
Author: Chen Xin (Shenxiu)
Hello everyone, I am Chen Xin, the product technical director of Tongyi Lingma. For the past eight years, I have been working in Alibaba Group on R&D performance, that is, R&D tool-related work.
We started building a one-stop DevOps platform in 2015, and then created Cloud Effect, which is to cloudify the DevOps platform. By 2023, we clearly feel that after the era of large models has arrived, software tools will face thorough innovation. The combination of large models and software tool chains will bring software research and development into the next era.
So where is its first stop? In fact, it is auxiliary programming, so we started to create the product Tongyi Lingma , which is an AI auxiliary tool based on a large code model. Today I take this opportunity to share with you some details on the implementation of Tongyi Lingma technology and how we view the development of large models in the field of software research and development.
I will share it in three parts. The first part first introduces the fundamental impact of AIGC on software research and development, and introduces the current trends from a macro perspective; the second part will introduce the Copilot model, and the third part is the progress of future software development Agent products. Why I mentioned Copilot Agent, I will explain to you later.
AIGC’s fundamental impact on software development
This picture is a picture I drew in the past few years. I think the core influencing factors of corporate R&D efficiency are these three points.
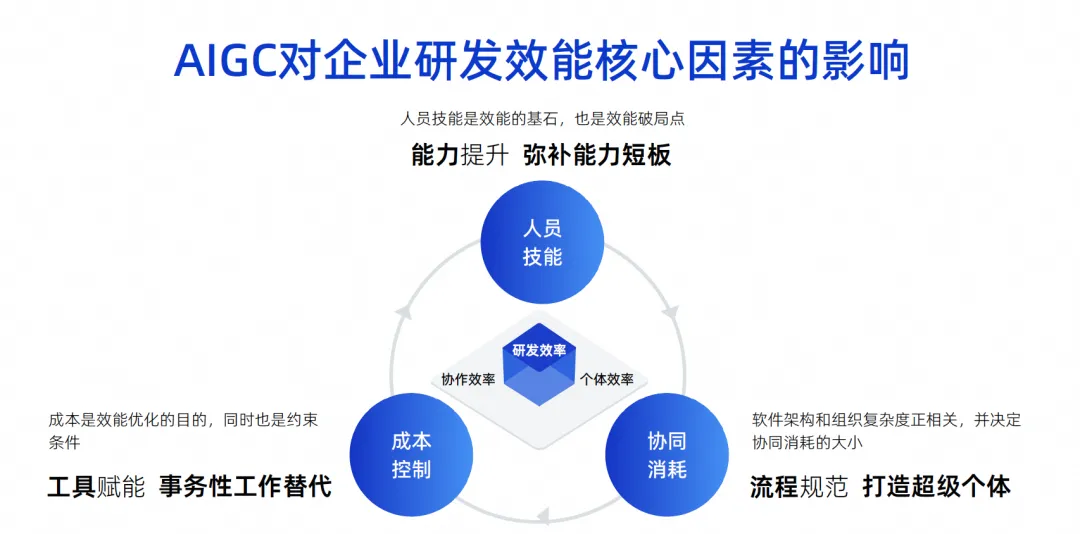
The first point is people skills. Personnel skills determine a very large factor in an enterprise's R&D efficiency. For example, Google can recruit engineers whose personal abilities are ten times stronger than others. One person is equivalent to ten people. Then a small group composed of a group of ten times more capable engineers will have a combat effectiveness of It is very powerful and can even realize the full stack. Their division of roles may be very simple, their work is very efficient, and their final effectiveness is also very great.
But in fact, few of our companies, especially Chinese companies, can reach the level of Google. This is an objective influencing factor. We believe that personnel skills are the cornerstone of effectiveness, and of course are also the breaking point of effectiveness.
The second point is collaborative consumption. On the basis that we cannot require every engineer to be highly capable, everyone must have a professional division of labor. For example, some do software design, and some do development, testing, and project management. As the complexity of the software architecture of the team composed of these people increases, the complexity of the organization will also increase proportionally. This will cause the collaborative consumption to increase, ultimately slowing down the overall R&D efficiency. .
The third point is cost control. We found that when working on projects, people cannot always be rich, there is always a shortage of manpower, and it is impossible to have unlimited funds to recruit ten times the number of engineers, so this is also a constraint.
Today in the era of AIGC, these three factors have produced some fundamental changes.
In terms of personnel skills, AI assistance can quickly improve the capabilities of some junior engineers. In fact, there are some reports about this abroad. The effect of junior engineers using code assistance tools is significantly higher than that of senior engineers. Why? Because these tools are very good substitutes for entry-level work, or their auxiliary effect, they can quickly make up for the shortcomings of junior engineers.
In terms of collaborative consumption, if AI can become a super individual today, it will actually be helpful to reduce process collaborative consumption. For example, there is no need to deal with people for some simple tasks, AI can do it directly, and there is no need to explain to everyone how to test the requirements. AI can just do simple tests, so the time efficiency is improved. Therefore, collaborative consumption can be effectively reduced through super individuals.
In terms of cost control, in fact, a large number of AI uses are to replace transactional work, including the current use of large code models for code assistance, which is also expected to replace 70% of daily transactional labor.
If we look at it specifically, there will be these four challenges and opportunities for intelligence.

The first one is individual efficiency. As I just introduced to you, the repetitive work and simple communication of a large number of R&D engineers can be completed through AI. It is a Copilot model.
Another aspect of collaboration efficiency is that some simple tasks can be done directly by AI, which can reduce collaboration consumption. I have just explained this clearly.
