
Just last week, we announced the GreptimeDB 2024 roadmap, revealing several major version plans for GreptimeDB this year. With the arrival of early spring in March, the first open source version of GreptimeDB suitable for production level has also arrived as scheduled during the "Jingzhe" season when everything recovers. v0.7 marks an important step towards a production-ready version, and we welcome every member of the community to actively participate and provide valuable feedback.
从 v0.6 到 v0.7,Greptime 团队取得了显著的进步:累计合并了 184 个 Commits,修改了 705 个文件,包括 82 项功能增强、35 项 Bug 修复、19 次代码重构,以及大量的测试工作。 这期间,一共有 8 名独立贡献者参与 GreptimeDB 的代码贡献,特别感谢 Eugene Tolbakov 作为 GreptimeDB 首位 committer,持续活跃在 GreptimeDB 的代码贡献中,和我们一同成长!
更新重点(省流版) Metric Engine:针对可观测场景设计的全新引擎可被推荐使用,能处理大量的小表,适合云原生监控场景; Region Migration:优化了使用体验,可以通过 SQL 方便地执行 Region 迁移; Inverted Index:高效定位用户查询所涉及数据段,显著减少扫描数据文件所需 IO 操作,加速查询过程。
v0.7 is one of the few major version updates since GreptimeDB was open sourced. This time we will also broadcast it live on the video account. To learn more about functional details, watch demo demonstrations, or have in-depth discussions with our core development team, welcome to join the live broadcast at 19:30 pm next Thursday (March 14).
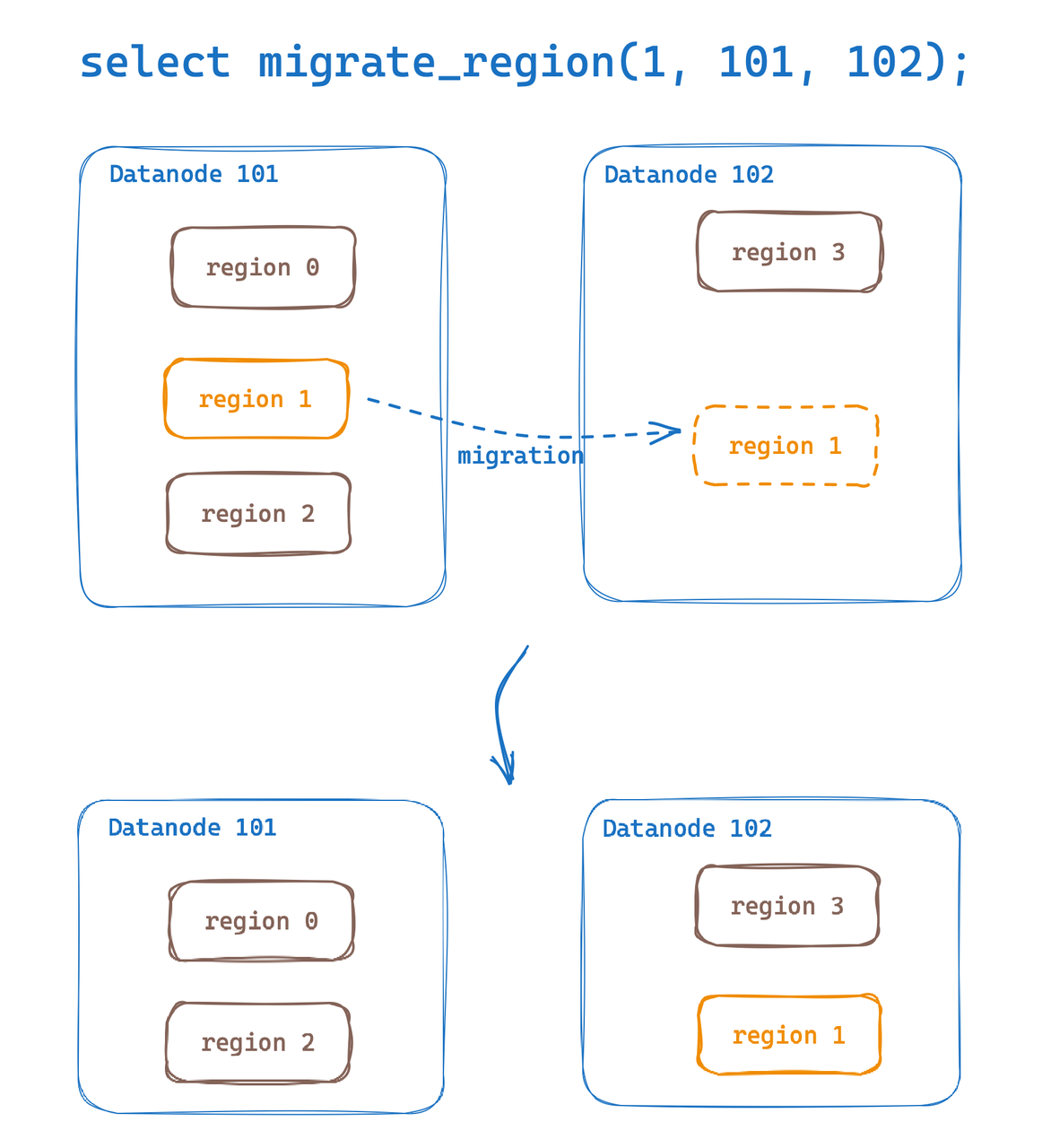
Region Migration
