
Author: Li Ruifeng
Paper title
Prototype Learning for Automatic Check-Out
Paper source
IEEE TMM
Paper link
https://ieeexplore.ieee.org/document/10049664/
code link
https://github.com/msfuxian/PLACO
昇思MindSpore作为一个开源的AI框架,为产学研和开发人员带来端边云全场景协同、极简开发、极致性能,超大规模AI预训练、极简开发、安全可信的体验,2020.3.28开源来已超过500万的下载量,昇思MindSpore已支持数百+AI顶会论文,走入Top100+高校教学,通过HMS在5000+App上商用,拥有数量众多的开发者,在AI计算中心,金融、智能制造、金融、云、无线、数通、能源、消费者1+8+N、智能汽车等端边云车全场景逐步广泛应用,是Gitee指数最高的开源软件。欢迎大家参与开源贡献、套件、模型众智、行业创新与应用、算法创新、学术合作、AI书籍合作等,贡献您在云侧、端侧、边侧以及安全领域的应用案例。
在科技界、学术界和工业界对昇思MindSpore的广泛支持下,基于昇思MindSpore的AI论文2023年在所有AI框架中占比7%,连续两年进入全球第二,感谢CAAI和各位高校老师支持,我们一起继续努力做好AI科研创新。昇思MindSpore社区支持顶级会议论文研究,持续构建原创AI成果。我会不定期挑选一些优秀的论文来推送和解读,希望更多的产学研专家跟MindSpore合作,一起推动原创AI研究,昇思MindSpore社区会持续支撑好AI创新和AI应用,本文是昇思MindSpore AI顶会论文系列第16篇,我选择了来自南京理工大学计算机科学与工程学院的魏秀参老****师团队的一篇论文解读,感谢各位专家教授同学的投稿。
昇思MindSpore旨在实现易开发、高效执行、全场景覆盖三大目标。通过使用体验,昇思MindSpore这一深度学习框架的发展速度飞快,它的各类API的设计都在朝着更合理、更完整、更强大的方向不断优化。此外,昇思不断涌现的各类开发工具也在辅助这一生态圈营造更加便捷强大的开发手段,例如MindSpore Insight,它可以将模型架构以图的形式呈现出来,也可以动态监控模型运行时各个指标和参数的变化,使开发过程更加方便。
本文主要涉及目标检测相关问题,通过目标检测实现对一幅图像中不同类别不同数量的零售商品的准确检测,最终可以得到“商品类别:商品数量”对应的购物清单。目标检测部分代码可以按照昇思MindSpore官方文档案例,或社区提供的目标检测相关代码和模型,可以轻松实现本文实验所需,十分方便快捷。
01
Research Background
Visual settlement of retail goods is a subfield of the smart retail industry. Its common application scenarios are areas with unmanned checkout counters such as supermarkets, stores, and convenience stores. Customers place the retail goods they want to purchase on the checkout counter, and then a Fixed-position cameras capture images of these retail items, which pass through an automatic visual checkout system that can identify product categories and accurately count them, and finally output a complete shopping list with the total amount.
The core of the retail product visual settlement task is to accurately identify and count retail products in the image. However, there are three main challenges in this task, namely, large-scale retail product data, domain gaps between single product examples and settlement images, and product category differences. Fine-grained properties. To address these challenges, Wei et al. proposed a baseline method for an object detection framework that bridges the differences and gaps between the two domains by synthesizing and rendering product checkout images from segmented single product examples. Similarly, IncreACO, DPNet and DPSNet improve the synthetic rendering strategy of Wei et al. to obtain better domain adaptability, thereby promoting the improvement of ACO accuracy. In addition, S2MC2 also uses the gradient inversion layer as the feature layer domain adaptation method, replacing the synthetic rendering strategy.
