
Author|Cheng Wei, MetaAPP big data R&D engineer
ByConity is ByteDance's open source cloud-native data warehouse. It meets the needs of data warehouse users for elastic resource expansion and contraction, read-write separation, resource isolation, strong data consistency, etc., while also providing excellent query, write performance.
MetaApp is a leading game developer and operator in China, focusing on the efficient distribution of mobile information and committed to building a virtual world for all ages. As of 2023, MetaApp has more than 200 million registered users, has collaborated on 200,000 games, and has a cumulative distribution volume of over 1 billion.
MetaApp paid attention to ByConity in the early days of open source and was one of the first users to test and launch it in the production environment. With the idea of understanding the capabilities of open source data warehouse projects, the MetaApp big data R&D team conducted a preliminary test on ByConity. Its storage-computation separation architecture and excellent performance, especially in log analysis scenarios, support for complex queries on large-scale data, attracted MetaApp to conduct in-depth testing of ByConity, and eventually fully replaced ClickHouse in the production environment, reducing resource costs by more than 50%. %.
This article will mainly introduce the functions of the MetaApp data analysis platform, the problems and solutions encountered in business scenarios, and the help of introducing ByConity to its business.
MetaApp OLAP data analysis platform architecture and functions
With the growth of business and the introduction of refined operations, products have put forward higher requirements for the data department, including the need to query and analyze real-time data and quickly adjust operation strategies; conduct AB experiments on a small group of people to verify the effectiveness of new functions It reduces data query time and difficulty, allowing non-professionals to analyze and explore data independently. In order to meet business needs, MateApp has implemented an OLAP data analysis platform that integrates event analysis, conversion analysis, custom retention, user grouping, behavior flow analysis and other functions .
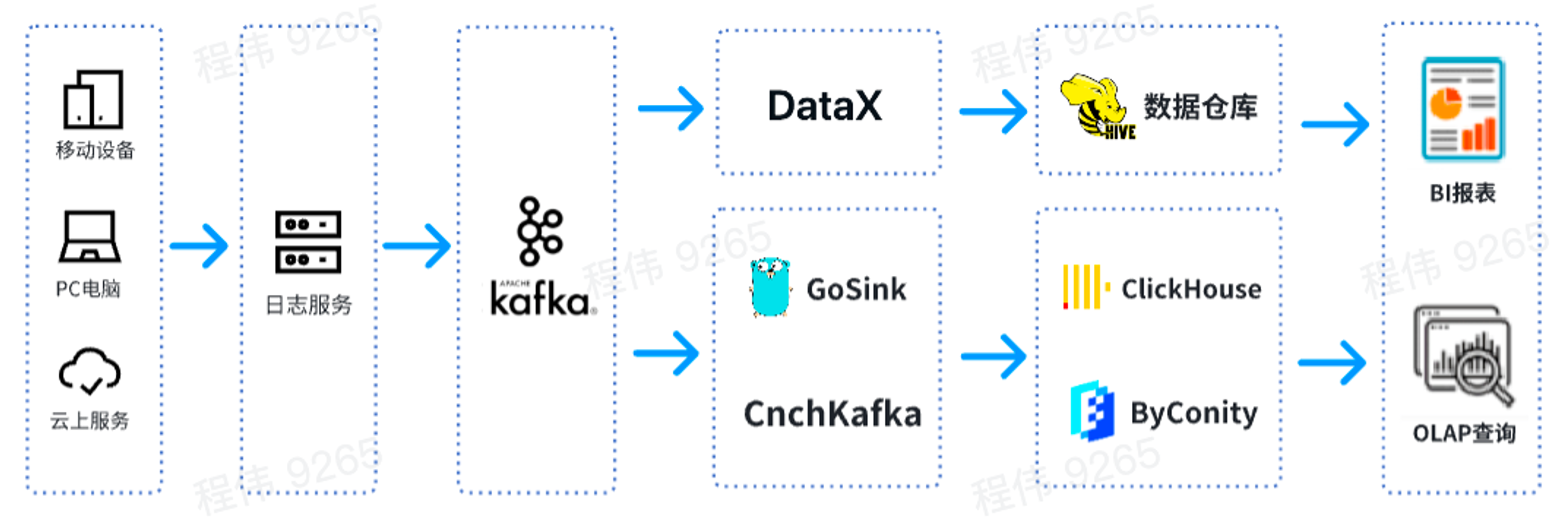
This is a typical OLAP architecture, divided into two parts, one is offline and the other is real-time.
In the offline scenario , we use DataX to integrate Kafka data into the Hive data warehouse and then generate BI reports. BI reports use the Superset component to display results;
In a real-time scenario , one line uses GoSink for data integration and integrates GoSink data into ClickHouse, and the other line uses CnchKafka to integrate data into ByConity. Finally, the data is obtained through the OLAP query platform for query.
Function comparison between ByConity and ClickHouse
ByConity is an open source cloud-native data warehouse developed based on the ClickHouse core and adopts a storage-computation separation architecture. Both have the following characteristics:
- The writing speed is very fast, suitable for writing large amounts of data, and the amount of data written can reach 50MB - 200MB/s
- The query speed is very fast. Under massive data, the query speed can reach 2-30GB/s.