The third one is R&D experience. What did the DevOps tool chain focus on in the past? One by one, they form a large assembly line and the entire tool chain. In fact, each tool chain may have different usage habits in different companies, and may even have different account systems, different interfaces, different interactions, and different permissions. This complexity brings very large context switching costs and understanding costs to developers, which invisibly makes developers very unhappy.
But some changes have taken place in the AI era. We can use natural language to operate many tools through a unified dialogue entrance, and even solve many problems in the natural language window.
Let me give you an example. For example, if we checked whether there is any performance problem in a SQL statement, what should we do? You may first dig out the SQL statement in the code, turn it into an executable statement, and then put it into a DMS system to diagnose it to see if it uses indexes and whether there are any problems, and then manually judge whether it is necessary or not. Modify this SQL to optimize it, and finally change it in the IDE. This process requires switching multiple systems and a lot of things need to be done.
In the future, if we have code intelligence tools, we can circle a code and ask the large model if there is any problem with this SQL. This large model can independently call some tools, such as the DMS system, to analyze, and the results obtained can be Directly tell me how SQL should be optimized through the large model and tell me the results directly. We only need to adopt it to solve the problem. The entire operation link will be shortened, the experience will be improved, and R&D efficiency will be improved.
The fourth is digital assets. In the past, everyone wrote code and put it there, and it turned into a mountain of code or liabilities. Of course, there are many outstanding gold mines that have not been unearthed, and there are still many documents that I want to find. The time can't be found.
But in the AI era, one of the most important things we do is to sort out our assets and documents, and empower large models through SFT and RAG, so that the large models become smarter and more in line with the personality of the enterprise. Therefore, today’s changes in human-computer interaction methods will bring about changes in experience.

Artificial intelligence breaks down the influencing factors just now. Its core is to bring about three changes in human-computer interaction methods. The first is that AI will become a Copilot, combined with tools, and then people can command it to help us complete some single-point tools. By the second stage, everyone should actually have a consensus. It becomes an Agent, which means that it has the ability to complete tasks independently, including writing code or doing tests independently. In fact, the tool acts as a multi-domain expert. We only need to give the context and complete the knowledge alignment. In the third stage, we judge that AI may become a decision-maker, because in the second stage the decision-maker is still a human. In the third stage, it is possible that the large model will have some decision-making capabilities, including more advanced information integration and analysis capabilities. At this time, people will focus more on business creativity and correction, and many things can be left to large models. Through this change in different man-machine modes, our overall work efficiency will become higher.

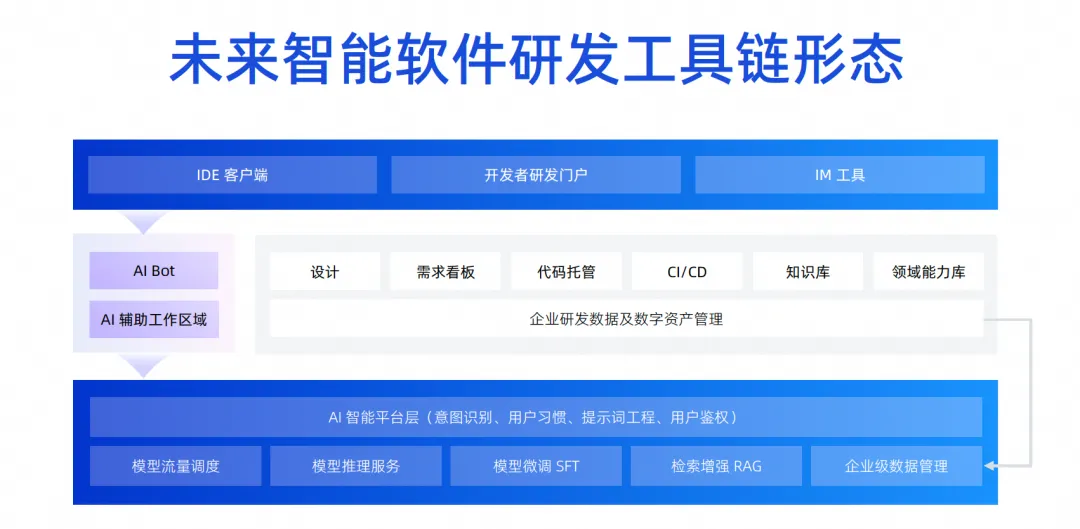
Another point is that the form of knowledge transfer we just talked about has also undergone fundamental changes. In the past, the problem of knowledge transfer was solved through word of mouth, training, and the old bringing the new. It is very likely that this will not be necessary in the future. We only need to equip the model with business knowledge and domain experience, and let every development engineer use intelligent tools. This knowledge can be transferred to the research and development process through the tools, and it will become the picture on the right. Shown above is now a one-stop tool chain for DevOps. After accumulating a large number of code and document assets, these assets are sorted out and put together with the large model. Through RAG and SFT, the model is embedded into each link of the DevOps tool, thereby generating more data, forming such a forward cycle. , in this process, front-line developers can enjoy the dividends or capabilities brought by the assets.
The above is my introduction from a macro perspective to the core factors affecting R&D efficiency of large models, as well as the two most important changes in form: the first is the change in the form of human-computer interaction, and the second is the change in the way knowledge is transferred. fundamental changes. Due to various technical limitations and problems in the development stage of large models, what we do best is the Copilot human-computer interaction mode, so next we will introduce some of our experience and how to create the best Copilot. Human-computer interaction mode.
