
Database indexes are a key component in optimizing the performance of any database system. Without effective indexes, your database queries can become slow and inefficient, resulting in a poor user experience and reduced productivity. In this article, we'll explore some best practices for creating and using database indexes.
Author: The Java Trail
Source of this article and cover: https://medium.com/, translated by the Axon open source community.
This article is about 2,700 words and is expected to take 9 minutes to read.
Various indexing algorithms are used in databases to improve query performance. Here are some of the most commonly used indexing algorithms:
B-Tree index
A B-Tree index is a self-balancing tree data structure that maintains data ordering and allows searches, sequential access, insertions, and deletions in logarithmic time. B-Tree index structure is widely used in databases and file systems. B-Tree indexes are widely used in relational databases such as MySQL and PostgreSQL.
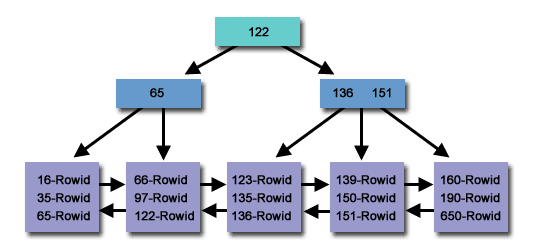
B-Tree indexes are optimized for range queries because they can efficiently find all records within a range of values. This is because records are stored in sorted order in the index. Take advantage of using column comparisons in expressions that use the =, >, >=, <, <=or BETWEENoperators.
For example, assume we have a products table with the following table structure:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
priceWe can add a B-Tree index to the field through the following SQL statement .
CREATE INDEX products_price_index ON products (price);
Hash index
Hash indexes are another popular indexing algorithm used to speed up queries. Hash indexes use a hash function to map keys to index locations. This indexing algorithm is most useful for exact match queries, such as searching for specific records based on primary key values . Hash indexes are commonly used in in-memory databases such as Redis.
Hash indexes work by mapping each record in the table to a unique bucket based on its hash value. Hash values are calculated using a hash function, a mathematical function that takes a data item as input and returns a unique integer value.
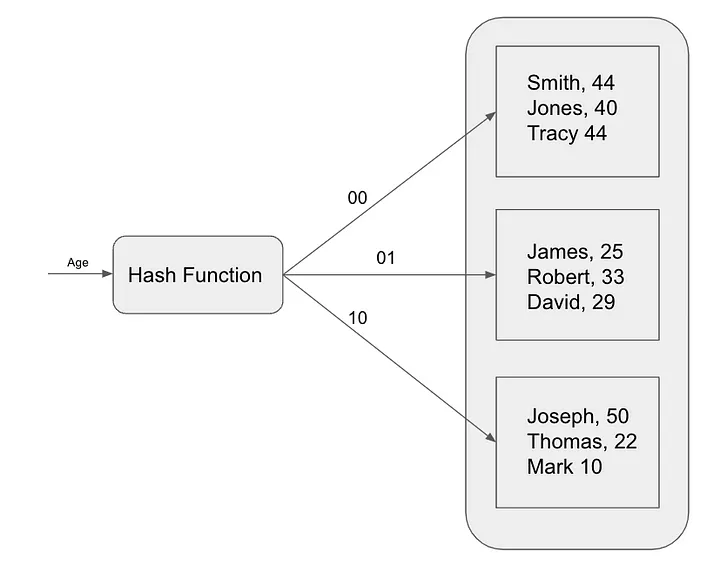
To find a record in a hashed index, the database calculates the hash of the search key and then looks up the corresponding bucket. If the record is in the bucket, the database will return the record. Otherwise, the database performs a full table scan.
Hash indexes are very fast for lookups , but they cannot be used to efficiently query ranges of data . This is because hash functions do not preserve any order between records in the table.
To execute a query using a hash index:
- The database calculates the hash value of the query criteria.
- Find the corresponding hash bucket in the hash table.
- The database then retrieves a pointer to the row in the table with the corresponding hash value.
- Use these pointers to retrieve the actual rows from the table.
