
Author: Lu Yufeng Source: Zhihu
Summary
MindNLP的开发大概也有小一年时间了,整体而言面临着诸多的问题,并且还伴随着LLM带来的一系列冲击和挑战。作为一个依赖昇思MindSpore向上生长的后来者NLP框架,其实也要考虑怎么扩大生态的问题。
As the saying goes - if you can't beat it, join it. But for the open source world, there is no need to talk about joining. It is normal for you to have me and you to be part of me. Moreover, at the moment when Pytorch2.1+Ascend was officially announced two days ago, ecological grafting is undoubtedly the best solution. Enough of the gossip and let’s get to the point.
01
MindNLP Datasets
MindNLP设计之初是希望尽可能全面利用昇思MindSpore的各个优势特性的,包括函数式融合编程、动态图功能、数据处理引擎等等。这里单独把数据处理引擎拎出来详细说说。
1.1MindSpore data processing engine
Figure 1: Schematic diagram of MindSpore data engine Pipeline
As shown in the figure, the design of the data engine is pipeline [1], which is very similar to Tensorflow's Dataset and Pytorch's Map-style Datasets, and is mainly aimed at high-performance data processing.
In an era when everyone is still making small model modifications and small data sets to refresh the rankings, data preprocessing is usually done offline, so that Python can be used to process it as flexibly as possible, and usually the large memory of the server can accommodate it. Everyone will stuff all the data in at once and then open multiple processes to process it. After that, load it into Tensor and send it to the network for training. But even so, if the data set is slightly larger, it may take hours or even days to preprocess the data set.
The Pipeline method focuses on several capabilities:
1. Load on demand
2. Asynchronous processing
3. Parallel
Among them, 1 and 2 can be discussed in detail. Taking text data as an example, if the simplest Python loading preprocessing logic (that is, Pytorch Dataloader) is used, the overall execution flow is as follows:
数据集全量加载至内存 -> 全量遍历并预处理 -> 单条数据打包Batch -> 循环返回每个Batch
The loading method of Pipeline is
A more vivid description is: There is now a pointer pointing to the beginning of the data set file. We fetch a batch size of data each time, and the pointer advances by the batch size until it is fetched.
Obviously, fetching only an appropriate amount of data each time can greatly reduce memory consumption, and the intermediate variables generated during the preprocessing process can also be compressed to a small size. In addition, this method can convert offline data preprocessing into online:
取Batch size条数据加载 -> Batch size条数据遍历并预处理 -> 返回一个Batch
Figure 2: Data processing and network computing pipeline
The data processing pipeline continuously processes data and sends the processed data to the cache on the Device side; after the execution of a Step, the data of the next Step is read directly from the cache of the Device. While the network is training, data is also being processed, each performing its own duties.
Of course, this method is also a double-edged sword. While improving memory utilization and performance, it will also introduce ease of use issues. The map in Figure 1 is asynchronous processing. After configuring each data preprocessing operation, it will not directly execute and return the results. This is not friendly to data that requires fine control and has many special conditions, and pipeline execution is very likely to occur. An abnormality is suddenly triggered.
However, LLM has changed this situation. All tasks have become Next Token Prediction, and all data processing has also become cleaning + Tokenize. The amount of data is huge and is often streaming data in business scenarios. Pipeline naturally becomes Optimal solution (this is probably the main reason why Pytorch started to make pipelines and HuggingFace datasets are also pipelines).
1.2MindNLP data set support issues
前面也提到,MindNLP的数据处理是完全使用了昇思MindSpore数据处理引擎的,并且一年内做了20+数据集的支持(对标torchtext)。但是实际使用过程中,显然各类NLP任务所需要的数据集绝不止这些,面对一个开放域很难去不停地做适配。
此外昇思MindSpore的Dataset也引发了一些问题,主要问题在于MindSpore Dataset设计了三类加载器,即:
1. Specific data set loader: such as IMDBDataset, EnWik9Dataset, etc.
2. Text abstract loader: TextFileDataset
3. User-defined loader: GeneratorDataset
If you use 1, it means that you need to continuously add adaptations; if you use 2, you need to preprocess formats such as xml, json, etc. before loading. This goes against the high-efficiency design concept of Pipeline, and you still face the need for manual adaptation. The amount of development; using 3 means that the first step in Figure 1 returns to full load, which is obviously not what we want. However, due to the need to quickly support the data set, we still chose the 1+3 method for support.
This is not efficient and requires a separate adaptation each time. So is there any permanent solution?