Create your best Copilot pose
We believe that the human-computer interaction model of code development can currently only solve problems such as small tasks, problems that require manual adoption, and high-frequency problems, such as code completion. AI helps us generate a paragraph, we accept it, and then generate another paragraph. , let’s take another section. This is a very frequent problem, and there is also the problem of short output. We will not generate a project at once, or even generate a class at once. We will generate a function or a few lines every time. . Why do we do this? In fact, it has a lot to do with the limitations of the model's own capabilities.
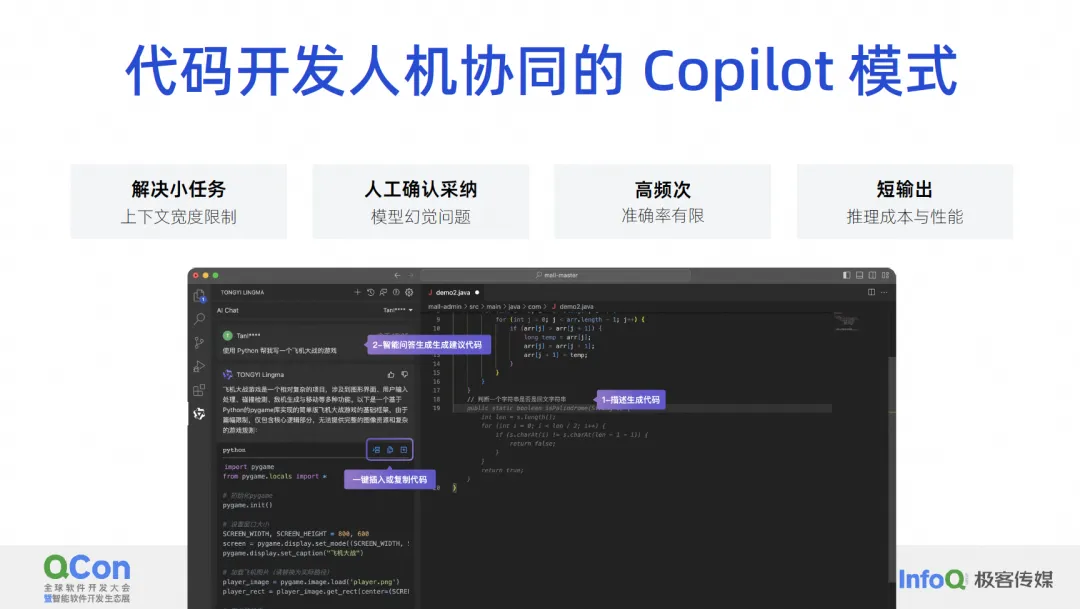
Because our current context width is still very limited, if we want to complete a requirement, there is no way to hand over all the background knowledge to it at once, so we can either use the Agent to break it into a bunch of small tasks and solve them step by step. Or let it complete the simplest task in Copilot mode, such as generating a small piece of code according to a comment. This is what we call solving small tasks.
In terms of manual adoption, humans now have to make judgments on the results generated by large code models. What we are currently doing well may be an adoption rate of 30%-40%, which means that more than half of our generated codes are actually inaccurate or do not meet developer expectations, so we must constantly eliminate illusion problems. .
However, the most important thing for large models to be truly usable at the production level is manual confirmation. Then, do not generate too many high-frequency models, but generate a little each time, because the cost of manually confirming whether this code is OK also affects performance. This article will talk about some of our thinking and what we do, and solve the problem of limited accuracy through high frequency. In addition, short output is mainly due to performance and cost issues.
The current model of code assistant actually hits some technical limitations of large models very accurately, so that such a product can be launched quickly. It has a very good opportunity. In our opinion, the Copilot model that developers like most is the following four keywords: high-frequency and rigid needs, within reach, knowing what I want, and exclusive to me.

The first one is that we need to solve high-frequency and urgently needed scenarios, so that developers can feel that this thing is really useful, not just a toy.
The second one is within reach, that is, it can be awakened at any time and can help us solve problems at any time. I no longer need to search for codes through various search engines like before. It is as if it is by my side and I can wake it up at any time to help me solve problems.
The third is to know what I think, that is, the accuracy of it answering my questions and the timing at which it answers my questions are very important.
Finally, it needs to belong to me. It can understand some of my private knowledge, rather than only understanding things that are completely open source. Let us discuss these four points in detail.
High frequency is just needed
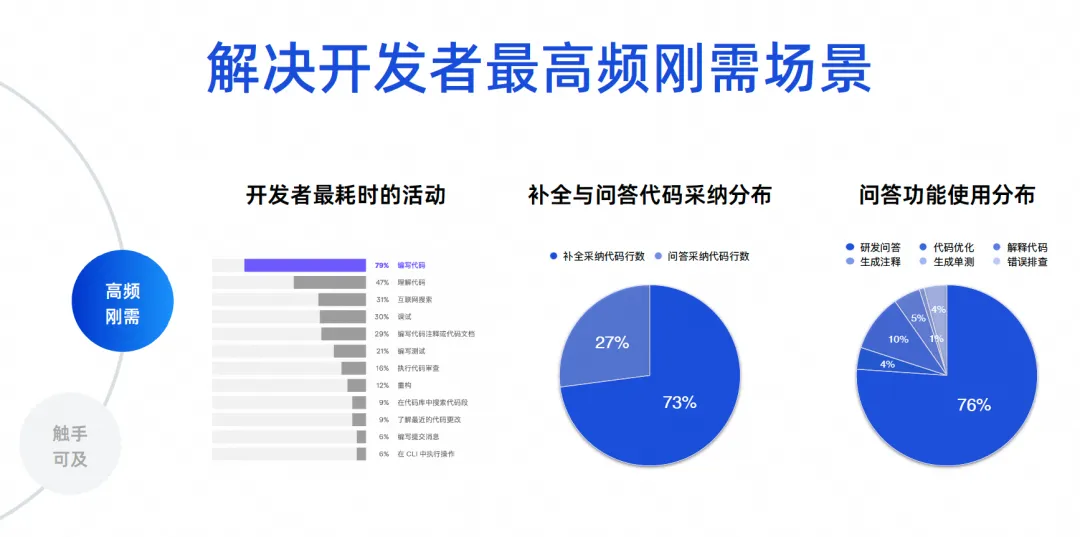
We need to determine what are the most frequent scenarios for software development. I have some real data here. The first data comes from a developer ecological report made by JetBrains in 2023, which compiled the most time-consuming activities of developers. It can be seen that 70% to 80% are writing Code, understand the code and search the Internet, debug, write comments, and write tests. These scenarios are actually the functions of code intelligence tools. The core problems that products like Tongyi Lingma solve are actually the most frequent problems.
