
Author: Yue Yang, Chen Dequan, Liu Jingna
Beijing Yushi Technology Co., Ltd. was established in June 2023. Yushi Technology is positioned as "the theme entrance in the era of intelligent investment". In the era of change when the asset management industry shifts from institution-centered to user-centered, it builds a thematic investment engine , empowering inclusive investment integration, and creating a "new bridge" with investors and asset management institutions as the theme and core, and natural language interaction as the entrance.

Yushi Technology processes an average of 10,000 pieces of financial information every day. By collecting information, discovering emerging trends, and judging trend turning points, it has formed a theme investment system that includes 10+ super themes, 40+ investment themes, and 200+ sub-themes; currently 10 An industry benchmark customer, providing services through data API and weekly and monthly reports. At present, a total of about 500 reports and nearly 1,000 public account analysis articles have been issued. In the future, we will realize a thematic investment agent for thousands of people through real-time mining of user intentions and theme calculations.
Platform features and challenges encountered
Yushi Technology's products are typical information service products. After the platform collects financial industry information through multiple channels and stores it locally, it starts relevant processes for processing according to the investment analysis framework, and finally forms financial data products to provide external services. The platform business functions and requirements for system resources have the following characteristics:
1. Large amount of data and diverse storage requirements
a) The core data of the platform is mainly unstructured data. The total amount of data in each processing stage including source data, intermediate data and result data is at the TB level. Although this magnitude is a piece of cake for file or object storage, However, there is still a certain pressure on analysis/index storage.
b) Unstructured data storage requires multiple access interface support when facing different processing processes, including files, objects, OLAP databases, cache and index systems, etc.
c) The processing of financial information needs to meet timeliness requirements, so there are also high requirements for the query performance of analytical storage systems.
2. The data processing process is complex and changeable
a) The data processing process is the embodiment of the investment analysis strategy in the system and is the core of the entire platform. The key node processing logic in these processes cannot be implemented through standardized platform functions. It needs to be published to the platform through Java/Python code and can be flexibly called by the process.
b) In order to realize business logic requirements, there are frequent data flow and interaction requirements between processing nodes in the processing process, between nodes and data storage interfaces, and even between processes.
c) Investment strategies need to be adjusted in a timely manner in response to market changes and customer needs. Data processing processes and even core processing logic need to be adjusted simultaneously according to business strategies.
d) Due to the complexity of data processing logic, after development goes online, it is often necessary to track and analyze the processing of specific data in the production environment, and it is necessary to be able to easily view detailed runtime information.
3. There are obvious peaks and valleys in platform resource demand.
a) There will be fixed peaks during the whole day operation of the platform, including the period when information is intensively inflowed and processed, and the period when business personnel are intensively querying. At the same time, there are also access peaks at the beginning of the week and the beginning of the month.
b) Peak periods require higher processing performance expansion ratios, and different peak types have different requirements for system resources. Pre-planning of expansion actions is required for different scenarios.
4. Reliability/timeliness requirements
a) Information will continue to be generated and flow into the platform 24 hours a day. It needs to be processed within a few minutes of entering the platform and enter the external service data pool. Therefore, the platform needs to be able to process stably and continuously, and automatically expand when encountering peak traffic to avoid data backlog. If there are omissions or errors in the processing process, it must be able to automatically retry.
b) External service-related systems serve as the access portal for end users and have certain requirements for service continuity.
In view of the above platform function design, Yushi Technology has the following requirements for IT infrastructure including IaaS/PaaS:
1. Diverse storage types, smooth mutual access between systems, supports multiple storage types, seamless mutual access between various storage systems, daily use, management and data transfer can be configured through the GUI.
2. Simple and flexible data processing process
a) Provide a unified processing flow management entrance and support graphical process design.
b) Supports the use of common development languages to implement complex business logic and can be seamlessly embedded into processes.
c) Between process nodes, process and data storage interface, complex interactive control can be realized between processes.
d) The runtime process can be tracked and analyzed, and specific data or processes can be easily tracked and analyzed.
3. System automatic expansion and contraction
a) The system capacity of the data processing process can be automatically expanded and contracted according to traffic peaks and valleys, and its expansion and contraction can be processed according to certain scripts based on inter-system dependencies.
b) Other business systems need to automatically adjust according to business access peaks and valleys.
4. Improve the overall quality and efficiency of R&D work
a) Reduce the direct cost of IT resources and management costs while ensuring system reliability; b) Improve the efficiency of the overall CI/CD process.
Cloud workflow CloudFlow + Function Compute FC helps complex data processing improve
Yushi Technology is a data technology company born under the wave of cloud native. At the beginning of its establishment, it decided to adopt cloud native technology to improve the overall quality and efficiency of IT work and optimize costs.