- High data compression ratio, low storage cost, compression ratio can reach 0.2~0.3
ByConity has the advantages of ClickHouse, maintains good compatibility with ClickHouse, and has been enhanced in terms of read-write separation, elastic expansion and contraction , and strong data consistency . Both are applicable to the following OLAP scenarios:
- Datasets can be large - billions or trillions of rows
- The data table contains many columns
- Query only specific columns
- Results must be returned in milliseconds or seconds
In previous sharings, the ByConity community compared the two [from a usage perspective]
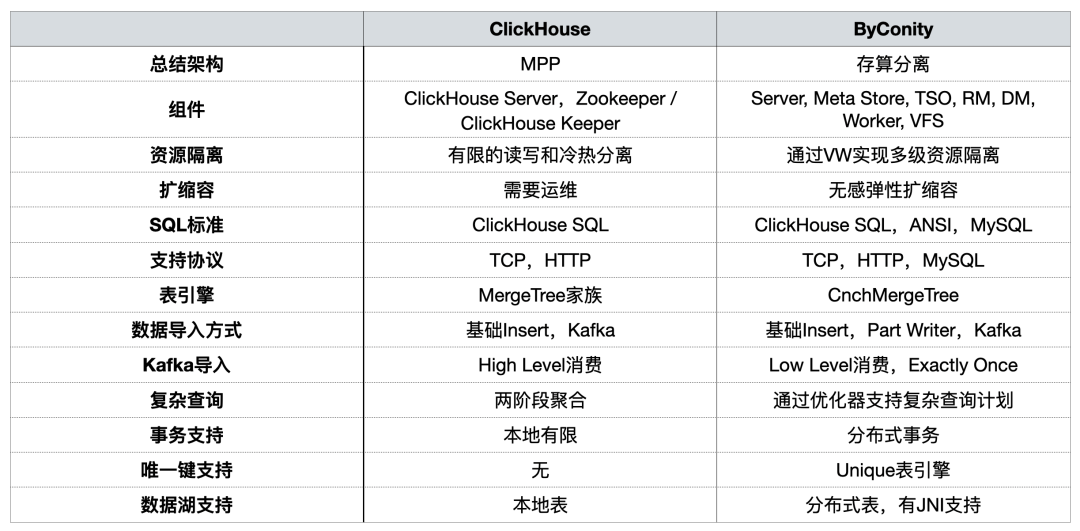
During the construction of the OLAP platform, we mainly focused on resource isolation, capacity expansion and contraction , complex queries, and support for distributed transactions .
Problems encountered when using ClickHouse
Problem 1: Integrated reading and writing can easily seize resources and cannot guarantee stable reading/writing.
During peak business periods, data writing will occupy a large amount of IO and CPU resources, causing queries to be affected (query times will become longer). The same goes for data queries.
Problem 2: Expansion/reduction is troublesome and takes a long time
- Long expansion/shrinking time: Since the machine is in an IDC and belongs to a private cloud, one of the problems is that the node addition cycle is extremely long. It takes one to two weeks from the time the node demand is issued to the actual addition of good nodes, which affects the business;
- Unable to scale up and down quickly: Data needs to be redistributed after scaling up, otherwise the node pressure will be very high.
Problem three: Operation and maintenance are cumbersome, and SLA cannot be guaranteed during peak business periods.
- Often due to business node failures, data queries are slow and data writing is delayed (from a few hours to a few days);
- There is a serious shortage of resources during peak business periods, and it is impossible to expand resources in the short term. The only way is to delete the data of some services to provide services for high-priority services;
- During low business periods, a large number of resources are idle and costs are inflated. Although we are in IDC, IDC machine purchase is also subject to cost control, and node expansion cannot be unlimited. In addition, there is a certain cost consumption during normal use;
- Unable to interact with cloud resources.
Improvements after introducing ByConity
First of all, ByConity’s separation of reading and writing computing resources can ensure that reading and writing tasks are relatively stable. If the reading tasks are not enough, the corresponding resources can be expanded to make up for the shortage, including using cloud resources for expansion.
Secondly, scaling up and down is relatively simple and can be done at the minute level. Since HDFS/S3 distributed storage is used and computing and storage are separated, data redistribution is not required after expansion and can be used directly after expansion.
In addition, cloud native deployment and operation and maintenance are relatively simple.
- The components of HDFS/S3 are relatively mature and stable, with capacity expansion and contraction, mature disaster recovery solutions, and problems can be solved quickly;
- During peak business periods, SLA can be guaranteed through rapid expansion of resources;
- During low business peak periods, costs can be reduced by reducing storage/computing resources.
The use and operation of ByConity
ByConity cluster usage
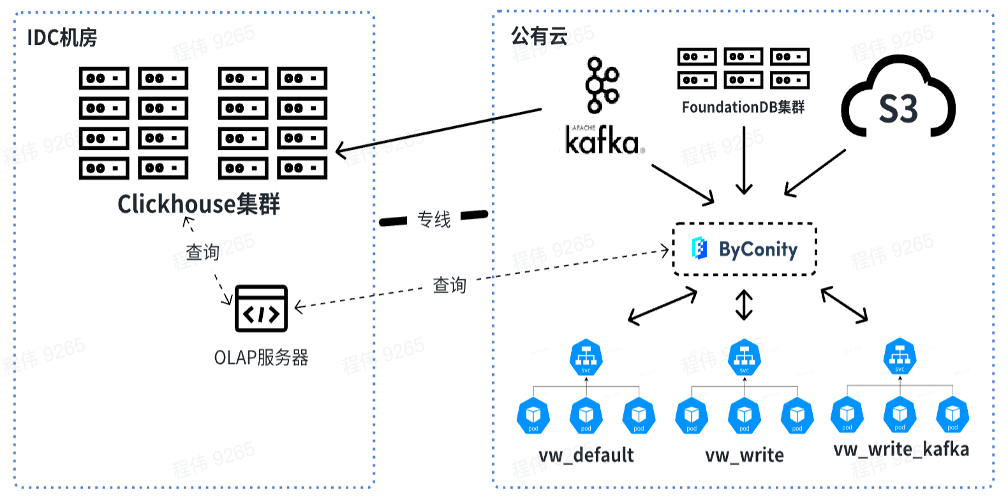
Currently, our platform has stably used ByConity in business scenarios. Through successive migrations, ByConity has completely taken over the data of the ClickHouse cluster and has begun to provide services stably. We built the ByConity cluster using S3 plus K8s on the cloud. We also used a scheduled expansion and contraction solution, which can be expanded at 10 a.m. and reduced at 8 p.m. on weekdays. We only need to use resources for more than ten hours a day. . According to calculations, this method reduces resources by about 40%-50% compared to directly using annual and monthly subscriptions. In addition, we are also promoting the combination of private cloud + public cloud to achieve the purpose of reducing costs and improving service stability.
