
Editor's note: When the author was trying to teach his mother to use LLM to complete work tasks, she realized that the optimization of prompt words was not as simple as imagined. Automatic optimization of prompt words is valuable for inexperienced prompt word writers who do not have enough experience to adjust and improve the prompt words provided to the model , which has triggered further exploration of automated prompt word optimization tools.
The author of this article analyzes the nature of prompt word engineering from two perspectives - it can be regarded as a part of hyperparameter optimization, or it can be regarded as a process of exploration, trial and error, and correction that requires constant attempts and adjustments.
The author believes that for tasks with relatively clear model input and output, such as solving mathematical problems, emotion classification, and generating SQL statements, etc. The author believes that prompt word engineering in this case is more like optimizing a "parameter", just like adjusting hyperparameters in machine learning. We can use automated methods to constantly try different prompt words to see which one works best. For tasks that are relatively subjective and vague, such as writing emails, poems, article summaries, etc. Because there is no black-and-white standard to judge whether the output is "correct", the optimization of prompt words cannot be carried out simply and mechanically.
The original article link: https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
LinkedIn profile link: https://linkedin.com/in/ianhojy
Medium profile link for subscriptions: https://ianhojy.medium.com/
Author | Ian Ho
Compiled | Yue Yang
Over the past few months, I've been trying to build various LLM-powered apps. To be honest, I spend a good portion of my time improving Prompt to get the output I want from LLM.
There were many times when I was stuck in emptiness and confusion, asking myself if I was just a glorified prompt engineer. Given the current state of human interaction with LLMs (Large Language Models), I still tend to conclude "not yet" and I'm able to overcome my imposter syndrome most nights. (Translator's Note: It is a psychological phenomenon that refers to individuals who are skeptical about their own achievements and abilities. They often feel that they are a liar, believe that they are not worthy of having or achieving the achievements they have achieved, and are worried about being exposed.) Currently We will not discuss this issue in depth for now.
But I still often wonder whether one day, the process of writing Prompt can be basically automated. How to answer this question depends on whether you can figure out the true nature of prompt engineering.
Although there are countless prompt engineering playbooks on the vast Internet, I still can't decide whether prompt engineering is an art or a science.
On the one hand, it feels like an art when I have to repeatedly learn and polish the prompts I write based on what I observe from the model output . Over time, I’ve discovered that little details matter — like using “must” instead of “should” or adding guidelines recommendations or specifications) at the end of the prompt word rather than in the middle. Depending on the task, there are so many ways that one can express a series of instructions and guidelines that sometimes it feels like a constant trial and error. and make mistakes.
On the other hand, one might think that prompt words are just hyper-parameters. Ultimately, LLM (Large Language Model) actually only treats the prompt words we write as embeddings, just like all hyperparameters. If we have a prepared and approved set of data for training and testing machine learning models, we can make adjustments to the prompt words and objectively evaluate their performance. Recently I saw a post by Moritz Laurer, ML engineer at HuggingFace[1]:
Every time you test a different prompt on your data, you become less sure if the LLM actually generalizes to unseen data… Using a separate validation split to tune the main hyperparameter of LLMs (the prompt) is just as important as train-val-test splitting for fine-tuning. The only difference is that you don’t have a training dataset anymore and it somehow feels different because there is no training / no parameter updates. Its easy to trick yourself into believing that an LLM performs well on your task, while you’ve actually overfit the prompt on your data. Every good “zeroshot” paper should clarify that they used a validation split for finding their prompt before final testing.
As we test more and more different prompt words (Prompts) on these data sets, we will become increasingly uncertain whether LLM can really generalize to unseen data... Isolate a part of the data set Set as the validation set to adjust the main hyperparameters (Prompt) of LLM and use the train-val-test splitting (Translator's Note: Divide the available data set into three parts: training set, validation set and test set.) method to proceed. Fine-tuning is just as important. The only difference is that this process does not involve training the model (no training) or updating the model parameters (no parameter updates), but only evaluating the performance of different prompt words on the validation set. It is easy to fool yourself into believing that the LLM performs well on the target task, when in fact the tuned cue words may perform very well on this current dataset, but may not perform well on a wider or unseen dataset. not applicable. Every good "zeroshot" paper should clearly state that they use a validation set to help find the best prompts before final testing.
After some thought, I think the answer is somewhere in between. Whether prompt engineering is a science or an art depends on what we want LLM to do. We've seen LLM do a lot of amazing things over the past year, but I tend to categorize people's intentions for using large models into two broad categories: solving problems and completing creative tasks ( creating).
On the problem-solving side , we have LLMs solving mathematical problems, classifying sentiments, generating SQL statements, translating text, and so on. Generally speaking, I think these tasks can all be grouped together, because they can have relatively clear input-output pairs (Translator's Note: The association between input data and corresponding model output data) (therefore, we can I have seen many cases where using only a small number of prompts can accomplish the target task very well). For this kind of task with well-defined training data (Translator's Note: The relationship between input and output in the training data set is clear and clear), prompt engineering seems more like a science to me. Therefore, the first half of this article will discuss Prompt as a hyperparameter , specifically exploring the research progress of automated prompt engineering (Translator's Note: Using automated methods or technologies to design, optimize and adjust prompt words).
In terms of creative tasks , the tasks required of LLM are more subjective and ambiguous. Write emails, reports, poems, abstracts. It’s here that we encounter more ambiguity – is the content of ChatGPT’s writing impersonal? (Based on the thousands of articles I've written about it, my current opinion is yes) And, since we often lack a more objective criterion for how we want LLMs to respond, the nature and demands of creative tasks often It is not appropriate to think of cue words as parameters that can be tuned and optimized like hyperparameters.
At this point, some might say that for creative tasks we just need to use common sense. To be honest, I used to think so too, until I tried to teach my mother how to use ChatGPT to help her generate work emails. In these cases, since prompt engineering is still mainly about improvement through continuous experimentation and adjustment rather than a one-time completion, how can you use your own ideas to improve Prompt and still retain the universality of Prompt? (as mentioned in the previous quote), is not always obvious.
Anyway, I looked around for a tool that could automatically improve prompts based on user feedback on large model generated examples, but found nothing. Therefore, I built a prototype of such a tool to explore whether a feasible solution existed. Later in this article, I’ll share with you a tool I experimented with that automatically improves prompt words based on real-time user feedback.
01 Part 1 - LLMs as Solvers: Treat Prompt Engineering as part of hyperparameter optimization
Many people in the industry are familiar with the famous "Zero-Shot-COT" terminology in the article "Large Language Models are Zero-Shot Reasoners" [2] (Translator's Note: The model has not learned explicit training data for a specific task. Next, solve new problems by combining existing knowledge). Zhou et al. (2022) decided to explore further in the article "Large Language Models are Human-Level Prompt Engineers" [3] What is its improved version? —— "Let's work this out in a step by step way to be sure we have the right answer". The following is an overview of the Automatic Prompt Engineer method they proposed:
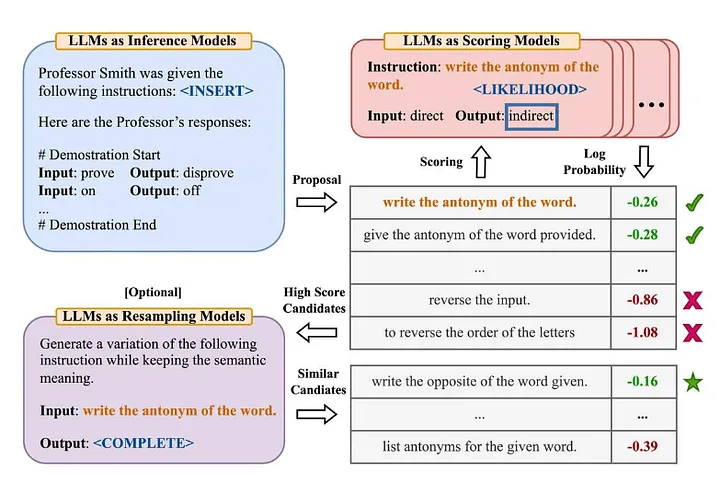
Source: Large Language Models are Human-Level Prompt Engineers[3]
To summarize this paper:
- Use LLM to generate candidate guidance prompts based on given input-output pairs (Translator's Note: The association between input data and corresponding model output data).
- Use LLM to score each instructional prompt, either based on how well the answer generated using the instruction matches the expected answer, or based on the model response obtained with the instruction. to evaluate the logarithmic probability.
- New candidate guidance prompt words are iteratively generated based on high-scoring candidate guidance prompt words (instructions).
Some interesting conclusions were discovered:
- In addition to demonstrating the superior performance of (human prompt engineers) and previously proposed algorithms, the authors note: “Counterintuitively, adding examples in context hurts model performance…because all The selected instruction words overfit the zero-shot learning scenario and therefore perform poorly in the case of small samples (few-shot) . "
- The effect of the iterative Monte Carlo Search algorithm (Monte Carlo Search) will gradually weaken in most cases, but when the original proposal space (Translator's Note: May refer to the Monte Carlo Search algorithm, initially used to generate candidates It performs well when the initial scope or solution of the problem is not suitable or effective enough.
Then in 2023, some researchers at Google DeepMind launched a method called "Optimisation by Prompting (OPRO)". Similar to the previous example, the meta-prompt contains a series of input/output pairs (Translator's Note: The input and expectations that describe a specific task or problem output combination). The key difference here is that the meta-prompt also contains previously trained prompt word samples and their correct answers or solutions and how accurately the model answered these prompt words, as well as detailing the differences between the different parts of the meta-prompt Guidance words for relationships.
As the authors explain, each cue word optimization step in the research work generates new cue words, aiming to reference previous learning trajectories so that the model can better understand the current task and produce more accurate output results.
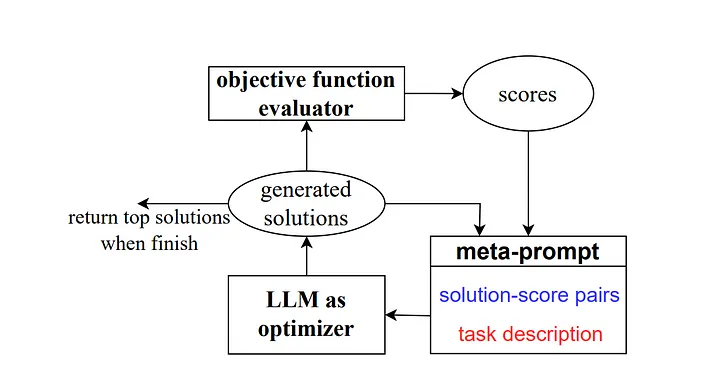
Source: Large Language Models as Optimizers[4]
For the Zero-Shot-COT scenario, they proposed the prompt word optimization method "Take a deep breath and work on this problem step-by-step" and achieved good results.
I have a few thoughts on this:
- “The styles of instructional prompts generated by different types of language models vary greatly. Some models, such as PaLM 2-L-IT and text-bison, generate very concise and clear instructional prompts, while others such as GPT’s The instructions are lengthy and quite detailed. "This deserves our attention. Currently, many prompt engineering methods on the market are written using OpenAI's language model as a reference object. However, as more and more models from different sources begin to be used, we should pay attention to these common prompt words. Engineering guidelines may not work that well. An example is given in Section 5.2.3 of the paper, which demonstrates the high sensitivity of model performance to small changes in instructions. We need to pay more attention to this.