Suppose we have a products table with the following table structure:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
Q: Are hash indexes not optimized like B-Tree?
There are some situations where a hash index might not be the best choice:
- Hash indexes are faster than tree indexes for lookups (for equality comparisons using the
=or<=>operator), but they cannot be used to efficiently query ranges of data. - Tree indexes are slower than hash indexes when searching, but they can be used to efficiently query ranges of data.
Range queries: Hash indexes are not optimized for range queries, where you need to find records within a range of values (using the =, >, >=, <, <=or BETWEENoperators). In this case, a B-Tree index would be more appropriate.
Sorting: Hash indexes are not optimized for sorting, you need to sort the records based on a specific column. In this case, a B-Tree index or a clustered index would be more suitable.
Large datasets: Hash indexes can be memory-intensive, so they may not be suitable for large datasets where memory usage is a concern.
We can namecreate a hash index on the column using the following command:
CREATE INDEX products_name_hash ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
CREATE INDEX products_name_tree ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
If we use a hash index, the database will calculate the hash value of the search key "iPhone 13 Pro" and then look up the corresponding bucket. Because hash functions are deterministic, the database will always find records in the same bucket, regardless of the order in which the records are stored in the table.
If we use a tree index, the database will start at the root of the tree and compare the search key "iPhone 13 Pro" with the value of the key stored at the root . Since the tree is sorted, the database will quickly find the record containing the search key.
Q: Why is B-Tree more optimized for Range queries than Hash index?
Now, let's say we want to find all products with a price between $100 and $200. We can use the following query:
SELECT * FROM products WHERE price BETWEEN 100 AND 200;
working principle
B-Tree
B-Tree indexes work by storing records in sorted order. To find records in a B-Tree index,
- The database starts at the root of the tree and compares the search key to the value of the key stored at the root.
- If the search key equals the root key, the database returns that record.
- Otherwise, the database determines which subtree to search next based on the comparison results.
Hash
Hash indexes work by mapping each record in a table to a unique bucket based on its hash value. The hash value is calculated using a hash function. Hash indexes randomly distribute data across buckets, making range queries inefficient. Retrieving a range of values, such as prices between $100 and $200, requires scanning all buckets in that range, which effectively results in a full table scan. Hash indexes are good at fast exact match lookups, but lack the data ordering required for efficient range queries.
Question, why is the B-Tree index more optimized than the Hash index in sorting?
B-Tree tree indexes sort data more efficiently than hash indexes because they store records in sorted order. This allows the database to quickly iterate through records in sorted order.
Hash indexes work by mapping each record in a table to a unique bucket based on its hash value. This means that the order of records in the bucket is random. To sort the records, the database needs to iterate through all buckets and then sort the records in each bucket. This is slower than using a B-Tree index, which stores records in sorted order.
We can pricecreate a B-Tree index on the column using the following command:
CREATE INDEX products_price_index ON products (price);
Now, let's say we want to sort products by price in ascending order. We can use the following query:
SELECT * FROM products ORDER BY price ASC;
The database will use a B-tree index to quickly iterate over products in sorted order.
Disadvantages of hash index:
- Hash indexes do not support range queries or sorting
- Hash indexes consume a lot of memory
- Hash indexes are not suitable for frequently updated databases
Bitmap index
Bitmap indexes are used for columns with a small number of distinct values, such as Boolean or gender columns. Bitmap indexes are very compact and efficient for lower cardinality columns.
SELECT * FROM employees WHERE gender = 'Female';
Bitmap indexes are very efficient on lower cardinality columns, allowing fast set operations such as unions and intersections. Ideal for ad hoc reporting and data warehousing.
Full-text index
Full-text indexing is used to index large amounts of text data, such as documents or web pages. This indexing algorithm breaks text into words or tokens and indexes them in a way that allows efficient search operations. Full-text indexes are most useful for queries that involve searching for specific words or phrases in text. Full-text indexing is commonly used in search engines such as Elasticsearch.
Use cases for e-commerce full-text indexing:
Full-text indexing allows e-commerce applications to quickly search large product catalogs based on user-entered search queries. Full-text indexing allows searching based on multiple words and phrases, including misspellings, synonyms, and even related concepts. This makes it easier for users to find what they are looking for, even if they don't know the exact product name or description.
For example, imagine a customer is looking for a new pair of running shoes. They type "running shoes" into the search bar. With full-text indexing, e-commerce applications can quickly search all product descriptions, names, and labels to find all products related to running shoes. Search results are sorted by relevance, which is determined by how often the search terms appear in product information.
Without full-text indexing, a search may only look at the product name, without taking into account other factors that may be relevant to customers, such as product descriptions or labels. Additionally, the search may not handle misspellings or related concepts, such as "jogging shoes" or "sneakers."
Suppose we have a productstable named with the following columns: id, name, descriptionand tags.
CREATE FULLTEXT INDEX products_ft_index ON products(name, description, tags);
Now, imagine a customer searches for "running shoes." We can use the following query to search for products related to the search term:
SELECT id, name, description, MATCH(name, description, tags) AGAINST('running shoes') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('running shoes' IN BOOLEAN MODE)
ORDER BY relevance DESC
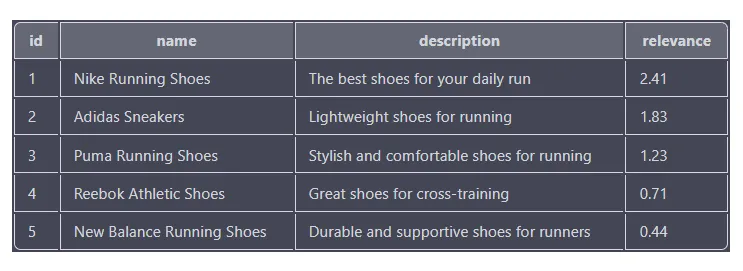
Relevance scores are based on how well each product matches the search terms, with higher scores indicating a closer match. The results are sorted in descending order based on relevance score, so the product with the highest relevance score (Nike running shoes) appears at the top of the list.
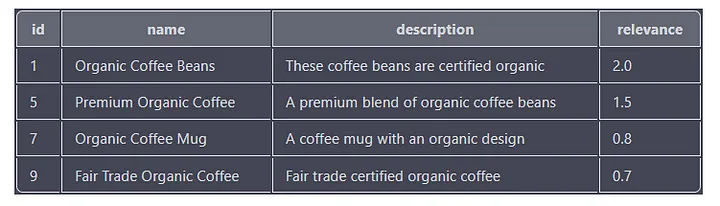
Here's another example query that searches for products containing the words "organic" and "coffee":
SELECT id, name, description, MATCH(name, description, tags) AGAINST('+"organic" +"coffee"') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('+"organic" +"coffee"' IN BOOLEAN MODE)
ORDER BY relevance DESC;
This query is searching for all products that have both the "organic" and "coffee" keywords in the name, description, or label columns. The relevance score of each result is also calculated based on the number of times and position of the keyword in the column.
The output will contain the "id", "name", "description" and "relevance" columns, with the results sorted by the "relevance" column in descending order.
advantage
- Full-text indexes work very well for text-based columns
- Great for search engines and content management systems
- Supports relevance ranking of search results
shortcoming
- Full-text indexing takes up a lot of storage space
- For very large data sets, performance may degrade
- Full-text indexing is not suitable for numeric or categorical data
For more technical articles, please visit: https://opensource.actionsky.com/
About SQLE
SQLE is a comprehensive SQL quality management platform that covers SQL auditing and management from development to production environments. It supports mainstream open source, commercial, and domestic databases, provides process automation capabilities for development and operation and maintenance, improves online efficiency, and improves data quality.
SQLE get
| type | address |
|---|---|
| Repository | https://github.com/actiontech/sqle |
| document | https://actiontech.github.io/sqle-docs/ |
| release news | https://github.com/actiontech/sqle/releases |
| Data audit plug-in development documentation | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |