
write in front
This article mainly introduces the paper "Kepler: Robust Learning for Faster Parametric Query Optimization" published at SIGMOD in 2023. This article combines parameterized query optimization and query optimization for parameterized queries, aiming to reduce query planning time while improving query efficiency. performance.
To this end, the author proposes an end-to-end, deep learning-based parametric query optimization method called Kepler (K-plan Evolution for Parametric Query Optimization: Learned, Empirical, Robust).
Numerical query refers to a type of query that has the same SQL structure and only differs in the bound parameter values. As an example, consider the following query structure:
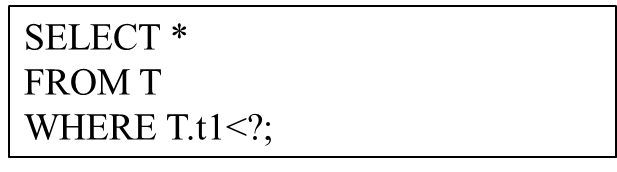
The query structure can be regarded as a template of a parameterized query, and the "?" represents different parameter values. The SQL statements executed by the user all have this query structure, but the actual parameter values may be different. This is a parameterized query. Such parameterized queries are used very frequently in modern databases. Because it continuously executes the same query template repeatedly, it brings opportunities to improve its query performance.
Parameterized query optimization (PQO) is used to optimize the performance of the above-mentioned parameterized queries. The goal is to reduce query planning time as much as possible while avoiding performance regression. Existing approaches rely too much on the system's built-in query optimizer, making them subject to the inherent suboptimality of the optimizer. The author believes that the ideal system for parameterized queries should not only reduce query planning time through PQO, but also improve the query execution performance of the system through query optimization (QO).
Query optimization (QO) is used to help a query find its optimal execution plan. Most of the existing methods for improving query optimization apply machine learning, such as machine learning-based cardinality/cost estimators. However, the current query optimization method based on learning has some shortcomings: (1) The inference time is too long; (2) The generalization ability is poor; (3) The improvement of performance is unclear; (4) It is not robust and the performance may decrease. return.
The above shortcomings pose challenges to learning-based methods, as they cannot guarantee the improvement in execution time of prediction results. To solve the above problems, the author proposes Kepler: an end-to-end learning-based parameterized query optimization method.
The authors decouple parametric query optimization into two problems: candidate plan generation and learning-based prediction structures. It is mainly divided into three steps: novel candidate plan generation, training data collection, and robust neural network model design. The combination of the three reduces query planning time while improving query execution performance, while meeting the goals of PQO and QO. Next, we first introduce the overall architecture of Kepler, and then explain the specific content of each module in detail.
Overall architecture
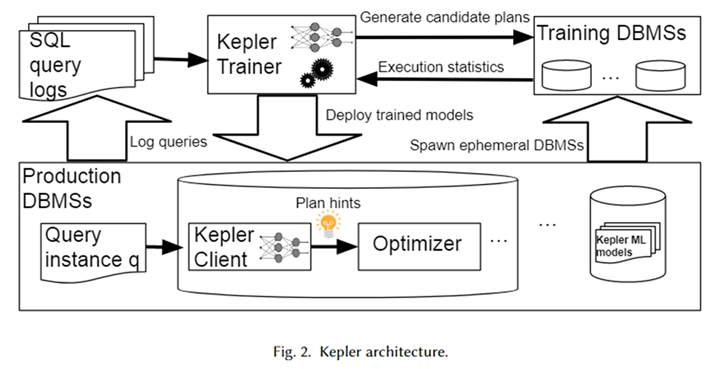
The overall architecture of Kepler is shown in the figure above. First, obtain the parameterized query template and the corresponding query instance (that is, the query with actual parameter values) from the database system log to form a workload. Kepler Trainer is used to train a neural network predictive model for this workload. It first generates candidate plans on the entire workload and executes them on a temporary database system to obtain the actual query execution time.
Use this query time to train a neural network model. After the training is completed, it is deployed in the database system in the production environment, called Kepler Client. When the user inputs a query instance, Kepler Client can predict the best execution plan for it and hand it over to the optimizer in the form of plan hint to generate and execute the best plan.
Candidate plan generation: Row Count Evolution
The goal of candidate plan generation is to construct a set of plans that contains a near-optimal execution plan for each query instance in the workload. In addition, it should be as small as possible to avoid excessive overhead in the subsequent training data collection process. The two constrain each other, and how to balance these two goals is a major challenge in candidate plan generation.
Equation 1 formulates specific plan generation goals. Among them, is a query instance on workload W, is the execution plan selected by the optimizer, is the optimal plan in the plan set under ideal circumstances, and ExecTime is the execution time of the corresponding plan on the instance. Therefore, the connotation of Equation 1 is the acceleration in execution time of the candidate plan set compared to the plan set generated by the optimizer over the entire workload. The algorithm is designed to maximize this speedup.
To this end, this paper proposes Row Count Evolution (RCE), an algorithm that generates new plans by randomly perturbing the optimizer cardinality estimate. It generates a series of plans for each query instance, combined into a set of candidate plans for the entire workload. The idea behind this algorithm is that incorrect estimation of the base is the main reason for the suboptimality of the optimizer. At the same time, the candidate plan generation stage does not need to find a specific single (near) optimal plan for each query instance, but only needs to include the (near) optimal plan.
The RCE algorithm continuously generates new plans through iteration. First, the initial iteration plan is the plan generated by the optimizer. To build subsequent iterations, uniform random sampling from the previous generation plan is first required. For each sampled plan, perturb (change) the cardinality of its join subplan.
The perturbation method is to randomly sample within the exponential interval of its current estimated cardinality. The perturbed cardinality is handed over to the optimizer to generate the corresponding optimal plan. Repeat each plan N times to generate many execution plans, among which execution plans that have not appeared are retained as the next generation plan, and the above process is repeated.
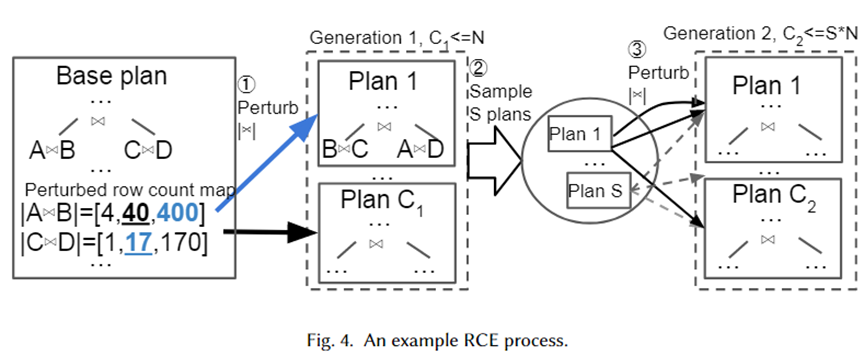
We give a specific example to visually illustrate the above algorithm, as shown in the figure below. First of all, Base Plan is the best plan selected by the optimizer. It has two join sub-plans, A join B and C join D. Their estimated bases are 40 and 17 respectively.
Next, perturbation sets are generated for the two join subplans from the exponential interval range 10-1~101, which are [4,40,400] and [1,17,170] respectively. Random samples are taken from the perturbation set and handed over to the optimizer for plan selection. Plan 1 is the new plan selected by the optimizer when cardinality is 400 and 17 respectively. Repeated N times, C1 plans are finally generated as the next generation. Next, sample S plans from them and repeat the above process for each plan to form the 2nd generation plan.
The reason why the authors adopted an exponential interval range as the perturbation set is to fit the distribution of the optimizer's cardinality estimation error. It can be seen from the above algorithm that as long as the number of perturbations is large enough, a lot of cardinality and its corresponding plans will be generated. In this way, when a query instance arrives, there should be a plan in our plan set that is close to the true cardinality, which can be regarded as the (near) optimal plan for the instance.
Training data collection
After generating the set of candidate plans, each plan is executed on the workload, and execution time data has been generated for supervised optimal plan prediction. Using actual execution data rather than the cost estimated by the optimizer can avoid the limitations caused by the suboptimality of the optimizer. The execution process is parallelizable. However, executing all the plans is a significant expense. Therefore, the authors propose two strategies to reduce the waste of resources caused by unnecessary suboptimal plan execution.
Adaptive timeouts and plan execution reordering, adaptive timeouts and plan execution reordering. The authors employ a timeout mechanism to limit the execution of suboptimal plans. For each query instance, when executing each plan, the current minimum execution time can be recorded.
Once the execution time of a plan exceeds a certain range of the minimum execution time, it can no longer be executed because it is definitely not the optimal execution plan. At the same time, the minimum execution time is constantly updated. In addition, executing query plans in ascending order of execution time based on the execution of each plan on other query instances can be used as a heuristic to speed up the timeout mechanism.
Online plan covering pruning, online plan set pruning. After all plans have been executed for the first N query instances, they are pruned into K plans using the Set Cover problem. Subsequent data collection and model training use these K plans. The Set Cover problem is defined as shown below.