02
HuggingFace ecological grafting
MindNLP's data set loading wants to achieve nothing more than two things:
1. Support large data sets without adaptation
2. Use an efficient Pipeline
Since you can't do it yourself, let's rely on the power of ecology. In addition to the Transformers warehouse, HuggingFace has developed libraries for various processes of AI training. Datasets has been accumulated for several years and supports a large number of data sets. And because HuggingFace provides hosting services, many new data sets are also directly in the Datasets hub. Publish directly on. Using Datasets to solve problem 1, let’s look at the second problem.
In fact, most people who use MindSpore Dataset basically choose two processing methods:
1. Offline preprocessing to MindRecord, and then load using MindDataset
2. Load the data set into memory and then load it using a specific data set loader/GeneratorDataset
In order to be able to do online preprocessing, method 1 is obviously not advisable, so the idea of grafting HuggingFace Datasets is also very simple. I have considered two ideas and will discuss them below.
2. 1 Grafting data set download
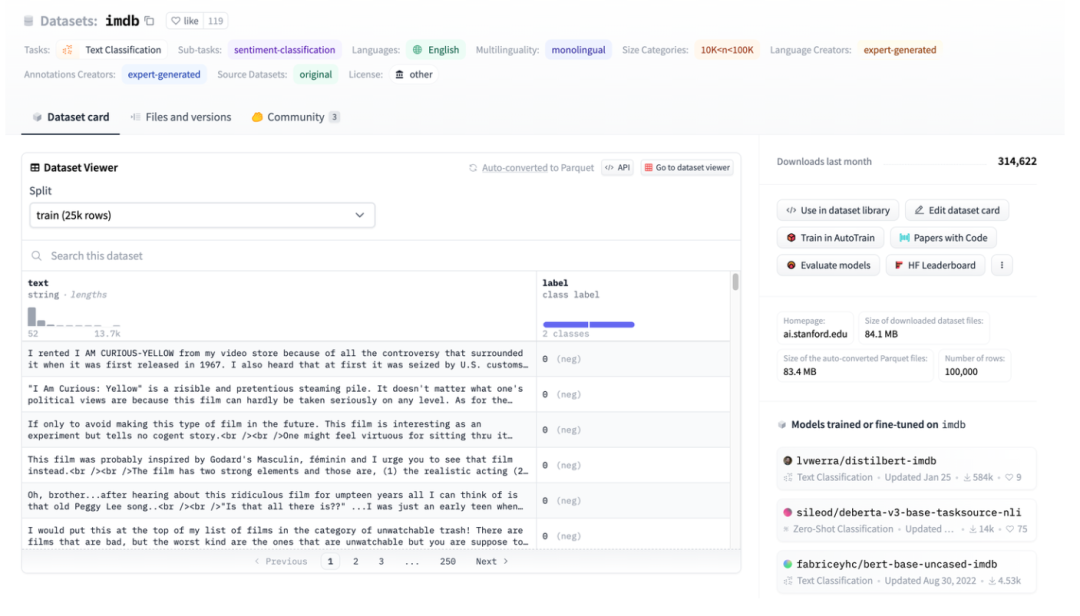 Figure 3: Illustration of HuggingFace Dataset, taking IMDB as an example
Figure 3: Illustration of HuggingFace Dataset, taking IMDB as an example
Figure 3 is a screenshot of the imdb page. You can see that the data has been well structured. Then use HuggingFace Datasets to download directly, and then directly use the abstract data loader TextFileDataset to read the processed files directly. for use.
Figure 4: TextFileDataset interface
You can see that TextFileDataset only needs to pass in the file path or path list to load. However, I encountered a problem during practical operation-HuggingFace Datasets uses Apache Arrow files.
Figure 5: Introduction to Arrow format of HuggingFace Datasets
Apache Arrow[2] is a language-independent, multi-system high-performance data exchange format standard that can be zero copied. This means that MindSpore's Dataset cannot be read directly and simply. Although it can also be operated using the pyarrow library, this increases the complexity and returns to a state that requires preprocessing before loading. However, it turns out that the characteristics of Arrow files are more suitable for MindSpore's Dataset.
2. 2 Advantages of Arrow format
In the Multiwalker environment, bipedal robots try to carry their cargo and walk to the right. Several robots carry a large cargo, and they need to work together, as shown in the picture below.
HuggingFace uses the Apache Arrow format, which has several obvious advantages:
1. Arrow’s standard format allows zero-copy reads, which virtually eliminates all serialization overhead.
2. Arrow is column-oriented, so querying and processing data slices or data columns is faster.
3. Arrow treats each data set as a memory-mapped file. When accessing partial data in a large file, it is not necessary to load the entire file, and multiple processes can share memory. Memory mapping allows the use of large datasets on machines with relatively small device memory; loading the complete English Wikipedia dataset requires only a few MB of RAM.
4. When loading data, you can set the streaming parameters for streaming loading.
At this time, let’s go back and look at the design of the MindSpore data engine: on-demand loading, online processing, and HuggingFace Datasets are a perfect match.
2.3 MindNLP adaptation
Since the arrow file loaded by HuggingFace Datasets itself is a memory mapped file, there is no need to copy it to the memory, and using the index index will not fully load it, so it can be directly used as the source loading data and sent directly to the GeneratorDataset for use. .
Figure 6: GeneratorDataset interface
The construction of GeneratorDataset mainly requires source data and the column name corresponding to each column of data. Looking back at Figure 3, you can see that HuggingFace Datasets has named all columns. The following is the core code intercepted:
from mindspore.dataset import GeneratorDataset
from datasets import load_dataset as hf_load
......
def load_dataset(...):
ds_ret = hf_load(path,
name=name,
data_dir=data_dir,
data_files=data_files,
split=split,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
keep_in_memory=keep_in_memory,
save_infos=save_infos,
revision=revision,
streaming=streaming,
num_proc=num_proc,
storage_options=storage_options,
)
if isinstance(ds_ret, (list, tuple)):
ds_dict = dict(zip(split, ds_ret))
else:
ds_dict = ds_ret
datasets_dict = {}
for key, raw_ds in ds_dict.items():
column_names = list(raw_ds.features.keys())
source = TransferDataset(raw_ds, column_names) if isinstance(raw_ds, Dataset) \
else TransferIterableDataset(raw_ds, column_names)
ms_ds = GeneratorDataset(
source=source,
column_names=column_names,
shuffle=shuffle,
num_parallel_workers=num_proc if num_proc else 1)
datasets_dict[key] = ms_ds
if len(datasets_dict) == 1:
return datasets_dict.popitem()[1]
return datasets_dict
The processing steps are also very simple:
1. Load using load_dataset of HuggingFace Datasets
2. Use encapsulated transit classes for encapsulation
3. Pass in GeneratorDataset
为了易用性的考虑,我们保持load_dataset接口的参数设置和HuggingFace Datasets完全一致,但是返回的是MindSpore数据引擎可处理的类或Dict,这样即可完成昇思MindSpore数据处理能力的无缝衔接。
Let’s briefly talk about the structure of the transit class.
The data types of HuggingFace Datasets include Dataset and IterableDataset:
There are two types of dataset objects, a Datasetand an IterableDataset. Whichever type of dataset you choose to use or create depends on the size of the dataset. In general, anIterableDatasetis ideal for big datasets (think hundreds of GBs!) due to its lazy behavior and speed advantages, while Datasetis great for everything else. This page will compare the differences between Datasetand anIterableDatasetto help you pick the right dataset object for you.[3]
When traversing these two types of data sets, a dict is returned, which is not supported by MindSpore's data processing engine. Therefore, two transfer classes are made to read the data in the dict without adding other additional operations. For Dataset, construct a TransferDataset class and read it in the __getitem__ method.
class TransferDataset():
"""TransferDataset for Huggingface Dataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __getitem__(self, index):
return tuple(self.ds[int(index)][name] for name in self.column_names)
def __len__(self):
return self.ds.dataset_size
For streaming data IterableDataset, you need to read it in the __iter__ method and construct TransferIterableDataset as an iterable object.
class TransferIterableDataset():
"""TransferIterableDataset for Huggingface IterableDataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __iter__(self):
for data in self.ds:
yield tuple(data[name] for name in self.column_names)
At this point, a plan that requires little effort and can completely graft HuggingFace Datasets has been completed. Compared with Paddle NLP, the grafting strategy is simple and elegant.
03
in conclusion
作为一个开源框架其实有大量的开源资源可以利用,所谓的南北向生态的不断扩展,也未必就是适配,我用用你你用用我,快快乐乐没有烦恼。本次HuggingFace Datasets嫁接到昇思MindSpore实操分享中,将对昇思MindNLP有了更深刻的认知,也有利于拓展昇思MindSpore生态。
references
[1]https://www.mindspore.cn/docs/zh-CN/r2.1/design/data_engine.htm
[3]https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable
A programmer born in the 1990s developed a video porting software and made over 7 million in less than a year. The ending was very punishing! Google confirmed layoffs, involving the "35-year-old curse" of Chinese coders in the Flutter, Dart and Python teams . Daily | Microsoft is running against Chrome; a lucky toy for impotent middle-aged people; the mysterious AI capability is too strong and is suspected of GPT-4.5; Tongyi Qianwen open source 8 models Arc Browser for Windows 1.0 in 3 months officially GA Windows 10 market share reaches 70%, Windows 11 GitHub continues to decline. GitHub releases AI native development tool GitHub Copilot Workspace JAVA is the only strong type query that can handle OLTP+OLAP. This is the best ORM. We meet each other too late.