
Author: vivo Internet Big Data Team - Huang Guihu, Chen Shengzun
HBase is an open source distributed non-relational database with high reliability, high scalability and high performance. It is widely used in big data processing, real-time computing, data storage and retrieval and other fields. In a distributed cluster, hardware failure is a common occurrence. Hardware failure may lead to node or cluster-level service interruption, meta table damage, RIT, Region holes, overlaps and other problems. How to quickly repair the fault and restore the business is particularly important. This article is mainly about Describe common failures and corresponding solutions around HBase meta tables.
1. Background
I believe that friends who have done HBase development, operation and maintenance related work have this feeling to some extent. HBase, as a leader in distributed non-relational databases, is not only stable, high-performance, and very simple to install and expand, but it also lacks Mature monitoring systems are extremely unfriendly to troubleshooting. If you lack a comprehensive understanding of HBase, you will often be at a loss to deal with daily failures. As the editors, we have operated and maintained 20+ HBase clusters of various sizes involving versions 1.x~2.x. We have experienced meta table corruption and failure to go online normally, Region overlaps, We have been dealing with online problems such as Region holes and lost permissions, and we have also sought the correct answers from the HBase source code with various problems. This article is a common solution to the meta table that the editors have summarized from many failures.
2. HBase meta meta information table
The HBase meta table, also known as the catalog table, is a special HBase table that stores all Regions in the HBase cluster and their corresponding RegionServer information. The data accuracy of the meta information table is crucial to the normal operation of the HBase cluster, so it needs to be ensured Correct data in the metainformation table is a necessary condition for stable operation of the cluster. If the data in the meta table is inconsistent, it will cause RIT (Region In Transition) or even the cluster cannot start normally because HMaster cannot be initialized normally. This shows the importance of the meta table in the HBase cluster. Below we focus on the meta table structure, data format, Start the process to parse it (this article mainly focuses on HBase 2.4.8 version, and will also intersperse HBase 1.x version).
2.1 meta table structure
The meta table mainly includes three column families: info, table, and rep_barrier, which respectively record Region information and table status:
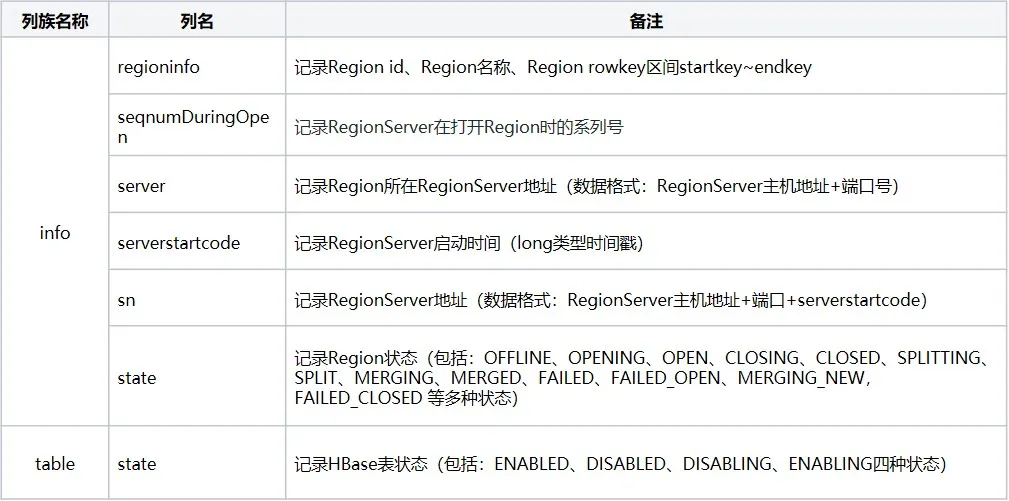
2.2 meta table loading process