Region Migration provides the ability to migrate regions of data tables between Datanodes. With this capability, we can easily implement hotspot data migration and horizontal expansion of load balancing. GreptimeDB mentioned that Region Migration was initially implemented when v0.6 was released. This version update improves and optimizes the user experience.
Now, we can easily perform Region migration via SQL:
select migrate_region(
region_id,
from_dn_id,
to_dn_id,
[replay_timeout(s)]);
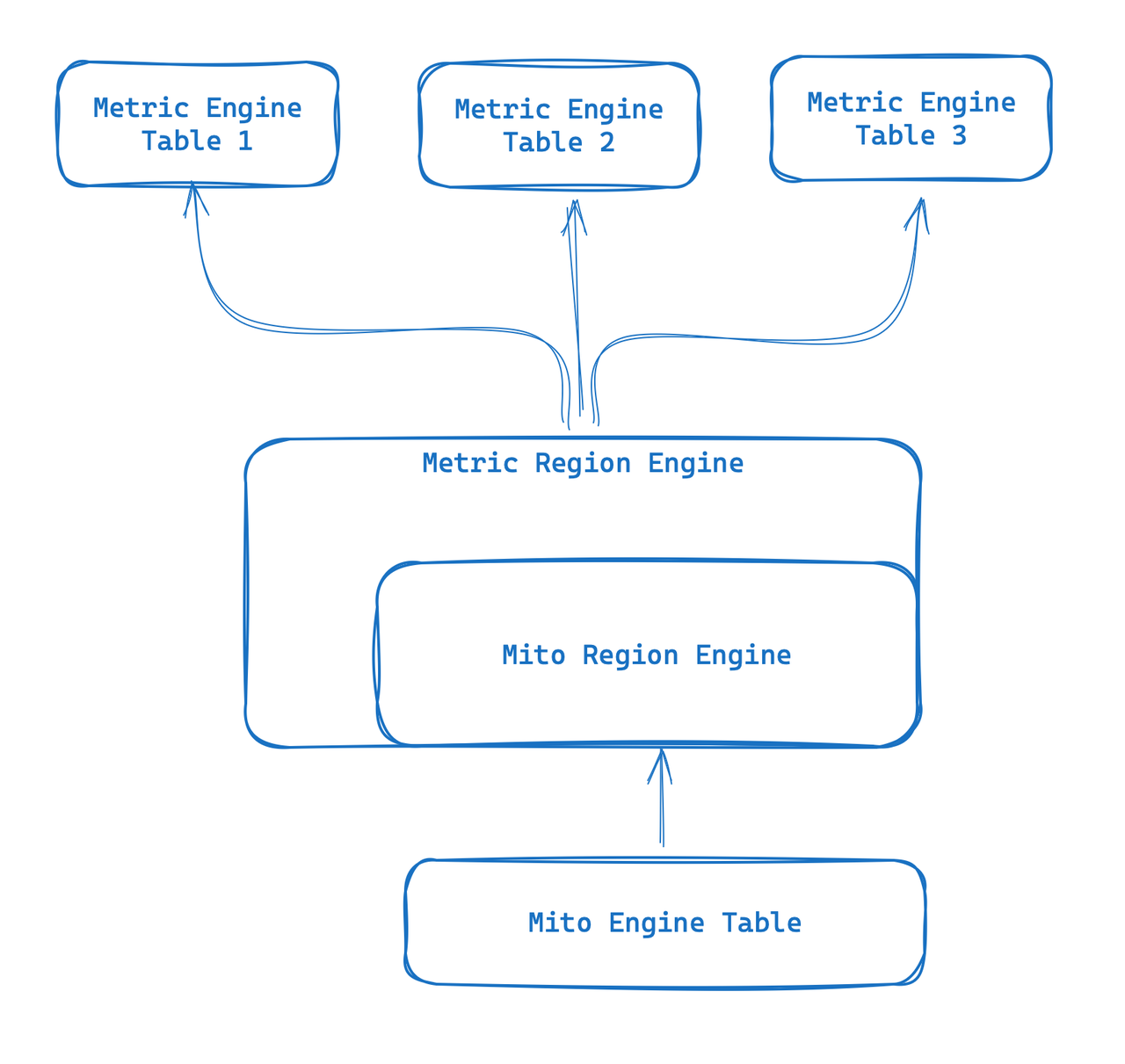
Metric Engine
Metric Engine is a brand-new engine designed for observable scenarios. Its main goal is to be able to handle a large number of small tables, and is especially