The figure below shows our current usage, using the OLAP server to perform joint queries on the ClickHouse cluster and ByConity in the offline IDC computer room. In the short term, the ClickHouse cluster will still be used as a transition for businesses that partially rely on ClickHouse.
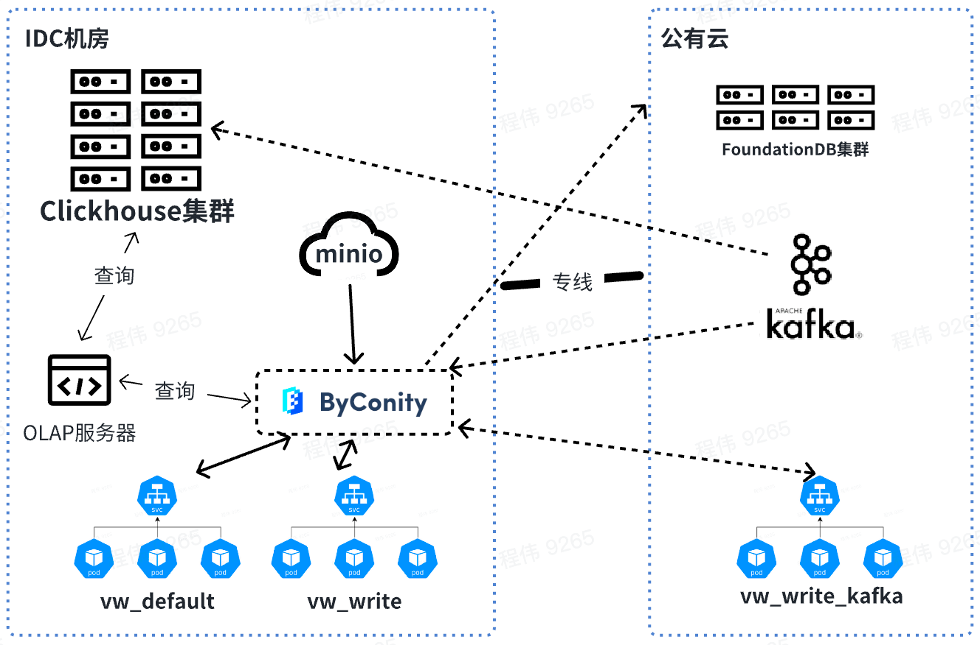
In the future, we will query and merge data offline, while the resources consumed by Kafka will be used online. When expanding resources, you can expand the resources of vw_default and vw_write online, and rationally use public cloud resources to deal with the problem of insufficient resources. At the same time, the capacity is reduced during low business peaks to reduce public cloud consumption.
Comparison of ByConity and ClickHouse queries in business data
Test data set and resource configuration
- Number of data items: Partitioned by date, 4 billion items in a single day, 40 billion in total in 10 days
- Tabular data: 2800 columns
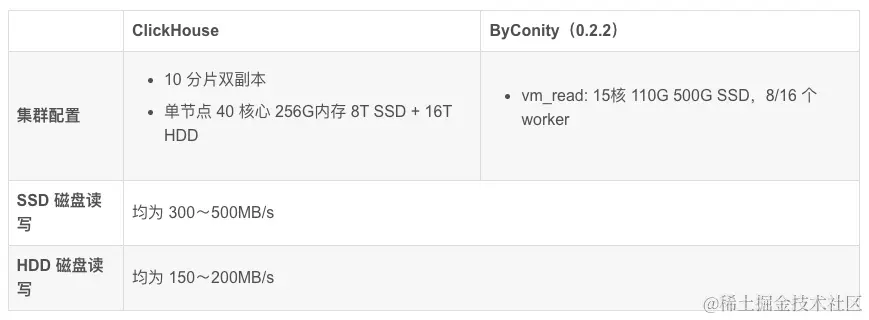
As can be seen from the above table:
The resources used by ClickHouse cluster query are: 400 cores and 2560G memory
The resources used by ByConity 8 worker cluster query are: 120 cores and 880G memory
The resources used by ByConity 16 worker cluster query are: 240 cores and 1760G memory
Summary of business SQL query results
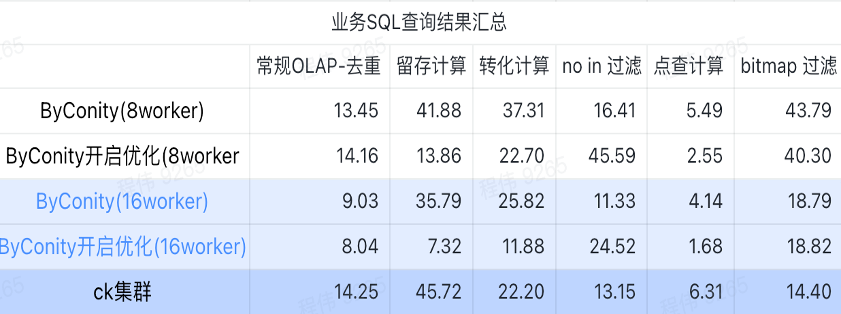
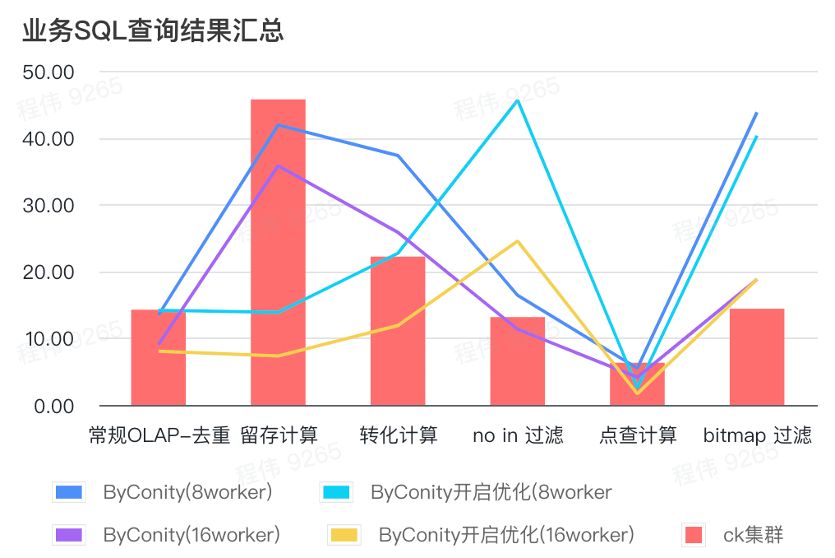
The summary here uses the average value, as you can see:
- Conventional OLAP - deduplication, retention, conversion, and enumeration can achieve the same query effect as the ClickHouse cluster (400C, 2560G) at a relatively small resource cost (120C, 880G), and can be doubled by expanding the resources (240C, 1760G ) to achieve the effect of doubling the query speed. If higher query speed is required, more resources can be expanded;
- Not in filtering may require a moderate resource cost (240C, 1760G) to achieve similar effects to the ClickHouse cluster (400C, 2560G);
- Bitmap may require greater resource costs to achieve similar effects to ClickHouse clusters.