Through the above meta table structure, we have an overall understanding of the table. Friends who have done HBase operation and maintenance believe that they all have this experience. Some clusters start faster, some clusters start slower, and sometimes even the cluster restarts due to improper operation. It has been stuck in meta table loading and cannot continue to execute subsequent processes. If we have an overall understanding of the meta table loading process, we will have a more or less psychological expectation for each cluster startup time. The following is the process related to meta table loading:
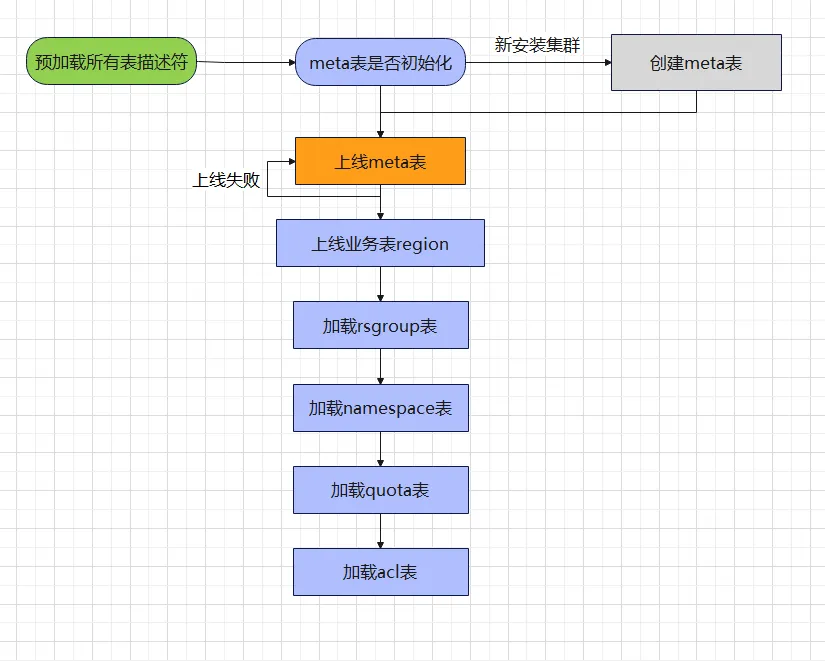
Through the above meta table loading flow chart, we can easily find out why some clusters start slowly and some clusters fail to start. Below we analyze two types of scenarios:
- The cluster starts slowly:
Usually new clusters or clusters with fewer tables tend to start faster, while clusters with more tables tend to start much slower. Some clusters even take 15 to 30 minutes to start HMaster. Sometimes the cluster startup time is long, which makes people suspicious. Is there something wrong with the cluster? Why can't it enter a normal state for so long? There are two places that take a long time in the entire loading process.
Preload all table descriptors : You need to scan the entire HBase data directory and parse out the data files under the .tabledesc directory and store them in HMaster memory. If there are a large number of tables (more than 10,000 tables), this process often takes about ten minutes. When we see the words "Pre-loading table descriptors" appear on the HMaster page, it means that the cluster is in the preloading stage. We just need to wait patiently, because the meta table loading stage has not yet reached.
Online business table Region : The meta table data size is usually between tens of MB and hundreds of MB. The region opening time is relatively fast (seconds). During the cluster startup phase, the offline region needs to be checked and online. If you want to speed up the opening speed, you can adjust hbase appropriately. master.executor.openregion.threads (default 5) value.
- Cluster startup failed:
Meta table online failure : When the HRegionServer of the default resource group hangs up and the machine's startcode changes after restarting, the meta data shard cannot find the open node, causing the cluster to fail to start.
3. How to repair the meta table
Since the HBase cluster status is mainly maintained through the meta table, if the meta table is damaged or wrong, it will cause the HBase cluster to become unavailable and face the risk of data loss. We know that meta table data consistency is very important, so under what circumstances will data inconsistency occur? (For HBase 2.4.8 repair commands, refer to the hbase-operator-tools tool).
-
RegionServer is down or abnormal : When RegionServer is down or abnormal, the Region and RegionServer information stored in the meta table may be incorrect or lost.
-
Data corruption or errors : When the data in the meta table is corrupted or incorrect, it may lead to unavailability of the HBase cluster and data loss.
-
Illegal operations : When illegal operations are performed on the meta table, such as deleting or modifying data in the meta table, it may cause errors or loss of the meta table.