The latter two data are data analysis of hundreds of thousands of users on Tongyi Lingma Online. 73% of the code we currently adopt online comes from completion tasks, and 27% comes from the adoption of question and answer tasks. So today, a large number of AIs replace people in writing code, and they are still generated between the lines of IDE. This is a result reflected from the real situation. Next is the proportion of using the Q&A function. 76% of the proportion comes from R&D Q&A, and the remaining 10% is a series of code tasks such as code optimization and code interpretation. Therefore, the vast majority of developers still use our tools to ask for some common R&D knowledge, or use natural language to generate some algorithms from large code models to solve some small problems.
The next 23% are our real detailed coding tasks. This is to give everyone a data insight. So we have our core goals. First, we need to solve the problem of code generation, especially between lines. Second, it is necessary to solve the accuracy and professionalism issues of R&D issues.
Within reach

What we ultimately want to talk about is creating an immersive programming experience. We hope that most of the problems faced by developers today can be solved within the IDE instead of having to jump out.
What has been our experience in the past? When you encounter a problem, you should search the Internet, or ask others, and then make your own judgment after asking around. Finally, write the code, copy it, put it in the IDE for debugging and compilation, and check again if it fails. This will be very time-consuming. We hope to be able to directly ask the big model in the IDE and let the big model generate code for me, so that the experience will be very pleasant. Through such a technical choice, we solved the problem of immersive programming experience.
The completion task is a performance-sensitive task, and its output needs to be in 300 to 500 milliseconds, preferably no more than one second, so we have a small parameter model, which is mainly used to generate code, and most of its training The corpus also comes from code. Although its model parameters are small, the accuracy of code generation is very high.
The second one is to do special tasks. We still have 20% to 30% of the actual tasks coming from these, including seven tasks such as annotation generation, unit testing, code optimization, and operational error troubleshooting.
We currently use a moderate parameter model. The main considerations here are, first, generation efficiency, and second, tuning. For a very large-parameter model, our tuning cost is very high, but on this medium-parameter model, its code understanding and code generation effects are already good, so we chose the medium-parameter model.
Then on large models, especially in answering more than 70% of our R&D questions, we pursue high accuracy and real-time knowledge. So we superimposed our RAG technology through a maximum parameter model, allowing it to plug in a near real-time Internet-based knowledge base, so the quality and effect of its answers are very high, and it can greatly eliminate model illusions and improve Answer quality. We support the entire immersive programming experience through three such models.

The second point is that we need to implement multiple terminals, because only by covering more terminals can we cover more developers. Currently, Tongyi Lingma supports VS code and JetBrains. It mainly solves triggering problems, display problems, and some interactivity problems.
At the core level, our local Agent service is an independent process. There will be communication between this process and the above plug-in. This process mainly addresses some core capabilities of the code, including code intelligent completion, session management, and agents.
In addition, syntax analysis services are also very important. We need syntax analysis to solve cross-file reference problems. If we want to enhance local retrieval, we also need a lightweight local vector retrieval engine. Therefore, the entire back-end service can actually be quickly expanded in this way.
We also have a feature. We have a small local offline model of a few tenths of a B to implement single-line completion in individual languages. This can be done offline, including JetBrains. Recently, JetBrains also launched a small model that runs locally. . In this way, some of our data security and privacy issues, such as local session management and local storage, are all placed on the local computer.

know what i think
I know what I think. Regarding the IDE plug-in tool, I think there are several points. The first is the triggering time. When it is triggered, it also has a great impact on the developer experience. For example, should I trigger it when I enter a space? Should it be triggered when the IDE has generated a prompt? Should it be triggered when deleting this code? We probably have more than 30 to 50 scenarios to sort out. Whether to trigger code in this scenario can be solved through rules. As long as we explore it carefully and investigate the developer experience, we can solve it. This is not Very profound technology.
But in terms of code generation length, we think it is more difficult. Because in different locations in different editing areas, the length of code it generates directly affects our experience. If developers only tend to generate a single line of code, the problem is that the developer cannot understand the entire generated content. For example, when generating a function, he does not know what the function is going to do, or when generating an if statement, he does not know what is inside the if statement. What is the business logic? There is no way to completely judge the functional units, which affects his experience.
