
01 Background at a glance
In the scenario where time series data is written to the database, due to problems such as network delays, it may happen that the timestamp of the data to be written is less than the maximum timestamp of the data that has been written. This type of data is collectively referred to as out-of-order data. The generation of out-of-order data is almost inevitable. At the same time, the writing of out-of-order data will affect the sorting and querying of all data. Therefore, we need to support the writing of out-of-order data and also support the out-of-order well. Efficient data query.
02 Process Overview
When processing out-of-order data, out-of-order data within a specified time window (such as 10 minutes or 1 hour) will be processed according to the deduplication strategy and stored, and out-of-order data outside the time window will be discarded. The following figure is the basic process of writing out-of-order data:

Among them, 3 key points need to be clarified:
- The time window refers to a period of time before the time point of the latest data timestamp in the table. When no new data is written to the table, its time window will not change.
- There is a parameter in the configuration file: ts_st_iot_disorder_interval, which is used to support the time window for writing out-of-order data, unit: seconds. The value of this configuration item cannot exceed the partition interval value.
- The basis for judging whether the data is out of order is that the timestamp of the written data is less than or equal to the maximum timestamp of all data stored in the written table object.
03 Scenario Example
1. Normal writing process
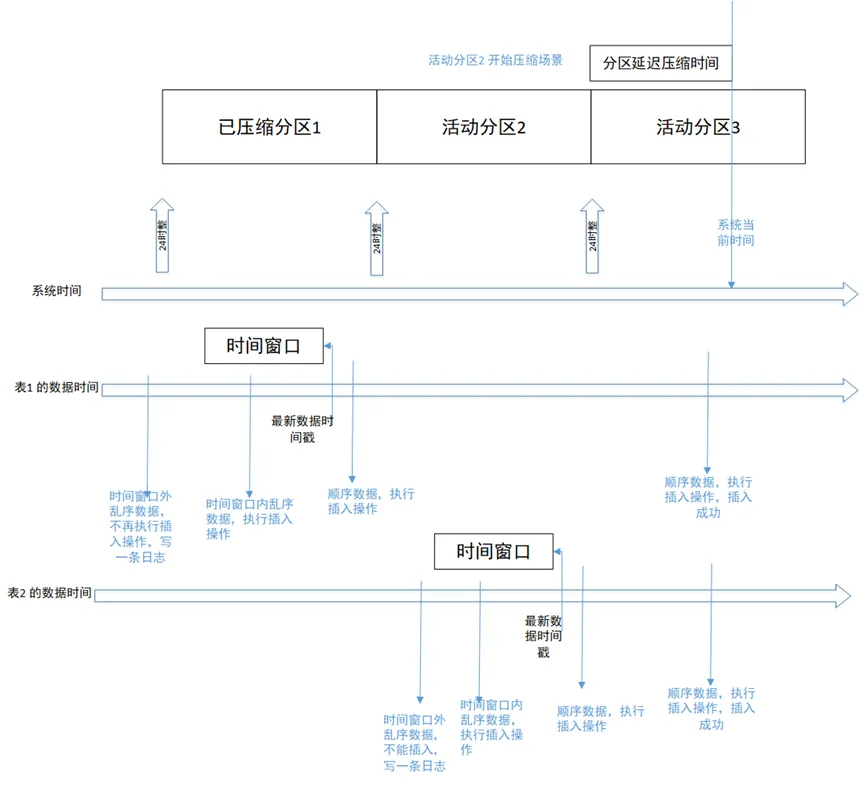
The time is divided into two lines: system time and data time. The data time is different for each table, so it is divided into two lines: the data time of Table 1 and the data time of Table 2.
-
Scenario 1: The scenario of sequential writing of data two days ago is as shown in the figure above. The scenario of Table 1 sequentially writing to historical partition 1. The written sequential data will be stored in the corresponding partition. The writing of the historical partition fails and throws wrong.
-
Scenario 2: Writing out-of-order data within the time window As shown in the figure above, Table 2 writes out-of-order data within the time window. The written data will be stored in active partition 2, which is being processed in another thread. Partition compression, write operations will also succeed.
-
Scenario 3: Writing out-of-order data that exceeds the time window. When the database turns on the compression function and configures the out-of-order time window to 1 hour, writing out-of-order data that is 1 hour earlier than the latest record timestamp in the table will fail. The written data will be filtered out and written to the log.
2. Import data process
There may also be out-of-order data in the imported data. In this scenario, the processing of out-of-order data is consistent with the normal writing process.
