
Everyone is welcome to Star us on GitHub:
Distributed full-link causal learning system OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Large model-driven knowledge graph OpenSPG: https://github.com/OpenSPG/openspg
Large-scale graph learning system OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
In less than 5 years, large model and Transformers technology has almost completely changed the field of natural language processing and begun to revolutionize fields such as computer vision and computational biology. Dr. Sebastian Raschka focuses on academic research papers and has prepared an introductory reading list for machine learning researchers and practitioners. After reading it in order, you can really get started in the current field of large model technology.
Of course, Dr. Sebastian Raschka also mentioned that there are many other helpful resources, such as:
- Jay Alammar的《Illustrated Transformer》;
- More technical blog posts by Lilian Weng;
- All catalogs and genealogy of Transformers organized by Xavier Amatriain;
- A minimal-code implementation of a generative language model written for educational purposes by Andrej Karpathy;
- and a lecture series and book chapter by the author of this article.
Understand the main architecture and tasks
If you are new to Transformers/large models, it makes the most sense to start from scratch.
1. Neural Machine Translation by Joint Learning to Align and Translate (2014)
Author: Bahdanau, Cho Wa Bengio
Paper link: https://arxiv.org/abs/1409.0473
If you have a few minutes to spare, I recommend starting with this paper. This paper introduces an attention mechanism to recurrent neural networks (RNN) to enhance the modeling capabilities of long sequences. This allows RNNs to translate longer sentences more accurately - which was the motivation behind the development of the original Transformer architecture.
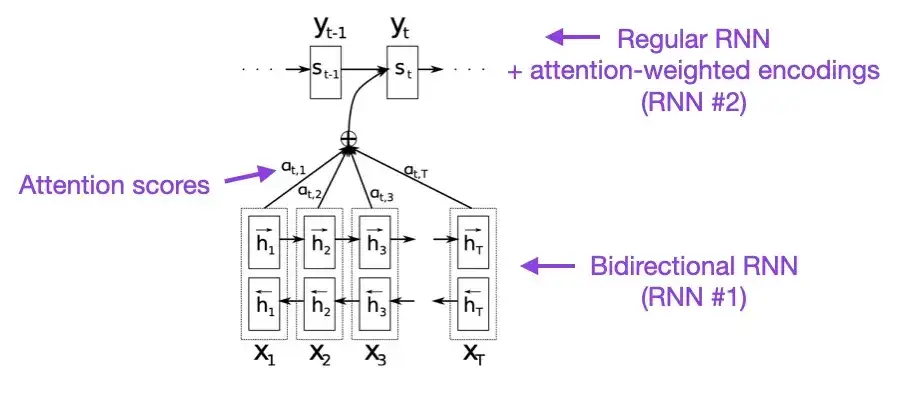
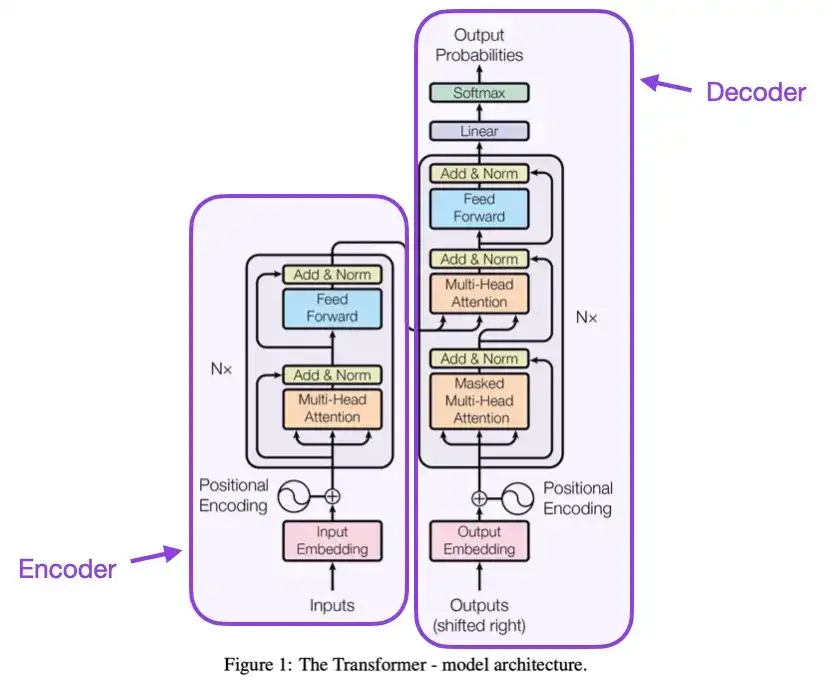
2. Attention Is All You Need (2017)
Credits: Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin
Paper link: https://arxiv.org/abs/1706.03762
This paper introduces the original Transformer architecture, which consists of two parts: an encoder and a decoder. These two parts will later become independent modules for explanation. In addition, this paper also introduced concepts such as scaling dot product attention mechanisms, multi-head attention blocks, and positional input encoding, which are still the foundation of modern Transformer models.
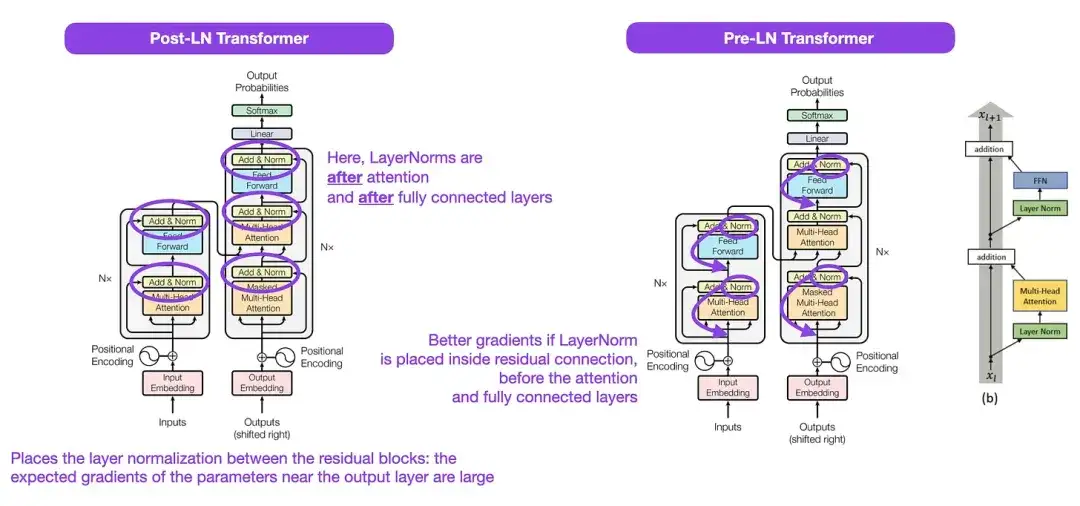
3. On Layer Normalization in the Transformer Architecture__(2020)
Authors: Yang, He, K Zheng, S Zheng, Xing, Zhang, Lan, Wang, Liu
Paper link: https://arxiv.org/abs/2002.04745
Although the original Transformer structure shown in the figure above is a very good summary of the original encoder-decoder architecture, the position of LayerNorm in the figure has been controversial. For example, the Transformer structure diagram in "Attention Is All You Need" places LayerNorm between residual blocks, which is inconsistent with the official (updated) code implementation accompanying the original Transformer paper. The variant shown in the picture of "Attention Is All You Need" is called Post-LN Transformer, and the updated code implementation uses the Pre-LN variant by default.
In the article "Layer Normalization in the Transformer Architecture", it is pointed out that Pre-LN works better and can solve the gradient problem. As shown below, many architectures adopt this approach in practice, but it can lead to representation collapse. Therefore, while the discussion of whether to use Post-LN or Pre-LN continues, a new paper "ResiDual: Transformer with Dual Residual Connections" ( https://arxiv.org/abs/2304.14802 ) proposes to utilize both. advantages; its effectiveness in practice remains to be seen.
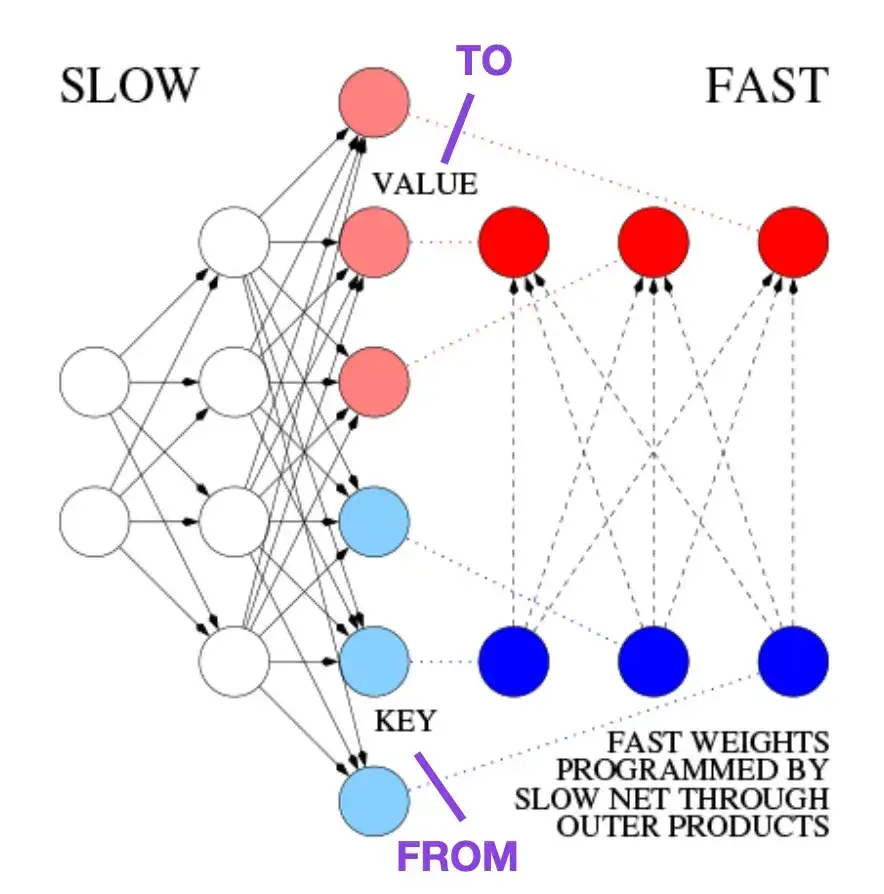
4. Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks__(1991)
Author: Schmidhuber
Paper link:
This paper is recommended for readers interested in historical anecdotes and early technologies similar to the modern Transformer architecture. For example, in 1991, approximately 25 years before the original Transformer paper Attention Is All You Need , Juergen Schmidhuber proposed a Fast Weight Programmer (FWP) as an alternative to recurrent neural networks. The FWP method involves a feedforward neural network that learns slowly via gradient descent to program the rapid weight changes of another neural network. The analogy to a modern Transformer is explained in the following blog post:
In today's Transformer terminology, FROM and TO are called keys and values respectively. The INPUT used by fast networks is called a query. Essentially, the query is processed through a fast weight matrix, which is the sum of the outer products of keys and values (ignoring normalization and projection). Since all operations of both networks are differentiable, we obtain end-to-end differentiable active control of fast weight changes through the addition of outer products or second-order tensor products. Therefore, the slow network can be learned via gradient descent, quickly modifying the fast network during sequence processing. This is mathematically equivalent (except for the normalization) to what became known as the Linear Self-Attention Transformer (or Linear Transformer).
As mentioned in the excerpt from the blog post above, this approach is now known as "Linear Transformer" or "Transformer with linearized self-attention". Subsequently, the equivalence between linearized self-attention and the fast weight programmers of the 1990s was clearly demonstrated in the 2021 paper "Linear Transformers Are Secretly Fast Weight Programmers".
5. Universal Language Model Fine-tuning for Text Classification(2018)
Author; Howard, Ruder
Paper address: https://arxiv.org/abs/1801.06146
This is a very interesting article from a historical perspective. It was written a year after the release of "Attention Is All You Need", but it did not involve Transformer, but focused on recurrent neural networks. However, it still deserves attention as it effectively proposes pre-trained language models and transfer learning for downstream tasks. Although transfer learning is well established in the field of computer vision, it has not yet become popular in natural language processing (NLP). ULMFit is one of the first papers to demonstrate pre-trained language models and fine-tuning them to specific tasks, resulting in state-of-the-art results in many NLP tasks.
