
In the author's mind, message queue , cache , and sub-database and sub-table are the three swordsmen of high concurrency solutions.
In my career, I have used well-known message queues such as ActiveMQ, RabbitMQ, Kafka, and RocketMQ.
In this article, the author combines his own real experience to share with you seven classic application scenarios of message queues.
1 Asynchronous & decoupling
The author was once responsible for the user service of an e-commerce company, which provided basic functions such as user registration, query, and modification. After the user successfully registers, a text message needs to be sent to the user.
In the picture, adding new users and sending text messages are all included in the user center service. The disadvantages of this method are very obvious:
-
The SMS channel is not stable enough and it takes about 5 seconds to send a text message. This makes the user registration interface very time-consuming and affects the front-end user experience;
-
If the SMS channel interface changes, the user center code must be modified. But User Center is the core system. You need to be cautious every time you go online. This feels very awkward, as non-core functions affect the core system.
In order to solve this problem, the author used the message queue to reconstruct it.

-
asynchronous
After the user center service successfully saves the user information, it sends a message to the message queue and immediately returns the result to the front end. This can avoid the problem of taking a long time and affecting the user experience.
-
decoupling
任务服务收到消息调用短信服务发送短信,将核心服务与非核心功能剥离,显著的降低了系统间的耦合度。
2 Peak elimination
In high-concurrency scenarios, sudden request peaks can easily cause the system to become unstable. For example, a large number of requests to access the database will put great pressure on the database, or the system's resources, CPU and IO, may become bottlenecked.
The author once served the Shenzhou private car ordering team. During the passenger life cycle of the order, the order modification operation first modifies the order cache, and then sends the message to MetaQ. The order placement service consumes the message and determines whether the order information is normal (such as whether there is out of order), if the order data is correct, it will be stored in the database.

When facing a request peak, since the concurrency of consumers is within a threshold range and the consumption speed is relatively uniform, it will not have a big impact on the database. At the same time, the producers of the order system that actually face the front-end will also become more stable.
3 message bus
The so-called bus is like the data bus in the motherboard, with the ability to transmit and interact data. The parties do not communicate directly and use the bus as a standard communication interface .
The author once served the order team of a lottery company. During the life cycle of a lottery order, it went through many steps such as creation, splitting sub-orders, ticket issuance, and prize calculation. Each link requires different service processing, each system has its own independent table, and the business functions are relatively independent. If every application had to modify the information in the order master table, it would be quite confusing.
Therefore, the company's architect designed the service of <font color="red"> Dispatch Center </font>. The Dispatch Center maintains order information, but it does not communicate with sub-services, but through message queues and ticketing gateways. Systems such as prize calculation services transmit and exchange information.
The architectural design of the message bus can make the system more decoupled and allow each system to perform its own duties.
4 Delayed tasks
When a user places an order on the Meituan APP and does not pay immediately, a countdown will be displayed when entering the order details. If the payment time is exceeded, the order will be automatically canceled.
A very elegant way is to use delayed messages from the message queue .
After the order service generates the order, it sends a delayed message to the message queue. The message queue delivers the message to the consumer when the message reaches the payment expiration time. After the consumer receives the message, it determines whether the order status is paid. If it is not paid, the logic of canceling the order is executed.

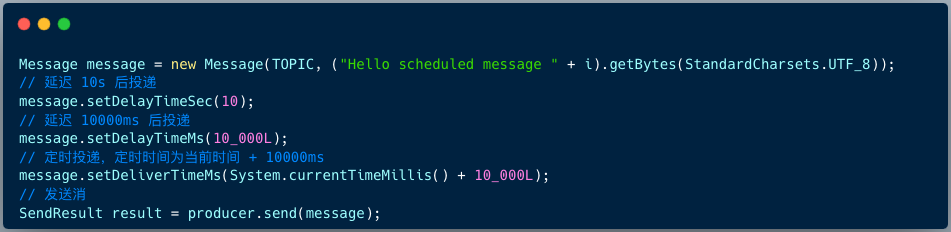
The code for RocketMQ 4.X producer to send delayed messages is as follows:
Message msg = new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
//设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
RocketMQ 4.X version supports 18 levels of delayed messages by default, which is determined by the messageDelayLevel configuration item on the broker side.

RocketMQ 5.X version supports delaying messages at any time. The client provides 3 APIs to specify the delay time or timing time when constructing the message.
5 Radio consumption
Broadcast consumption : When using the broadcast consumption mode, each message is pushed to all consumers in the cluster, ensuring that the message is consumed by each consumer at least once.
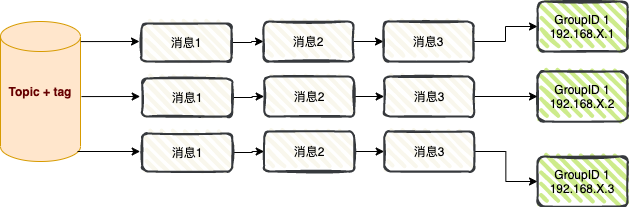
Broadcast consumption is mainly used in two scenarios: message push and cache synchronization .
01 Message push
The figure below shows the driver-side push mechanism of a private car. After the user places an order, the order system generates a special car order. The dispatch system will dispatch the order to a driver based on the relevant algorithm, and the driver-end will receive the dispatch push message.
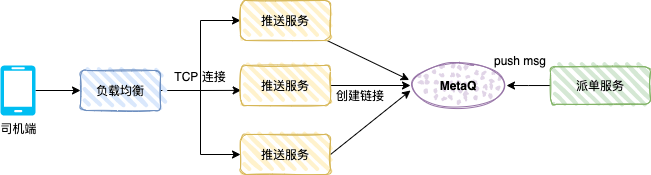
The push service is a TCP service (custom protocol) and a consumer service. The message mode is broadcast consumption.
After the driver opens the driver APP, the APP will create a long connection through load balancing and push service, and the push service will save the TCP connection reference (such as driver number and TCP channel reference).
The dispatch service is the producer and sends the dispatch data to MetaQ. Each push service will consume the message. The push service determines whether the TCP channel of the driver exists in the local memory. If it exists, the data is pushed to the server through the TCP connection. Driver side.
02 Cache synchronization
In high-concurrency scenarios, many applications use local cache to improve system performance.
The local cache can be HashMap, ConcurrentHashMap, or the caching framework Guava Cache or Caffeine cache.

As shown in the figure above, after application A is started, as a RocketMQ consumer, the message mode is set to broadcast consumption. In order to improve interface performance, each application node loads the dictionary table into the local cache.
When the dictionary table data changes, a message can be sent to RocketMQ through the business system, and each application node will consume the message and refresh the local cache.
6 Distributed transactions
Taking the e-commerce transaction scenario as an example, the core operation of user payment for orders will also involve changes in multiple subsystems such as downstream logistics delivery, points changes, and shopping cart status clearing.
![]()
1. Traditional XA transaction solution: insufficient performance
In order to ensure the consistency of execution results of the above four branches, a typical solution is implemented by a distributed transaction system based on the XA protocol. Encapsulate the four call branches into a large transaction containing four independent transaction branches. The solution based on XA distributed transactions can meet the correctness of business processing results, but the biggest disadvantage is that in a multi-branch environment, the resource locking range is large and the concurrency is low. As the number of downstream branches increases, the system performance will become worse and worse.
2. Based on ordinary message scheme: difficulty in ensuring consistency
![]()
In this solution, the message downstream branch and the main branch of the order system change are prone to inconsistencies, for example:
- The message was sent successfully, but the order was not executed successfully, and the entire transaction needs to be rolled back.
- The order was executed successfully, but the message was not sent successfully, and additional compensation was required to discover the inconsistency.
- The message sending timeout is unknown, and it is impossible to determine whether the order needs to be rolled back or the order changes submitted.
3. Based on RocketMQ distributed transaction messages: supports eventual consistency
In the above-mentioned ordinary message solution, the reason why ordinary messages and order transactions cannot be guaranteed to be consistent is essentially because ordinary messages cannot have the ability to commit, rollback, and unified coordination like stand-alone database transactions.
The distributed transaction message function implemented based on RocketMQ supports two-stage submission capabilities based on ordinary messages. Bind two-phase submission to local transactions to achieve consistency in global submission results.
RocketMQ transaction messages support ensuring the eventual consistency of message production and local transactions in distributed scenarios . The interaction process is shown in the figure below:
![]()
1. The producer sends the message to the Broker.
2. After the Broker successfully persists the message, it returns an Ack to the producer to confirm that the message has been sent successfully. At this time, the message is marked as " temporarily undeliverable ". The message in this state is a semi-transaction message .
3. The producer starts executing local transaction logic .
4. The producer submits a secondary confirmation result (Commit or Rollback) to the server based on the local transaction execution result. After the Broker receives the confirmation result, the processing logic is as follows:
- The secondary confirmation result is Commit: the Broker marks the semi-transaction message as deliverable and delivers it to the consumer.
- The secondary confirmation result is Rollback: the Broker will roll back the transaction and will not deliver the semi-transaction message to the consumer.
5. In special circumstances where the network is disconnected or the producer application is restarted, if the Broker does not receive the secondary confirmation result submitted by the sender, or the secondary confirmation result received by the Broker is in the Unknown status, after a fixed period of time, the service The terminal will initiate a message review from the message producer, that is, any producer instance in the producer cluster .
- After the producer receives the message review, it needs to check the final result of the local transaction execution corresponding to the message.
- The producer submits a secondary confirmation again based on the final status of the local transaction that is checked , and the server still processes the half-transaction message according to step 4.
7 Data transfer hub
In the past 10 years, special systems such as KV storage (HBase), search (ElasticSearch), streaming processing (Storm, Spark, Samza), time series database (OpenTSDB) and other special systems have emerged. These systems were created with a single goal in mind, and their simplicity makes it easier and more cost-effective to build distributed systems on commodity hardware.
Often, the same data set needs to be injected into multiple specialized systems.
For example, when application logs are used for offline log analysis, searching for individual log records is also indispensable. It is obviously impractical to build independent workflows to collect each type of data and then import them into their own dedicated systems. Using message queues Kafka serves as a data transfer hub, and the same data can be imported into different dedicated systems.
Log synchronization mainly has three key parts: log collection client, Kafka message queue and back-end log processing application.
- The log collection client is responsible for collecting log data of various user application services, and sends the logs "in batches" and "asynchronously" to the Kafka client in the form of messages. The Kafka client submits and compresses messages in batches, which has very little impact on the performance of application services.
- Kafka stores logs in message files, providing persistence.
- Log processing applications, such as Logstash, subscribe to and consume log messages in Kafka, and eventually the file search service retrieves the logs, or Kafka passes the messages to other big data applications such as Hadoop for systematic storage and analysis.

If my article is helpful to you, please like it, read it, and forward it. Your support will encourage me to produce higher-quality articles. Thank you very much!