General query/event analysis query
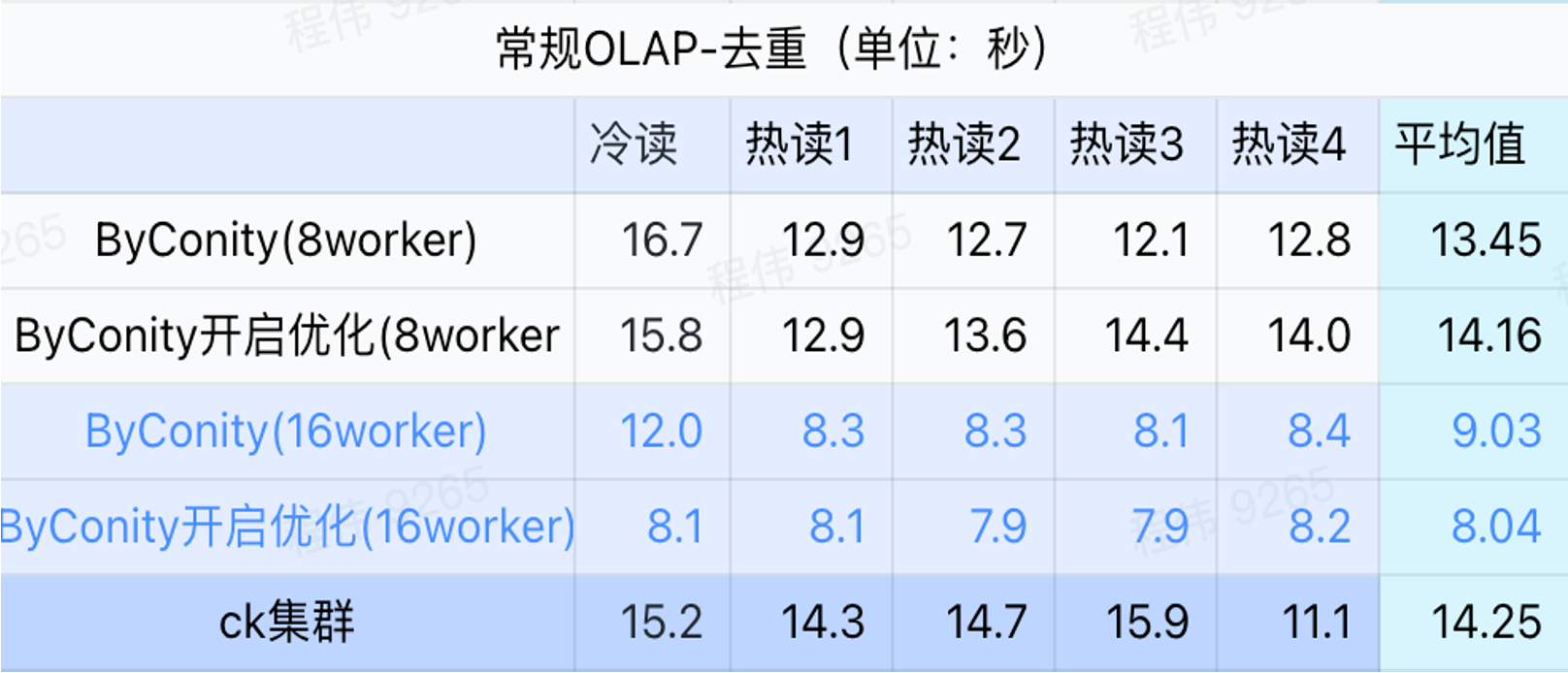
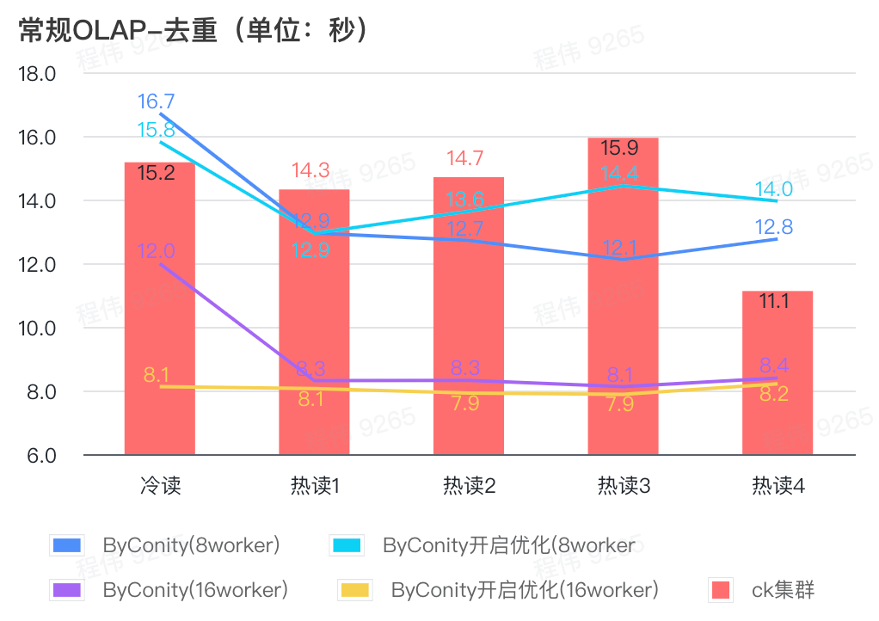
As can be seen from the above figure:
- In the deduplication query scenario, there is not much difference between turning on ByConity optimization and not turning on optimization;
- 8 workers (120C 880G) basically achieve query time close to ClickHouse;
- In deduplication scenarios, the query speed can be accelerated by expanding computing resources.