In the context of this article, represents all query instances, which can be represented as different plans, each plan being a near-optimal plan for some query instance. Therefore, the problem can be formulated as using the smallest possible set of plans to provide near-optimality for all query instances. The problem is NP, so the author uses a greedy algorithm to solve it.

Robust best plan prediction
After collecting training data on the actual execution time of the candidate plan set, supervised machine learning is used to predict the best plan for any query instance. The training goal can be logically expressed by the following equation. where represents the best plan chosen by the model for the query instance. The meaning of this equation is the speedup resulting from the plan chosen by the model compared to the plan chosen by the optimizer. Its upper limit is Equation 1. In other words, the model should capture as much as possible the acceleration brought by the candidate plans generated by RCE.
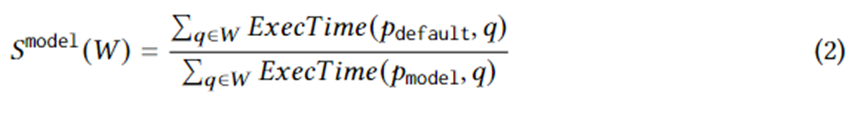
The structure of the model adopts a forward neural network and applies the latest progress in machine learning uncertainty, namely Spectral-normalized Neural Gaussian Processes (SNGPs). Combining it into the neural network can improve the convergence of the model and at the same time enable the neural network to output the uncertainty of prediction. When the uncertainty is higher than a threshold, the work of plan prediction is returned to the optimizer, which determines the best plan.
The model is characterized using the actual values of each parameter. In order to input the actual values of parameters into the neural network, some preprocessing is required, especially for string type data. For string type data, the author uses a fixed-size vocabulary and buckets that are not in the vocabulary to represent it as a one-hot vector, and adds an embedding layer to learn the embedding of the one-hot vector, and then be able to Handle string type data.
Experimental effect
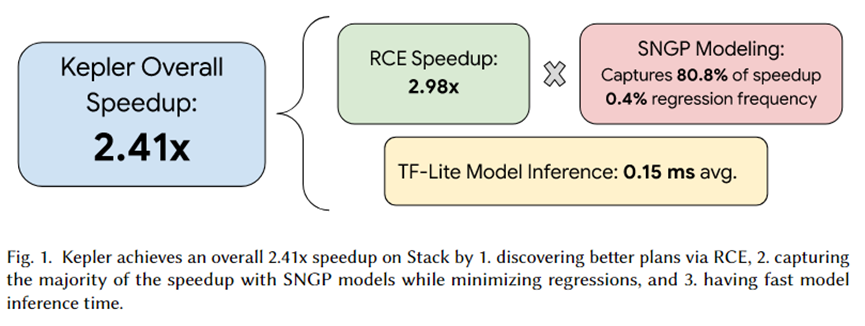
The author of this article integrated Kepler into PostgreSQL and organized a series of experiments. The summary of the experiment is shown in the figure above. The total acceleration effect brought by Kepler is 2.41 times. Among them, the candidate plan set generated by RCE can bring about 2.92 times acceleration, 80.8% is captured by the SNGP prediction model, and only 0.4% of the regression is achieved. Furthermore, the model’s inference time is only 0.15ms on average.
Summarize
This paper proposes Kepler, a learning-based approach that robustly accelerates parameterized queries. It generates a candidate plan set through the Row Count Evolution (RCE) algorithm, executes it on the workload to obtain the actual execution time, and uses the actual execution time to train the prediction model.
The prediction model adopts Spectral-normalized Neural Gaussian Processes (SNGPs), the latest advancement in machine learning uncertainty estimation, to improve convergence while outputting the uncertainty of the prediction. Based on this uncertainty, it is selected whether the model or the optimizer completes the plan prediction. Task. Experiments have proven that RCE can bring high acceleration effects, and SNGP can capture the acceleration effects brought by RCE as much as possible while avoiding regression. Therefore, the goals of PQO and QO are achieved at the same time, that is, while reducing the query planning time, the query execution performance is improved.
I decided to give up on open source industrial software. Major events - OGG 1.0 was released, Huawei contributed all source code. Ubuntu 24.04 LTS was officially released. Google Python Foundation team was laid off. Google Reader was killed by the "code shit mountain". Fedora Linux 40 was officially released. A well-known game company released New regulations: Employees’ wedding gifts must not exceed 100,000 yuan. China Unicom releases the world’s first Llama3 8B Chinese version of the open source model. Pinduoduo is sentenced to compensate 5 million yuan for unfair competition. Domestic cloud input method - only Huawei has no cloud data upload security issues