The challenges encountered in improving quality and efficiency mainly focus on data processing processes. Therefore, in addition to using regular CI/CD efficiency improvement tools such as Alibaba Cloud and containerized deployment, after team inspection, we finally chose cloud workflow CloudFlow and functions. Calculate FC Two new products. The goal is to solve the need to manage complex data processes through cloud workflow CloudFlow, and to use function computing FC to solve the problem of some nodes processing complex business logic during the operation of cloud workflow CloudFlow. At the same time, the processing capabilities can perfectly solve the need for elastic scaling.
The data flow diagram is as follows:
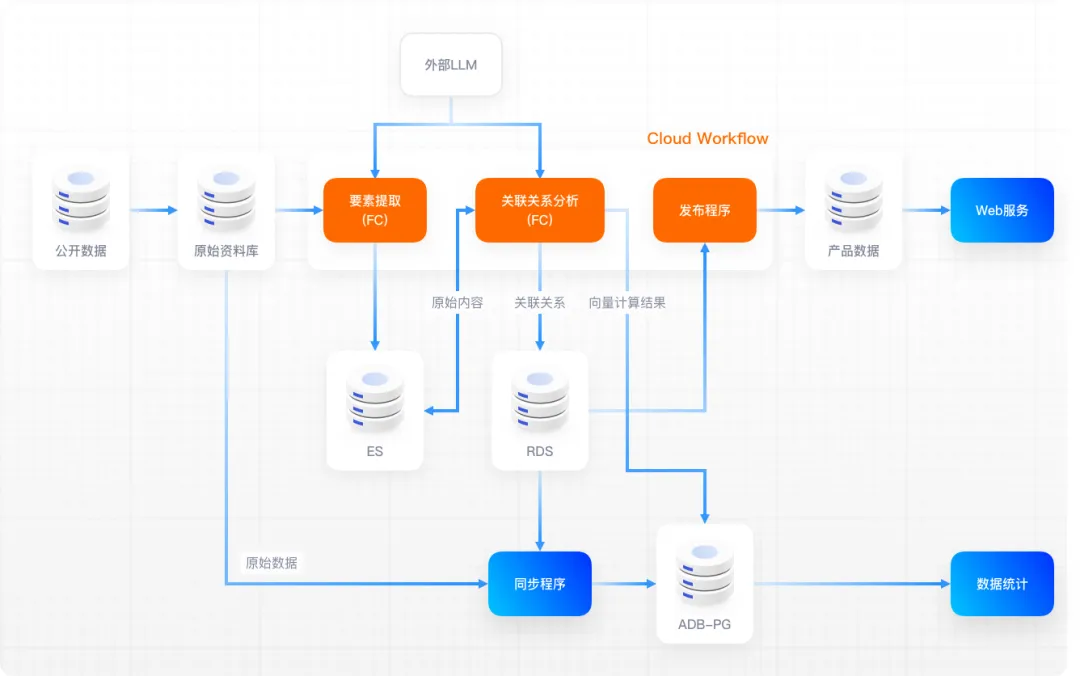
Through practice, it has been found that for common workflows, using CloudFlow to develop Web interfaces reduces the development workload by about half compared to using mainstream Java application frameworks. At the same time, since the online release link is omitted, the efficiency of online debugging has also been improved. , the usage efficiency of tracking and debugging based on the web console has also been greatly improved after a period of adaptation.
During the six months of use, Yushi Technology has developed nearly 20 workflows, which call dozens of functions and run hundreds of thousands of times. Although there is only one engineer responsible for the workflow, it is still possible to maintain an average of a new workflow being launched every two weeks or so. For engineers, except for the occasional need for online tracking and debugging, there is basically no need to care about the running status of the workflow after it goes online, truly achieving "release and forget about it".
Outlook
As a data-centered start-up in the era of big models, we will dig deeper into the possibility of combining data platforms with large model capabilities. Through the infrastructure innovation capabilities provided by Alibaba, we will provide our end customers with stronger capabilities and more iterations. Fast data products.
I decided to give up on open source industrial software. Major events - OGG 1.0 was released, Huawei contributed all source code. Ubuntu 24.04 LTS was officially released. Google Python Foundation team was laid off. Google Reader was killed by the "code shit mountain". Fedora Linux 40 was officially released. A well-known game company released New regulations: Employees’ wedding gifts must not exceed 100,000 yuan. China Unicom releases the world’s first Llama3 8B Chinese version of the open source model. Pinduoduo is sentenced to compensate 5 million yuan for unfair competition. Domestic cloud input method - only Huawei has no cloud data upload security issues