Retention calculation
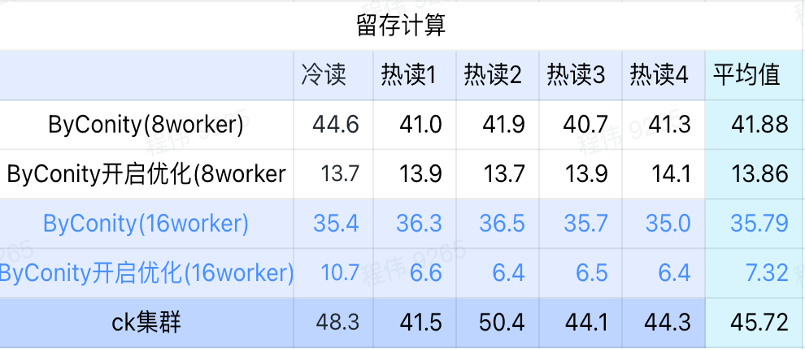
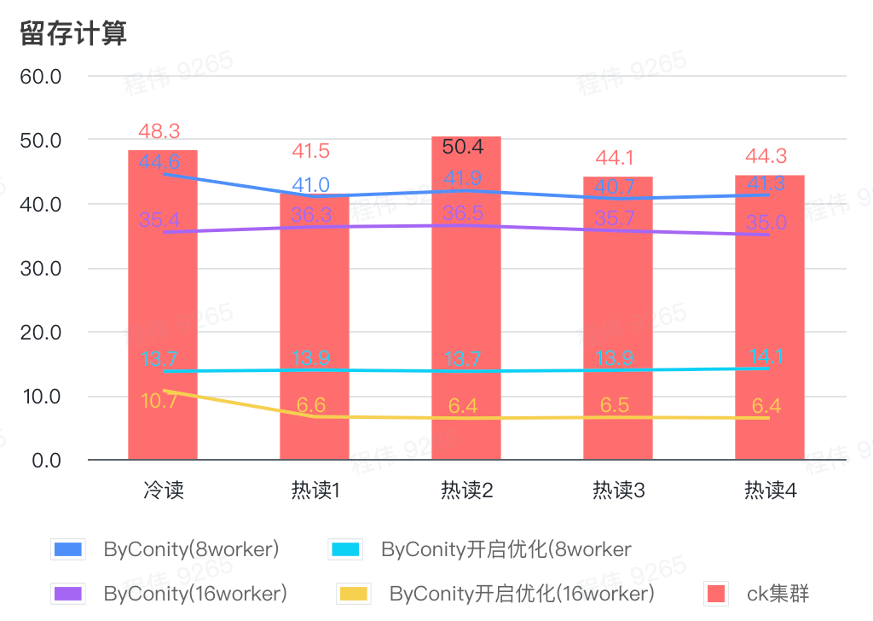
As can be seen from the above figure:
- In the retained computing scenario, the query time after ByConity turns on optimization is 33% of the query time without turning on optimization;
- 8 worker (120C 880G) The query time with optimization turned on is 30% of the query time;
- In the retained computing scenario, the query speed can be accelerated to 16% of the CK query time by expanding computing resources + optimization.
Conversion calculation
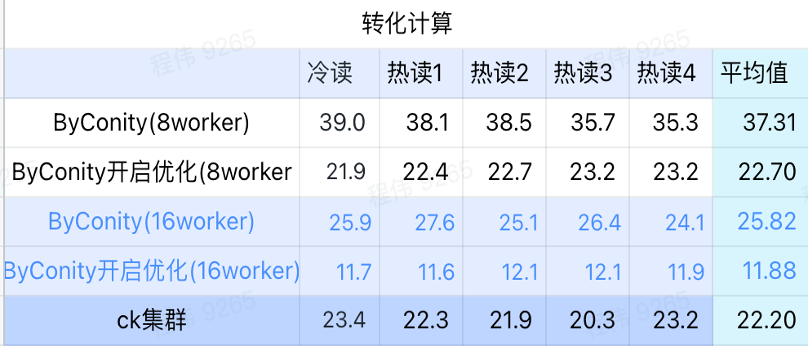
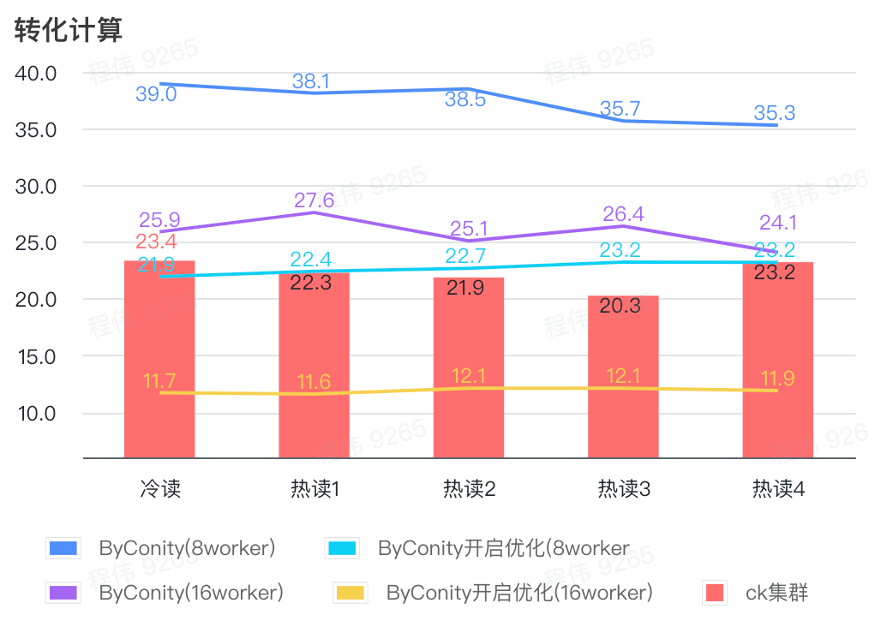
As can be seen from the above figure:
- In the conversion calculation scenario, the query time after ByConity is enabled for optimization is 60% of the query time without optimization;
- The query time of 8 workers (120C 880G) with optimization turned on is close to the ClickHouse query time;
- Transforming computing scenarios, the query speed can be accelerated to 53% of ClickHouse query time by expanding computing resources + optimization.