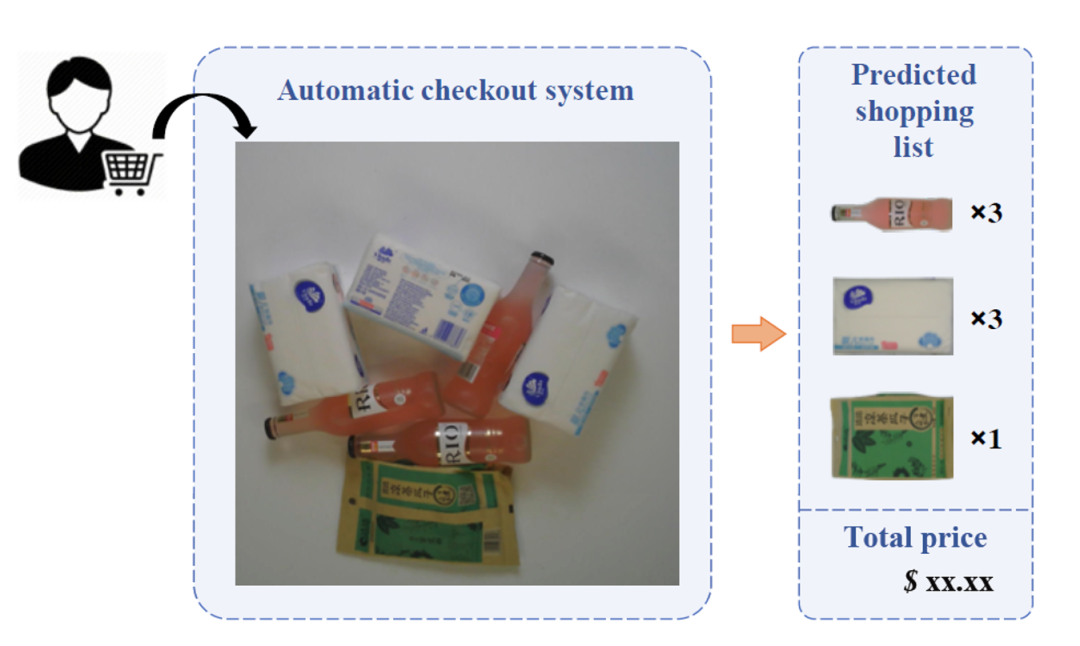
Figure 1 Schematic diagram of visual settlement of retail goods
02
team introduction
Visual Intelligence & Perception (VIP) Group, headed by Professor Wei Xiushen . The team has published in top international journals in related fields such as IEEE TPAMI, IEEE TIP, IEEE TNNLS, IEEE TKDE, Machine Learning Journal, "Chinese Science: Information Science", etc., and top international conferences such as NeurIPS, CVPR, ICCV, ECCV, IJCAI, AAAI, etc. He has published more than fifty papers, and related work has won a total of 7 world championships in authoritative international competitions in the field of computer vision, including DIGIX 2023, SnakeCLEF 2022, iWildCam 2020, iNaturalist 2019, and Apparent Personality Analysis 2016.
03
Introduction to the paper
In this paper, we propose a method called "Prototype Learning for Retail Merchandise Visual Checkout (PLACO)", which attempts to solve single-item examples (as training ) and the settlement image (as a test), the overall structure is shown in Figure 2. Specifically, a prototype is a vector representation that accurately represents the semantics of a category in visual space (i.e., a true category representation), typically implemented by category-specific feature centers. Another benefit of utilizing product prototypes for visual settlement of retail merchandise is that, in addition to potentially resolving domain differences, it avoids the multi-view problem of single product examples. Category prototypes more accurately represent a product's category semantics than single-view or multiple-view example images, which also proves its generality and robustness. Additionally, we designed a prototype alignment module as a domain adaptation solution. After obtaining single product examples and category prototypes in the settlement image domain, we achieve domain adaptation by reducing the distance between homogeneous prototypes and enlarging the distance between heterogeneous prototypes to enhance intra-category compactness and inter-category sparsity.
