the platform, and the replacement battery brand was a new Hais battery.
User: What is the battery capacity?
The entire Prompt can be divided into four parts. The first part introduces the task, the second part does knowledge injection, and the variables product_info and quality_info correspond to product details and quality inspection reports respectively. The third part gives task examples, and the fourth part gives user questions. LLM has few-shot learning capabilities. Through a few simple examples, we can tell the model what the expected answer is, which can guide LLM to complete the task in the way we expected. At this time, the reply we got from ChatGPT is that the battery capacity is 2815mAh.
Here, the service quality of intelligent customer service is measured by the degree of acceptance of artificial customer service suggestions by intelligent customer service. The acceptance rate for product parameter consultation questions is 20%, and the acceptance rate for quality inspection item consultation is 6.4%. Human customer service is preferred for consultations such as chatting greetings and promotional activities. The intelligent customer service based on ChatGPT takes 5-10 seconds to respond to user questions, and the response time of manual customer service is about 30 seconds. The response speed of intelligent customer service is faster. ChatGPT API calls are charged by token. The current running cost of intelligent customer service is 0.12 yuan/session.
3. Classification of user problems in the second phase of optimization of the intelligent customer service system
Different types of user consultations and the adoption of suggestions given by intelligent customer service also vary greatly. When it comes to product parameter consultation and quality inspection item consultation, the opinions of intelligent customer service are highly adopted, helping manual customer service improve the response speed to user issues. For issues such as chatting issues, the adoption rate of suggestions given by intelligent customer service is low.
A user problem classification model is installed in front of the ChatGPT intelligent customer service module, and the classification results are questions about product parameter consultation and quality inspection report consultation, which are sent to the intelligent customer service system based on ChatGPT to further reduce costs and increase efficiency. The user problem classification model uses Bert for text classification tasks. Next, we briefly introduce the application of Bert classification in this scenario.
3.1 Introduction to Bert
Bert is a pre-trained language model proposed by Google in 2018 [3]. The model uses the Encode side of Transformer and captures contextual information in sentences based on a multi-head self-attention mechanism. In the pre-training stage, cloze tasks and sentence judgment tasks are used to train the network. When applied to downstream tasks, the feature vector of the CLS bit can be used as the sentence vector, and connected to the Linear layer after the network to classify sentences.
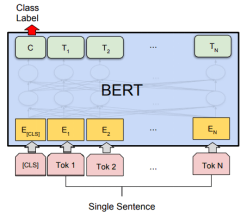
The Bert model used 3.3 billion text corpus for training in the pre-training stage, and the network has a basic understanding of natural language. Based on the Bert pre-training model, fine-tuning downstream tasks has achieved good results in many fields.
3.2 User question classification network training data
It takes a long time to manually label the data of user problem classification. Here, ChatGPT is used to give the classification of user problems as training data for Bert fine-tuning stage.
Prompt for designing classification tasks:
Please conduct text classification of user questions. User questions need to be classified as required: ['Product parameter consultation', 'Quality inspection report consultation','After-sales consultation ', 'Platform Policy', 'Activity Offers', 'Chat and Greetings'] categories.
User: How much memory does this mobile phone have?
AI: Product parameter consultation
User: Has the battery been dismantled or repaired?
AI:Quality inspection report consultation
User: Where will the goods be shipped from after placing the order?
AI:After-sales consultation
User:Does it support 7-day no-reason returns?
AI:Platform policy
User:Hello
AI: Small talk question
User:Thanks!
AI: Chat greetings
User: How long is the standby time?
3.3 Training classification model
After the training data set is ready, start fine-tuning Bert. The input of the network is a sentence. After the text is segmented by a word segmenter, a segmented token sequence is obtained. The maximum length of the Bert input token must not exceed 512. For overly long sequences, truncation is performed. After adding "[cls]" and "[sep]" to the beginning and end of the text, a padding operation will be performed to facilitate batch training of the network. Map the processed sequence to the corresponding ID according to Bert's dictionary, and then send it to the network for training. Since self-attention cannot capture position information, Bert superimposes position embedding on token embedding.
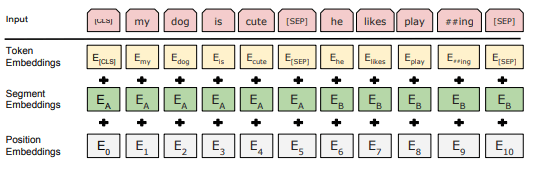
Next define the structure of the model, the code is as follows:
import torch.nn as nn
from transformers import BertModel
class Classifier(nn.Module):
def __init__(self,bert_model_path,num_classes):
super(Classifier,self).__init__()
self.bert = BertModel.from_pretrained(bert_model_path)
self.dropout = nn.Dropout(0.1)
self.fc = nn.Linear(768, num_classes)
def forward(self,tokens,masks):
_, pooled_output = self.bert(tokens, attention_mask=masks,return_dict=False)
x = self.dropout(pooled_output)
x = self.fc(x)
return x
The feature dimension produced by the Bert model is 768. After the Dropout layer randomly masks a certain proportion of weight, it is sent to the Linear layer to map the feature vector to the Label space. num_classes corresponds to the dimension of the Label space. There are 6 categories we want to classify here. . The AdamW optimizer was used for training, with a learning rate of 1e-5 and 10 rounds of training. The accuracy on the test set is 76.6%, and f1 is 0.754. The f1 for product parameter consultation is 0.791, and the f1 for quality inspection report consultation is 0.841.
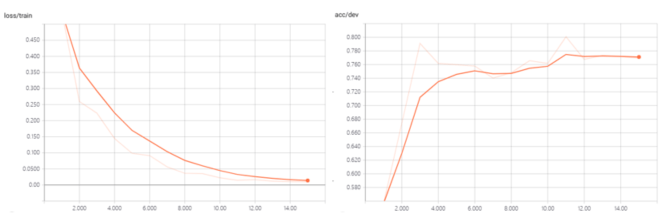
Through the front-end user question classification model, the intelligent customer service system helps the intelligent customer service system to filter out some questions that have low adoption and are suitable for manual customer service answers. The cost of the intelligent customer service system responding to user sessions has been reduced to 0.033 yuan/session, and the operating expenses have been reduced by 72.5%.
4. Screening of business details and knowledge related to quality inspection items in the third phase of optimization of the intelligent customer service system
When building intelligent customer service, the prompt includes all product details and quality inspection item information of the product, without considering the correlation between these items and the user's problem. For example, if the user's problem is battery-related, when injecting knowledge about product details and quality inspection items, you can only inject battery-related knowledge. The longer the number of tokens, the longer ChatGPT processing will take. By filtering business details and quality inspection items related to user issues and injecting knowledge, the number of tokens required to complete a session can be further reduced, reducing the operating costs of intelligent customer service while also improving the response speed of intelligent customer service.
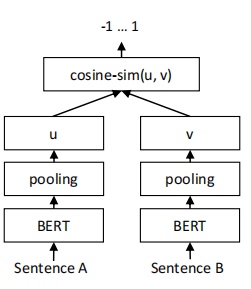
When Bert calculates the similarity of two sentences, the two sentences are input into Bert at the same time for information interaction. The calculation speed is relatively slow. The sentence vector cannot be calculated in advance, and the semantic search is relatively slow. Sentence-Bert draws on the framework of the twin network and sends two sentences into two Bert models. The parameters of the two models are shared. The network structure [4] is shown in the figure below. The Bert network outputs the embedding vector of each token and generates the representation of the sentence vector through the pooling strategy. In the paper, "[CLS]" bits, average pooling, and maximum pooling are used to generate the representation of sentence vectors. Experiments show that the average method of the pooling strategy works best. The obtained sentence vector calculates the cosine similarity between the two to measure the similarity of the two sentences.
Suppose the user asks customer service "How much is the battery?", the customer service gets the details of the product clicked by the user: 95 new iPhone 12 128G Purple Mobile 5G China Unicom 5G Telecom 5G National Bank; Network standard: All Netcom; Purchase channel: National Bank; Warranty status : Out of warranty or less than 30 days; Battery health value: 85%-90%; System version: iOS 16.5.1; Number of charges: 562; SIM card: supports dual cards; Source: second-hand high-quality products; IMEI: 352*** 833; Fulfillment service information: genuine official inspection, 7 days no reason, one-year platform warranty, SF Express free shipping, mobile phone service rights card, stored in Changsha Circulation Center, order now and expected to be delivered on August 17; CPU model: Apple A14; Battery capacity: 2815mAh; CPU frequency: 3.0GHz; Unlocking method: facial recognition; Whether fast charging is supported: Yes; Charging peak power: 20W; Resolution: 2532*1170; Screen size: 6.1 inches; Main screen material: OLED; time to market: 2020-10; operating system: iOS; screen type: full screen; rear camera: 12 million pixels + 12 million pixels; front camera: 12 million pixels; total number of cameras: three cameras (the last two); Body weight: 162g; Body size: 146.7*71.5*7.4mm; Body type: Straight board.