not in filter
Not in filtering is mainly used in user grouping scenarios and user tagging scenarios.

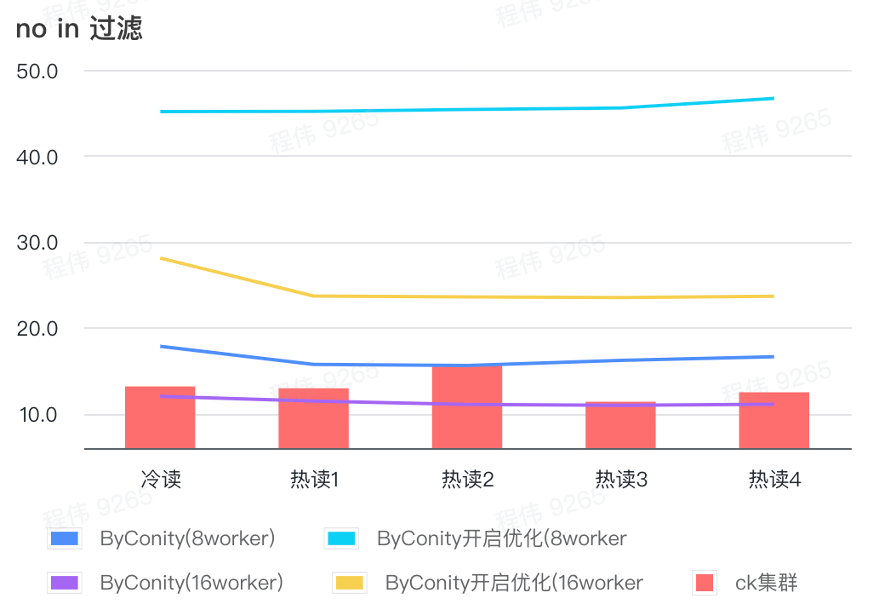
As can be seen from the above figure:
- In the no in filtering scenario, ByConity with optimization turned on is worse than ByConity with optimization not turned on, so in this scenario we directly use the method of not turning on optimization;
- 8 worker (120C 880G) query time without optimization is slower than ClickHouse query time, but not much;
- In no in filtering scenarios, the query speed can be accelerated to 86% of ClickHouse query time by expanding computing resources.
Click calculation 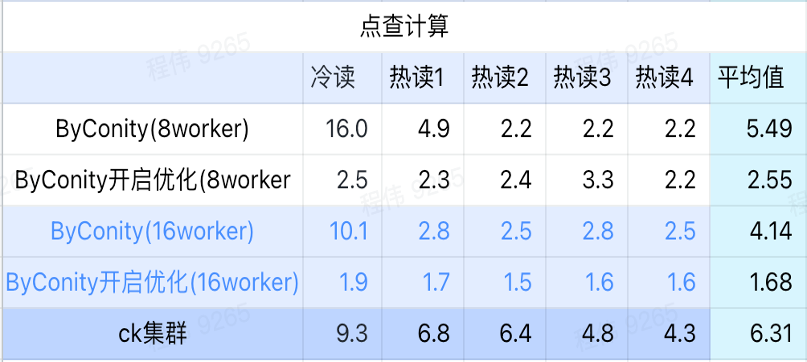
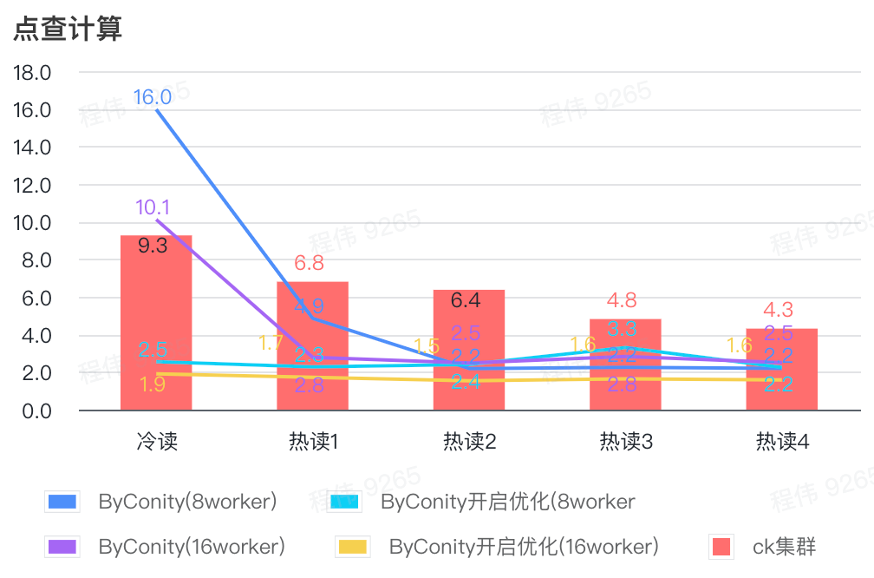
As can be seen from the above figure:
- After checking the scene, it is better to turn ByConity on and optimize than ByConity not to turn on optimization;
- The query time of 8 workers (120C 880G) without optimization is close to the ClickHouse query time;
- In the click-through scenario, the query speed can be accelerated to 26% of the ClickHouse query time by expanding computing resources and turning on optimization.
bitmap query
Bitmap query is a scenario that is used more in AB testing.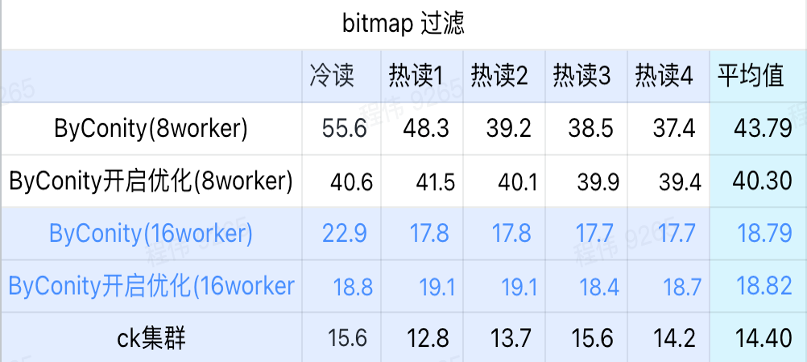
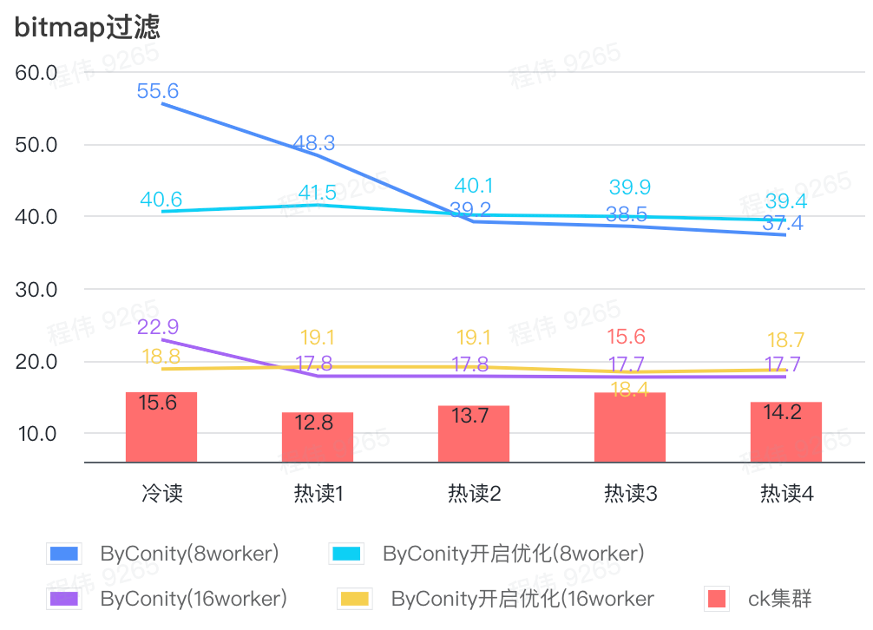
As can be seen from the above figure:
- In the bitmap filtering scene, it is better to turn ByConity optimization on than without ByConity optimization;
- 8 worker (120C 880G) query time without optimization is much slower than ClickHouse query time;
- Bitmap filtering scene, expanding resources to 16 workers (240C 1769G) is slower than ClickHouse query.
Gains after full migration of ByConity
Reduced resources
The following does not count the differences of CPU, the data is for reference only.
After full migration using ByConity
- Comparison of query and merge resource consumption shows that CPU consumption is reduced by about 75% compared to before;
- Comparing data writing resources, CPU consumption is reduced by about 35% compared to before;
- Only half of the fixed resources need to be purchased, and the remaining half depends on the flexibility of working days (10 a.m. to 8 p.m.). The cost is reduced by about 25% compared to purchasing the full amount of resources;
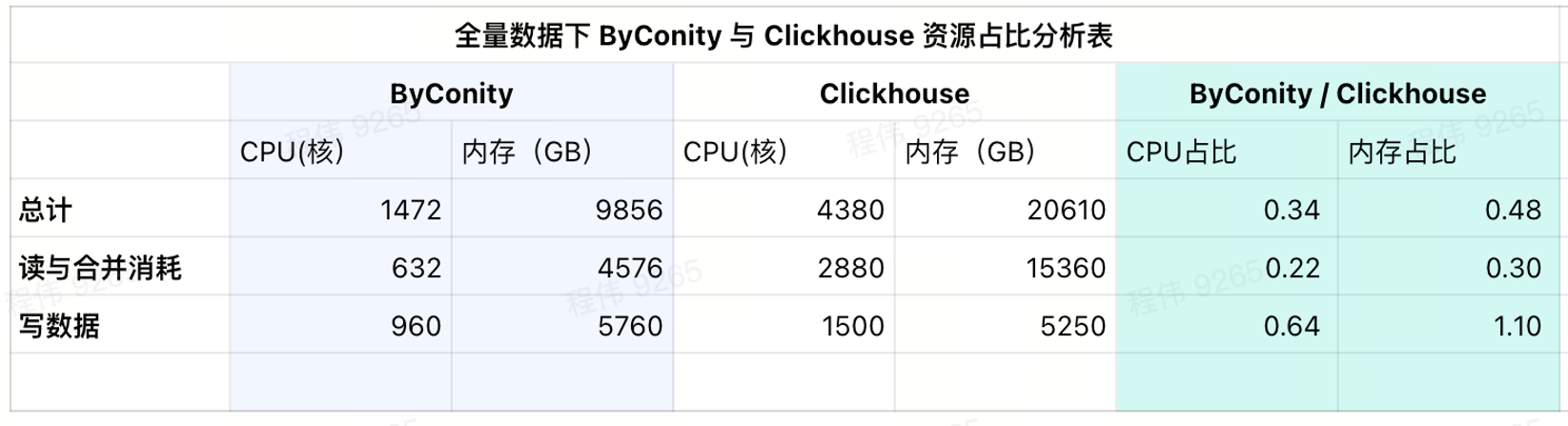
Current usage consumption
As can be seen from the current results table, ByConity's CPU and memory ratios are 34% and 48% of ClickHouse respectively.