suitable for cloud-native monitoring scenarios such as using Prometheus. By utilizing synthetic wide tables, this new Engine provides the ability to store indicator data and reuse metadata. The "table" becomes more lightweight on top of it, and it can overcome some of the existing Mito engine tables that are too heavyweight. limit.
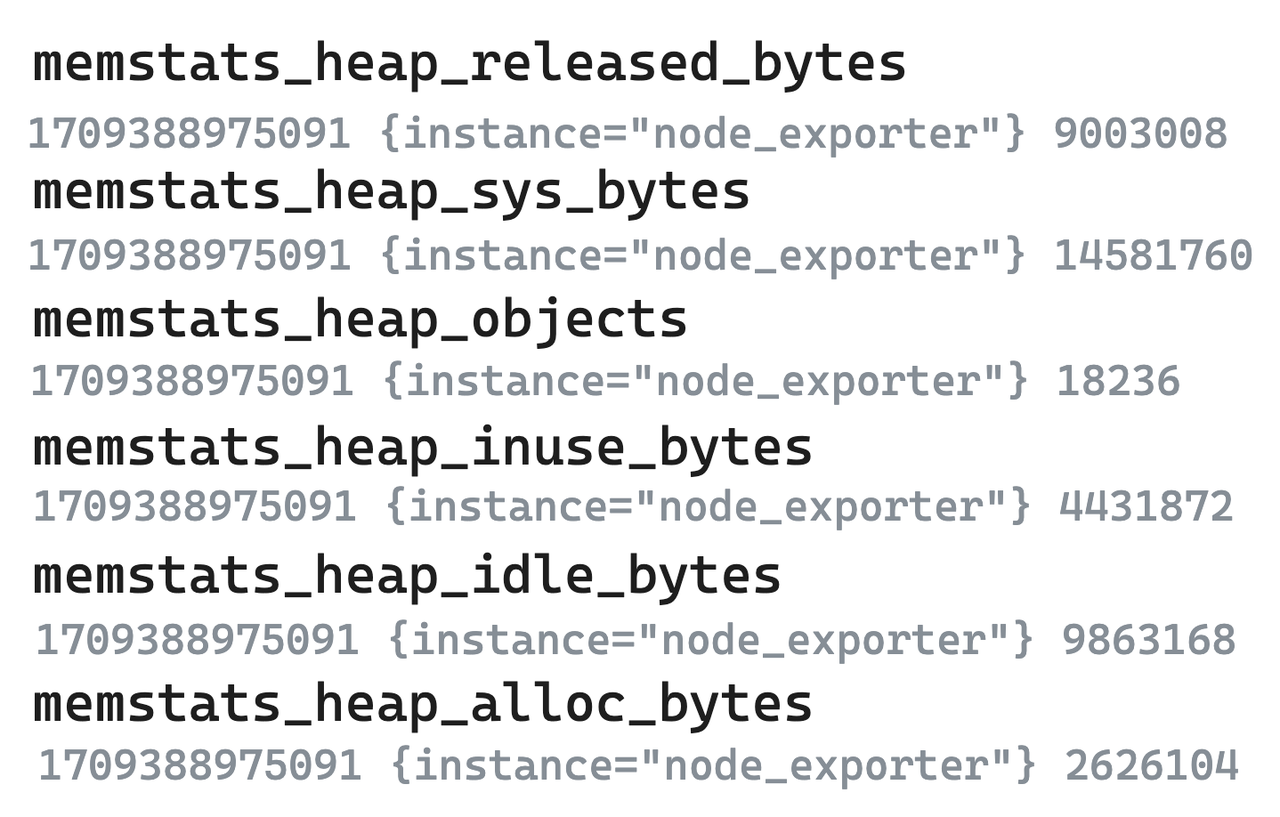
-
Legend - Raw Metric Data
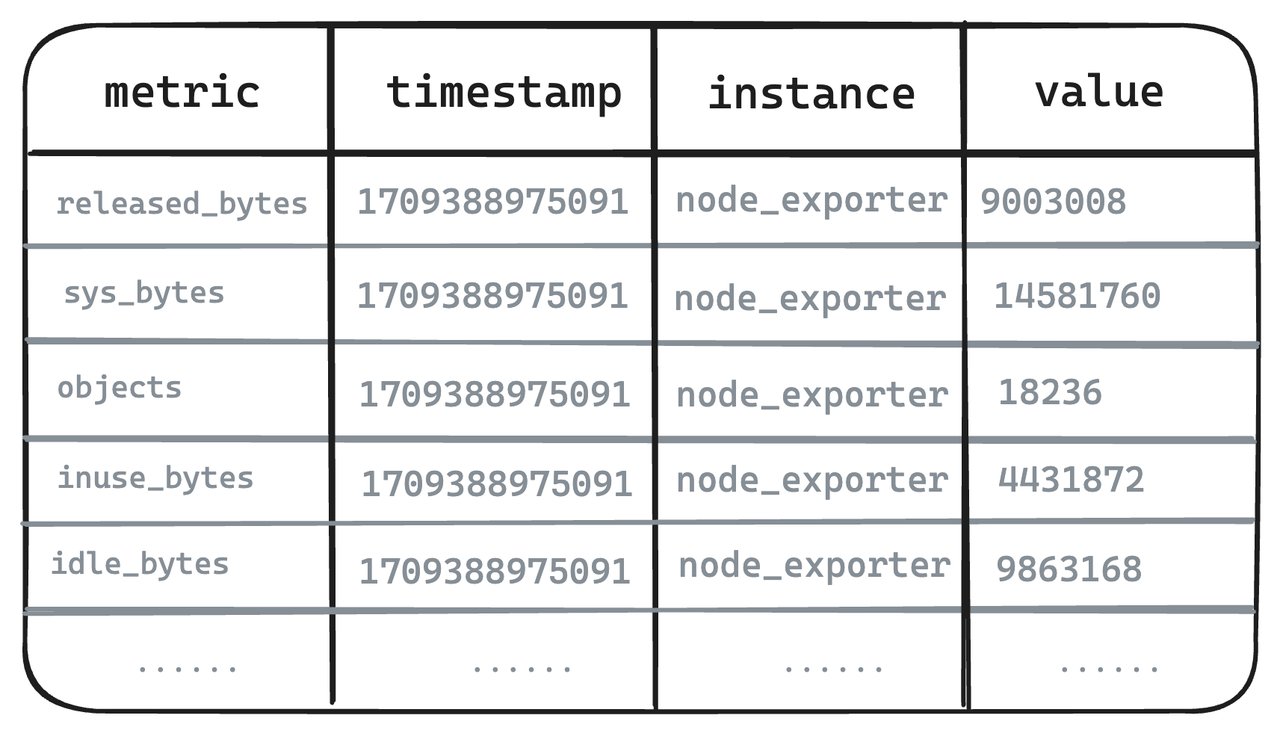
- The following Metrics of the six Node Exporters are taken as examples. In single-value model systems represented by Prometheus, even highly correlated indicators need to be split into several and stored separately.
