
There are extensive risk control requirements in aspects such as credit access and transaction marketing of financial business products. As business types increase, traditional expert rules and scorecard models are unable to cope with increasingly complex risk control scenarios.
In the context of traditional risk control where expert rule systems are the mainstream application, the input habits of rule models are called "variables." Risk assessment based on expert rules has the characteristics that it is difficult to quantify the rule trigger threshold, and there is a bottleneck in improving the accuracy of rule hits.
With the technical implementation of machine learning and neural network algorithms, more and more "features" are beginning to be used to refer to the input parameters provided to the algorithm model . Specifically, "features" serve as the output parameter of the upstream foreign interface during its output process, and serve as the input parameter of the downstream rule model during the application-side input process.
construction background
Feature variable data sources include basic customer information, financial status, consumption behavior and social network graphs, etc., which are input into different risk control models to reflect the borrower's credit status and risk level. Efficient feature extraction management is a series of online The data basis for risk control actions.
In financial institutions such as banks and insurance companies, due to the complexity of the organizational structure of risk business sources, there is inevitably a chimney-style development of characteristic variables between different lines. The data needs of strategy modelers are often limited to a certain product. It has been developed and deployed but has not formed a unified management and sharing platform mechanism, resulting in deviations in the consistency of data usage and policy generation between businesses.
Therefore, it is necessary to further productize the abstraction of the risk business data process to standardize the derivation, storage, call and monitoring of characteristic variables, and a unified risk control characteristic variable platform has also emerged.
Pain point analysis
In the risk control task development scenario, the model task fetches numbers from the pre-developed variable storage table. In actual development, there are often business and development pain points such as high threshold for feature development and deployment, difficulty in extracting complex features, inconsistent feature application calibers, and inconsistent feature processing processes.
01 The threshold for developing real-time feature variables is high
The technology stack of risk control business-related strategy modelers is mainly based on Python and SQL capabilities. There is a certain learning cost for Flink development based on Java semantics. In addition to model training and deployment based on offline data, real-time feature processing capabilities are insufficient.
02 It is difficult to extract complex feature variables
The return messages of some external data source interfaces have many nested levels, the location of the parameters is confusing, the interface is difficult to obtain, and there is a lack of unified platform management and maintenance for extracted features.
03 The application caliber of feature variables is inconsistent
When building a risk control model , the model tasks have the same feature variable requirements, but there are situations where feature engineering processing is repeated for the same original data in different teams or different projects, resulting in the consistency and accuracy of the corresponding SQL after the feature variable logic is changed. question.
04 It is difficult to unify the feature variable processing process
The requirements for new feature variables on the downstream strategy and model side lack a consistent and standardized processing path, resulting in confusing naming of incoming and outgoing parameters in the corresponding variable table. When the new fields are added, the upstream table cannot be read through the original SQL, resulting in more complex nested Join operations. With the configuration of derived features and variable sets , task scale and resource usage are often difficult to control.
Risk control characteristic variable system construction plan
The construction of risk control characteristic variable system focuses on real-time risk identification and prevention and control of financial institutions . Through batch extraction, aggregation and derivative processing of multi-source heterogeneous data, a unified characteristic variable platform that is standardized and easy to expand is precipitated to realize data access. , feature variable generation , end-to-end closed loop that provides data for downstream model training and decision execution, improving risk event response speed and decision-making accuracy.
01 Technical capabilities
Risk control business often faces real-time data processing requirements. In customer transactions, credit approval and other scenarios, stream computing can update customer credit ratings, limit control and other risk information in real time, providing real-time cross-system risk identification capabilities for downstream decision-making engines.
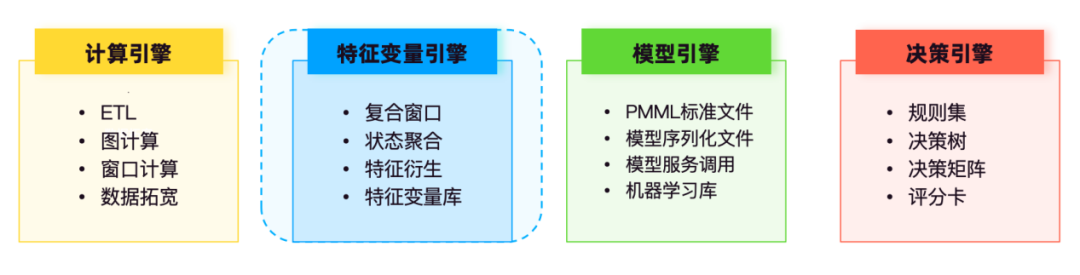
In the real-time risk control technology system architecture , computing includes batch computing, stream computing and graph computing. Taking stream computing capabilities as an example, Flink provides underlying real-time feature computing capabilities, which are mainly used for data ETL, wide table processing , and window processing . Computing, dual-stream Join and other scenarios, through pre-calculation, state aggregation calculation and other capabilities, the processing of original feature variables, standard feature variables, and derived feature variables is realized to provide feature support for decision-making models.
The model engine is mainly responsible for storing and managing various trained models, such as credit scoring models, fraud detection models , churn warning models, etc.
The decision engine centrally manages policy models such as rule sets, decision trees, decision matrices, and scorecards. The rule set calls the feature variable service and the model service of the model engine to participate in the logical operation of the decision flow.
Based on heterogeneous data sources, the feature variable engine performs data extraction, processing and calculation, standardized management and maintenance, and enables self-service query by risk control personnel, making business data retrieval and data analysis more convenient and standardized.
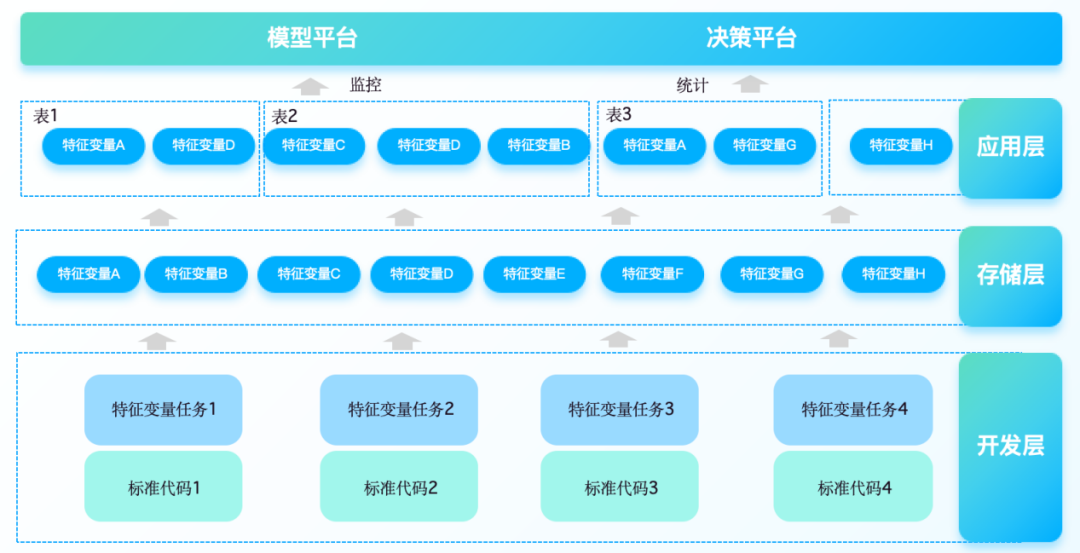
02 Data source
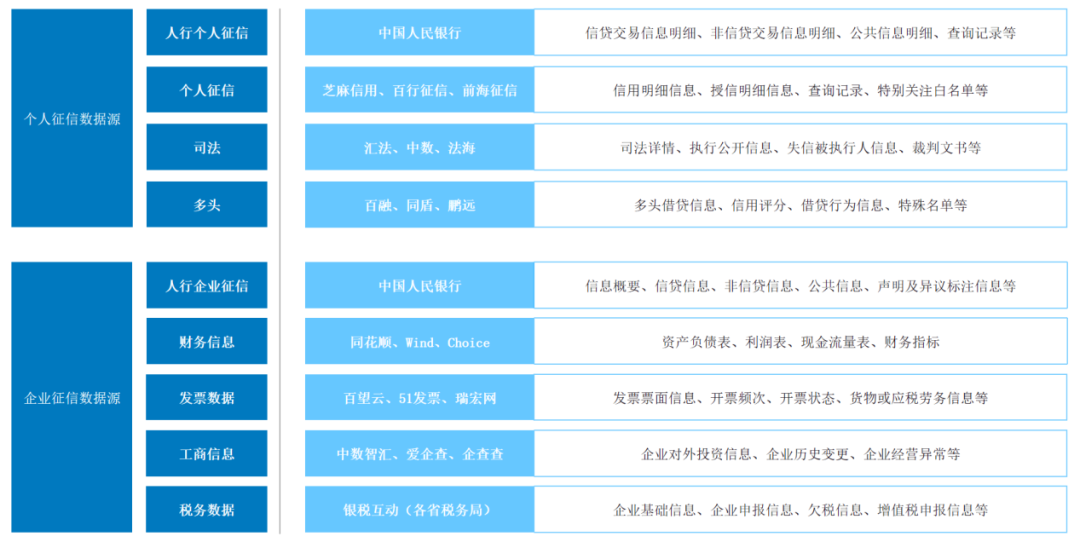
Taking the credit business data source as an example, according to different credit entities, it can usually be divided into To C personal credit and To B corporate credit. In actual business reviews, account managers usually analyze the feasibility of customer credit based on two indicators: cash flow level and debt level.
In the personal credit scenario, customer cash flow levels can be broken down into social security payment, bank and third-party payment platform income flow. The liability level mainly comes from the People's Bank of China credit report, which covers all loans issued by financial institutions under an individual's name, financial products occupying risk exposures and external guarantee information. In addition to the People's Bank of China, the credit report data sources include other third-party individual licensed credit reports. Credit agencies, such as Baihang Credit Information, Pudao Credit Information and Qiantang Credit Information.
In the corporate credit scenario, the risk sources of small and micro inclusive loans are concentrated in the actual controller. In addition to the actual controller's personal flow, the cash flow level is collected simultaneously from the corporate account flow, and the liability level is additionally accessed from the People's Bank of China's corporate credit report. . Under the credit extension of medium and large enterprises and industry-specific loans, the risk behavior events of the main entities are difficult to directly measure based on credit tax data. Different from the inclusive loans for small and micro enterprises, further offline due diligence needs to be combined with the company's on-site inventory and the operating conditions of affiliated enterprises.
For the above two types of credit businesses, feature processing often collects the following multi-dimensional data sources:
03 Data processing
For data sources in different risk control scenarios, feature variable processing methods that integrate batch, stream, pre-calculation and other modes are used to achieve agile development of business needs and storage and calculation cost control.
Batch computing: For large-scale historical data sets, batch processing is used to process feature variables. Problems such as missing values and outliers in the data are processed using methods such as interpolation and smoothing to ensure data quality.
Stream computing: For real-time data streams, stream processing mode is used for feature variable processing. Through real-time stream processing technology , real-time analysis of data is realized to meet the real-time requirements of risk control scenarios. At the same time, an event-driven architecture is adopted to ensure the efficiency and flexibility of data processing.
Precomputation: For business system data, precalculate and store feature variables according to their frequency of change, which can effectively reduce flow calculation costs and improve the efficiency of the decision-making system in fetching data from the feature engine.
04 Platform construction
Specifically, the characteristic variable platform needs to integrate data from multiple sources such as credit reporting systems, third-party data sources, and internal corporate systems, and perform derivative processing of batching capabilities, so as to support the input requirements of risk control models in different business scenarios. Supports configurable, business-led low-code processing methods for feature variables of different complexity. Therefore, the construction of feature variable platform usually includes the following aspects:
1. Feature variable extraction and generation, automated data cleaning and preprocessing, convert raw data into features that can be used for modeling. Provides a canvas + component-based one-stop WEB IDE model to improve development efficiency and supports user-defined or system-built-in feature calculation logic.
2. Feature variable storage and management
Based on a distributed storage mechanism , it stores large-scale historical and real-time characteristic data. Implement feature version control, record the change history of feature calculation logic, and ensure that model training can be traced back to a specific version of data.
3. Servitization of characteristic variables
Provides a feature service interface to provide real-time or batch feature query services for various model training, prediction and decision-making engines. Through the output component, you can quickly connect to downstream rule engines, real-time data warehouses, and message queues to meet the performance requirements for low latency and high concurrent access in complex business scenarios.
4. Exploration and analysis of characteristic variables
Provides a wealth of statistical analysis tools to help analysts quickly understand feature variable distribution, correlation relationships, etc. The visual interface displays feature importance, influence and other indicators to assist feature selection and iteration.
5. Integration with internal and external systems
Integrate multiple data sources such as financial institutions’ internal trading systems, CRM systems, and ERP systems. Supports connection with other risk control components (such as rule engines, model libraries, etc.) and third-party data service providers such as external credit reporting.
05 Construction income
In the implementation of a bank's customer characteristic variable project, the platform serves the processing and derivative management needs of characteristic variables in pre-lending credit scenarios, and connects with diversified upstream data sources, such as external operators, industrial and commercial, and judicial data; and the bank's internal customer equipment Information, account transaction information; asset valuation and limit calculation data collected before lending. Through real-time feature variable calculation capabilities , it can apply to downstream models such as scorecards to provide data.
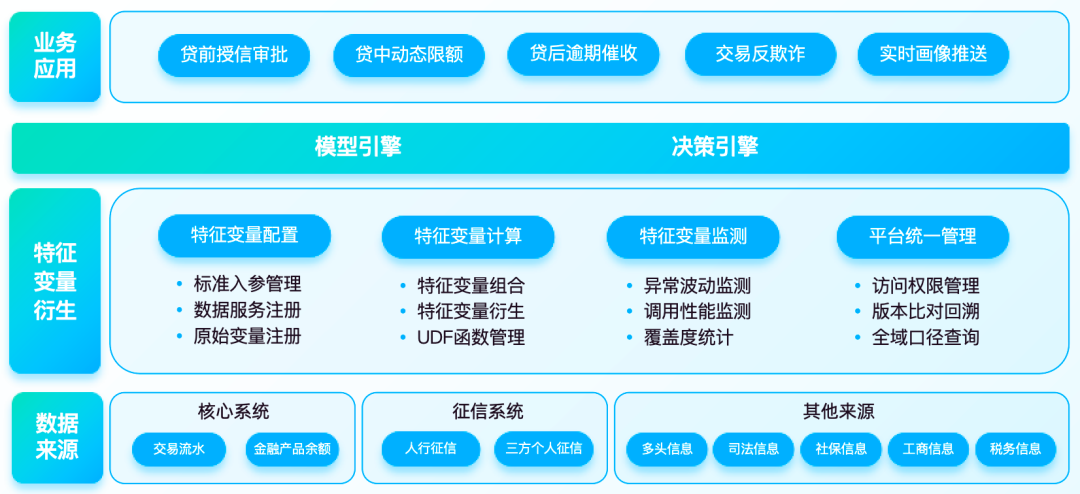
1. Component-based extraction of feature variables
The platform parses feature variables in batches from SQL commands. For the data acquisition requirements of model tasks, users can freely process and combine the required feature variables on the platform and write them into the corresponding theme hive table for reading and processing.
2. Synchronous update of feature variable sets
The page supports adding, deleting, and editing feature variable sets, and platform table structure operations are automatically synchronized to the physical model table. When the logic of feature variables changes, you only need to edit the corresponding standard feature variable derivative code or the original feature variable standardization operation to avoid complex development of large SQL functions.
3. Stability and abnormality monitoring
The monitoring dashboard function provided by the platform supports the monitoring of the fluctuation of characteristic variables and the calling of variable sets. The monitoring of characteristic variable values ensures that when the upstream data is abnormal, the downstream tasks are stopped in time, thus maximizing the possibility of avoiding problems caused by excessive differences in characteristic variables when the model is used. Distortion of model results; statistics on the call status of each variable set, and real-time push of baseline alarms and strong and weak rule verification information.
4. Unified platform management and control
The platform provides member management, approval center, call analysis, automatic archiving, task restart and other management and control methods, supports task priority adjustment, and uniformly schedules task operations to improve data service performance and cluster resource utilization.
The platform was deployed online, covering and supporting 30+ credit scenarios for consumer loans, small and micro credit loans and other businesses. By combining with the downstream rule model engine, the characteristic variable platform realizes the implementation of real-time decision-making capabilities in risk control scenarios, which satisfies the need to improve users' customer experience and loan efficiency in the credit card application and loan approval processes in pre-loan credit scenarios. In addition, It also provides data for post-loan collection, transaction anti-fraud and other scenarios, supporting downstream systems to monitor users’ abnormal transaction behaviors in real time, conduct anti-money laundering identity identification, and push real-time alarms.
"Dutstack Product White Paper" download address: https://www.dtstack.com/resources/1004?src=szsm
"Data Governance Industry Practice White Paper" download address: https://www.dtstack.com/resources/1001?src=szsm
For those who want to know or consult more about big data products, industry solutions, and customer cases, visit the Kangaroo Cloud official website: https://www.dtstack.com/?src=szkyzg
Linus took it upon himself to prevent kernel developers from replacing tabs with spaces. His father is one of the few leaders who can write code, his second son is the director of the open source technology department, and his youngest son is an open source core contributor. Robin Li: Natural language will become a new universal programming language. The open source model will fall further and further behind Huawei: It will take 1 year to fully migrate 5,000 commonly used mobile applications to Hongmeng. Java is the language most prone to third-party vulnerabilities. Rich text editor Quill 2.0 has been released with features, reliability and developers. The experience has been greatly improved. Ma Huateng and Zhou Hongyi shook hands to "eliminate grudges." Meta Llama 3 is officially released. Although the open source of Laoxiangji is not the code, the reasons behind it are very heart-warming. Google announced a large-scale restructuring