If we use some fixed rules to do it, it will also cause a problem, that is, it will be relatively rigid. So our approach is actually based on the semantic information of the code. Through training and a large number of samples, the model understands how long it should be generated in what scenario today. We have implemented the model to automatically determine the class level, function level, The generation intensity at the logical block level and row level is called adaptive generation intensity decision-making. By doing a lot of pre-training, we allow the model to perceive, thus improving the accuracy of generation. We think this is also a key technical item.
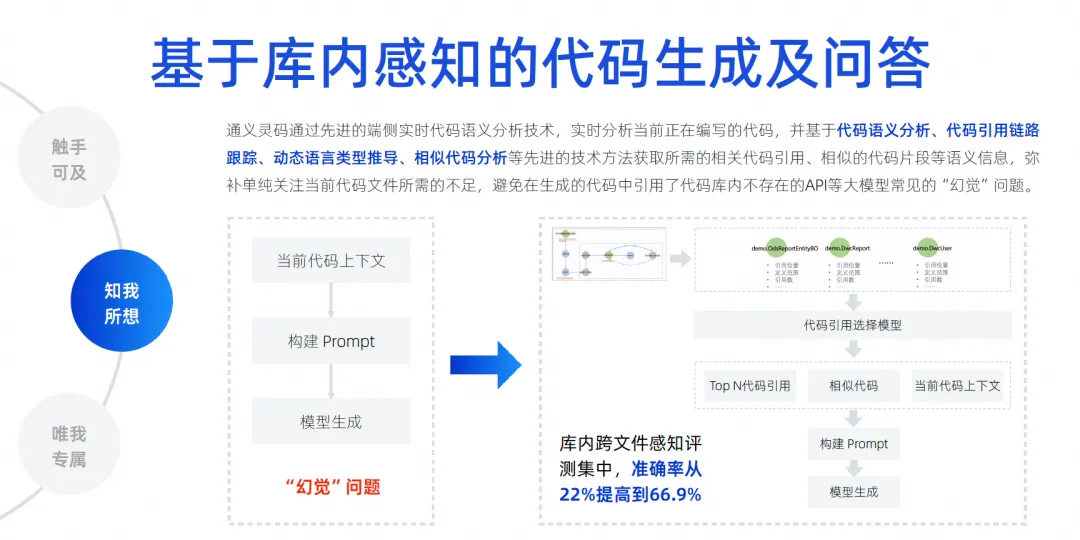
The most critical thing going forward is how to eliminate the illusion of the model, because only when the illusion is sufficiently eliminated can our adoption rate be improved. Therefore, we must implement cross-file context awareness within the library. Here, we do a lot of code-based semantic analysis, reference chain tracking, similar code, and dynamic language type derivation.
The most important thing is to try every means to guess what kind of background knowledge the developer may need to fill in this position. These things may also involve some languages, frameworks, user habits, etc. We use various things to combine it Get the context, prioritize it, put the most critical information into the context, and then give it to the large model for derivation, allowing the large model to eliminate illusions. Through this technology, we can achieve a cross-file context-aware test set. Our accuracy has increased from 22% to 66.9% . We are still constantly improving the completion effect.
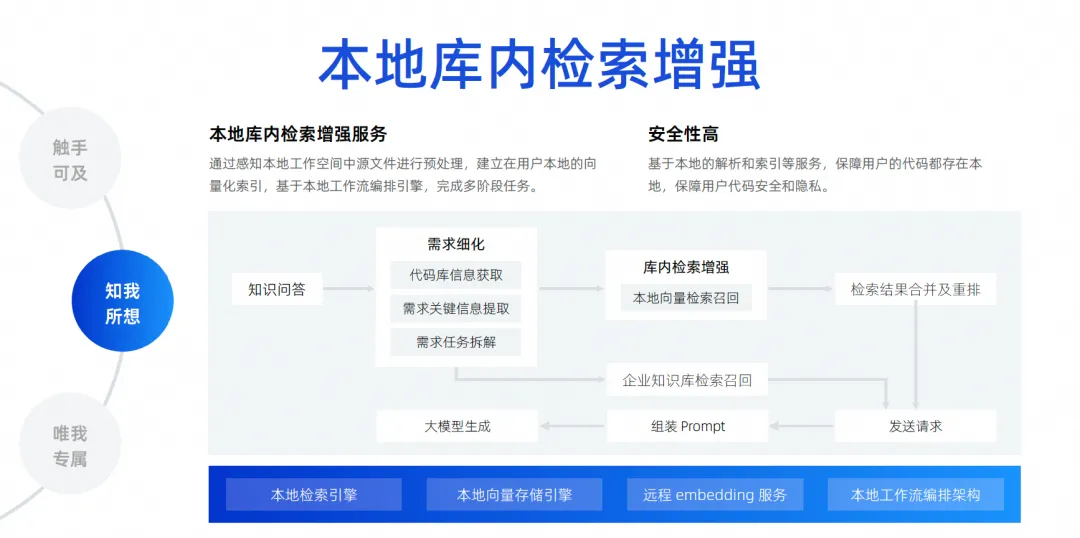
The last one is our local in-library search enhancement. As I just said, context awareness only guesses the developer's context at the trigger location. A more common scenario is that today developers want to ask a question, and let the large model help me solve a problem based on all the files in the local library, such as helping me fix a bug, help me add a requirement, help me fill in a file, and automatically Implementing additions, deletions, modifications, and searches, and even adding a new package version to my Pompt file. There are actually many needs like this. To achieve this, we actually need to plug in a search engine for the large model. Because it is impossible for us to stuff all the files of the entire project into the large model, due to the impact of context width, we must use a technology called local in-library search enhancement .