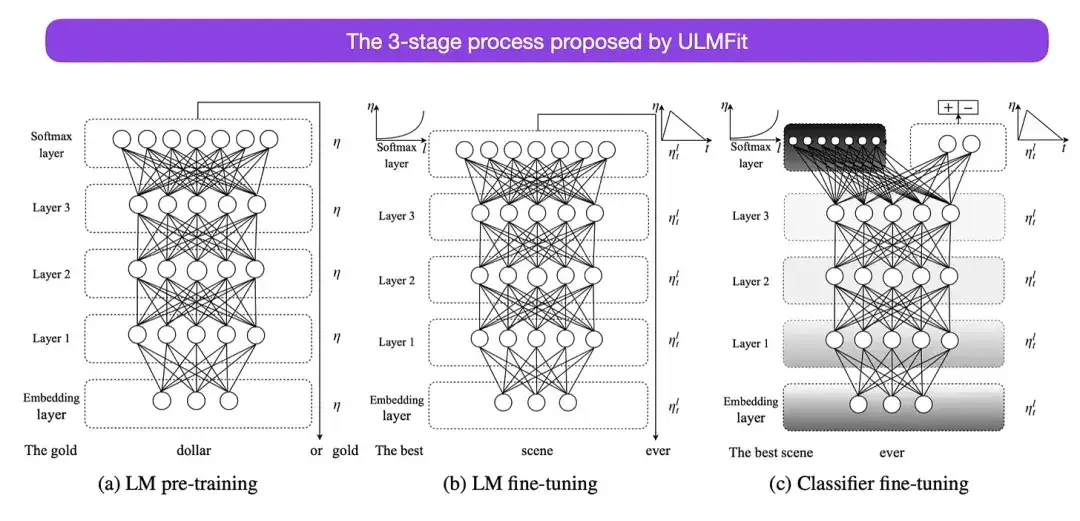
The three-stage process of fine-tuning language models proposed by ULMFit is as follows:
- Train a language model on a large text corpus;
- Fine-tune this pre-trained language model on task-specific data to adapt it to the style and vocabulary of the specific text;
- Avoid catastrophic forgetting by gradually unfreezing layers while fine-tuning the classifier on task-specific data.
This method - first training a language model on a large corpus, and then fine-tuning it to downstream tasks - is the core method of Transformer-based models and basic models (such as BERT, GPT-2/3/4, RoBERTa, etc.). However, the key part in ULMFit, the gradual unfreezing, is not usually performed routinely when actually operating the converter architecture, and usually all layers are fine-tuned at once.
6. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding****(2018)
作者:Devlin, Chang, Lee, Toutanova
Paper link: https://arxiv.org/abs/1810.04805
According to the original Transformer architecture, research on large-scale language models began to diverge in two directions: encoder-based Transformers for predictive modeling tasks (such as text classification), and generative modeling tasks (such as translation, summarization and A decoder-style Transformer for other text creation forms).
The aforementioned BERT paper introduced the original concepts of masked language modeling and next sentence prediction, and it remains the most influential encoder-style architecture. If you are interested in this branch of research, I recommend you to continue learning about RoBERTa, which simplifies the pre-training goal by removing the next sentence prediction task.
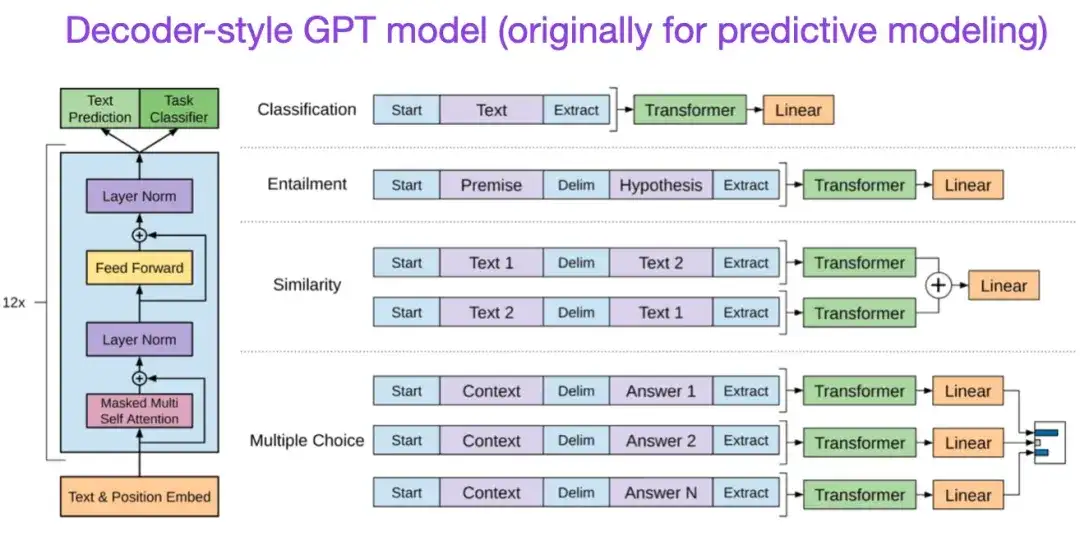
** 7. Improving Language Understanding by Generative Pre-Training (2018)** Author: Radford and Narasimhan Paper address:
The original GPT paper introduced the popular decoder-style architecture and pre-training via next word prediction. Whereas BERT can be viewed as a bidirectional transformer due to its masked language model pre-training objective, GPT is a one-way, autoregressive model. Although GPT embeddings can also be used for classification, GPT methods are at the core of today's most influential large language models (LLMs), such as ChatGPT.
If you are interested in this research direction, I recommend that you continue to learn more about GPT-2 and GPT-3 related papers. These two papers demonstrate that LLMs can achieve zero-shot and few-shot learning, and highlight the emergent capabilities of LLMs. GPT-3 is still the most commonly used baseline and basic model for training current LLM. The InstructGPT technology that gave birth to ChatGPT will be introduced in a separate entry later.
GPT2 related papers: https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe
GPT3 related papers: https://arxiv.org/abs/2005.14165
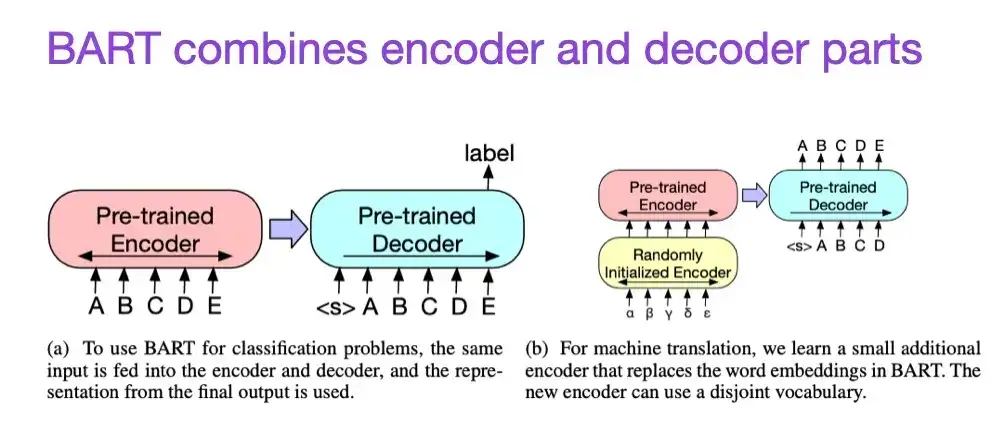
8. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2019)
作者:Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, Zettlemoyer
Paper link: https://arxiv.org/abs/1910.13461 .
As mentioned earlier, BERT-type encoder-style large language models (LLMs) are generally better suited for predictive modeling tasks, while GPT-type decoder-style LLMs are better at generating text. In order to combine the best of both worlds, the above-mentioned BART paper combines the encoder and decoder parts (which is similar to the original Transformer structure introduced in the second paper).
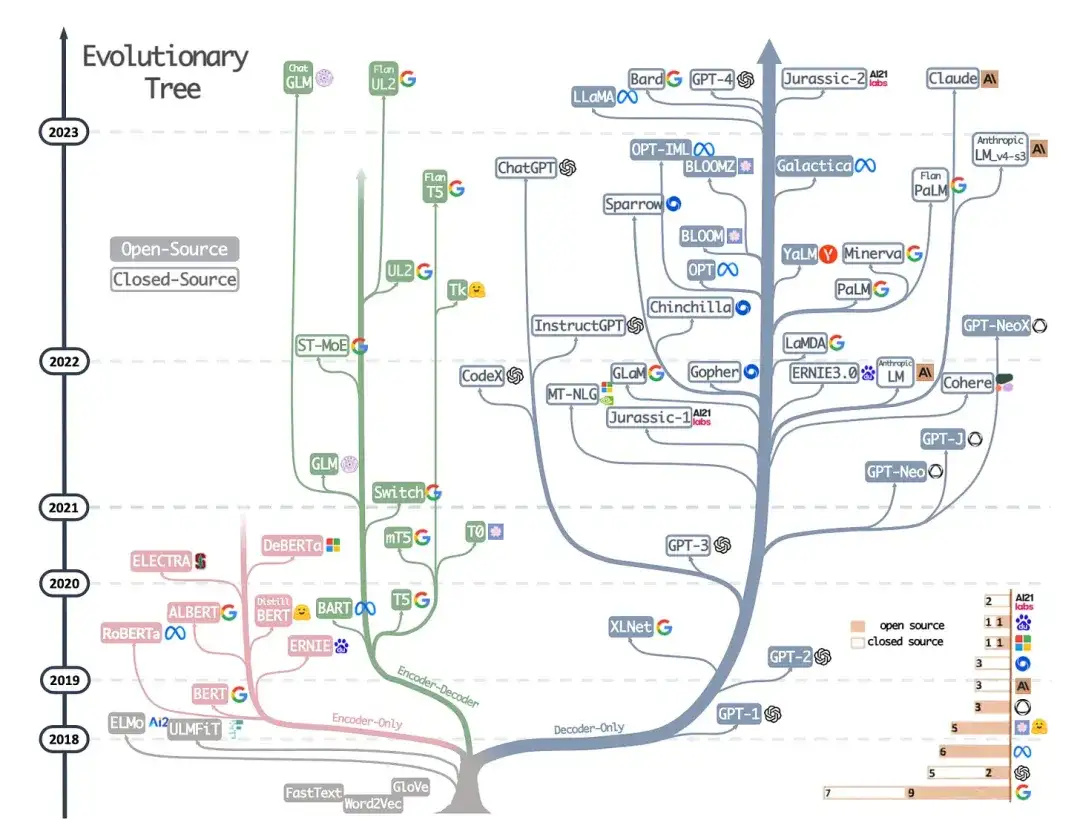
9. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond(2023)
Author: Yang, Jin, Tang, Han, Feng, Jiang, Yin, Hu,
Paper link: https://arxiv.org/abs/2304.13712
This is not a research paper, but it is probably the best architecture overview article ever written, and it vividly shows how different architectures have evolved. However, in addition to discussing BERT-style masked language models (encoders) and GPT-style autoregressive language models (decoders), it also provides helpful discussion and guidance on pre-training and fine-tuning data.
Scaling Laws & Improving Efficiency
If you want to learn more about various techniques to improve Transformer efficiency, I recommend reading the 2020 paper "Efficient Transformers: A Survey" and the 2023 paper "A Survey on Efficient Training of Transformers". Additionally, here are a few papers that I found particularly interesting and worth reading.
- 《Efficient Transformers: A Survey》:
https://arxiv.org/abs/2009.06732
- 《A Survey on Efficient Training of Transformers》:
https://arxiv.org/abs/2302.01107
10. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness(2022)
Author: Dao, Fu, Ermon, Rudra, Ré
Paper link: https://arxiv.org/abs/2205.14135 .
Although most Transformer papers don't bother replacing the original scaled dot product mechanism to achieve self-attention, the one mechanism I see cited most recently is FlashAttention.
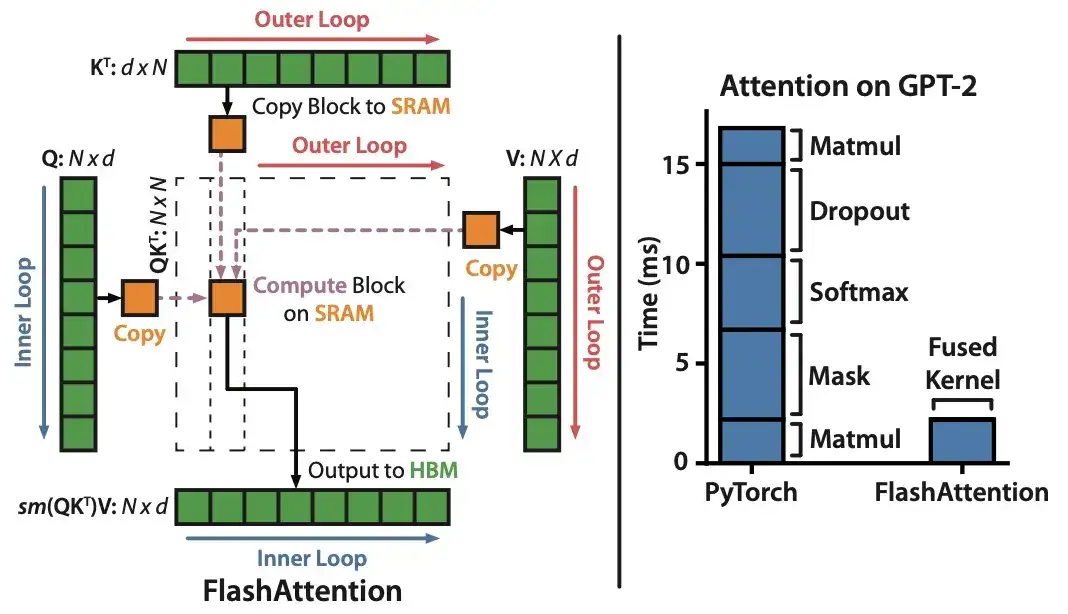
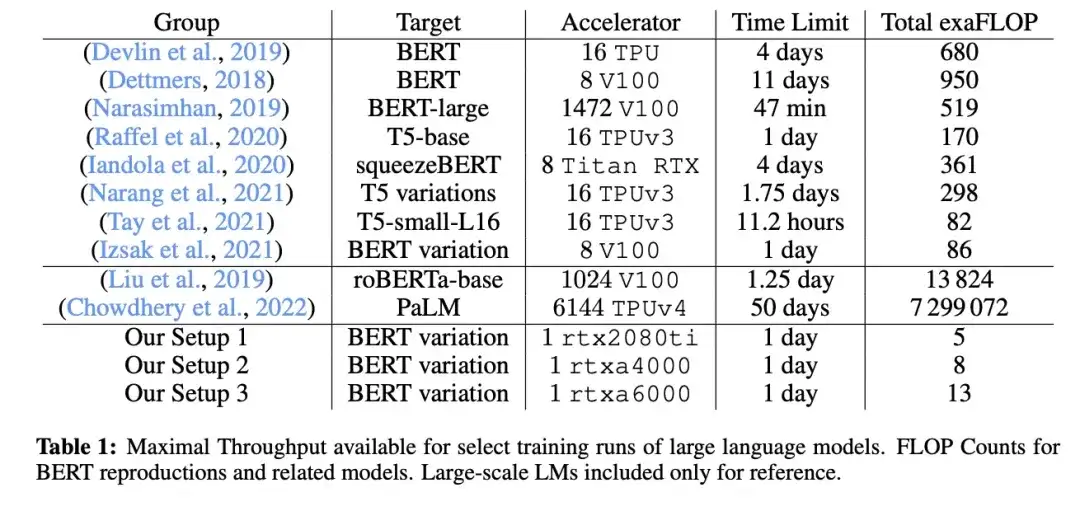
11. Cramming: Training a Language Model on a Single GPU in One Day (2022)
_Author:_Geiping and Goldstein,
Paper link: https://arxiv.org/abs/2212.14034
In this paper, researchers used a single GPU to train a masked language model/encoder style large language model (here BERT) for 24 hours. For comparison, the original BERT paper in 2018 was trained on 16 TPUs for four days. An interesting finding is that although smaller models have higher throughput, they also learn less efficiently. Therefore, larger models do not require longer training times to reach a certain predictive performance threshold.
12. LoRA: Low-Rank Adaptation of Large Language Models (2021)
Author: by Hu, Shen, Wallis, Allen-Zhu, Li, L Wang, S Wang, Chen
Paper link: https://arxiv.org/abs/2106.09685 .
Modern large-scale language models exhibit emergent capabilities through pre-training on large-scale data sets and perform well on a variety of tasks, including language translation, summary generation, programming, and question answering. However, there is value in fine-tuning a transformer to improve its capabilities on domain-specific data and specialized tasks. Low-rank adaptation (LoRA) is one of the most influential methods for parameter-efficient fine-tuning of large language models.
Although other methods for efficient parameter fine-tuning exist, LoRA deserves particular attention because it is both elegant and very general and can be applied to other types of models. The weights of a pretrained model have full rank on the task they were pretrained on, whereas the authors of LoRA note that large language models have lower "intrinsic dimensionality" when they are adapted to new tasks. Therefore, the core idea of LoRA is to decompose the weight change ΔW into lower-rank representations to achieve higher parameter efficiency.

13_. Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning (2022)_
Author: Lialin, Deshpande, Rumshisky
Paper link: https://arxiv.org/abs/2303.15647 .
This review reviews more than 40 papers on efficient parameter fine-tuning methods (covering popular techniques such as prefix adjustment, adapters, and low-rank adaptation), aiming to make the fine-tuning process (extremely) computationally efficient.
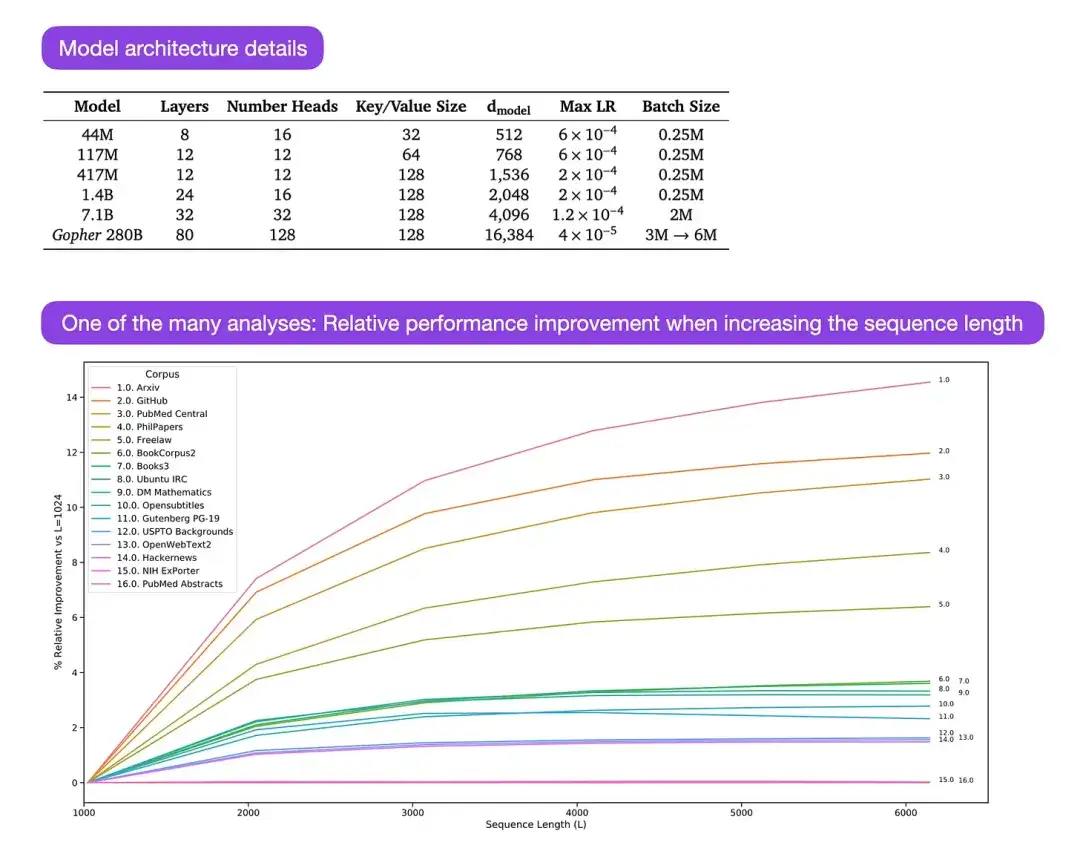
** 14. Scaling Language Models: Methods, Analysis & Insights from Training Gopher (2022)** Author: Rae and 78 colleagues
Paper link: https://arxiv.org/abs/2112.11446
Gopher is a particularly good paper that contains a lot of analysis to understand the training process of large language models (LLM). The researcher trained a model with 280B parameters and 80 layers here. The model was trained based on 300B tokens. It contains some interesting architectural improvements, such as using RMSNorm (root mean square normalization) instead of LayerNorm (layer normalization). Both LayerNorm and RMSNorm are preferred over BatchNorm because they do not depend on batch size and do not require synchronization, which is especially advantageous when using smaller batches in distributed settings. However, it is generally believed that RMSNorm is more effective in stabilizing the training process of deep architectures.
除上述这些有趣的细节外,该论文的主要焦点在于分析不同规模下的任务表现。针对152项多样化的任务评估显示,模型尺寸的增大对理解能力、事实核查以及识别有害语言等任务的提升效果最为显著。然而,与逻辑和数学推理相关的任务从架构扩展中获益较少。
15. Training Compute-Optimal Large Language Models(2022)
作者:Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals, 和 Sifre
Paper link: https://arxiv.org/abs/2203.15556 .
本文介绍了一款名为Chinchilla的70B参数模型,该模型在生成建模任务上超越了广受欢迎的175B参数的GPT-3模型。然而,其核心观点在于指出当前大型语言模型“显著缺乏训练”。论文定义了大型语言模型训练的线性缩放定律。例如,尽管Chinchilla的规模仅为GPT-3的一半,但它之所以能超越 GPT-3,是因为它接受了1.4万亿(而非仅3000亿)个token的训练。换言之,训练token的数量与模型大小同样至关重要。
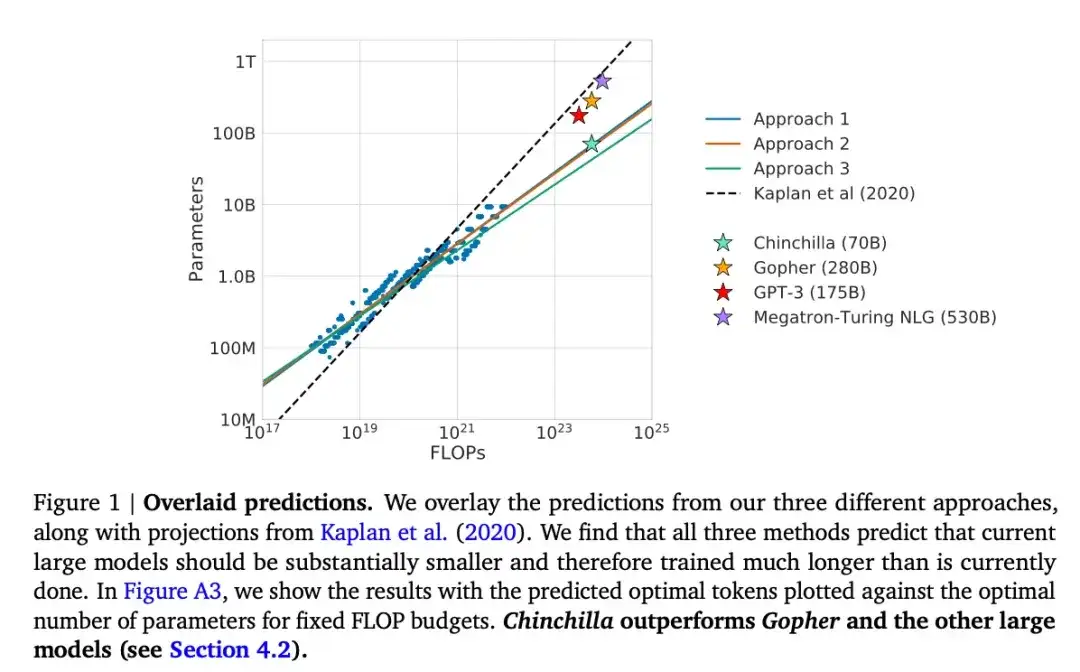
16.Pythia:A Suite for Analyzing Large Language Models Across Training and Scaling(2023)
作说:Biderman, Schoelkopf, Anthony, Bradley, O'Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika, 和van der Wal
Paper link: https://arxiv.org/abs/2304.01373
Pythia is a series of open source large language models (ranging from 700M to 12B parameters), designed to study the evolution of large language models during the training process. Its architecture is similar to GPT-3, but includes some improvements, such as Flash Attention (similar to LLaMA) and Rotary Positional Embeddings (similar to PaLM). Pythia is trained on The Pile data set (825Gb), and the training uses 300B tokens (approximately equivalent to 1 epoch on regular PILE, or 1.5 epochs on deduplicated PILE).
The main findings of the Pythia study are as follows:
- Training on repeated data (which means training for more than one epoch due to the way large language models are trained) neither helps nor hurts performance;
- The order of training does not affect the memory effect. This is unfortunate, because if the opposite were true, we could mitigate the undesirable verbatim memory problem by reordering the training data;
- Word frequency during pre-training affects task performance. For example, for words that appear more frequently, accuracy with a smaller number of samples tends to be higher;
- Doubling the batch size cuts training time in half without affecting convergence.
Alignment: Guide large language models to desired goals and interests
In recent years, we have witnessed a number of large-scale language models that are relatively powerful and capable of generating realistic text (such as GPT-3 and Chinchilla, etc.). It seems that we have reached a ceiling of what can be achieved under commonly used pre-training paradigms.
To make the language model more useful and reduce the generation of misinformation and harmful language, the researchers designed additional training paradigms to fine-tune the pre-trained base model.
17. Training Language Models to Follow Instructions with Human Feedback****(2022)
作者:Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike, 和Lowe,
Paper link: https://arxiv.org/abs/2203.02155 .
In the so-called InstructGPT paper, the researchers used a reinforcement learning mechanism combined with human feedback (RLHF). They first used the pretrained GPT-3 base model and further fine-tuned it via supervised learning on human-generated cue-response pairs (step 1). Next, they trained a reward model by having humans rank the model outputs (step 2). Finally, they used the reward model to update the pre-trained and fine-tuned GPT-3 model through the reinforcement learning method of proximal policy optimization (step 3).
Incidentally, this paper is also considered to be the paper that explains the idea behind ChatGPT - according to recent rumors, ChatGPT is a scaled version of InstructGPT that has been fine-tuned with a larger data set.
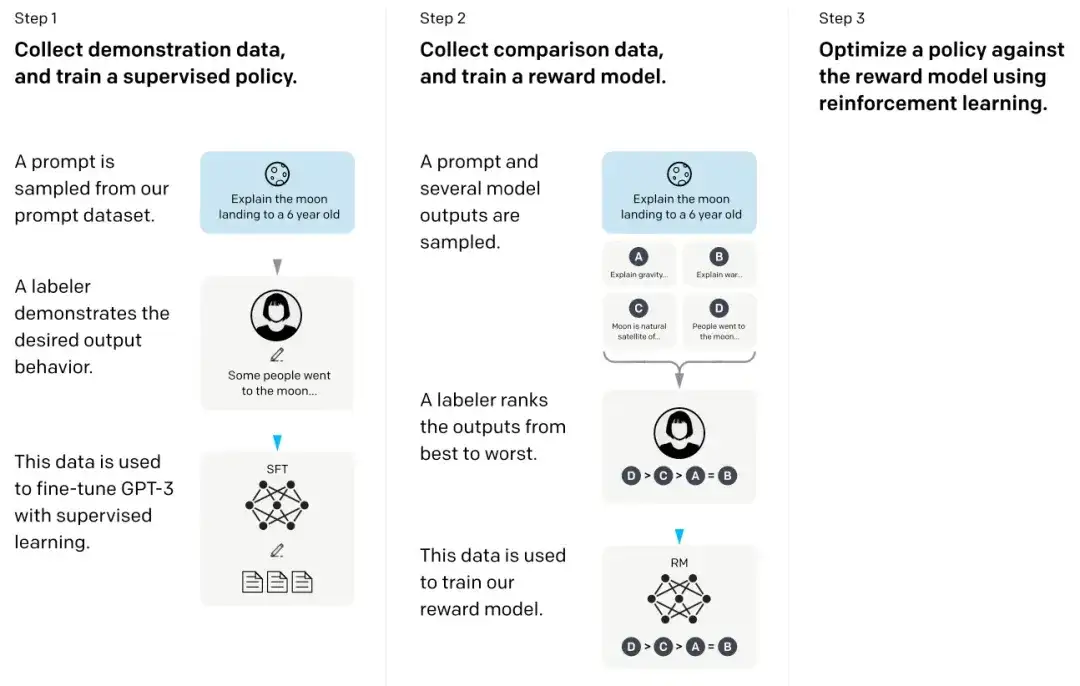
18. Constitutional AI: Harmlessness from AI Feedback(2022)
Featured:Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau , Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann, Amodei, Joseph, McCandlish, Brown, Kaplan
Paper link: https://arxiv.org/abs/2212.08073 .
In this paper, researchers further develop the idea of "alignment" and propose a training mechanism to create "harmless" AI systems. Instead of direct human supervision, the researchers propose a self-training mechanism based on a list of rules that are provided by humans. Similar to the InstructGPT paper mentioned above, the proposed method uses reinforcement learning methods.
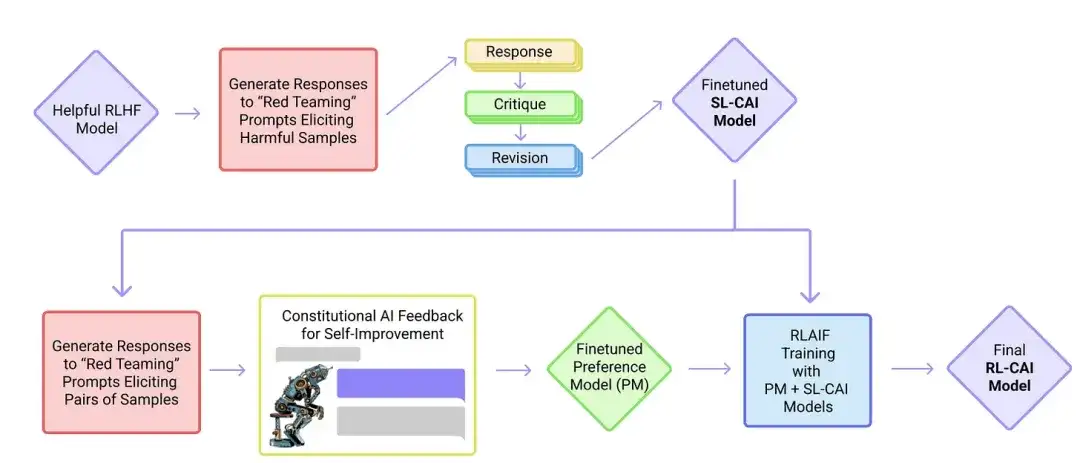
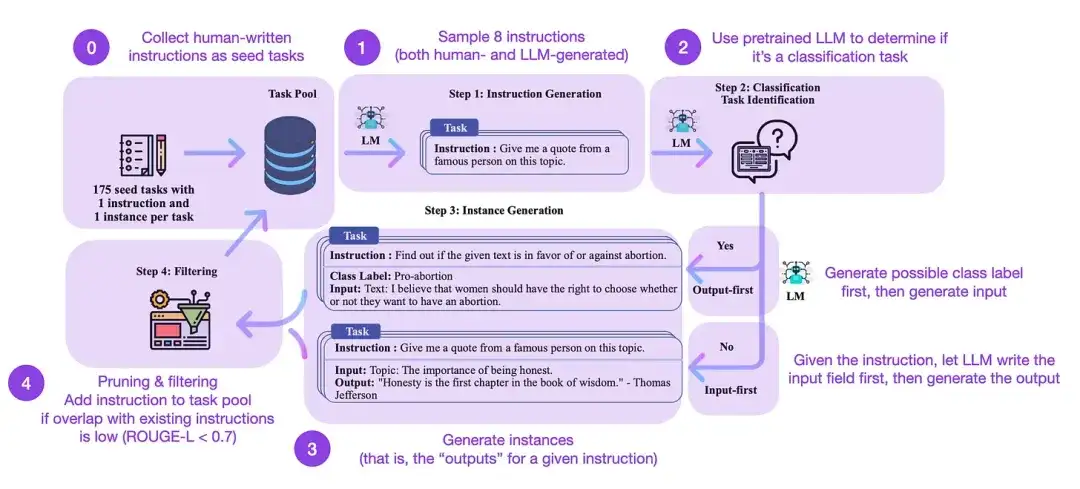
19. Self-Instruct: Aligning Language Model with Self Generated Instruction(2022)
Authors of the paper: Wang, Kordi, Mishra, Liu, Smith, Khashabi, and Hajishirzi
Paper link: https://arxiv.org/abs/2212.10560
Instruction fine-tuning is how we transition from pre-trained base models like GPT-3 to more powerful LLMs like ChatGPT. Open source, human-generated instruction datasets like databricks-dolly-15k can help make this process possible. But how to achieve scale? One approach is to let LLM perform bootstrap learning based on its own generated content.
Self-Instruct is a (nearly annotation-free) method of aligning pretrained LLMs with instructions. How does this process work? In short, it consists of four steps:
- Initialize a task pool with a set of human-written instructions (175 in this case) and sample instructions from it;
- Use a pre-trained LLM (such as GPT-3) to determine the task category;
- For new instructions, let the pre-trained LLM generate responses;
- These responses are collected, filtered, and filtered before adding them to the task pool.
In this way, the self-instruction method can effectively improve the ability of the pre-trained language model to follow and generate instructions while reducing manual annotation, thereby expanding and optimizing the model's capabilities.
In practice, this method performs relatively well based on the ROUGE score. For example, self-guided fine-tuning of large language models (LLMs) outperformed the GPT-3 base model and was able to compete with LLMs pre-trained on large sets of human-written instructions. Moreover, self-guidance can also benefit LLMs that have been fine-tuned by human instructions.
Of course, the gold standard for evaluating LLM is to invite human evaluators to participate. Based on human evaluation, self-guided methods go beyond basic LLM, as well as LLM trained on human instruction datasets in a supervised manner (such as SuperNI, T0 Trainer). But interestingly, self-guidance did not outperform those trained through reinforcement learning methods incorporating human feedback (RLHF).
Which is more promising, human-generated instruction data sets or self-guided data sets? I'm bullish on both. Why not start with a human-generated instruction dataset, such as the 15,000 instructions in databricks-dolly-15k, and then extend it in a self-directed way?
Reinforcement Learning and Human Feedback (RLHF) For more explanations of Reinforcement Learning and Human Feedback (RLHF), as well as related papers on proximal policy optimization to implement RLHF, please see my more detailed article below:
When discussing large language models (LLMs), whether in research updates or tutorials, I often refer to a process called reinforcement learning with human feedback (RLHF). RLHF has become an important part of the modern LLM training pipeline because it can incorporate human preferences into the optimization framework, thereby improving the usefulness and safety of the model.
Read the full article:
https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
Conclusion and further reading
I tried to keep the above list concise and concise, focusing on the top ten papers (plus three papers on RLHF) that understand the design, limitations, and evolution of contemporary large-scale language models. For further study, it is recommended to refer to the cited documents in the above papers. Here are some additional resources:
Open source alternatives to GPT:
- BLOOM: A 176B-Parameter Open-Access Multilingual Language Model (2022),https://arxiv.org/abs/2211.05100
- OPT: Open Pre-trained Transformer Language Models (2022),https://arxiv.org/abs/2205.01068
- UL2: Unifying Language Learning Paradigms (2022),https://arxiv.org/abs/2205.05131
ChatGPT alternatives:
- LaMDA: Language Models for Dialog Applications (2022),https://arxiv.org/abs/2201.08239
- (Bloomz) Crosslingual Generalization through Multitask Finetuning (2022),https://arxiv.org/abs/2211.01786
- (Sparrow) Improving Alignment of Dialogue Agents via Targeted Human Judgements (2022),https://arxiv.org/abs/2209.14375
- BlenderBot 3: A Deployed Conversational Agent that Continually Learns to Responsibly Engage,https://arxiv.org/abs/2208.03188
Large models in biocomputing:
- ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing (2021),https://arxiv.org/abs/2007.06225
- Highly Accurate Protein Structure Prediction with AlphaFold (2021),https://www.nature.com/articles/s41586-021-03819-2
- Large Language Models Generate Functional Protein Sequences Across Diverse Families (2023),https://www.nature.com/articles/s41587-022-01618-2
Article recommendations
7 prompt tips to make your conversation with AI more effective
In an era when everyone is a developer, is it still useful to learn programming?
If there is any infringement, please contact us to delete it. Reference links:
https://magazine.sebastianraschka.com/p/understanding-large-language-models
Follow us
OpenSPG:
Official website: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
Official website: https://openasce.openfinai.org/
GitHub: [https://github.com /Open-All-Scale-Causal-Engine/OpenASCE ]