
mysqld: Brother, I can’t get up...
Author: Ben Shaohua, engineer at ACOSEN R&D Center, responsible for project requirements and maintenance. Other identities: Corgi shoveler.
Produced by the Aikeson open source community. Original content may not be used without authorization. Please contact the editor and indicate the source for reprinting.
This article is approximately 2,100 words long and is expected to take 7 minutes to read.
introduction
As the title states, in automated testing scenarios, MySQL cannot be started through systemd .
Continuously kill -9end the instance process and check whether mysqld will be pulled up correctly after exiting.
Specific information is as follows:
- Host information: CentOS 8 (Docker container)
- Use systemd to manage the mysqld process
- The operating mode of systemd service is: forking
- The startup command is as follows:
# systemd 启动命令
sudo -S systemctl start mysqld_11690.service
# systemd service 内的 ExecStart 启动命令
/opt/mysql/base/8.0.34/bin/mysqld --defaults-file=/opt/mysql/etc/11690/my.cnf --daemonize --pid-file=/opt/mysql/data/11690/mysqld.pid --user=actiontech-mysql --socket=/opt/mysql/data/11690/mysqld.sock --port=11690
Symptom
The startup command continues to hang, with neither success nor any return. After several attempts, the scenario cannot be reproduced manually.
The figure below shows a reproduction scenario. If the service port numbers are inconsistent, please ignore them.

The MySQL error log contains no information. Check the systemd service status and find that the startup script MAIN PIDfailed to execute due to a lack of parameters.
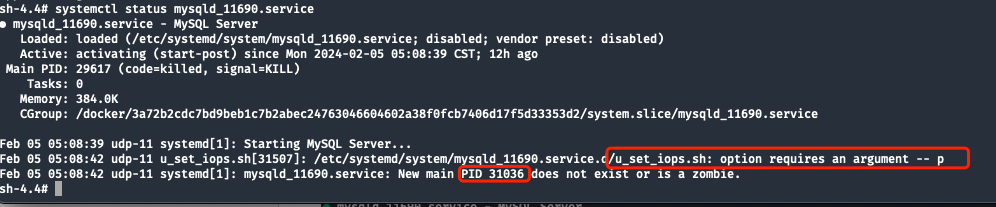
The final information output by systemd is:New main PID 31036 does not exist or is a zombie
Summary of reasons
When systemd starts mysqld , it will first execute according to the configuration in the service template:
- ExecStart (start mysqld )
- mysqld starts creating
pidfiles - ExecStartPost (some customized post-scripts: adjust permissions, write
pidto cgroup , etc.)
In the intermediate state of step 2-3 , that is, pidwhen the file is just created, the host receives the command issued by the automated test: sudo -S kill -9 $(cat /opt/mysql/data/11690/mysqld.pid).
Since this pidfile and pidprocess do exist (if killthe command or command does not exist, catan error will be reported), automated CASE considers that killthe operation has ended successfully. However, since mysqld.pidthis file is maintained by MySQL itself, from the perspective of systemd , you still need to wait for step 3 to be completed before the startup is considered successful.
When systemd uses forking mode, it will PIDdetermine whether the service is successfully started based on the value of the child process.
If the child process starts successfully and no unexpected exit occurs, systemd considers the service to have been started and sets the child process's PIDvalue as MAIN PID.
If the child process fails to start or exits unexpectedly, systemd will consider that the service failed to start successfully.
in conclusion
When executing ExecStartPost, because the child process ID 31036 has been killdeleted, the post-processing shelllacks startup parameters, but the ExecStart step has been completed, causing MAIN PID 31036 to become a zombie process that only exists in systemd .
Troubleshooting process
When I encountered this problem, I was a little confused. I simply checked the basic information of the memory and disk. It met expectations and there was no shortage of resources.
Let’s first look at the Error Log of MySQL to see what we find. View the results as follows:
...无关内容省略...
2024-02-05T05:08:42.538326+08:00 0 [Warning] [MY-010539] [Repl] Recovery from source pos 3943309 and file mysql-bin.000001 for channel ''. Previous relay log pos and relay log file had been set to 4, /opt/mysql/log/relaylog/11690/mysql-relay.000004 respectively.
2024-02-05T05:08:42.548513+08:00 0 [System] [MY-010931] [Server] /opt/mysql/base/8.0.34/bin/mysqld: ready for connections. Version: '8.0.34' socket: '/opt/mysql/data/11690/mysqld.sock' port: 11690 MySQL Community Server - GPL.
2024-02-05T05:08:42.548633+08:00 0 [System] [MY-013292] [Server] Admin interface ready for connections, address: '127.0.0.1' port: 6114
2024-02-05T05:08:42.548620+08:00 5 [Note] [MY-010051] [Server] Event Scheduler: scheduler thread started with id 5
By observing the Error Log, we found that there is no useful information because no log information is output after the startup time.
Check systemctl status to confirm the current status of the service:
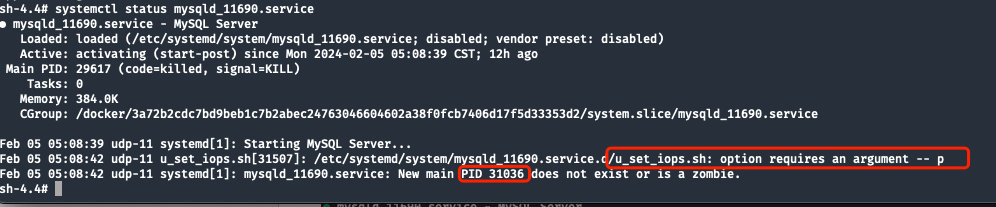
The picture below shows the status information under normal circumstances :

After comparison, two useful pieces of information were compiled:
- Post- execution failed
shelldue to lack of-pparameters (-pthe parameters areMAIN PID, that is, after the fork child process is startedPID). - systemd cannot be obtained
PID 31036, does not exist, or is a zombie process.
Let's first check the process IDand mysqld.pidsee:
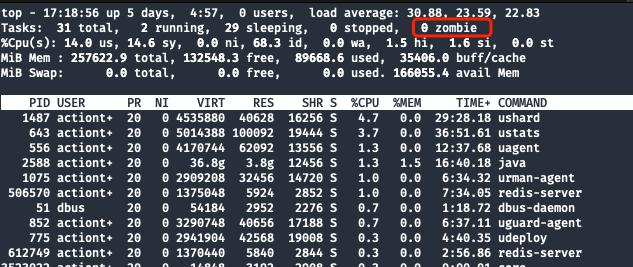
Confirmation clues:
PID 31036does not existmysqld.pidThe file exists and the file content is 31036topCommand to check if there is no zombie process
Still need to get more clues to confirm the cause, check journalctl -uthe content to see if it helps:
sh-4.4# journalctl -u mysqld_11690.service
-- Logs begin at Mon 2024-02-05 04:00:35 CST, end at Mon 2024-02-05 17:08:01 CST. --
Feb 05 05:07:54 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:07:56 udp-11 systemd[1]: Started MySQL Server.
Feb 05 05:08:31 udp-11 systemd[1]: mysqld_11690.service: Main process exited, code=killed, status=9/KILL
Feb 05 05:08:31 udp-11 systemd[1]: mysqld_11690.service: Failed with result 'signal'.
Feb 05 05:08:32 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:08:36 udp-11 systemd[1]: Started MySQL Server.
Feb 05 05:08:37 udp-11 systemd[1]: mysqld_11690.service: Main process exited, code=killed, status=9/KILL
Feb 05 05:08:37 udp-11 systemd[1]: mysqld_11690.service: Failed with result 'signal'.
Feb 05 05:08:39 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:08:42 udp-11 u_set_iops.sh[31507]: /etc/systemd/system/mysqld_11690.service.d/u_set_iops.sh: option requires an argument -- p
Feb 05 05:08:42 udp-11 systemd[1]: mysqld_11690.service: New main PID 31036 does not exist or is a zombie.
The content here journalctl -uonly describes the phenomenon and cannot analyze the specific reasons. It is similar to the content of systemctl status and is not very helpful.
View /var/log/messagesthe system log content:

It was found that the loop reported some memory error information. After searching, it was found that the error may be a hardware problem. After asking colleagues in automated testing, I came to the conclusion:
- The scenario is an occasional problem. The use case is executed 4 times, 2 times successful and 2 times failed.
- Each execution is on the same host and the same container image.
- When it fails, the container where the hang lives is the same.
Since there are successful execution results, we will ignore the hardware problems here.
Now that containers are mentioned, there is a problem when I think about whether cgroups will map to the host? In the systemctl status checked above , it can be seen that the host directory mapped by cgroup is:CGroup: /docker/3a72b2cdc7bd9beb1c7b2abec24763046604602a38f0fcb7406d17f5d33353d2/system.slice/mysqld_11690.service
Check the read and write permissions of the parent folder system.sliceand there is no abnormality. First, temporarily eliminate the cgroup mapping problem (because there are other services taken over by systemd on the host that also use the same cgroup ).
I plan to try if pstack can see where systemd hangs specifically, 3048143for systemctl start pid:
sh-4.4# pstack 3048143
#0 0x00007fdfaef33ade in ppoll () from /lib64/libc.so.6
#1 0x00007fdfaf7768ee in bus_poll () from /usr/lib/systemd/libsystemd-shared-239.so
#2 0x00007fdfaf6a8f3d in bus_wait_for_jobs () from /usr/lib/systemd/libsystemd-shared-239.so
#3 0x000055b4c2d59b2e in start_unit ()
#4 0x00007fdfaf7457e3 in dispatch_verb () from /usr/lib/systemd/libsystemd-shared-239.so
#5 0x000055b4c2d4c2b4 in main ()
Observation found that start_unit is suspicious. start_unit()The function is located in the executable file. It is used to start systemd units , which is not helpful.
Based on existing clues, we can speculate that:
mysqld.pidIf the file exists, it means that there was indeed a mysqld process with the process number31036being started before.kill -9After the process is started, it is terminated by the automated use case.- systemd obtained an already terminated
MAIN PID, post- shell execution failed, and the fork process failed.
By sorting out the steps of the systemd startup process, we can speculate on the possibilities. The MySQL instance will only generate files after mysqld is successfully started, so it may be caused by being accidentally terminated mysqld.pidin subsequent steps .kill -9
Reproduction method
Since there are no other clues or clues, I plan to try to reproduce it based on the inferred conclusion.
4.1 Adjust systemd mysql serivce template
Edit the template file /etc/systemd/system/mysqld_11690.service, seconds after mysqld starts, sleep10so that you can simulate the scenario of killing the instance process within this time window.
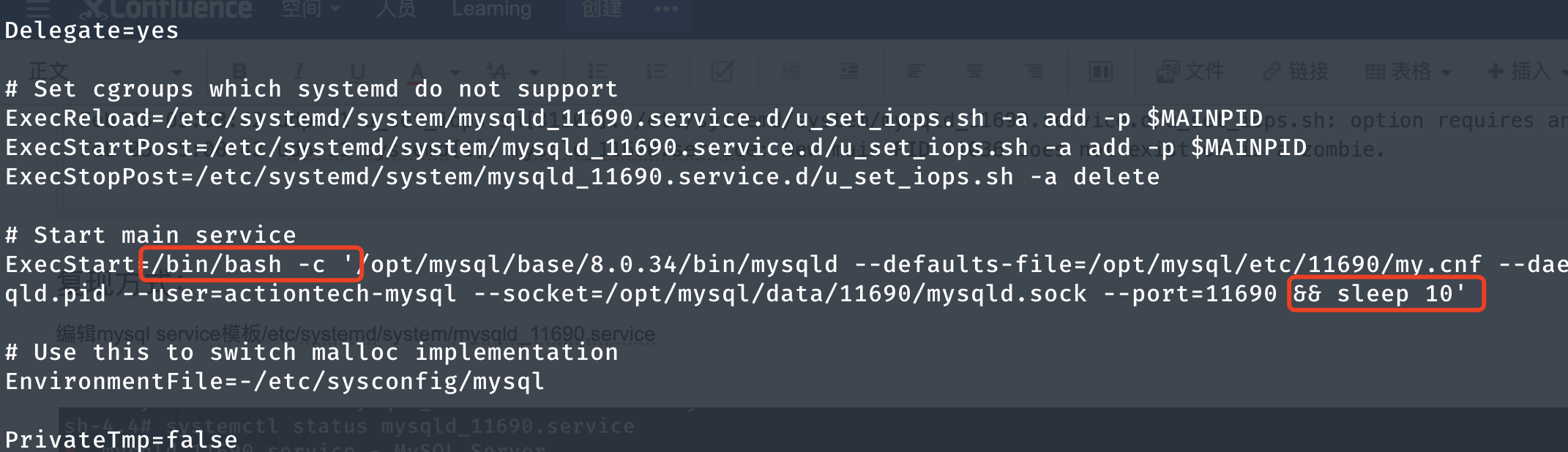
4.2 Configuration reloading
Execution systemctl daemon-reloadorders changes to take effect.
4.3 Scene reproduction
- [ssh session A] First prepare a new container, make relevant configurations and execute to
sudo -S systemctl start mysqld_11690.servicestart a mysqld process. At this time,sleepthe session will hang due to reasons. - [ssh session B] In another session window,
startwhile the command hang is alive, checkmysqld.pidthe file and execute it immediately once the file is createdsudo -S kill -9 $(cat /opt/mysql/data/11690/mysqld.pid). - At this time, observe systemctl status and the performance is consistent with expectations.

Solution
First, remove the killhanging systemctl start command and execute it systemctl stop mysqld_11690.service. This allows systemd to actively end the zombie process. Although stopthe command may report an error, this does not affect it.
Wait for stopthe execution to complete and then use startthe command to start again and return to normal.
For more technical articles, please visit: https://opensource.actionsky.com/
About SQLE
SQLE is a comprehensive SQL quality management platform that covers SQL auditing and management from development to production environments. It supports mainstream open source, commercial, and domestic databases, provides process automation capabilities for development and operation and maintenance, improves online efficiency, and improves data quality.
SQLE get
| type | address |
|---|---|
| Repository | https://github.com/actiontech/sqle |
| document | https://actiontech.github.io/sqle-docs/ |
| release news | https://github.com/actiontech/sqle/releases |
| Data audit plug-in development documentation | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |