
What is High-Cardinality
Cardinality is defined in mathematics as a scalar used to represent the number of elements in a set. For example, the cardinality of a finite set A = {a, b, c} is 3. There is also a concept of cardinality for infinite sets. Today we mainly talk about the field of computers. , we won’t expand here.
In the context of a database, there is no strict definition of cardinality, but everyone's consensus on cardinality is similar to the definition in mathematics: it is used to measure the number of different values contained in a data column. For example , a data table that records users usually has several columns UID, Nameand . GenderObviously, UIDthe cardinality of , is not as high as , and a column of may have relatively few values. So in the example of the user table, it can be said that the column belongs to the high basis, and the column belongs to the low basis.IDNameUIDGenderUIDGender
If it is further subdivided into the field of time series database, the cardinality often refers to the number of timelines. Let us take the application of time series database in the observable field as an example. A typical scenario is to record the request time of API services. To give the simplest example, there are two labels for the response time of each interface of the API service of different instances: API Routesand Instance. If there are 20 interfaces and 5 instances, the base of the timeline is (20+1)x(5 +1)-1 = 125 ( +1taking into account that the response time of all interfaces of an Instance or the response time of an interface in all Instances can be viewed separately), the value does not seem large, but it should be noted that the operator is a product, so as long as a certain If the cardinality of a label is high, or a new label is added, the cardinality of the timeline will increase dramatically.
Why it matters
As we all know, relational databases such as MySQL, which everyone is most familiar with, generally have ID columns, as well as common columns such as email, order-number, etc. These are high-cardinality columns and are rarely heard of. However, certain problems arise due to such data modeling. The fact is that in the OLTP field that we are familiar with, high-cardinality is often not a problem, but in the timing field, it often causes problems because of the data model. Before entering the timing field, we still discuss it first. Let’s take a look at what a high-base data set actually means.
In my opinion, in layman’s terms, a high-based data set means a large amount of data. For a database, the increase in the amount of data will inevitably have an impact on writing, querying and storage. In particular, in The biggest impact when writing is the index.
High cardinality of traditional databases
Take B-tree, the most common data structure used to create indexes in relational databases, as an example. Normally, the complexity of insertion and query is O(logN), and the space complexity is generally O(N). ), where N is the number of elements, which is the cardinality we are talking about. Naturally, the larger N will have a certain impact, but because the complexity of insertion and query is the natural logarithm, the impact is not that big when the data magnitude is not particularly large.
So it seems that high-base data does not bring any impact that cannot be ignored. On the contrary, in many cases, the index of high-base data is more selective than the index of low-base data. The high-base index can filter out large data through a query condition. Partial data that does not meet the conditions, thereby reducing disk I/O overhead. In database applications, it is necessary to avoid excessive disk and network I/O overhead. For example select * from users where gender = "male";, the resulting data set will be very large, and the disk I/O and network I/O will be very large. In practice, using this low-cardinality index alone does not make much sense.
High cardinality of time series databases
So what is different about time series databases that causes high-radix data columns to cause problems? In the field of time series data, whether it is data modeling or engine design, the core will revolve around the timeline. As mentioned earlier, the high cardinality problem in time series database refers to the number and size of timelines. This size is not just the cardinality of one column, but the product of the cardinality of all label columns. This spread will be very large. , it can be understood that in common relational databases, the high basis is isolated in a certain column, that is, the data scale grows linearly, while the high basis in time series databases is the product of multiple columns, which is non-linear growth. Let's take a closer look at how the high-base timeline is generated in the time series database. Let's look at the first scenario first:
Time-series quantity
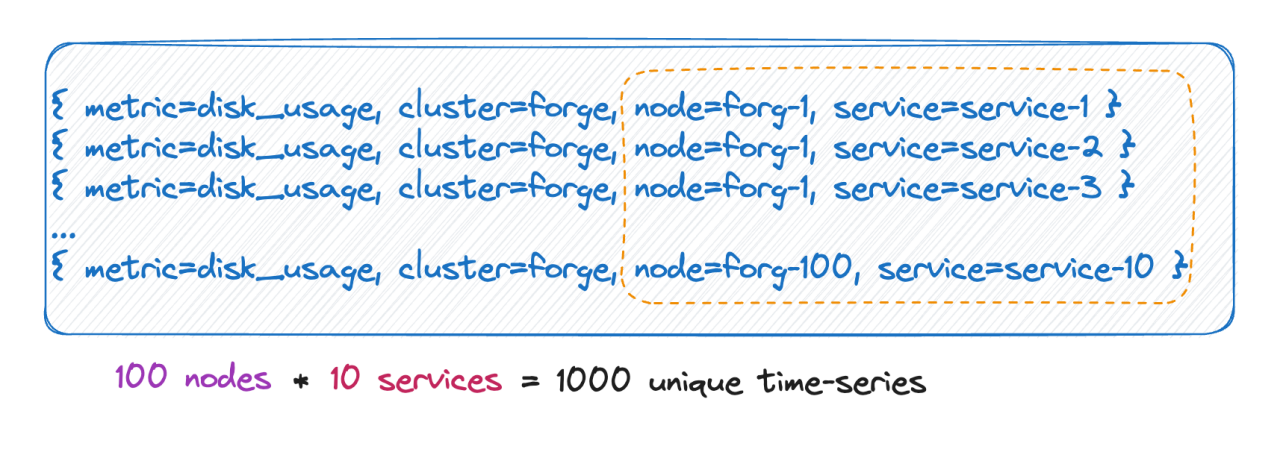
We know that the number of timelines is actually equal to the Cartesian product of all label bases. As shown in the picture above, the number of timelines is 100 * 10 = 1000 timelines. If 6 tags are added to this metric, each tag value has 10 values, and the number of timelines is 10^9, which is 100 million. A timeline, you can imagine this magnitude.
Tag has infinite values
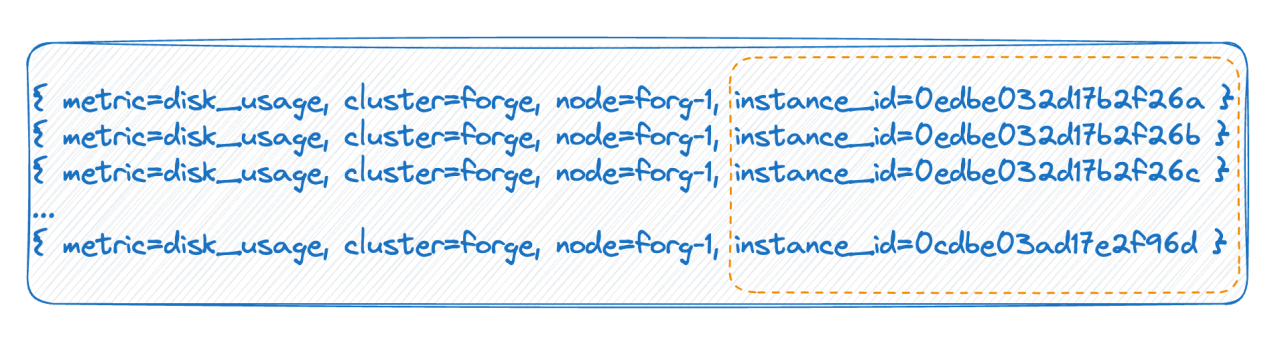
In the second case, for example, in a cloud-native environment, each pod has an ID. Each time it is restarted, the pod is actually deleted and rebuilt, and a new ID is generated, which causes the tag value to be very There are many, and each full restart will cause the number of timelines to double. The above two situations are the main reasons for the high cardinality mentioned by the time series database.
How time series database organizes data
We know how high cardinality occurs. We need to understand what problems it will cause, and we also need to understand how mainstream time series databases organize data.
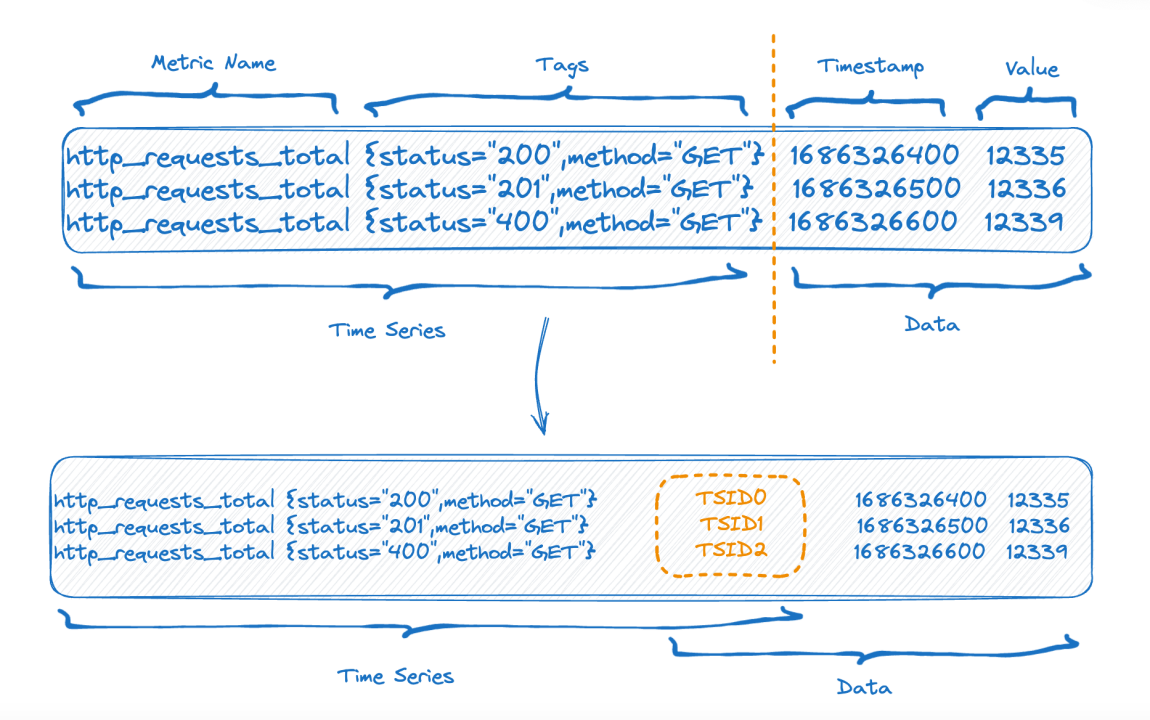
The upper half of the figure shows the representation before data is written, and the lower half of the figure shows the logical representation after data storage. The left side is the index data of the time-series part, and the right side is the data part.
Each time-series can generate a unique TSID, and the index and data are related through the TSID. Familiar friends may have seen this index, it is an inverted index.
Let’s look at the picture below, which is a representation of the inverted index in memory:
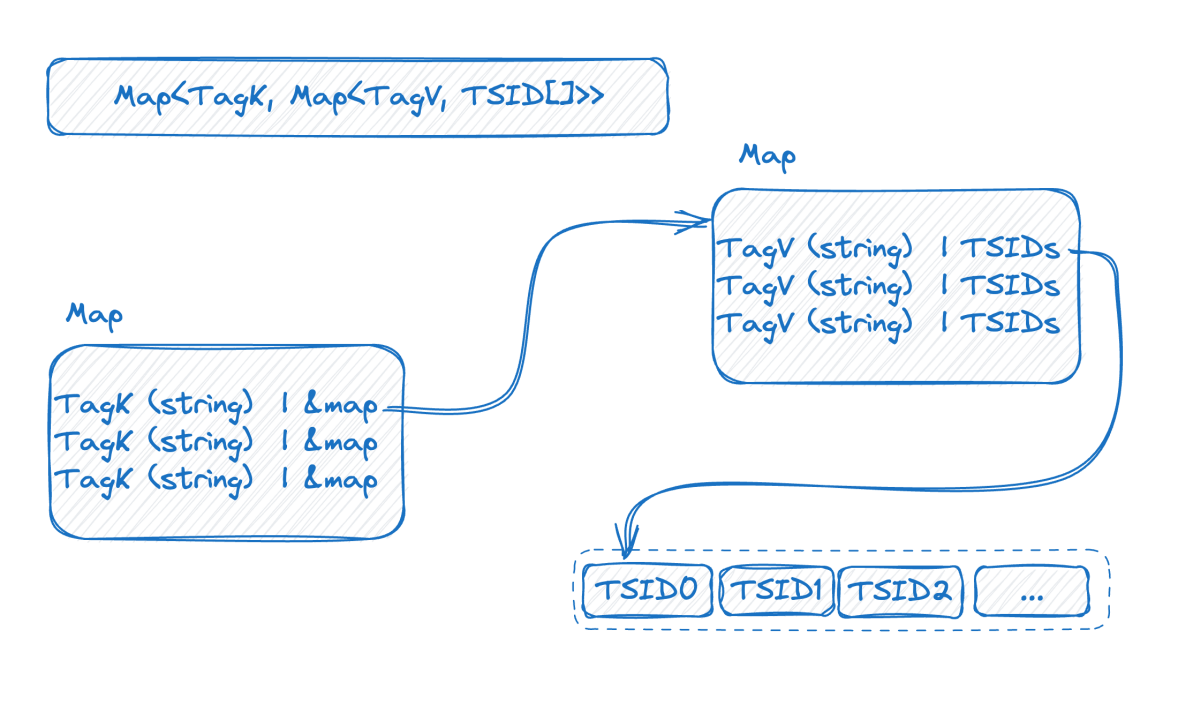
This is a two-layer map. The outer layer first finds the inner map through the tag name. K in the inner map is the tag value, and V is the set of TSIDs containing the corresponding tag value.
At this point, combined with the previous introduction, we can see that the higher the base of the time series data, the larger the double-layer map will be. After understanding the index structure, we can try to understand how the high basis problem arises:
In order to achieve high throughput writing, it is best to keep this index in memory. High cardinality will cause the index to expand and you will not be able to fit the index in memory. If the memory cannot be stored, it must be swapped to the disk. After swapping to the disk, the writing speed will be affected due to a large amount of random disk IO. Let's look at the query again. From the index structure, we can guess the query process, such as the query conditions where status = 200 and method="get". The process is to first find statusthe map with key , get the inner map and then "200"get all the TSID sets, and check again in the same way. A condition, and then the new TSID set obtained after the intersection of the two TSID sets is used to retrieve data one by one according to the TSID.
It can be seen that the core of the problem is that the data is organized according to the timeline, so you must first get the timeline, and then find the data according to the timeline. The more timelines involved in a query, the slower the query will be.
How to solve it
If our analysis is correct and we know the cause of the high basis problem in the field of time series data, then it will be easy to solve. Let’s take a look at the cause of the problem:
- Data level: Index maintenance and query challenges caused by C(L1) * C(L2) * C(L3) * ... * C(Ln).
- Technical level: Data is organized according to timelines, so you need to get the timeline first, and then find the data according to the timeline. If there are more timelines, the query will be slower.
The editor will discuss the solutions from two aspects:
Optimization of data modeling
1 Remove unnecessary labels
We often accidentally set some unnecessary fields as labels, causing the timeline to bloat. For example, when we monitor the status of the server, we often have instance_name, ip. In fact, it is not necessary for these two fields to become labels. One of them is probably enough, and the other one can be set as an attribute.
2. Data modeling based on actual queries
Take sensor monitoring in the Internet of Things as an example:
- 10w devices
- 100 regions
- 10 devices
If modeled into a metric, in Prometheus, it will result in a timeline of 10w * 100 * 10 = 100 million. (Non-rigorous calculation) Think about it, will the query be performed in this way? For example, how to query the timeline of a certain type of equipment in a certain region? This seems unreasonable, because once the device is specified, the type is determined, so the two labels do not actually need to be together, then it may become:
- metric_one: 10w devices
- metric_two:
- 100 regions
- 10 devices
- metric_three: (assuming that a device may be moved to a different region to collect data)
- 10w devices
- 100 regions
The total is a timeline of 10w + 100 10 + 10w 100 ~ 1010w, which is 10 times less than the above.
3. Separately manage valuable high-base timeline data
Of course, if you find that your data modeling is very consistent with the query, but the timeline is still unable to be reduced because the data scale is too large, then put all the services related to this core indicator on a better machine.
Optimization of time series database technology
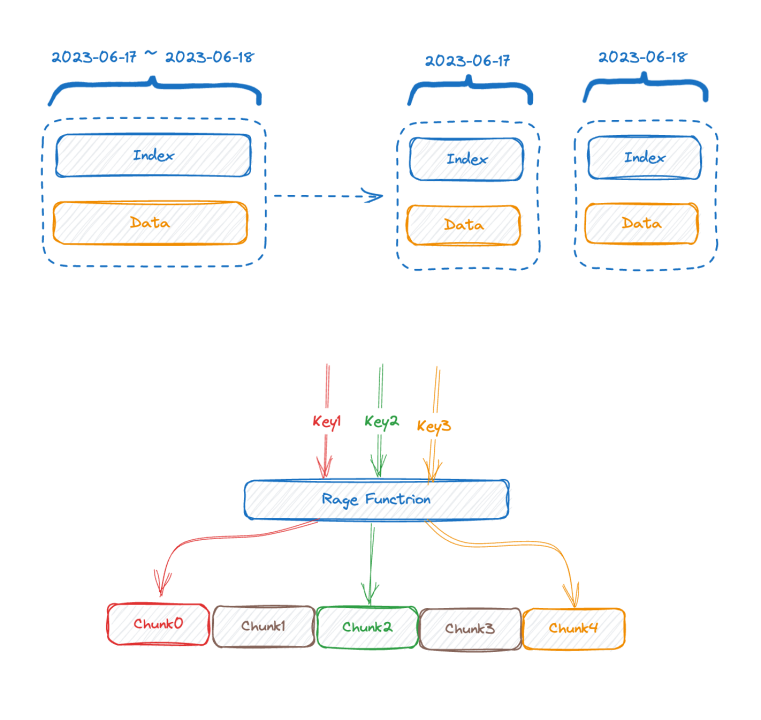
- The first effective solution is vertical segmentation. Most mainstream time series databases in the industry have more or less adopted a similar method to segment the index according to time, because if this segmentation is not done, as time progresses, the index will It will expand more and more, and finally the memory will not be able to store it. If it is divided according to time, the old index chunk can be swapped to the disk or even remote storage. At least the writing will not be affected.
- The opposite of vertical segmentation is horizontal segmentation. A sharding key is used, which can generally be one or several tags with the highest frequency of query predicate usage. Range or hash segmentation is performed based on the values of these tags, which is equivalent to using The distributed divide-and-conquer idea solves the bottleneck on a single machine. The price is that if the query condition does not include a sharding key, the operator cannot be pushed down, and the data can only be moved to the top layer for calculation.
The above two methods are traditional solutions, which can only alleviate the problem to a certain extent, but cannot fundamentally solve the problem. The next two solutions are not conventional solutions, but are the directions that GreptimeDB is trying to explore. They are only briefly mentioned here without in-depth analysis, for your reference only:
-
We may want to think about whether time series databases really need inverted indexes. TimescaleDB uses B-tree indexes, and InfluxDB_IOx does not have inverted indexes. For high-cardinality queries, we use partition scans commonly used in OLAP databases combined with min-max indexes. Would the effect be better if we perform some pruning optimization?
-
Asynchronous smart indexing. To be smart, you must first collect and analyze behaviors. Analyze and asynchronously build the most appropriate index to speed up queries in each query of the user. For example, we choose tags that appear very rarely in user query conditions. No inversion is created for it. Combining the above two solutions, when writing, because the inversion is built asynchronously, it does not affect the writing speed at all.
Looking at the query again, because time series data has time attributes, the data can be bucketed according to timestamp. We do not index the latest time bucket. The solution is to perform hard scan and combine some min-max indexes for pruning optimization. It is still possible to scan tens of millions or hundreds of millions of lines in seconds.
When a query comes, first estimate how many timelines it will involve. If it involves a small amount, use inversion, and if it involves a lot, go directly to scan + filter without inversion.
We are still exploring the above ideas and are not yet perfect.
Conclusion
High base is not always a problem. Sometimes high base is necessary. What we need to do is to build our own data model based on our own business conditions and the nature of the tools we use. Of course, sometimes tools have certain scenario limitations. For example, Prometheus indexes labels under each metric by default. This is not a big problem in a single-machine scenario, and it is also convenient for users to use. However, it will be stretched when dealing with large-scale data. GreptimeDB is committed to creating a unified solution in both stand-alone and large-scale scenarios. We are also exploring technical attempts at high-base problems, and everyone is welcome to discuss it.
Reference
- https://en.wikipedia.org/wiki/Cardinality
- https://www.cncf.io/blog/2022/05/23/what-is-high-cardinality/
- https://grafana.com/blog/2022/10/20/how-to-manage-high-cardinality-metrics-in-prometheus-and-kubernetes/
About Greptime:
Greptime Greptime Technology is committed to providing real-time and efficient data storage and analysis services for fields that generate large amounts of time series data, such as smart cars, the Internet of Things, and observability, helping customers mine the deep value of data. Currently there are three main products:
-
GreptimeDB is a time series database written in Rust language. It is distributed, open source, cloud native and highly compatible. It helps enterprises read, write, process and analyze time series data in real time while reducing long-term storage costs.
-
GreptimeCloud can provide users with fully managed DBaaS services, which can be highly integrated with observability, Internet of Things and other fields.
-
GreptimeAI is an observability solution tailored for LLM applications.
-
The vehicle-cloud integrated solution is a time-series database solution that goes deep into the actual business scenarios of car companies, and solves the actual business pain points after the company's vehicle data grows exponentially.
GreptimeCloud and GreptimeAI have been officially tested. Welcome to follow the official account or official website for the latest developments! If you are interested in the enterprise version of GreptimDB, you are welcome to contact the assistant (search greptime on WeChat to add the assistant).
Official website: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentation: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
A programmer born in the 1990s developed a video porting software and made over 7 million in less than a year. The ending was very punishing! High school students create their own open source programming language as a coming-of-age ceremony - sharp comments from netizens: Relying on RustDesk due to rampant fraud, domestic service Taobao (taobao.com) suspended domestic services and restarted web version optimization work Java 17 is the most commonly used Java LTS version Windows 10 market share Reaching 70%, Windows 11 continues to decline Open Source Daily | Google supports Hongmeng to take over; open source Rabbit R1; Android phones supported by Docker; Microsoft's anxiety and ambition; Haier Electric shuts down the open platform Apple releases M4 chip Google deletes Android universal kernel (ACK ) Support for RISC-V architecture Yunfeng resigned from Alibaba and plans to produce independent games for Windows platforms in the future