This function is to realize our free Q&A based on the library, and to establish a local search enhancement service in the library. We judge that this method is the best for developers’ experience and has the highest security.
The code does not need to be uploaded to the cloud to complete the entire link. From the perspective of the entire link, after a developer asks a question, we will go to the code base to extract the key information required to disassemble the task. After the disassembly is completed, we will perform local vector search and recall, and then merge and rearrange the search results. , and search the internal data knowledge base of the enterprise, because the enterprise has unified knowledge base management, which is enterprise-level. Finally, all the information is summarized and sent to the big model, so that the big model can generate and solve problems.

Only for me
I think if enterprises want to achieve a very good effect with large code models, they cannot escape this level. For example, how to realize personalized scenarios for enterprise data, for example, in the project management stage, how to generate large models according to some inherent formats and specifications of requirements/tasks/defect contents, helping us realize automatic disassembly and automatic renewal of some requirements. Writing, automatic summarization, etc.
The development stage may be what everyone pays the most attention to. Companies often say that they must have code specifications that conform to the company's own, reference the company's own second-party libraries, call APIs to generate SQL, including using some front-end frameworks, component libraries, etc. self-developed by the company. , these all belong to development scenarios. Test scenarios must also generate test cases that comply with enterprise specifications and even understand the business. In operation and maintenance scenarios, you should always look for the enterprise's operation and maintenance knowledge, and then answer questions to obtain some of the enterprise's operation and maintenance APIs to quickly generate code. These are the scenarios for enterprise data personalization that we believe we need to do. The specific approach is to achieve this through retrieval enhancement or fine-tuning training.
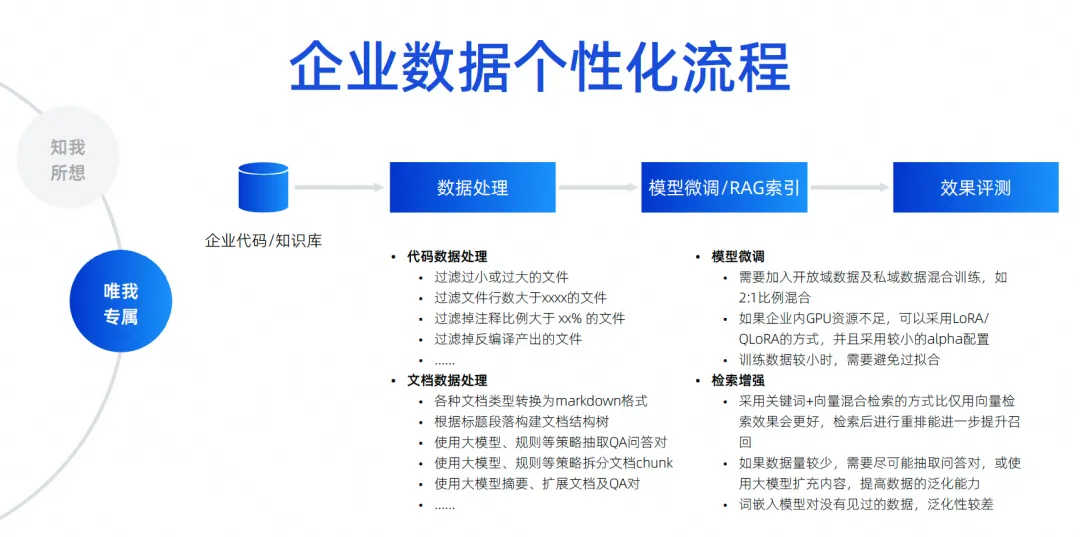
Here I have listed some simple scenarios and things to pay attention to, including how the code should be processed, how the documents should be processed, and the code must be filtered, cleaned, and structured before it can be used.
During our training process, we must consider the mixing of open domain data and private domain data. For example, we need to make some different parameter adjustments. In terms of retrieval enhancement, we have to consider different retrieval enhancement strategies. We are actually constantly exploring, including how to hit the contextual information we need in code generation scenarios, and How we hit the contextual information of the answers we need in the question and answer scenario is retrieval enhancement.
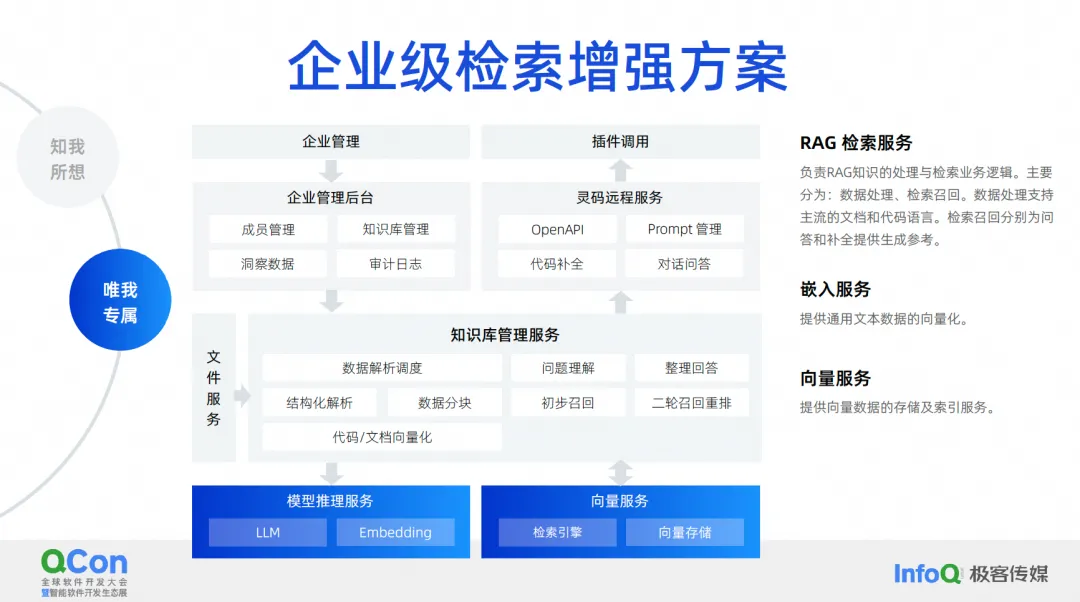
What we want to do is an enterprise-level retrieval enhancement solution . The current architecture diagram of the enterprise-level retrieval enhancement solution is roughly like this. In the middle is the management service of the knowledge base, including scheduling of data analysis, understanding of questions, organizing answers, structured analysis, data segmentation, etc. The core capabilities are in the middle, and downward are our more commonly used Embedding services. , including services for large models, storage and retrieval of vectors.