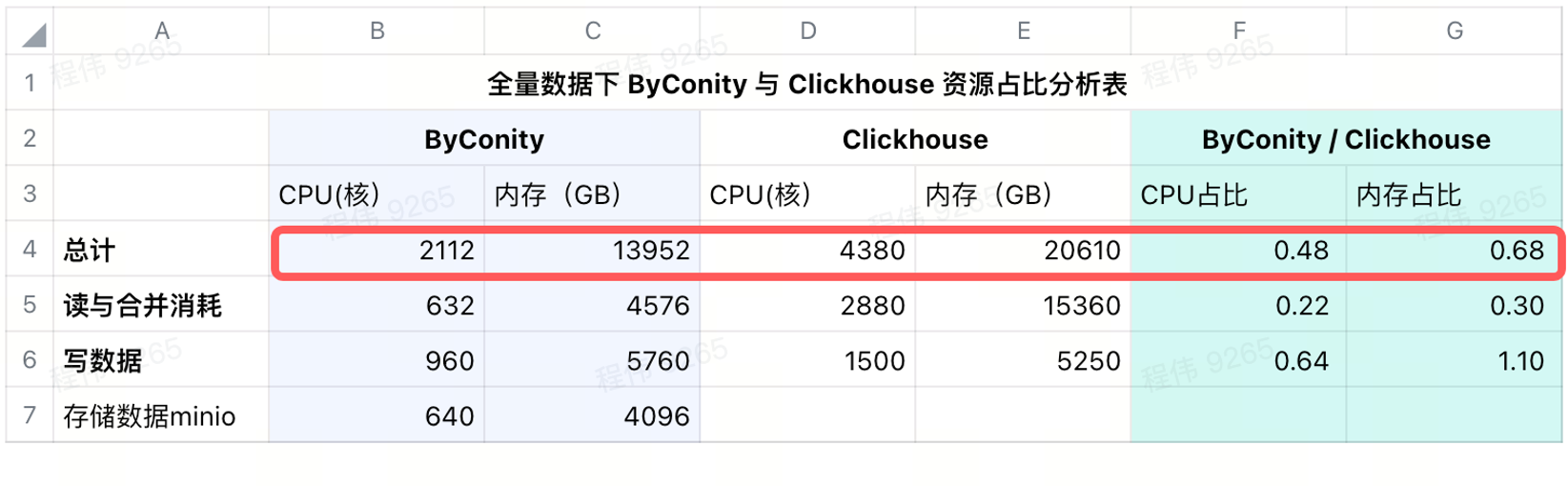
Consumption after adding remote storage
We use minio for data storage in IDC, using a 640-core CPU, 4096G memory, 16 nodes, a single node with 40 cores, 256G, and a disk of 36T. After adding these costs to ByConity, ByConity’s CPU and memory ratio Still lower than ClickHouse, respectively 48% and 68% of ClickHouse. It can be said that in terms of resource use, if calculated on a yearly and monthly basis, ByConity will be at least about 50% lower than before; if it is started and stopped on demand, the cost will be reduced by about 25% compared to purchasing resources in full .
Reduced operation and maintenance costs
- Easier way to write configuration data. In the past, the write service we specially configured often had problems such as Too many parts.
- Peak query expansion is easier. Just add the number of pods and you can quickly expand the capacity. No one will ask "Why didn't the data come out after checking for half an hour?"
Suggestions for replacing ClickHouse with ByConity
- Test whether your SQL can run normally on the ByConity platform in your business. If it is compatible, it will basically run. If there are some minor problems in individual cases, you can raise them in the community to get quick feedback;
- Control the resources of the test cluster, test data set size, and compare the query results of the ByConity cluster and the ClickHouse cluster to see if they meet expectations. If expected, replacement can be planned. For tasks that are more computationally focused, ByConity may perform better;
- Based on the size of the test data set, the consumed S3 and HDF space, bandwidth, and QPS computing resource usage, the resources required for storage and computing of the full amount of data are evaluated;
- Enter the data into the ByConity or ClickHouse cluster at the same time and start dual running for a period of time to solve problems that arise during the dual running. For example, when our company has insufficient resources, we use them based on business. We can first build a ByConity cluster on the cloud, move in a certain part of the business, and then gradually replace it based on the business. After freeing up IDC resources, we can move these Part of the data is migrated offline;
- You can unsubscribe from the ClickHouse cluster after there are no problems with dual running.
There are some considerations during this process:
- The read bandwidth and QPS of S3 and HDFS remote storage may be higher, and certain preparations are required. For example, our peak read and write bandwidth per second is: write 2.5GB/read 6GB, and the peak QPS per second is: 2~6k;
- When the bandwidth of the Worker node is full, it will also cause a query bottleneck;
- The cache disk of the Default node (that is, the read computing node) can be configured to be appropriately larger, which can reduce the bandwidth pressure of S3 during query and speed up the query.
- If you encounter uncached data, you may have cold start issues. ByConity also has some operational suggestions for this, which need to be more integrated with its own business. For example, we use pre-checking in the morning to alleviate this part of the cold start problem.
future plan
In the future, we will promote the testing and implementation of the ByConity data lake solution. In addition, we will combine data indicator management with data warehouse theory, so that 80% of queries will fall on the data warehouse. Everyone is welcome to join in the experience.
GitHub |https://github.com/ByConity/ByConity

Scan the QR code to add ByConity Assistant
Fellow chicken "open sourced" deepin-IDE and finally achieved bootstrapping! Good guy, Tencent has really turned Switch into a "thinking learning machine" Tencent Cloud's April 8 failure review and situation explanation RustDesk remote desktop startup reconstruction Web client WeChat's open source terminal database based on SQLite WCDB ushered in a major upgrade TIOBE April list: PHP fell to an all-time low, Fabrice Bellard, the father of FFmpeg, released the audio compression tool TSAC , Google released a large code model, CodeGemma , is it going to kill you? It’s so good that it’s open source - open source picture & poster editor tool