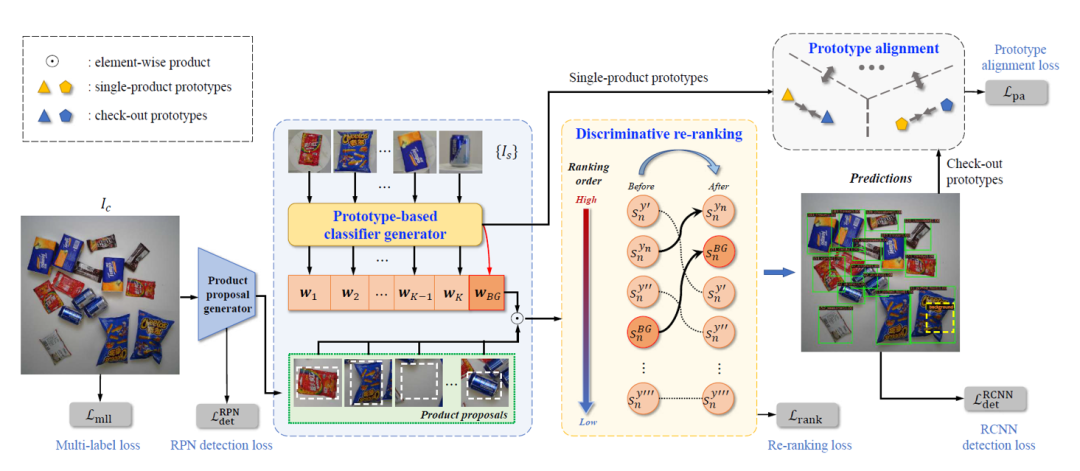
Figure 2 Schematic diagram of PLACO framework
To further improve the discriminative ability of these learned classifiers, we develop a discriminative rearrangement method to improve their discriminative ability by adjusting the prediction scores of these product recommendations, see Figure 3. Specifically, we rank the prediction score of the true category the highest to improve prediction confidence, while re-ranking the background score to the second position according to the characteristics of the background classifier, i.e., a hard rearrangement strategy. In addition, considering the fine-grained characteristics of items, we also introduce a slack variable as a soft rearrangement strategy to provide reasonable ranking possibilities for the prediction scores of fine-grained products. In addition, we added a multi-label recognition loss to PLACO to model the co-occurrence of items in checkout images, thereby further improving the accuracy of visual checkout of retail items.
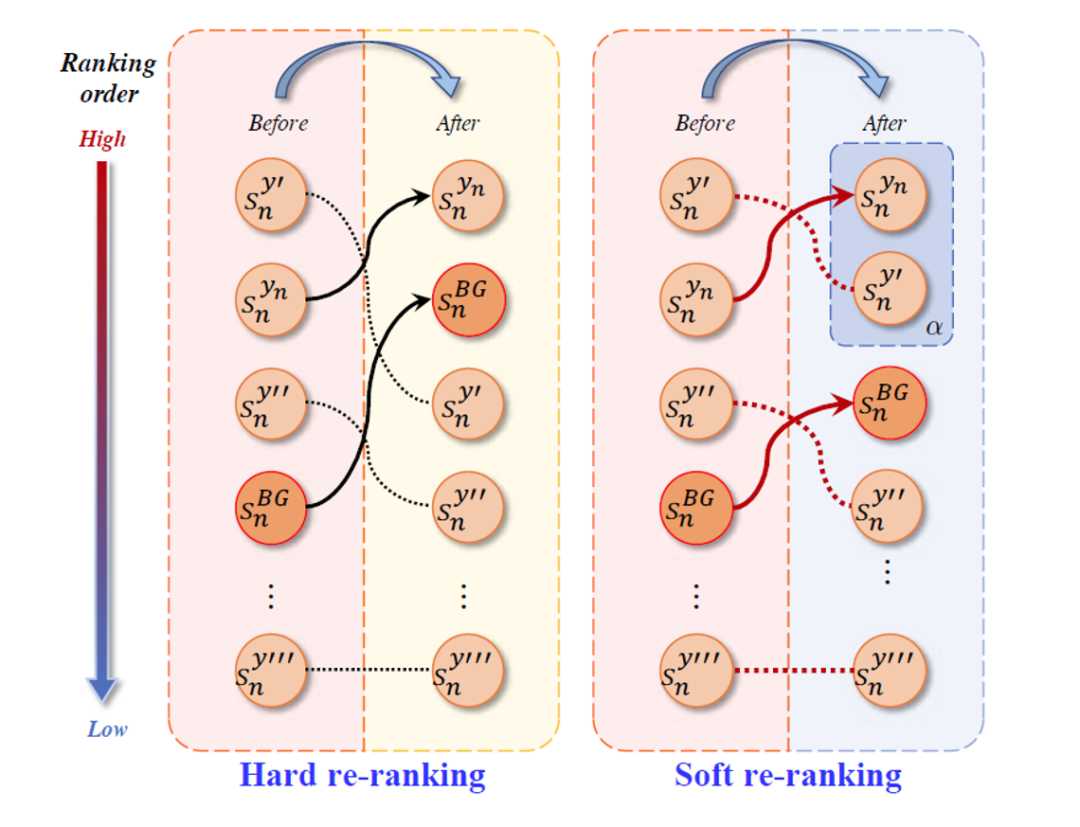
Figure 3 Schematic diagram of two discriminative rearrangement methods
04
Experimental results
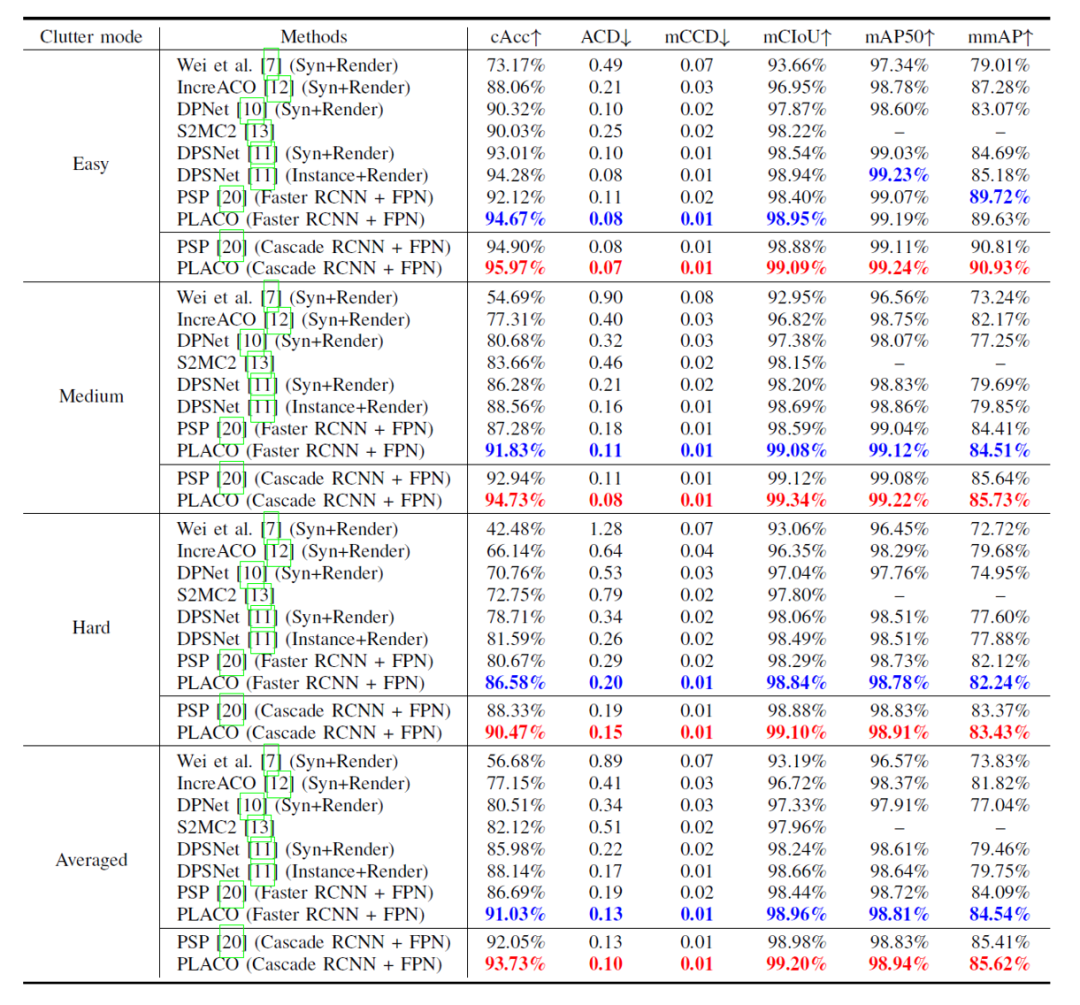
We conducted comparative experiments on the visual checkout performance of seven methods on the RPC data set. Among them, Wei et al.'s method, IncreACO, DPNet and DPSNet all use synthetic data and rendering data to jointly train. The target detection backbone framework of these methods is Faster RCNN or Mask RCNN; S2MC2 uses weaker point-level annotations for supervised training. It is a method of counting