Sample quality inspection report of the product that the customer clicked on obtained by customer service (some items are omitted): The appearance of the casing - chipping: none; The appearance of the casing - scratches: none; The appearance of the casing - wear and tear: none; The appearance of the casing The condition of the shell appearance - deformation: none; the condition of the shell appearance - debonding/gaps: none; the shell appearance condition - shell/others: normal; the shell appearance condition - lettering/pictures: none; the shell appearance condition - bumps/paint peeling: None; Camera appearance conditions - Flash: Normal; Camera appearance conditions - Front camera: Normal; Camera appearance conditions - Rear camera: Normal; Other appearance conditions - Audio grille: Normal; Other appearance conditions - Stuck Screen appearance: normal; screen appearance - cracked: none; screen appearance - screen/others: normal; screen appearance - inner screen paint peeling: none; screen appearance - deep scratches: none; screen appearance The condition of the screen display - light scratches: none; the condition of the screen display - gray entry: none; the condition of the screen display - bright spots: none; the condition of the screen display - dead pixels: none; the condition of the screen display - signs of aging: none; the screen display condition - aging marks: none; the screen display condition - bright spots: none The situation of screen display - bubbles: none; the situation of screen display - leakage: none; the situation of screen display - stains: none; the situation of screen display - bright spots: none; the situation of screen display - other: normal; the screen touch Condition - touch: normal; button condition - power button: normal; interface condition - data interface: normal; wireless condition - wireless function: normal; sound and vibration condition - front microphone: normal; sound and vibration condition - Vibration: normal; sound and vibration situation - Speaker: normal; sound and vibration situation - Bottom microphone: normal; sound and vibration situation - Earpiece: normal; call function situation - SIM card 1: normal; call function situation -SIM card 2: normal; other conditions - ID lock: none; other conditions - system status: normal; camera status - front camera: normal; camera status - rear camera: normal.
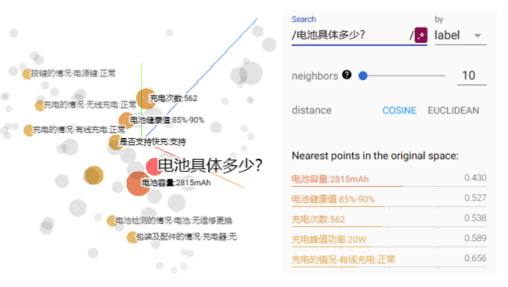
You can see that only a few items in the product details and quality inspection items are related to user issues. Injecting knowledge into all business details and quality inspection items will waste a lot of tokens, causing ChatGPT to need to find relevant information in a long sequence. Answering user questions is slow and inefficient. Here, Sentence-Bert is used to calculate the sentence vectors of user questions, business details, and quality inspection items, and the top 5 most relevant business details and quality inspection items are selected based on cosine similarity for knowledge injection. ChatGPT is based on the knowledge related to the product battery. User response. The details of the Top5 are as follows: battery capacity: 2815mAh, battery health value: 85%-90%, number of charges: 562, peak charging power: 20W, body size: 146.771.5 7.4mm, the top5 quality inspection items are as follows: charging status - wired charging: normal, battery detection status - battery: no maintenance and replacement, charging status - wireless charging: normal, button status - power button: Normal, condition of packaging and accessories - Charger: None. At this time, the response from ChatGPT intelligent customer service was "Battery capacity is 2815mAh." The number of tokens injected into the original knowledge was 1228. After filtering related knowledge, the number of tokens was reduced to 132, and the number of tokens dropped by 89%.
5. Summary
LLM's excellent natural language understanding capabilities can empower all walks of life. The traditional manual customer service field is highly dependent on manual labor and data-intensive. A large amount of data that has not been fully processed provides fertile ground for LLM to be implemented in this scenario. The intelligent customer service system based on ChatGPT has been launched here to help customer service improve service quality and efficiency.
6. References
[1] Ouyang L , Wu J , Jiang X ,et al.Training language models to follow instructions with human feedback[J].arXiv e-prints, 2022.DOI:10.48550/arXiv.2203.02155.
[2] Brown T B , Mann B , Ryder N ,et al.Language Models are Few-Shot Learners[J]. 2020.DOI:10.48550/arXiv.2005.14165.
[3] Devlin J , Chang M W , Lee K ,et al.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.DOI:10.48550/arXiv.1810.04805.
[4] Reimers N , Gurevych I .Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks[J]. 2019.DOI:10.18653/v1/D19-1410.
About the author
Wang An, a senior NLP algorithm expert, is responsible for understanding user intentions in search scenarios and implementing intelligent customer service based on ChatGPT. He has rich implementation experience in text classification, entity recognition, relationship matching, and question and answer scenarios. WeChat ID: tiantian_375699720, constructive communication is welcome.
The future belongs to those who prepare for it; if there is a road under your feet, the future can be expected.
> 转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
> 关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~