
This article introduces the background and experience of using the chain of responsibility design pattern, so that readers can deepen their impression of this design pattern, and even be inspired to "facelift" the projects they are currently involved in and responsible for, thereby improving the "facelift" of the system. Beauty”. Share every detail of your work.
1. Background
There is such a module in the system I am responsible for, the partition module. If you look at this word directly, I believe many people will be confused or even misunderstood. In fact, its real meaning is "routing". Next, I will briefly describe what "routing" is.
I believe everyone has had online shopping experience. Whenever we place an order, we can check the logistics tracking status of the order anytime and anywhere. The above-mentioned "routing" concept refers to: the transportation of the order from point A to point B. Routing line, for example, order order1 needs to be transported from A to destination F. It can go from A->B->D->F, or from A->D->F. As for which route should be taken, it depends on The routes configured in the system and the corresponding matching rules are filtered out.
For a long time, the routing configuration and rules in the system have been static (the so-called static means that they have been configured in advance and are almost fixed). The disadvantage of this approach is obvious, that is, the cost cannot be controlled, as mentioned above. In the example mentioned, there are obviously opportunities for the transportation route to be reduced or even delivered directly (the goods from A to F can obviously fill N trucks, but they have to be transported according to the route established in the system), but they are blocked by the system. Due to the fixed routing rules, we can only take more roads, which increases the cost of manpower operations and transportation.
Based on this, an expert discovered a business opportunity to reduce costs and increase efficiency: to activate this routing line and rules, so that the system can be more flexibly compatible with the above situations and achieve the ultimate utilization of resources. For example: For example, if there are many orders They are all destined from A to destination F. The static line configuration in the system is only A->B->D->F. However, after system monitoring and calculation, it was found that the amount of goods from A to F can fill two trucks. Then At this time, a new route is temporarily generated for these orders from A to F. At the same time, the goods are received and shipped at the A site. Any practical link involving routing line matching is compatible with this temporary routing scenario, so that The overall cost can be reduced without changing user habits, and the efficiency of transportation to the destination has also been greatly improved.
The plan proposed by this expert was very good and was widely recognized and praised by everyone. After the project was established, it entered a vigorous development stage, and I was fortunate enough to be entrusted with the important task of leading the development and delivery of this project.
It is worth mentioning that the changes to the routing circuit run through the entire actual operation process of the order as well as some corner-to-edge auxiliary queries, statistical reports and other functions. There are many scenarios involved, so the pressure is still quite high, although it is true that during the period We took a lot of detours, but the final result was good. Even later, there were several similar needs to change routing lines. But based on this transformation, we can easily deal with it. This will be discussed later in the article. It will be reflected in the effect.
Having said so much, do you feel that it is all nonsense? Haha, it is indeed a bit long-winded. Next, let us take a look at Menghuilu and reproduce the entire transformation process that is fragmented but has a sense of accomplishment.
2. Ideas and methods
The partitioning mentioned in subsequent articles is the meaning of matching rules for routing
First, let’s look at a simple schematic diagram of the practical operation process.
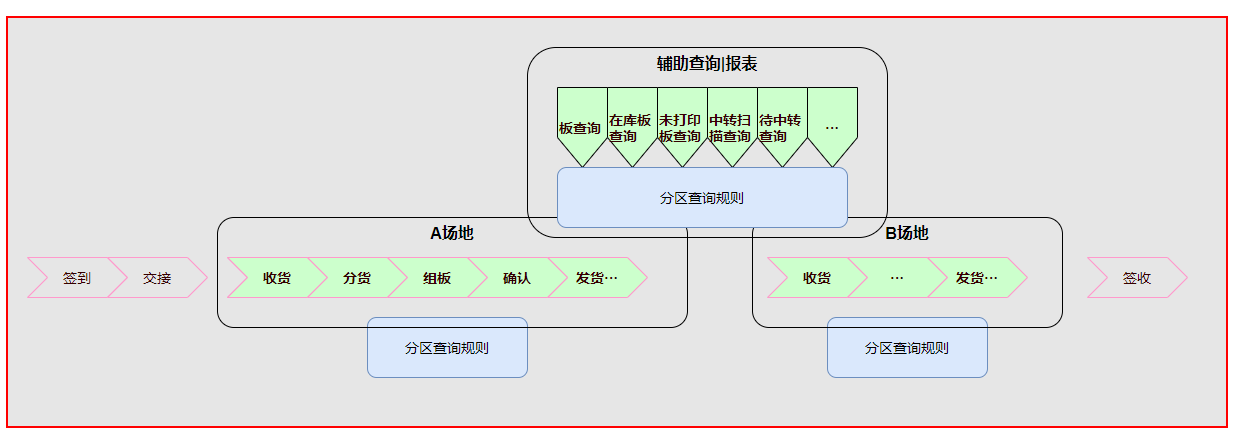
Partition matching rules will be involved in the actual operation process of each site. At the same time, routing matching rules will also be involved in the query function or report function of some auxiliary operations, so once the partition matching rules need to be changed , then you will face the following pain points
Based on the above pain points, I have decided to restructure and rectify this module. Firstly, I will improve myself through this challenge, and secondly, I will also pave the way for the possibility of changing this rule again in the future. So what should I do specifically? How to solve the pain points mentioned above? This is what I did
Seeing this, some people may ask, will this bring another problem: Although the scenes will not be missed, once a code change is reached, all scenes will take effect, but will the original scenes of some scenes be changed? Functional features? I think the students here are indeed very careful. If the closure is forced, this new problem will indeed arise. Therefore, the unified closure must support expansion and reserve hooks to support the differentiated processing of each scene. This is rather abstract. For example: For example, the general scenario rule is that all orders are transported according to the zoning rules of the system's established configuration, but now some merchants have opened some services to quickly deliver to the destination, then for these merchants' orders It is no longer possible to use the existing general rules for partition matching and transportation. It is necessary to perform partition matching according to the new rules to achieve the purpose of fast transportation. This is the difference inside.
So what exactly is the chain of responsibility model?
The definition given by Daniel: giving multiple objects the opportunity to process requests, thus avoiding the coupling relationship between the sender and receiver of the request. These objects are connected into a chain and the request is passed along the chain until an object handles it.
Let’s talk about how I apply it based on the actual business of the existing system: I have already introduced in the background of the opening chapter that the existing partition matching rules are static partition matching (such as a certain business point to point, a certain business point to a range area) Wait, I won’t go into the specific business details. Just know that there are a lot of matching rules here.) Now we need to add a new rule to support dynamics (it is also a variety of matching, so I won’t go into details). Here I Define each partition rule as a partition type, and each partition type as a partition node. Weave these nodes into a chain, so that each request can find a matching line in this chain. transportation.
Since the business details are relatively sensitive, they will not be disclosed in detail in the article, which will not affect the understanding of the application of key design patterns.
Combining the definition and the above analysis, is the actual situation suitable for using the responsibility chain design pattern? I believe that as long as the above pain points can be solved and the overall benefits outweigh the disadvantages, then it is applicable. First, the advantages of using this model to transform are as follows:
Of course, this model also has certain shortcomings: when the chain of responsibility is relatively long, since each request will traverse the entire chain, there may be performance problems. At the same time, it will also be more complicated to debug for students who do not understand the business.
Overall, the advantage is that it solves our current pain points and facilitates subsequent expansion, while the performance part of the disadvantages can be skipped by combining the hook functions reserved in the template mode (if the current request is not suitable for the current partition node rules ) to minimize the impact of performance problems, and at the same time, it is also necessary for developers to understand the business. So it seems that overall the advantages outweigh the disadvantages.
Having said so much, let’s first take a look at a simple comparison diagram of the partition module before and after the transformation.
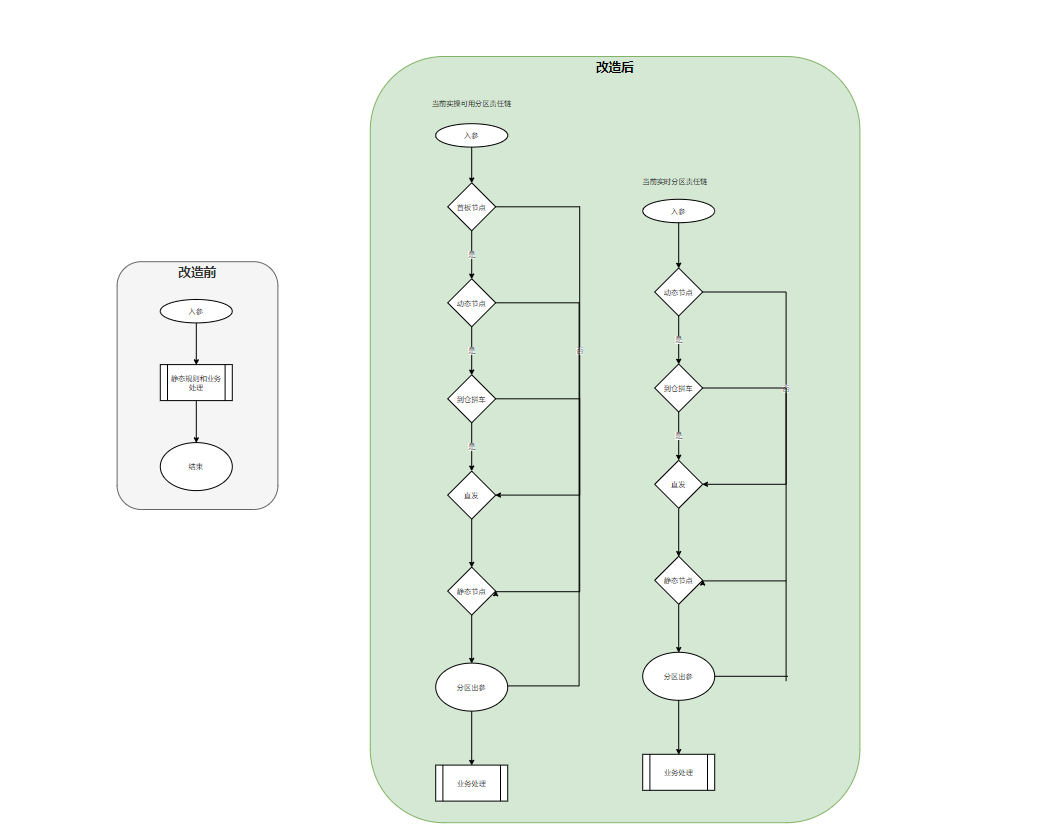
Although the diagram is very simple, the meaning of the comparison is still obvious. Before the transformation: partition matching and business processing are coupled together; after the transformation: partition matching is a chain and there is no business logic processing in it, which is freed from coupling. Extensions are also supported. Some people may be confused after seeing this: Didn't the above say that only one dynamic matching rule was added? Why are there so many nodes in the chain, and there are still two chains. Let me explain a little here: the current two chains have experienced many demand version changes. At present, it seems that the difference is not big, mainly because the source business specified scenarios they provide are different. The two abstracted chains are different from each other. Interfering with their respective operations, the nodes introduced in many places in this article were also added later, and are still the node rules used in the system until now (this is what I mentioned at the beginning of the article: What if there are rule changes later. Sure enough, it is still As smart as I am, the "prophecy" has come true. In the effect, I will tell you the importance of supporting expansion here to shorten the construction period)
3. Practical process
I believe many readers will find that the above talks about unified closing and combining with template mode to avoid performance impact to the greatest extent, so your chain of responsibility cannot be supported by one design mode.
Yes, you are right, Smart. It is true that just using a single chain of responsibility design pattern is far from achieving the effect mentioned above. Here we do combine the factory, template, and chain of responsibility patterns. Factory It is used to obtain the bean of the chain. The template is used to set general methods, calls between methods, and methods such as switches, pre- and post-processing, and differentiation reserved for subclass implementation. The responsibility chain is used to combine various nodes. Here are a few simple examples. The node displays the class diagram as follows
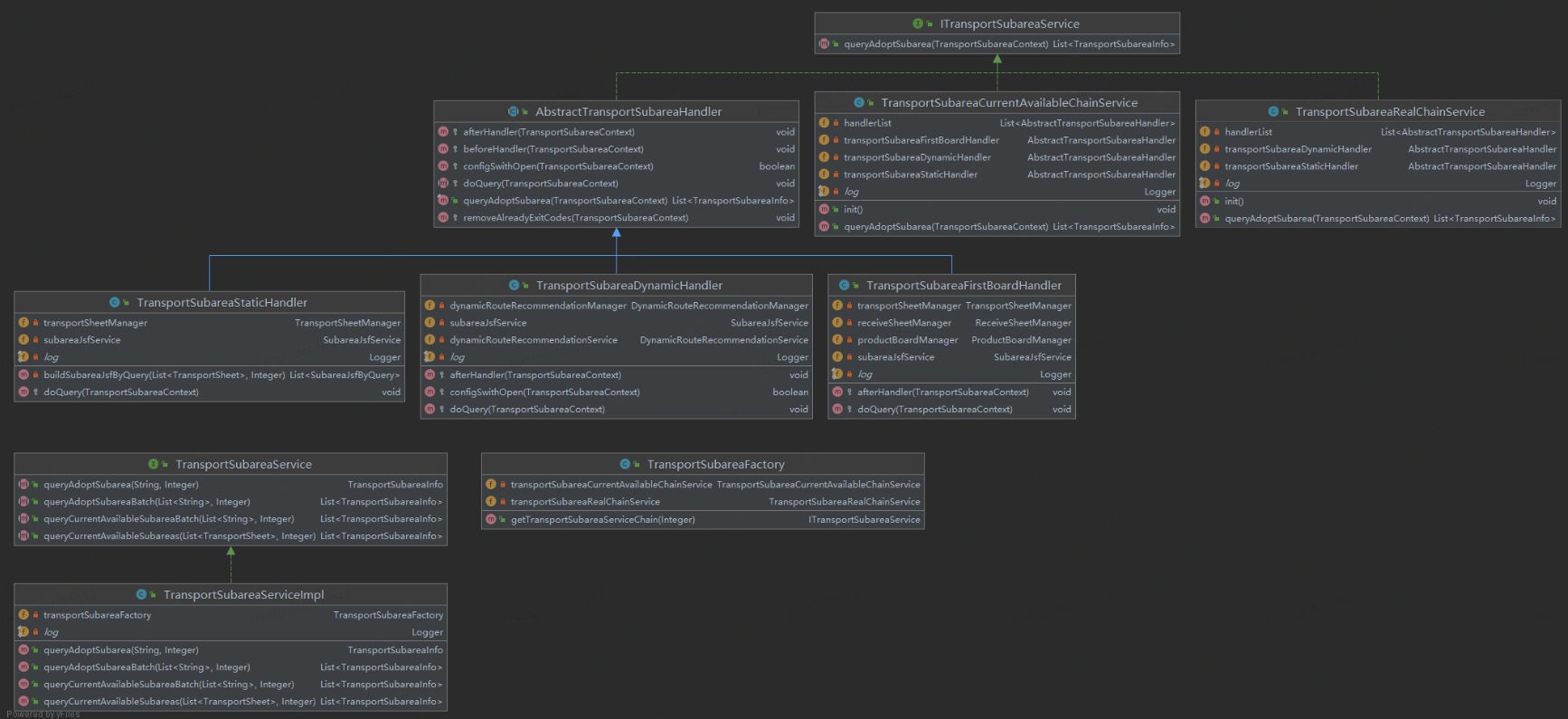
This section is relatively simple. After all, it is just coding. The above class diagram is almost a practical application in the code and is also the core part of the code. In actual calls, the bean chain is obtained through the factory for specific partition matching.
4. Thoughts on the practice process and evaluation of effects
The results after the transformation are mainly reflected in the subsequent expansion and maintenance. As mentioned at the beginning of the article, once the partition matching rules are changed, there will be two pain points. The most direct manifestation is in the construction period. The first time to take this block When changing the requirements for new routing rules, the overall actual construction period is 45 days on the R&D side, not to mention that once a BUG is encountered, the testing period is not guaranteed (corresponding to the dynamic nodes in the nodes in the figure above)

But not long after, new requirements for matching rules were added again (corresponding to the carpooling node in the node above). For similar requirements, the construction period was shortened by nearly half, and the optimal 45 days was reduced to 27 days. This requirement also includes For the transformation of other non-partitioned modules, of course, there are some perfections in the first version of the transformation. After this time, the requirements have been optimized.

The next two really embody what is called the disappearance of construction period. One is the first board zoning rule requirement, and the other is the direct zoning rule in the recent B network integration requirements.
To be honest, I didn’t expect such a big effect when I didn’t look back at the data. Looking back now, I am also shocked. Who would have thought that the application of a design pattern can shorten the construction period from 45 days to 1 God, this is incredible.
Of course, there are also some areas that can be improved and upgraded. At present, the assembly of responsibility chain nodes is manually specified and can be changed to automatic assembly (I have already implemented it in the transformation of another business scenario, and it will also be carried out here. Synchronous transformation), another one is to control the number of nodes. If the number is too large, you may need to consider a compatibility solution.
As the saying goes, it doesn’t take a day to pierce through a drop of water, and it doesn’t take a day to freeze three feet of ice. It is certainly feasible to pursue powerful tools and novel technologies, but don’t forget about the small changes in daily work. In a short time, You may not be able to see anything, but once quantitative changes lead to qualitative changes, I believe the results will be very impressive.