point-level objects based on density maps; PSP is the conference version method of PLACO in this article. PLACO has enhanced the prototype alignment module for PSP. Both methods have two target detection backbones, Faster RCNN and Cascade RCNN. Experimental results of the framework. Since the RPC data is divided into three levels: easy, medium and difficult according to the category and quantity of retail goods in the image, we also report the results of these three levels and the overall average result when reporting the experimental results.
It can be seen from the results that the PLACO method in this article has basically achieved the best results in both Faster RCNN and Cascade RCNN backbone target detection frameworks, especially in the main detection indicator settlement accuracy (cAcc). "↑" in the table indicates that the larger the result, the better the performance. "↓" indicates that the smaller the result, the better the performance. The best results based on the Faster RCNN framework are shown in bold blue, and the best results based on the Cascade RCNN framework are highlighted in red. Bold representation.
Table 1 Comparison results of visual settlement of retail goods using seven methods on the RPC data set
05
Summary and Outlook
This paper proposes a prototype learning method PLACO for automatic checkout, including a prototype-based classifier learning module, a discriminative rearrangement module and a prototype alignment module. The prototype-based classifier learning module was developed to implicitly alleviate the domain gap between the examples used as training and the checkout images used as testing. Furthermore, this paper adopts the prototype alignment module as an explicit domain adaptation solution. This paper designs a discriminative reranking method to improve the performance of PLACO by introducing more discriminative capabilities in classifier learning and fine-grained categories. This paper applies a multi-label loss to simulate the co-occurrence of products in checkout images. On the large-scale benchmark RPC data set, PLACO achieved a settlement accuracy of 91.03%, 2.89% higher than the previous best method. Since this article mainly involves mu table detection issues, you can easily implement the experiments required in this article according to the official MindSpore document cases or the target detection related codes and models provided by the community, which is very convenient and fast.
A programmer born in the 1990s developed a video porting software and made over 7 million in less than a year. The ending was very punishing! Google confirmed layoffs, involving the "35-year-old curse" of Chinese coders in the Flutter, Dart and Python teams . Daily | Microsoft is running against Chrome; a lucky toy for impotent middle-aged people; the mysterious AI capability is too strong and is suspected of GPT-4.5; Tongyi Qianwen open source 8 models Arc Browser for Windows 1.0 in 3 months officially GA Windows 10 market share reaches 70%, Windows 11 GitHub continues to decline. GitHub releases AI native development tool GitHub Copilot Workspace JAVA is the only strong type query that can handle OLTP+OLAP. This is the best ORM. We meet each other too late.