
Sharer: Zeng Qingguo |School: Southern University of Science and Technology
brief introduction
The slowdown of Moore's Law has promoted the development of non-traditional computing paradigms, such as customized Ising machines specifically designed to solve combinatorial optimization problems. This session will introduce new applications of P-bit based Ising machines for training deep generative neural networks, using sparse, asynchronous and highly parallel Ising machines to train deep Boltzmann networks in a mixed probabilistic-classical computing setting. .
Related papers
标题:Training Deep Boltzmann Networks with Sparse Ising Machines
作宇:**Shaila Niazi, Navid Anjum Aadit, Masoud Mohseni, Shuvro Chowdhury, Yao Qin, Kerem Y. Camsari
01
Purpose of the article
Goal: Demonstrate how to efficiently train sparse versions of deep Boltzmann networks using specialized hardware systems (e.g., P-bit) that provide orders of magnitude speedup over commonly used software implementations in computational hard probability sampling tasks;
Long-term goal: Help facilitate the development of physics-inspired probabilistic hardware to reduce the rapidly growing cost of traditional deep learning based on graphics and tensor processing units (GPU/TPU);
Difficulties in hardware implementation:
1. Connected p-bits must be updated serially, and updates are prohibited in dense systems;
2. Ensure that the p-bit receives all the latest information from its neighbor nodes before updating, otherwise, the network will not Sampling from a true Boltzmann distribution.
02
main content
The content of training deep Boltzmann networks using sparse Ising machines is mainly divided into four parts:
1. Network structure
2. Objective function
3. Parameter optimization
4. Inference (classification and image generation)
1. Network structure
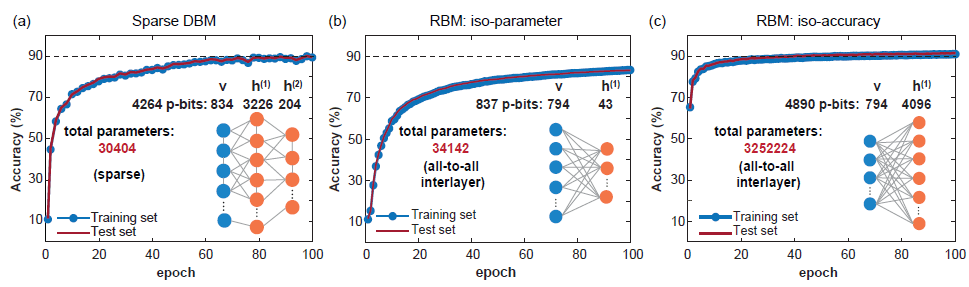
Pegasus and Zepyhr topologies developed by D-Wave are used to train hardware-aware sparse deep networks. This operation is inspired by extended but connection-constrained networks such as the human brain and advanced microprocessors. Despite the ubiquitous use of full connectivity in machine learning models, both advanced microprocessors and human brains with billions of transistor networks exhibit a large degree of sparsity. In fact, most hardware implementations of RBM face scaling problems due to the high computational responsibility required by each node, while sparse connections in hardware neural networks often show advantages. Moreover, the sparse network structure solves the above-mentioned hardware implementation difficulties well.
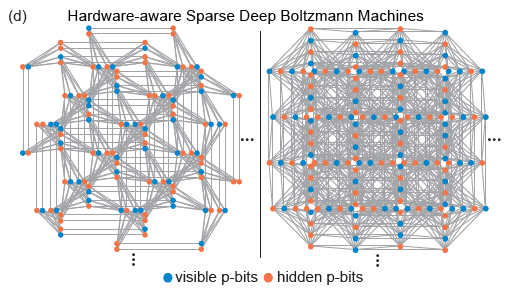
(Image source: arXiv:2303.10728)
2. Objective function
Maximizing the likelihood function is equivalent to minimizing the KL divergence between the data distribution and the model distribution:
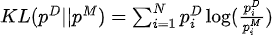
Among them,  is the data distribution and
is the data distribution and  is the model distribution.
is the model distribution.
The gradient of KL divergence with respect to the model parameters ( 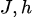 ) is:
) is:
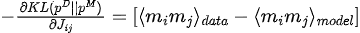
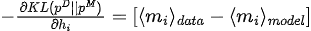
3. Parameter optimization

(Image source: arXiv:2303.10728)
Train network parameters according to Algorithm 1, including
-
Initialization of initialization parameters (
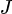 , );
, );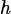
-
Use the training data to assign values to the input layer p-bits, and then perform MC sampling to obtain sampling samples of the data distribution;
-
Directly perform MC sampling to obtain sampling samples of the model distribution;
-
The gradient (called persistent contrastive divergence) is estimated using samples sampled in two stages, and the parameters are updated using the gradient descent method.
Among them, MC sampling uses p-bits iterative evolution:

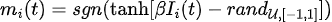
In the process of training sparse Boltzmann networks, there are two points to note:
-
1) Randomized p-bits index
When training a Boltzmann network model on a given sparse network, the graph distance between visible, hidden and label nodes is a very important concept. Normally, if the layer is fully connected, the graph distance between any given two nodes is constant, but this is not the case for sparse graphs, so the positions of visible, hidden, and label p-bits appear Extraordinarily important. If the visible, hidden and label p-bits are clustered and too close, the classification accuracy will be greatly affected. This is most likely because if the graphic distance between label bits and visible bits is too large, the correlation between them becomes weaker. Randomizing the p-bits index can alleviate this problem. -
-
(Image source: arXiv:2303.10728)
**2)大规模并行**
在稀疏深度玻尔兹曼网络上,我们使用启发式图着色算法DSatur对图着色,对于未连接p-bits进行并行更新。
-
-
(Image source: arXiv:2303.10728)
4. Inference
Classification: Use test data to fix visible p-bits, then perform MC sampling, and then obtain expectations for the obtained label-pbits, and take the label with the largest expected value as the predicted label
-
-
(Image source: arXiv:2303.10728)
Image generation: Fix the label p-bits to the encoding corresponding to the label you want to generate, then perform MC sampling, and anneal the network during the sampling process (gradually increasing from 0 to 5 in steps of 0.125), and the obtained samples correspond to The visible p-bits are the generated images.
-

-
(Image source: arXiv:2303.10728)
03
Summarize
The article uses a sparse Ising machine with a massively parallel architecture, which achieves sampling speeds orders of magnitude faster than traditional CPUs. The paper systematically studies the mixing time of hardware-aware network topologies and shows that the classification accuracy of the model is not limited by the computational operability of the algorithm, but by the moderately sized FPGA that was able to be used in this work. Further improvements may involve using deeper, broader, and possibly "harder to mix" network architectures that take full advantage of ultrafast probabilistic samplers. In addition, combining the layer-by-layer training technology of traditional DBM with the method of the article can bring further possible improvements. Implementing sparse Ising machines using nanoscale devices, such as random magnetic tunnel junctions, may change the current status of practical applications of deep Boltzmann networks.
A programmer born in the 1990s developed a video porting software and made over 7 million in less than a year. The ending was very punishing! Google confirmed layoffs, involving the "35-year-old curse" of Chinese coders in the Flutter, Dart and Python teams . Daily | Microsoft is running against Chrome; a lucky toy for impotent middle-aged people; the mysterious AI capability is too strong and is suspected of GPT-4.5; Tongyi Qianwen open source 8 models Arc Browser for Windows 1.0 in 3 months officially GA Windows 10 market share reaches 70%, Windows 11 GitHub continues to decline. GitHub releases AI native development tool GitHub Copilot Workspace JAVA is the only strong type query that can handle OLTP+OLAP. This is the best ORM. We meet each other too late.