For example, when using PaLM 2-L to evaluate the model on the GSM8K test set, the accuracy of "Let's think step by step." reached 71.8%, and the accuracy of "Let's solve the problem together." was 60.5%, while the first two The semantic combination of instruction words, "Let's work together to solve this problem step by step." has an accuracy of only 49.4%.
This behavior increases both the variation between single-step instructions and the fluctuations that occur during the optimization process, prompting us to generate multiple single-step instructions at each step. instructions) to improve the stability of the optimization process.
Another important point is mentioned in the conclusion of the paper: "One limitation of our current application of algorithms to real-world problems is that the large language models used to optimize cue words do not effectively exploit the erroneous cases in the training set to infer promising In the experiment, we tried to add error cases that occurred when the model was trained or tested in the meta-prompt, instead of randomly sampling from the training set in each optimization step, but the results were similar, which showed that only The amount of information in these error cases is not enough for the optimizer LLM (a large language model used to optimize prompt words) to understand the reasons for the incorrect predictions. "This is indeed worth emphasizing, because although these methods provide strong evidence of the optimization process of prompt words. Similar to the hyperparameter optimization process in traditional ML/AI, but we tend to prefer using positive, positive examples, whether it is what kind of content input we want to provide to LLM, or how we guide LLM to improve the prompt words. However, in traditional ML/AI, this preference is usually not so obvious, and we focus more on how to use the information about the error to optimize the model, rather than paying too much attention to the direction or type of the error itself (i.e. we focus on -5 and +5 errors are mostly treated equally).
If you are interested in APE (Automated Prompt Engineering), you can go to https://github.com/keirp/automatic_prompt_engineer to download and use it.
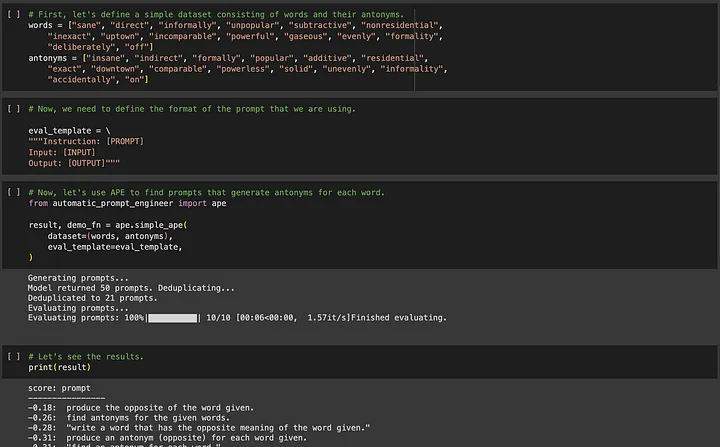
Source: Screenshot from Example Notebook for APE[5]
A key requirement in both methods, APE and OPRO, is that there needs to be training data to help optimize, and the data set needs to be large enough to ensure the universality of the optimized cue words.
Now, I want to talk about another type of LLM task where we may not have readily available data.
02 Part 2 - LLMs as Creators: Think of Prompt Engineering as a process of incremental improvement by constantly trying and adjusting
Suppose we were now to come up with some short stories.
We simply don’t have novel text examples to train the model on, and it would take too long to write some qualified novel text examples. Furthermore, it's not clear to me whether it makes sense to have a large model output a "so-called correct" answer, since there may be many types of model outputs that are acceptable. Therefore, for this type of task, it is almost impractical to use methods such as APE to automate prompt word engineering.
However, some readers may wonder, why do we even need to automate the process of writing prompt words? You can start with any simple prompt word, such as "provide me with 3 short story ideas about {{issue}} in {{country}}", fill {{issue}} with "inequality", replace {{country}} with "Singapore", and observe the model Respond to the results, discover problems, adjust the prompt words, and then observe whether the adjustment is effective, and repeat this process.
But in this case, who stands to benefit most from cue word engineering? It is precisely those beginners who are not experienced in writing prompt words. They do not have enough experience to adjust and improve the prompt words provided to the model . I experienced this firsthand when I taught my mother to use ChatGPT to complete work tasks.
My mom may not be very good at channeling her dissatisfaction with ChatGPT's output into further improvements to prompt words, but I've realized that no matter how good our prompt word engineering skills are, what we're really good at is articulating the problems we see ( i.e. the ability to complain). Therefore, I tried to build a tool to help users express their complaints and let LLM improve the prompt words for us. To me, this seems like a more natural way of interacting, and seems to make it easier for those of us trying to use LLM for creative tasks.
It should be stated in advance that this is just a proof-of-concept, so if readers have any good ideas, feel free to share them with the author!
First, write the prompt word with {{}} variables. The tool will detect these placeholders for us to fill in later, again using the example above, asking the large model to output some creative stories about inequality in Singapore.
Next, the tool generates a model response based on the filled-in prompt words.

Then give our feedback (complaints about the model output):
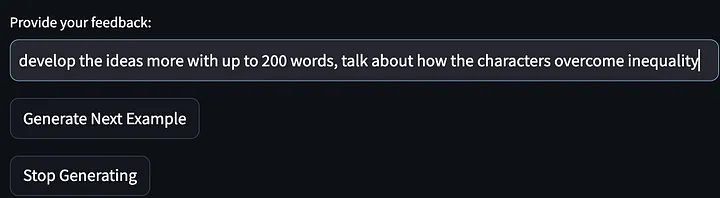
The model was then asked to stop generating further examples of story ideas and output cue words that improved from the first iteration. Please note that the prompts given below have been refined and generalized to require "describe the strategies…to overcome or engage with these challenges." And my feedback on the first model output was "talk about how the protagonist of the story solves inequality."

We then asked the large model to conceive of the short story again, using the modified prompt words.
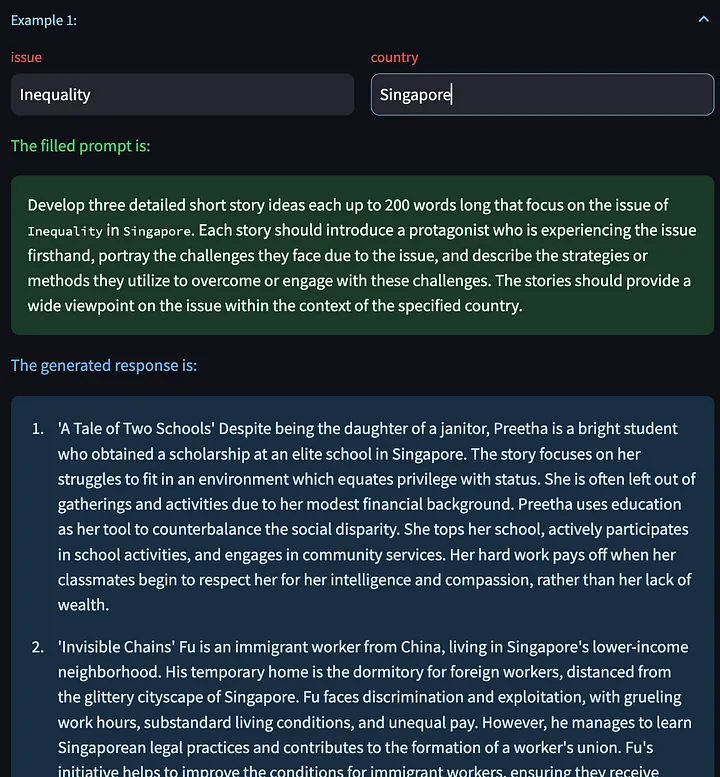
We also have the option to click "Generate Next Example", which allows us to generate a new model response based on other input variables. Here are some generated creative stories about the layoff problem in China:
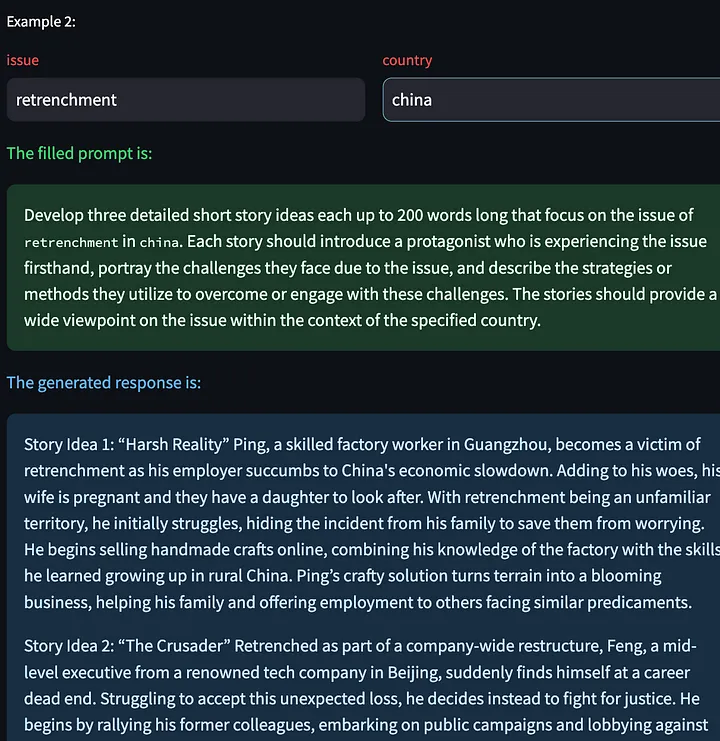
Then give feedback on the above model output:
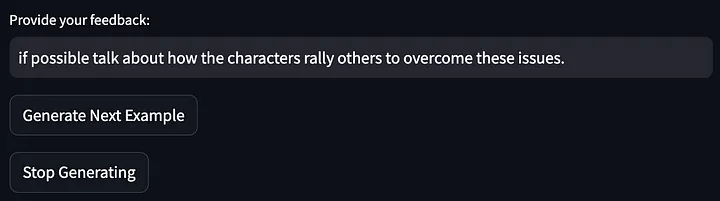
Then, the prompt words were further optimized:

The optimization results this time look pretty good. After all, it was just a simple prompt word at first. After less than two minutes of (albeit somewhat casual) feedback, the optimized prompt word was obtained after three iterations. Now, we can continue to optimize the prompt words by simply sitting down and expressing dissatisfaction with the LLM output.
The internal implementation of this function is to start from meta-prompt and continuously optimize and generate new prompt words based on the user's dynamic feedback. It's nothing fancy, and there's definitely room for further improvement, but it's a good start.
prompt_improvement_prompt = """
# Context #
You are given an original prompt.
The original prompt was used to generate some example responses. For each response, feedback was provided on how to improve the desired response.
Your task is to review all the feedback and then return an improved prompt that addresses the feedback, making it better at generating responses when prompted against the GPT language model.
# Guidelines #
- The original prompt will contain placeholders within double curly brackets. These are values for input that you will see in the examples.
- The improved prompt should not exceed 200 words
- Just return the improved prompt and nothing else before and after. Remember to include the same placeholders with double curly brackets.
- When generating the improved prompt, refrain from writing the entire prompt as one paragraph. Instead, you should use a combination of task descriptions, guidelines (in point form), and other sections to the prompt as appropriate.
- The guidelines should be in point form, and should not be a repetition of the task. The guidelines should also be distinct from one another.
- The improved prompt should be written in normal English that is best understood by the language model.
- Based on the feedback provided, you must rephrase the desired behavior of the response into `must`, imperative statements, instead of `should` suggestive statements.
- Improvements made to the prompt should not be overly specific to one single example.
# Details #
The original prompt is:
```
{original_prompt}
```
These are the examples that were provided and the feedback for each:
```
{examples}
```
The improved prompt is:
```
"""
Some observations while using this tool:
- GPT4 tends to use a large number of words when generating text (the "polyglot" feature). For this reason, there may be two effects. First, this "verbose" property may encourage overfitting to specific examples . ** If LLM is given too many words, it will use them to correct specific feedback given by the user. Secondly, this "verbal" characteristic may damage the effectiveness of prompt words, especially in lengthy prompt words, some important guiding information may be obscured. I think the first problem can be solved by writing good meta-prompts to encourage the model to generalize based on user feedback. But the second problem is more difficult. In other use cases, instructive prompts are often ignored when the prompt word is too long. We can add some restrictions in the meta-prompt (such as limiting the number of words in the prompt example provided above) , but this is really arbitrary, and some restrictions or rules in the prompt words may be affected by the underlying large model. The impact of a specific attribute or behavior.
- Improved prompt words sometimes forget previous optimizations to the prompt word. One way to solve this problem is to provide the system with a longer improvement history, but doing so causes the improvement prompt words to become too lengthy.
- One advantage of this approach in the first iteration is that the LLM may provide guidance for improvements that are not part of user feedback. For example, in the first word optimization above, the tool added “Provide a broader perspective on the discussed issue…” even though I provided Feedback is simply a request for relevant statistics from reliable sources.
I haven't deployed this tool yet because I'm still working on the meta-prompt to see what works best and work around some of the streamlit framework issues and then handle other errors or exceptions that may arise in the program. But the tool should be live soon!
03 In Conclusion
The entire field of prompt engineering focuses on providing the best prompt words for solving tasks. APE and OPRO are the most important and outstanding examples in this field, but they do not represent all. We are excited and looking forward to how much progress we can make in this field in the future. Evaluating the effects of these techniques on different models can reveal the working tendencies or working characteristics of these models, and can also help us understand which meta-prompt techniques are effective. Therefore, I think these are very important tasks that will help We use LLM in our daily production practice.
However, these methods may not be suitable for others who wish to use LLM for creative tasks. For now, there are many existing learning manuals that can get us started, but nothing beats trial and error. Therefore, in the short term, I think the most valuable thing is how we can efficiently complete this experimental process that is in line with our human strengths (giving feedback), and let LLM do the rest (improving the prompt words).
I will also work more on my POC (Proof of Concept). If you are interested in this, please contact me ( https://www.linkedin.com/in/ianhojy/) !
Thanks for reading!
END
References
[1]https://www.linkedin.com/in/moritz-laurer/?originalSubdomain=de
[2]https://arxiv.org/pdf/2205.11916.pdf
[3]https://arxiv.org/pdf/2211.01910.pdf
[4]https://arxiv.org/pdf/2309.03409.pdf
[5]https://github.com/keirp/automatic_prompt_engineer
[6]https://arxiv.org/abs/2104.08691
[7]https://medium.com/mantisnlp/automatic-prompt-engineering-part-i-main-concepts-73f94846cacb
[8]https://www.promptingguide.ai/techniques/ape
This article was compiled by Baihai IDP with the authorization of the original author. If you need to reprint the translation, please contact us for authorization.
Original link:
https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
I decided to give up on open source Hongmeng. Wang Chenglu, the father of open source Hongmeng: Open source Hongmeng is the only architectural innovation industrial software event in the field of basic software in China - OGG 1.0 is released, Huawei contributes all source code Google Reader is killed by the "code shit mountain" Fedora Linux 40 is officially released Former Microsoft developer: Windows 11 performance is "ridiculously bad" Ma Huateng and Zhou Hongyi shake hands to "eliminate grudges" Well-known game companies have issued new regulations: employee wedding gifts must not exceed 100,000 yuan Ubuntu 24.04 LTS officially released Pinduoduo was sentenced for unfair competition Compensation of 5 million yuan