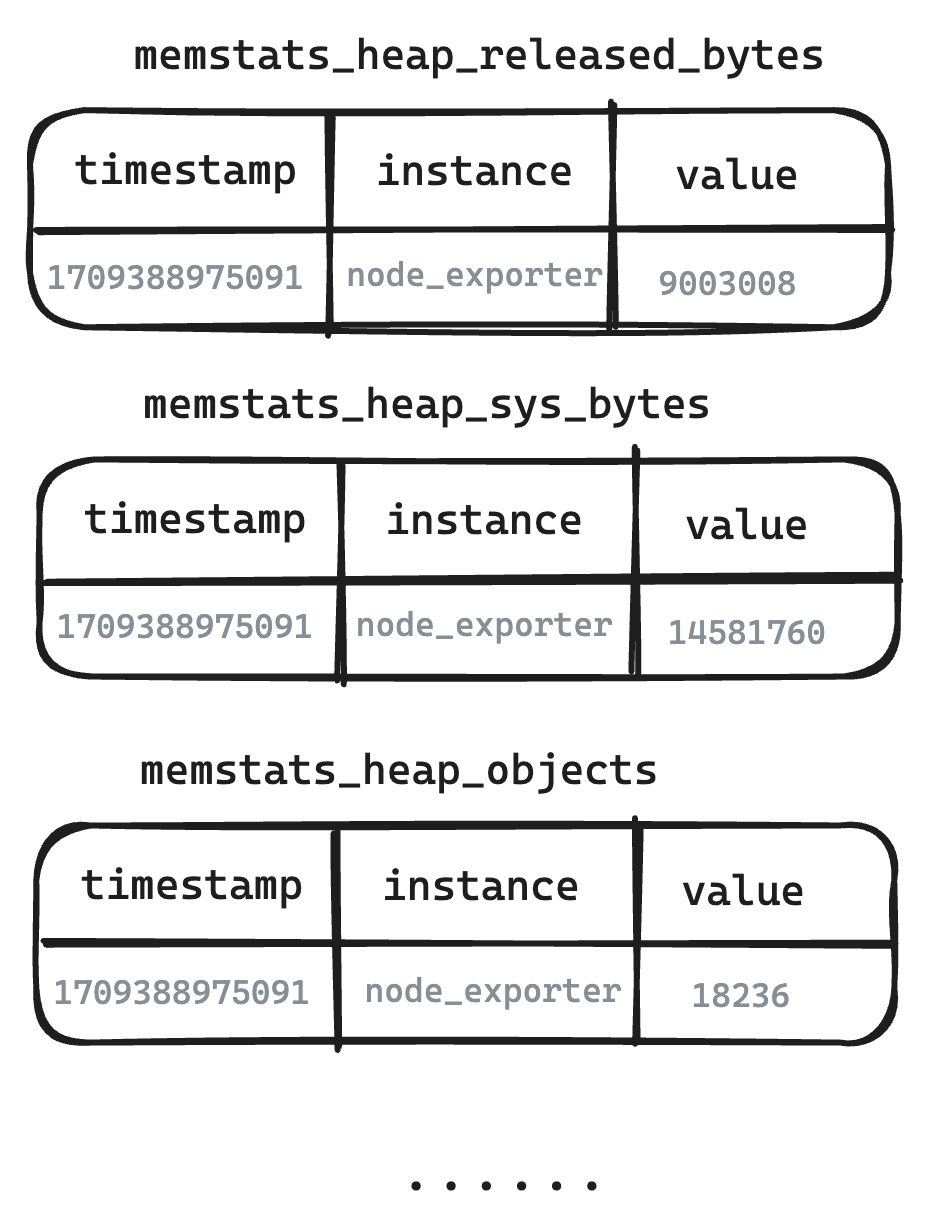
-
Legend - Logical table from user perspective
- Metric Engine authentically restores the structure of Metrics, and what users see is the written Metrics structure.
-
Legend - the physical table that stores the perspective
- At the storage layer, Metric Engine performs mapping and uses a physical table to store related data, which can reduce storage costs and support larger-scale Metrics storage.
-
Legend - Next R&D plan: Fields automatic grouping
- Most of the Metrics generated in actual scenarios are relevant. GreptimeDB can automatically derive related indicators and merge them together, which not only reduces the number of timelines across Metrics, but is also friendly to related queries.

-
Storage cost optimization
The cost test was conducted based on the AWS S3 storage backend. Each data was written for about 30 minutes, and the total write volume was about 30w row/s. Count the number of times each operation occurs in the process, and estimate the cost based on AWS's quotation. The index function was enabled during the test.
For quotations, please refer to the Standard level at https://aws.amazon.com/s3/pricing/
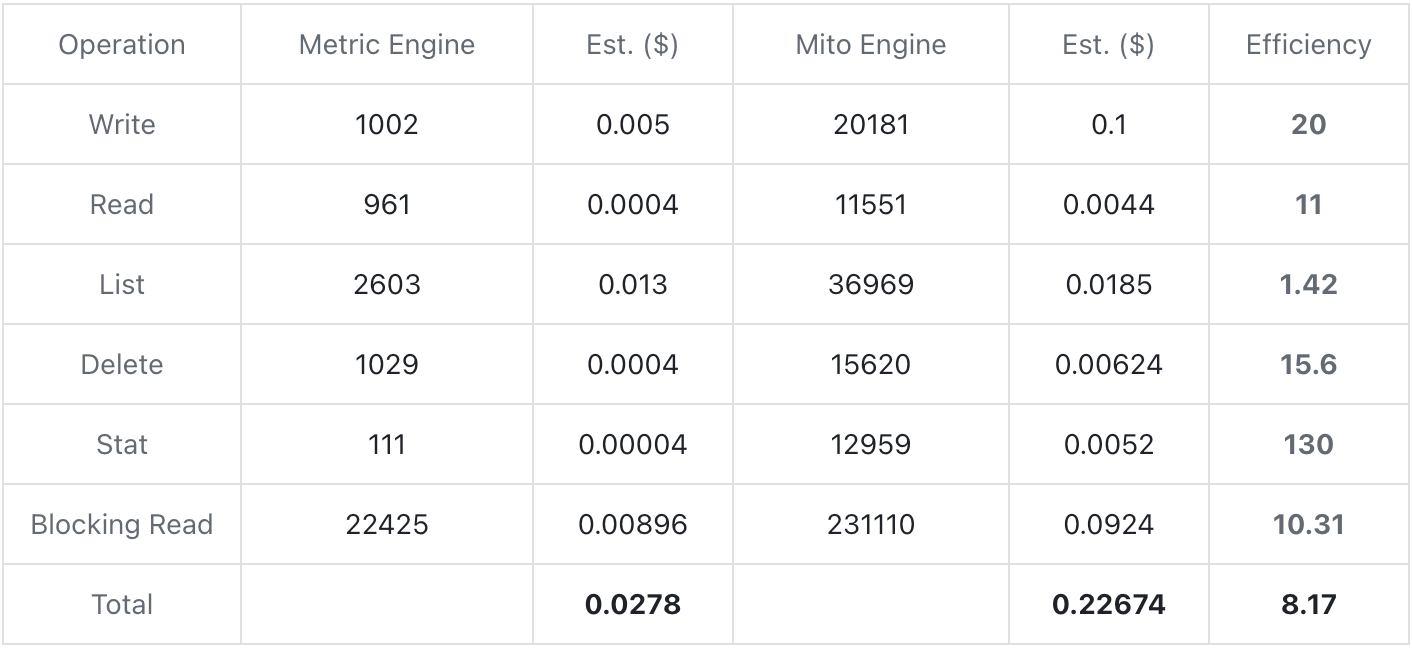
As can be seen from the above test table, Metric Engine can significantly reduce storage costs by reducing the number of physical tables. The number of operations at each stage is reduced by orders of magnitude. The converted comprehensive cost can be reduced by more than eight times compared to Mito Engine.
Inverted Index
Inverted Index 作为新引入的索引模块,旨在高效定位用户查询所涉及数据段,显著减少扫描数据文件所需 IO 操作,加速查询过程。TSBS 测试场景下场景性能平均提升 50%,部分场景性能提升近 200%。Inverted Index 的核心优势包括:
- Out-of-the-box: The system automatically generates appropriate indexes, and users do not need to specify additional indexes;
- Practical functions: supports equality, range and regular matching of multi-column values, ensuring that data can be quickly located and filtered in most scenarios;
- Flexible adaptation: Automatically adjust internal parameters to balance construction costs and query efficiency, effectively responding to the indexing needs of different scenarios
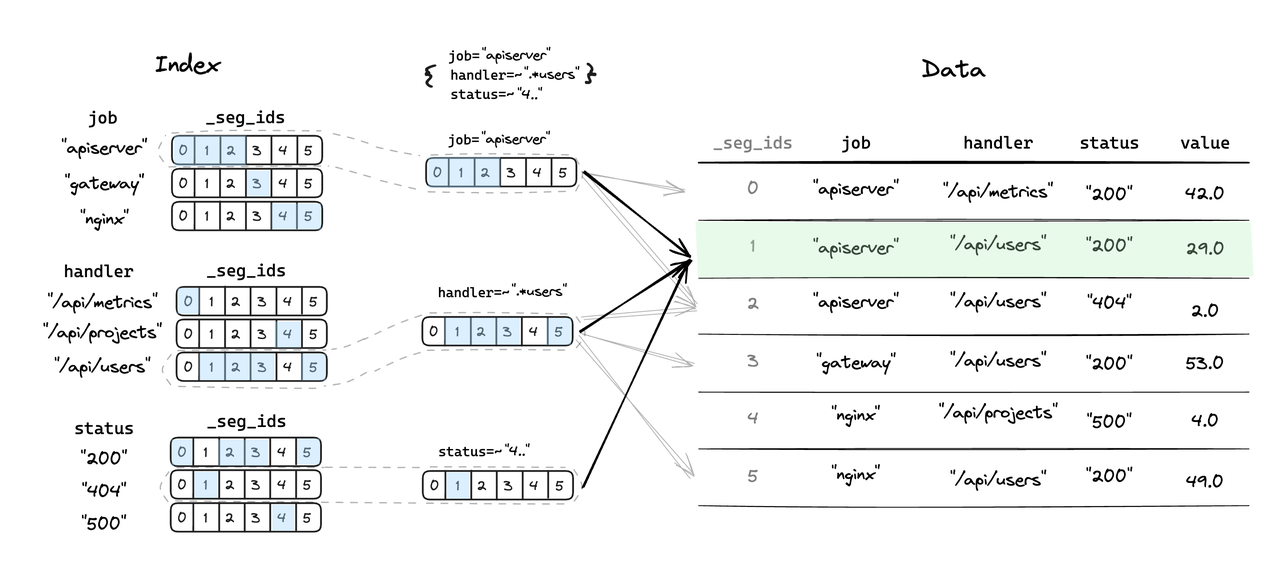
- Legend - Logical representation of Inverted Index and data positioning process
- Users specify filtering conditions in multiple columns, and through the quick positioning of the Inverted Index, most of the unmatched data segments can be eliminated, resulting in fewer data segments to be scanned and query acceleration achieved.
Other updates
1. 数据库的管理功能得到显著增强
We have significantly supplemented the information_schema table, adding new information such as SCHEMATA and PARTITIONS. In addition, the new version introduces many new SQL functions to implement DB management operations. For example, you can now trigger Region Flush, perform Region migration, and query the execution status of procedures through SQL.
2. Performance improvement
In the v0.7 version, Memtable has been reconstructed to improve data scanning speed and reduce memory usage. At the same time, we have also made many improvements and optimizations to the read and write performance of object storage.
Upgrade guide
Due to some major changes in the new version, this v0.7 release requires downtime for upgrade. It is recommended to use the official upgrade tool. The general upgrade process is as follows:
- Create a new v0.7 cluster
- Close the old cluster traffic entrance (stop writing)
- Export table structure and data through GreptimeDB CLI upgrade tool
- Import data to the new cluster through the GreptimeDB CLI upgrade tool
- Ingress traffic switches to new cluster
For detailed upgrade guide, please refer to:
- Chinese: https://docs.greptime.cn/user-guide/upgrade
- English: https://docs.greptime.com/user-guide/upgrade
future outlook
Our next major milestone is in April, when v0.8 will be launched. This version will introduce GreptimeFlow, an optimized stream computing solution specifically designed to perform continuous aggregation operations in GreptimeDB data streams. Considering the need for flexibility, GreptimeFlow can be integrated into the GreptimeDB computing layer and deployed together, or it can be deployed as an independent service.
In addition to continuous upgrades at the functional level, we are also continuing to optimize version performance. Although the performance of v0.7 has been greatly improved compared to before, there is still some gap between it and some mainstream solutions in observable scenarios. This This will also be our next key optimization direction.
Welcome to read the GreptimeDB Roadmap 2024 to get a comprehensive understanding of our year-round version update plan. You are also welcome to participate in code contributions or feedback and discussions on functions and performance. Let us join hands to witness the continued growth and improvement of GreptimeDB.
About Greptime:
Greptime Greptime Technology is committed to providing real-time and efficient data storage and analysis services for fields that generate large amounts of time series data, such as smart cars, the Internet of Things, and observability, helping customers mine the deep value of data. Currently there are three main products:
-
GreptimeDB is a time series database written in Rust language. It is distributed, open source, cloud native and highly compatible. It helps enterprises read, write, process and analyze time series data in real time while reducing long-term storage costs.
-
GreptimeCloud can provide users with fully managed DBaaS services, which can be highly integrated with observability, Internet of Things and other fields.
-
GreptimeAI is an observability solution tailored for LLM applications.
-
The vehicle-cloud integrated solution is a time-series database solution that goes deep into the actual business scenarios of car companies, and solves the actual business pain points after the company's vehicle data grows exponentially.
GreptimeCloud and GreptimeAI have been officially tested. Welcome to follow the official account or official website for the latest developments! If you are interested in the enterprise version of GreptimDB, you are welcome to contact the assistant (search greptime on WeChat to add the assistant).
Official website: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentation: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
A programmer born in the 1990s developed a video porting software and made over 7 million in less than a year. The ending was very punishing! High school students create their own open source programming language as a coming-of-age ceremony - sharp comments from netizens: Relying on RustDesk due to rampant fraud, domestic service Taobao (taobao.com) suspended domestic services and restarted web version optimization work Java 17 is the most commonly used Java LTS version Windows 10 market share Reaching 70%, Windows 11 continues to decline Open Source Daily | Google supports Hongmeng to take over; open source Rabbit R1; Android phones supported by Docker; Microsoft's anxiety and ambition; Haier Electric shuts down the open platform Apple releases M4 chip Google deletes Android universal kernel (ACK ) Support for RISC-V architecture Yunfeng resigned from Alibaba and plans to produce independent games for Windows platforms in the future