
As a distributed search engine, ES is unmatched in terms of expansion capabilities and search features. However, it has its own weaknesses. As a near-real-time storage system, its sharding and replication design principles also make it It cannot compete with OLTP (Online Transaction Processing) systems in terms of data latency and consistency.
Because of this, its data is usually synchronized from other storage systems for secondary filtering and analysis. This introduces a key node, that is, the synchronous writing method of ES data. This article introduces the MySQL synchronous ES method.
When writing MySQL data to ES, the first thing that comes to mind must be to consume Binlog and write directly to ES. This method is simple and clear. However, if you consider more dimensions, you will find some disadvantages of this method. Therefore, there is another way, that is,
[RocketMQ
+ Flink Consumer + ES Bulk] integrated ecology. We will evaluate these two access methods from four aspects: synchronization delay, consumption characteristics, ES write performance, and system disaster tolerance. We hope that Give everyone inspiration and choose the synchronization method that suits your business.
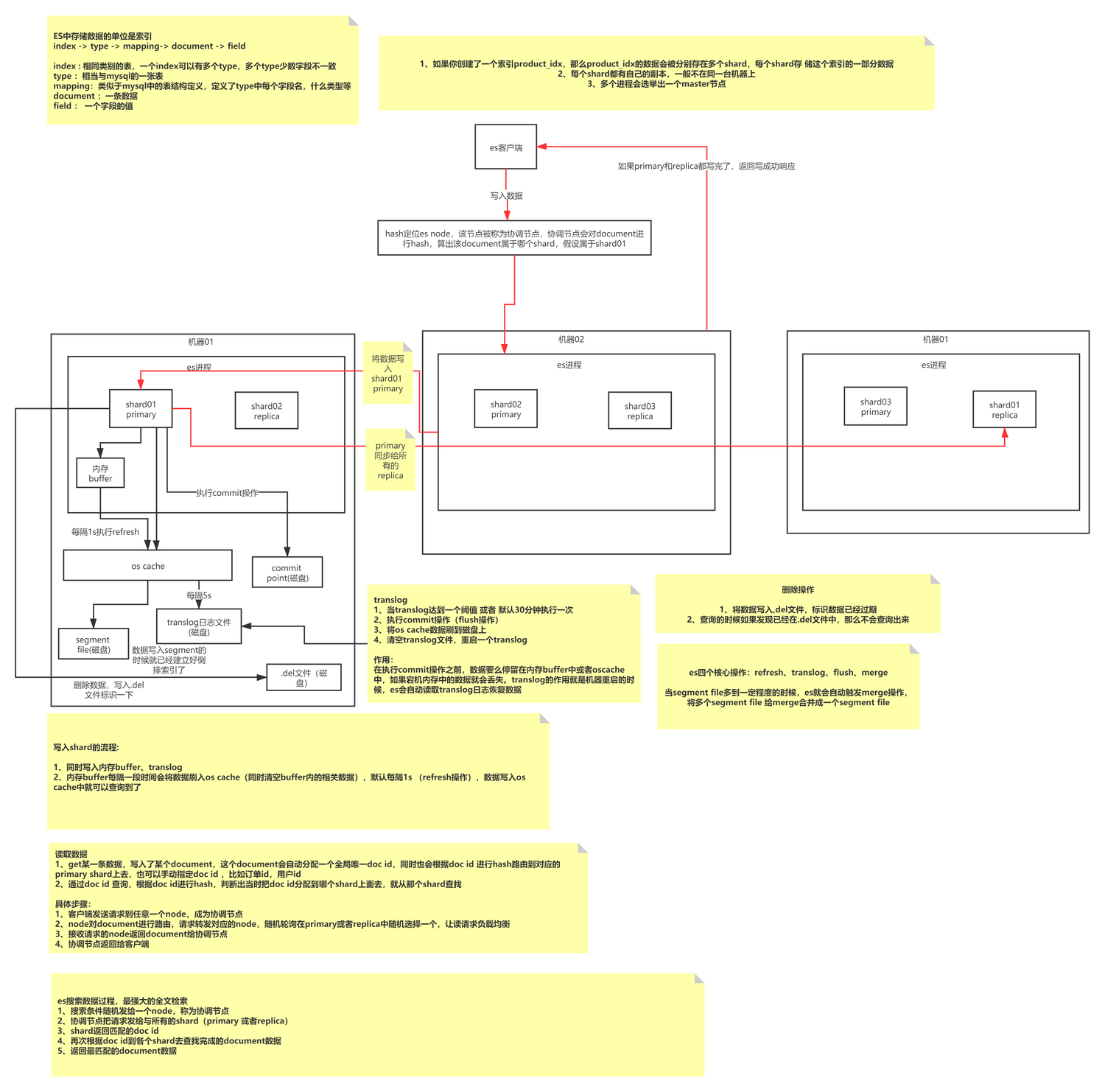
ES basic writing principles
ES writing is an append-type writing process that first forms segments of a specific size, and then periodically merges small data segments into large data segments to reduce memory fragmentation and improve query efficiency. An Index consists of N Shards and their copies. It stores Documents of the same Type. Its indexing method is defined by Mapping. Each Shard is composed of N Segments. Each Shard is a fully functional and complete Lucene index. , which is the smallest processing unit of ES; Segment is the smallest data processing unit of ES, and each Segment is an independent inverted index.
ES writing actually continuously writes data to the same Segment (memory), and then triggers Refresh to refresh the Segment to OS Cache (default 1s). At this time, the data can be queried, and OS Cache will trigger Flush by the operating system. Operations are persisted to disk.
Makes you think: How does ES ensure that data is not lost? What are the advantages and disadvantages of append writing? How does append writing handle data update issues? Which writing method does MySQL belong to? The focus of this article is not here, you can read the article separately.

ES basic concepts
ES direct write

The advantage of using ES direct-connect writing is that the path is short and there are few dependent components. In addition, Dsyncer (heterogeneous storage conversion system) usually provides a complete current limiting retry mechanism, so consumption delay and consumption data integrity are both Guaranteed.
shortcoming:
-
It is not easy to access multi-computer room disaster recovery deployment. Currently, ES disaster recovery computer rooms are all deployed independently and in independent read and write mode. Therefore, if this method is adopted, it will be difficult to control the writes of multiple computer rooms at the same time, and the disaster recovery effect will not be achieved. Binlog-->Dsyncer Usually one MySQL Table corresponds to one conversion task. If you start multiple repeated conversion tasks in order to write multiple computer rooms, it seems a bit stupid.
-
If your own business scenario involves concurrent writing of the same record, but the writes may not all come from Binlog, it is more likely to encounter write conflicts if you consider direct writing to ES globally because there is no guarantee of an ordered queue.
Build ES integrated system through Flink

Flink builds an ES integrated system, which means that all ES writes are completed by Flink tasks. Flink monitors RocketMQ real-time data streams, which not only ensures the orderliness of data partitions, but also makes full use of ES's batch writing capabilities. ES The batch writing capability is many times higher than the single writing performance. At the same time, due to the fault tolerance of Flink itself, the ultimate consistency of data can be guaranteed even in abnormal scenarios.
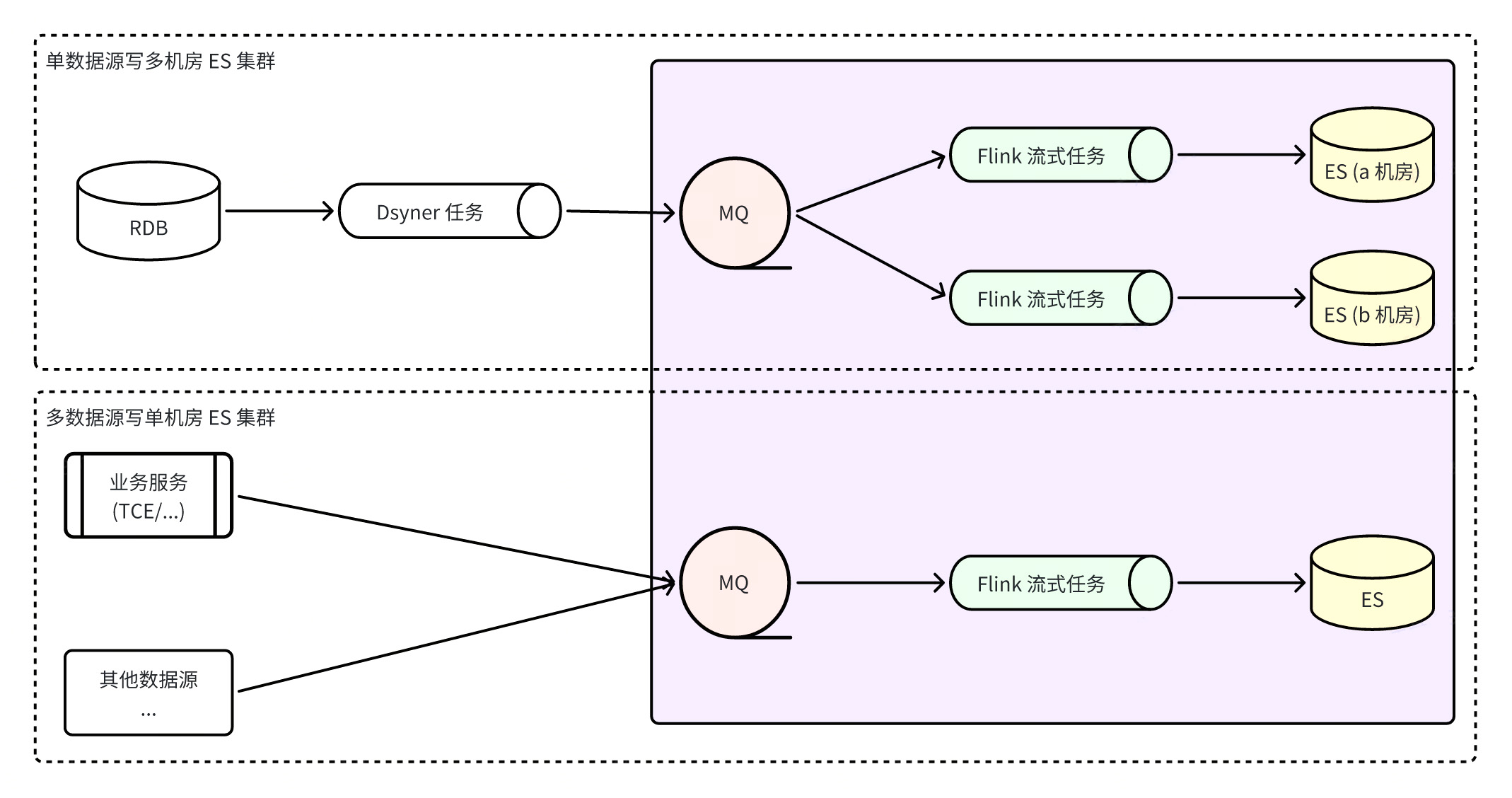
advantage
:
-
MQ can be used to access multi-machine room ES clusters more quickly, and writes are decoupled. Consumers in the three computer rooms write data independently from each other . When a single computer room fails, as long as there is an available computer room, the read traffic will be cut off directly. Yes, the disaster recovery plan is simple and clear ;
-
When problems such as network jitters cause ES to temporarily fail to write, RocketMQ will temporarily store the message without affecting the writing of other clusters, and Flink will save the consumption snapshot and keep retrying until success, which better guarantees the final consistency of the data. sex ;
-
Writing from multiple data sources can ensure global partition consistency.
shortcoming
:
-
Relying on more components will increase the data synchronization delay of the entire link, and the default refresh frequency of ES is once per second. After testing, the data delay of the link under normal circumstances is second-level, which is not completely unacceptable;
-
It relies on more components and has higher requirements for the stability of basic components. RocketMQ exceptions or Flink task exceptions will cause synchronization link problems and increase the risk of business exceptions.
One issue that needs attention here is that some people may consider connecting to a multi-machine room ES cluster. How to ensure that multiple computer rooms are successful at the same time, and how to ensure that the data can be queried after successful writing? At present, these two points cannot be achieved because multiple computer rooms write independently without affecting each other, and the ES cluster is a weak data consistency cluster, so there is no guarantee that successful writes can be found immediately.
Prerequisites for building and running an ES Flink consumer program :
-
Flink running environment : First of all, you need to have a running environment for Flink tasks. Usually, enterprise-level Flink tasks will be scheduled as a YARN job in the distributed system and allocate resources for execution, but at the same time, Flink can also be used as a stand-alone process, or to build an independent Cluster operation.
-
ES message format : It is necessary to agree on an ES message transmission format and serialization method. A set of paradigms can solve all synchronization scenarios. The currently popular serialization method is pb format or json format. Currently, we recommend the use of pb format. Data format Schema definition:
|
Field name
|
value type
|
Required/Optional
|
describe
|
|
_index
|
string
|
required
|
The name or alias of the document to be indexed
|
|
_type
|
string
|
Required/Optional
|
Document type
|
|
_on_type
|
string
|
required
|
Document write operation type
, value range:
index, create, update,
upsert
, delete
|
|
_id
|
string
|
Optional
|
Document ID
. If not specified, it will be
automatically generated
when written to ES . However, if the same data is repeatedly consumed and written to ES, multiple documents will be generated.
|
|
_routing
|
string
|
Optional
|
Document
routing
. If not specified, the _id field value routing will be used by default.
|
|
_version
|
int64
|
Optional
|
Document version
. When specified, it is greater than 0
and is only valid for index/delete operations . The
external_gte
version type is used by default.
|
|
_source
|
object
|
Required/Optional
|
Document content
, it does not need to be specified when the operation type is delete.
|
|
_script
|
object
|
Optional
|
Document script
, valid when the operation type is update/upsert, but cannot exist with _source at the same time
|
syntax = "proto3";
message ESIndexInfo {
string Name = 1; // 文档要写入索引的名称或别名
}
enum ESOPType { // 文档写入操作类型
DELETE = 0; // 删除文档
INDEX = 1; // 创建新文档或更新老文档,只能全量更新 (替换老文档)
UPDATE = 2; // 更新老文档,支持部分更新 (合并老文档)
UPSERT = 3; // 创建新文档或更新老文档,支持部分更新 (合并老文档)
CREATE = 4; // 创建新文档,存在时报错丢弃
}
message ESDocAction {
ESIndexInfo IndexInfo = 1; // 索引信息 (必需)
ESOPType OPType = 2; // 操作类型 (必需)
string ID = 3; // 文档 ID (可选)
string Doc = 4; // 文档内容 (JSON 格式, 删除操作时不需要)
int64 Version = 5; // 文档版本 (可选, 大于 0 且操作为 index/create/delete 有效)
string Routing = 6; // 文档路由 (可选, 非空有效)
string Script = 7; // 文档脚本 (JSON 格式, 操作类型为 update/upsert 有效,但和 Doc 不能同时存在)
}-
Necessary configuration for Flink tasks : monitored RocketMQ Topic information, writing ES cluster information;
-
Flink execution function : Flink processes streaming messages in two ways: streaming SQL and custom applications. Streaming SQL is subject to some limitations of its own, such as not supporting multiple index messages in the same MQ, while custom programming is more flexible. , such as adding various management, logs, error code processing, etc., this method is recommended;
-
Flink resource configuration : JobManager resource configuration, TaskManager resource configuration, etc.;
-
Flink custom parameter configuration : You can customize some dynamic configurations closely related to the application to facilitate dynamic adjustment of Flink consumption capabilities, such as:
|
parameter name
|
use
|
default value
|
|
job.writer.connector.bulk-flush.max-actions
|
The maximum number of documents in a single bulk, if it exceeds the number, a flush will be performed (that is, a bulk request of ES will be executed)
|
Default 300
|
|
job.writer.connector.bulk-flush.max-size
|
The maximum number of bytes in a single bulk, if it exceeds the limit, a flush will be performed (that is, a bulk request of ES will be executed)
|
Default10MB
|
|
job.writer.connector.bulk-flush.interval
|
The maximum interval between two bulks, if more than one flush (i.e. execute an ES bulk request)
|
Default 1000ms
|
|
job.writer.connector.global-rate-limit
|
Global write speed limit value
|
Default -1, no speed limit
|
|
job.writer.connector.failure-handler
|
Specify a custom failure handler, such as handling 4xx errors, 5xx errors in different ways, 429 always retrying infinitely, etc.;
|
|
|
global_parallelism_num
|
flink task global concurrency
|
rmq is queue/4, bmq/kafka is partition/3
|
|
max_parallelism_num
|
Maximum concurrency of flink tasks
|
The number of queue/partitions of mq
|
|
checkpoint_interval
|
The interval for creating Checkpoint, unit ms (5min=300000)
|
Default 15min
|
|
checkpoint_timeout
|
Timeout for creating Checkpoint, unit ms (5min=300000)
|
Default 10min
|
|
rebalance_enable
|
Enable out-of-order consumption
|
Default false
|
Comparison suggestions
|
Writing method
|
Sync delay
|
Write properties
|
ES write performance
|
consumer
|
Disaster tolerance
|
|
direct connection
|
Fewer dependent components and low latency
|
Binlog single key ordered
|
bulk write
|
FaaS
|
Poor
|
|
RocketMQ+Flink+ES
|
There are many dependent components and the delay is high/second level
|
Global single key order
|
bulk write
|
Considerable
|
good
|
After the above introduction, if the business can accept second-level delays, using RocketMQ+Flink can better achieve orderliness and disaster recovery capabilities. Flink is also far superior to FaaS in terms of streaming task processing capabilities, but directly The connection method obviously has simpler links, lighter architecture, and lower system integration and maintenance costs. Therefore, it is still necessary to choose the most suitable one based on the business characteristics.
Source Team|ByteDance E-commerce Business Platform
{{o.name}}
{{m.name}}