Upward are some backends we manage. In this scenario, they support our retrieval enhancement of documents and code generation retrieval enhancement. Code generation is to complete the retrieval and enhancement of this scenario. The processing methods and technologies required are actually slightly different from those of documents.
In the past, we have done academic research with Fudan University for several years, and we are very grateful for their efforts. We have also published some papers. At that time, the results of our test set were also based on a model of 1.1 to 1B, coupled with search enhancement, it actually The accuracy and effect can achieve the same effect as that of a 7B or above model.
Future software development agent product evolution
We believe that future software development will definitely enter the Agent era, which means that it has some autonomy, and it can use our tools very easily, then understand human intentions, complete the work, and eventually form a multi-purpose software as shown in the figure. Collaborative model of agents.

Just in March this year, the birth of Devin actually made us feel that this matter was really accelerated. We never imagined that this matter could complete a real business project. We had never imagined it in the past, and we even felt that This matter may still be a year away, but its emergence makes us feel that today we can really dismantle hundreds or thousands of steps through large models and execute them step by step. If problems arise, we can also self-reflect and iterate on ourselves. Such strong dismantling ability and reasoning ability surprised us very much.
With the birth of Devin, various experts and scholars began to invest, including our Tongyi Laboratory, which immediately launched a project called OpenDevin. This project has exceeded 20,000 stars in just a few weeks. It can be seen that everyone is very enthusiastic about this field. Then we immediately open sourced SWE's Agent project, pushing the SWE-bench solution rate to over 10%. Large models in the past were all in the range of a few percent, and pushing it to 10% is already close to Devin's performance, so we judged Academic research in this field can be very fast,
Let's make a bold guess. It is very likely that from June to September around the middle of 2024, the solution rate of SWE-bench will exceed 30%. Let's make a bold guess. If it can achieve a resolution rate of 50 to 60 percent, its test set is actually some real Github issues. Let AI complete the issues on Github, fix bugs, and solve such needs. test set. If this test set can make the autonomous completion rate of AI reach 50 or 60%, we think it can really be implemented at the production level. At least some simple defects can be fixed by it, which is some of the latest developments we have seen in the industry.
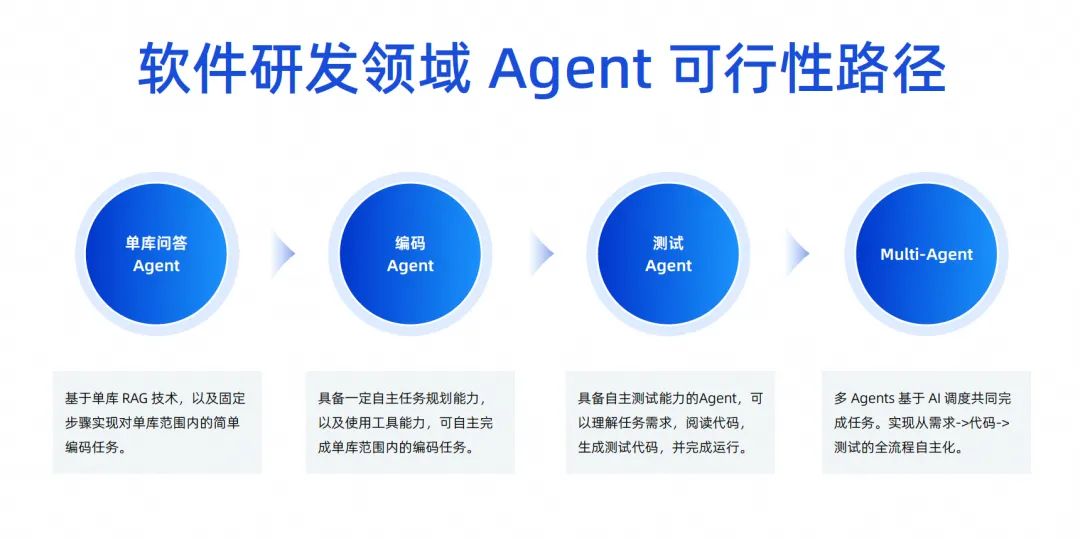
However, this picture cannot be realized immediately. From a technical perspective, we will gradually implement it in these four steps.
In the first step, we are still working on a single-database Q&A Agent. This field is very cutting-edge. We are currently working on a single-database Q&A Agent, which will be online in the near future.
In the next step, we hope to launch an Agent that can independently complete coding tasks. Its main role is to have a certain degree of independent planning capabilities. It can use some tools to understand background knowledge and can independently complete coding tasks within a single library, not across libraries. , you can imagine that a requirement has multiple code bases, and then the front end is also changed, and the back end is also modified, and finally a requirement is formed. We feel that it is still far away.
So we first implement the coding agent of a single library, and next we will do the testing agent. The testing agent can automatically complete some testing tasks based on the generated results of the coding agent, including understanding the requirements of the task, reading the code, generating test cases, and autonomously run.
If the success rate of these two steps is relatively high, we will move to the third step. Let multiple agents work together to complete tasks based on AI scheduling, thereby realizing the autonomy of the entire process from requirements to code to testing.
From an engineering point of view, we will proceed step by step to ensure that each step reaches a better production-level implementation and ultimately produce products. But from an academic perspective, their research speed will be faster than ours. Now we are discussing from academic and engineering perspectives, and we have a third branch which is model evolution. These three paths are some of the research we are currently doing together with Alibaba Cloud and Tongyi Lab.
Eventually, we will form a Multi-Agent conceptual architecture. Users can talk to the large model, and the large model can break down tasks, and then there will be a multi-Agent collaboration system. This Agent can plug in some tools and have its own running environment. Then multiple Agents can collaborate with each other, and they will also share some context mechanisms.
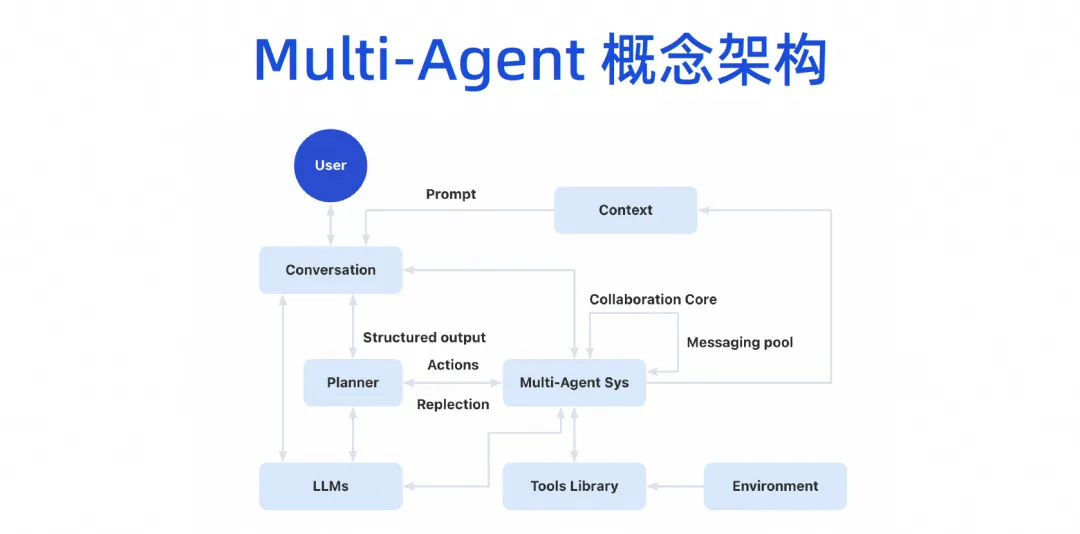
This product image will be divided into three layers. The bottom is the basic layer. For enterprises, the basic layer can be completed first. For example, a large code model can now be introduced. Although we have not implemented AI Bot immediately, we now have the capabilities of the IDE code generation plug-in and can already do some work, which is the Copilot model.
Copilot mode evolves the Agent layer above the infrastructure layer. In fact, the infrastructure can be reused. The retrieval enhancement, fine-tuning training and knowledge base that should be done can be done now. The sorting out of this knowledge and the accumulation of assets come from the accumulation of the original DevOps platform. Now you can combine the current basic capability layer with the entire DevOps tool chain through some prompt word projects.
We did some experiments. In the requirements stage, if we want this large model to realize automatic disassembly of a requirement, we may only need to combine some past disassembly data and current requirements into a prompt for the large model. The model can be disassembled and personnel assigned better. In the experiment, it was found that the accuracy of the results is quite high.
In fact, the entire DevOps tool chain does not require Agent or Copilot for everything. We now use some prompt word projects, and there are many scenarios that can be empowered immediately, including automatic debugging in our CICD process, intelligent question and answer in the knowledge base field, etc.
After implementing multiple agents, the agent can be exposed in the IDE, the developer's portal, the DevOps platform, or even our IM tool. It is actually an anthropomorphic intelligence. The agent itself will have its own workspace. In this workspace, our developers or managers can monitor how it helps us complete code writing, how it helps us complete testing, and how it is used on the Internet. What kind of knowledge is acquired to complete the work, it will have its own work space, and ultimately realize the complete process of the entire task.
Click here to experience Tongyi Lingma.
The Google Python Foundation team was laid off. Google confirmed the layoffs, and the teams involved in Flutter, Dart and Python rushed to the GitHub hot list - How can open source programming languages and frameworks be so cute? Xshell 8 opens beta test: supports RDP protocol and can remotely connect to Windows 10/11. When passengers connect to high-speed rail WiFi , the "35-year-old curse" of Chinese coders pops up when they connect to high-speed rail WiFi. MySQL's first long-term support version 8.4 GA AI search tool Perplexica : Completely open source and free, an open source alternative to Perplexity. Huawei executives evaluate the value of open source Hongmeng: It still has its own operating system despite continued suppression by foreign countries. German automotive software company Elektrobit open sourced an automotive operating system solution based on Ubuntu.