-
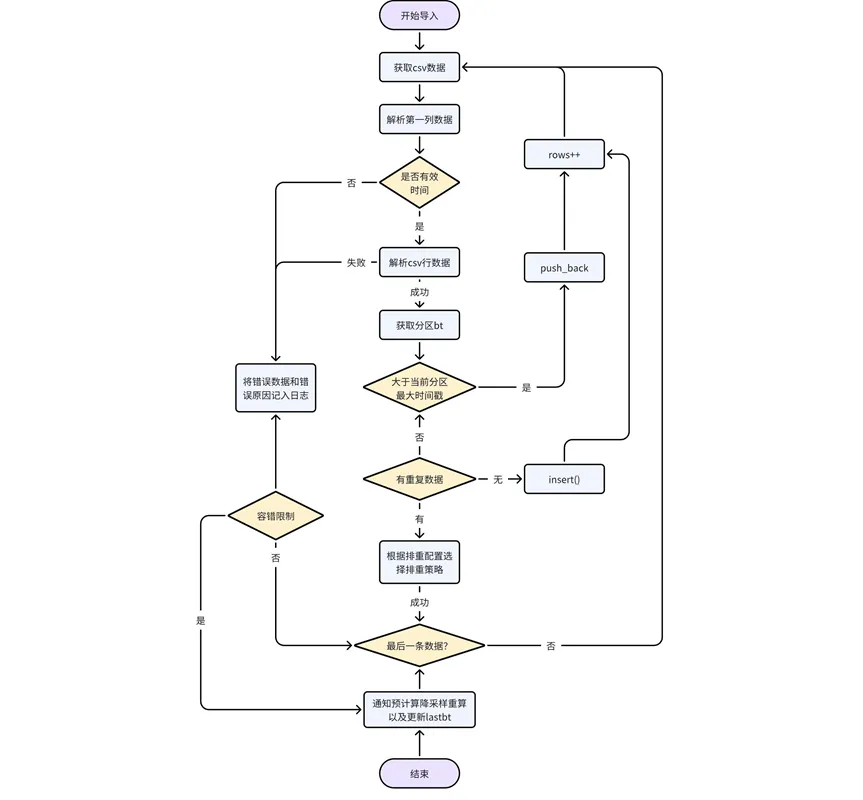
Processing of the data itself: parse the data in the CSV file line by line, determine whether the first column of data is a valid time/timestamp type, and return an error if not; if it is valid time data, determine the partition to which the data belongs, and obtain the partition bt. If the data timestamp is greater than the maximum timestamp of existing data in the current partition, push back directly; otherwise, the out-of-order data needs to be processed according to the deduplication configuration logic.
-
Adapt downsampling and precomputation logic: During the process of importing data, you need to update the record status of url in the kaiwudb_jobs system task table to expired; after the import is completed, notify precomputation/downsampling, recalculate/process the data involved, or wait for the next step. A precomputation task is recalculated when it is scheduled by the system.
After the import is completed, precalculation and downsampling are notified to recalculate or update the results, and update lastbt.
3. Downsampling process
After the out-of-order data is written, the downsampling results need to be updated based on the latest data.

-
Processing of out-of-order data imported into historical partitions: When importing out-of-order data belonging to historical partitions, update the record status of url=[database/partition/table_name] in the kaiwudb_jobs system task table to expired, and then the partition table will be re-downloaded accordingly. Sampling rule processing.
-
Process insert and write historical partition data: When decompressing the historical partition of the insert data table, update the record status of url=[database/partition/table_name] in the kaiwudb_jobs system task table to expired, and the partition table will be re-corresponded in the future. Processing of downsampling rules.
4. After the out-of-order data is written in the precomputation process, the precomputation results need to be updated based on the latest data.
-
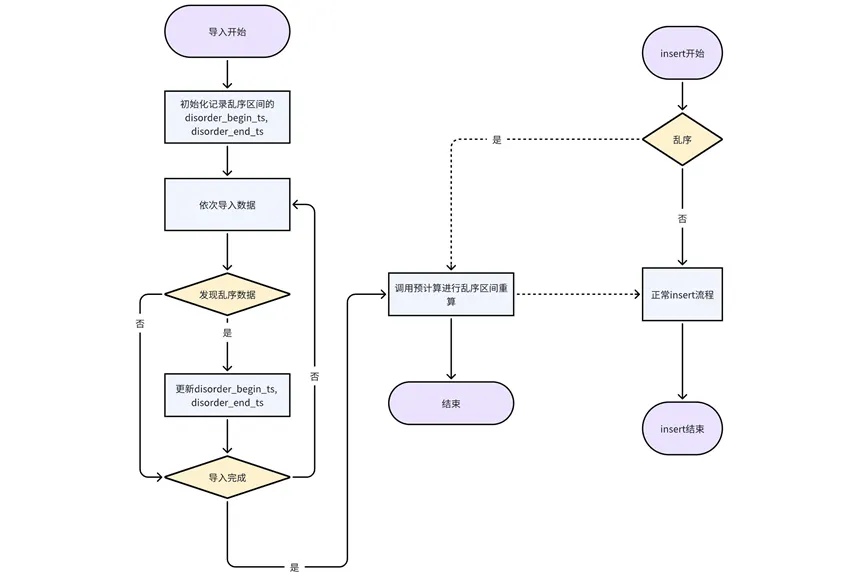
Process insert and write out-of-order data: insert every time a piece of out-of-order data appears in insert. This approach can ensure the accuracy of the precomputation results to a greater extent.
-
Processing of imported out-of-order data: The import is currently processed in units of partition tables. During the import process of each partition table, the out-of-order start timestamp and end timestamp are recorded. After the import of the current partition table is completed, the pre-computation interface is called for recalculation.
04 Summary
In the scenario of out-of-order data processing, there are many functions and linkage modules involved, which need to be synchronized and updated. When the database has complete out-of-order data processing, it can better adapt to user business scenarios and greatly improve the applicability of the database in multiple scenarios.
I decided to give up on open source industrial software. Major events - OGG 1.0 was released, Huawei contributed all source code. Ubuntu 24.04 LTS was officially released. Google Python Foundation team was laid off. Google Reader was killed by the "code shit mountain". Fedora Linux 40 was officially released. A well-known game company released New regulations: Employees’ wedding gifts must not exceed 100,000 yuan. China Unicom releases the world’s first Llama3 8B Chinese version of the open source model. Pinduoduo is sentenced to compensate 5 million yuan for unfair competition. Domestic cloud input method - only Huawei has no cloud data upload security issues