Meta table failure is just a general term. We can roughly divide it into long-term RIT, Region hole, Region overlap, table description file loss, meta table hdfs path empty, meta table data loss, etc. according to the type. Below I will discuss them respectively. These types of faults are analyzed and fixed:
3.1 RIT
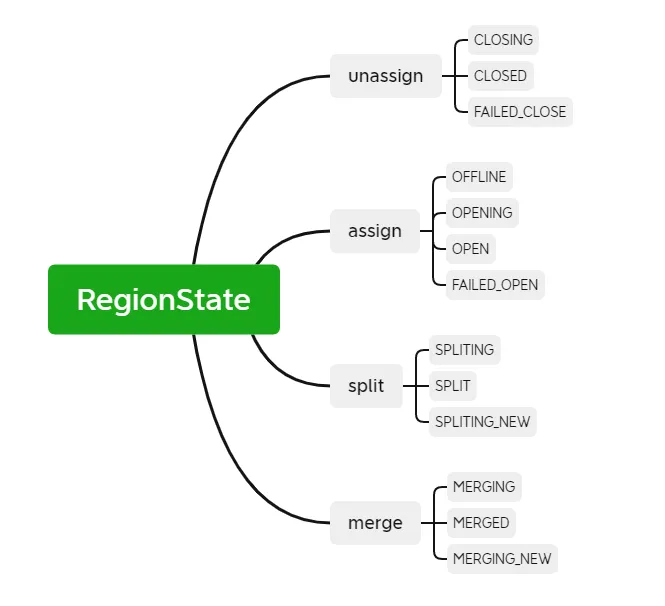
RIT (Region In Transition) refers to the ongoing state transition in the HBase cluster. The following operations will cause the state of the Region in the HBase cluster to change. For example, the RegionServer is down, the Region is splitting, merging, and other operations. The Region state mainly includes the following Twelve states and transformation diagram:
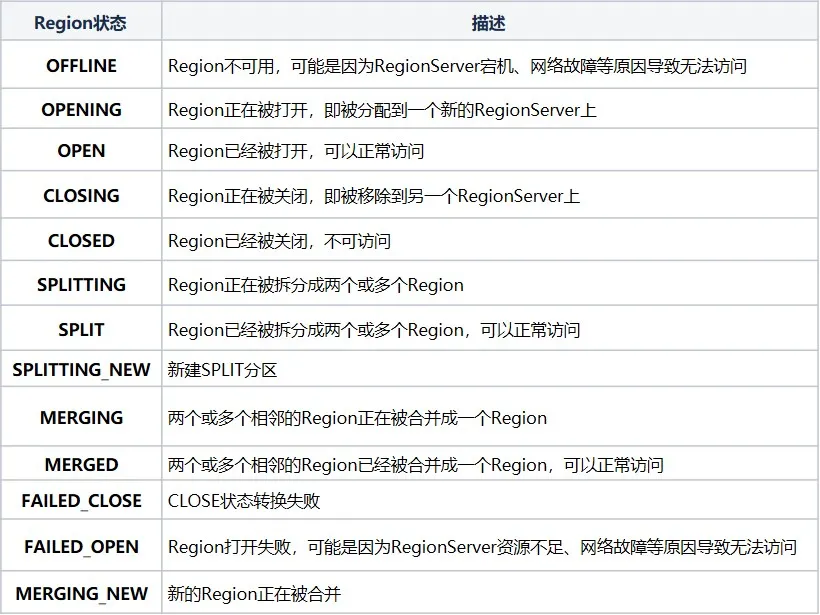
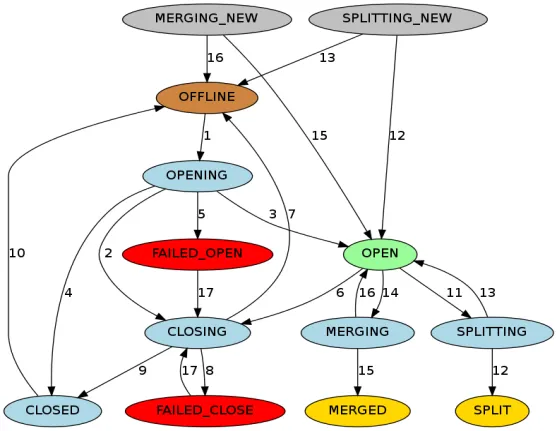
In order to be more clear about the Region status, we can divide it into assign, unassign, split, and merge according to the operation type. If the RegionServer is down or abnormal, data is damaged or errors occur during the operation, RIT will appear. Although RIT is often encountered in HBase operation and maintenance problem, but if the underlying logic is clear, it will be easier to deal with RIT problems. HBase clusters have RIT repair capabilities. Most cases can be restored normally without manual intervention. Manual intervention is required only when RIT occurs for a long time. So what is long-term Time for RIT? Why does long-term RIT occur?
If you have used HBase 1.x and HBase 2.x versions, you will obviously feel that RIT is less common in HBase 2.x. In fact, the operation of the Region is mainly to transfer the Region through the AssignmentManager class. Comparing the codes of the two versions, we found that hbase.assignment.maximum. The default value of the attempts parameter (number of assign retries) is different in the two versions. The number of retries in HBase 2.4.8 is the maximum integer Integer.MAX_VALUE (while the value defaults to 10 in HBase 1.x). This is why in HBase Reasons for long-term RIT are relatively rare in 2.x.
RIT processing method:
-
RIT will occur when creating or deleting large tables. This is mainly due to the large number of Regions and the high pressure on the cluster, which results in long assign and unassign response times. For this type of problem, HBase generally does not require manual intervention and can heal itself.
-
If the cluster version is 1.x, you can appropriately adjust the hbase.assignment.maximum.attempts value to increase the number of retries. For example, FAILED_OPEN and FAILED_CLOSE can usually self-heal, or manually execute the assign command to assign each Region online (if there are many Regions, switch to HMaster repair).
-
If Region allocation fails and there is no RegionServer, manual assignment cannot be restored. For example, Region is assigned to bogus.example.com , and nodes 1 and 1 can only be restored by switching HMaster.
Questions to think about:
Why can't the Region go online normally even after manual intervention and can it be restored by switching HMaster? (Refer to HMaster startup process TransitRegionStateProcedure, HMaster class source code)
3.2 Region Hole
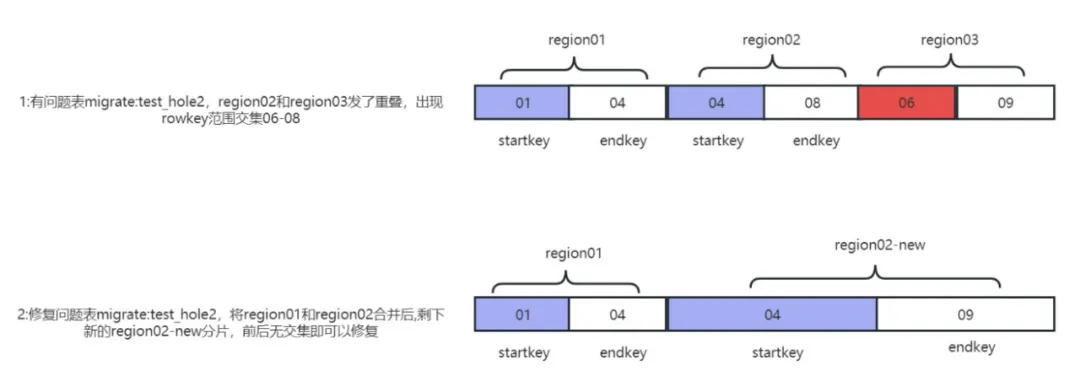
When we create an HBase table, if we carefully analyze the Region rules, we will be surprised to find that the Region startkey and endkey belong to continuous intervals that are closed on the left and open on the right. What problems will occur if suddenly one of these intervals is missing (as shown below)?
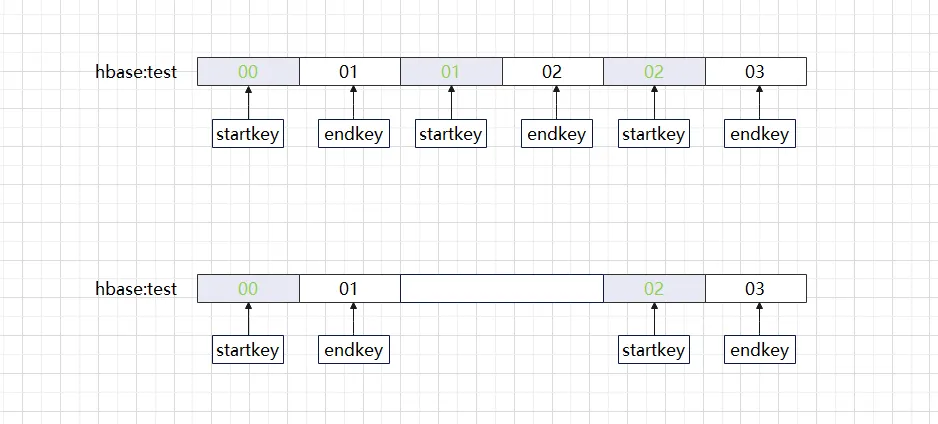
The above situation is what we often call a hole in the Region. If you use the HBase hbck tool to check, you will see the error message ERROR: There is a hole in the region chain between 01 and 02. You need to create a new .regioninfo and region dir in hdfs to plug the hole. When a hole appears in an HBase cluster, it often cannot heal itself and requires manual intervention to return to normal. Now that we know that a Region is missing, wouldn’t it be enough if we just fill in the Region in the blank interval? The normal approach is to first add back the blank Region, check whether the meta table information is correct, and finally go online with the Region. If this series of operations are done manually, it will not only be error-prone but also take a long time. Here are the different versions. HBase repair method, in fact, although the processing methods of different versions are slightly different, the processing process is the same.
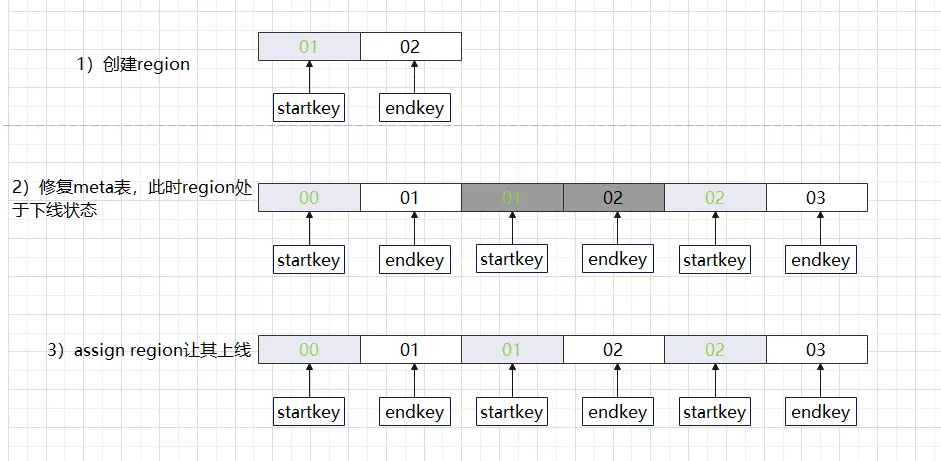
Region hole processing method:
(1) HBase 1.x repair method
-
HBase hbck –fixHdfsHoles : Create empty Region file path on hdfs
-
HBase hbck -fixMeta : Repair the meta table data where the Region is located
-
HBase hbck –fixAssignments : Region after online repair
-
Or HBase hbck –repairHoles is equivalent to a combination of (fixHdfsHoles, fixMeta, fixAssignments)
(2) HBase 2.4.8 repair method (refer to the hbase-operator-tools tool later)
Since HBase 2.4.8 does not provide relevant commands to add Region directory operations, it is relatively troublesome. In fact, many tool classes in HBase 2.4.8 provide methods for creating Regions, and the HBaseTestingUtility class in the hbase-server-2.4.8-test package provides them. In order to operate the Region-related entrance, our solution below mainly focuses on recovery based on this method.
-
extraRegionsInMeta -fix : First delete the records that do not exist in the hdfs directory in the meta table.
-
HBaseTestingUtility.createLocalHRegion : Create hdfs file path to ensure Region continuity
-
addFsRegionsMissingInMeta : Add new Region information to the meta table (the Region id will be returned after the addition is successful)
-
assigns : Finally put the newly added Region online
3.3 Region overlap
Since there will be holes in the Region, will this happen? Will there be multiple identical startkeys and endkeys? The answer is yes. If the startkey and endkey of multiple Regions are the same Region, then we call this situation Overlapping Regions. Region overlap is difficult to simulate in HBase and is also a difficult problem to handle. If we do hbck check and this kind of log appears ERROR: Multiple regions have the same startkey: 02

Another type of overlapping Region intersects with the rowkey range of one or two adjacent shards. This type of problem is collectively called the overlap problem. For this more difficult scenario, we use self-developed tools to simulate the recurrence of the overlap problem and repair the overlap with one click. (folding) and hole (hole) problems.
overlap problem simulation function
The problem of Region overlap is actually two different Regions. The ranges of rowkeys overlap. For example, the startkey and endkey of Region01 are (01,03), and the range of another Region02 is (01,02). In this way, the two Regions intersect ( 01,02), hbck detection will report an overlap problem.
In the production environment, the overlap problem will only occur when the region is split and the machine hangs up at the same time. The conditions are relatively harsh and it is difficult to reproduce the problem. Being able to reproduce the problem is important for subsequent repairs and fault drills. The overlap problem Reproduction principle:
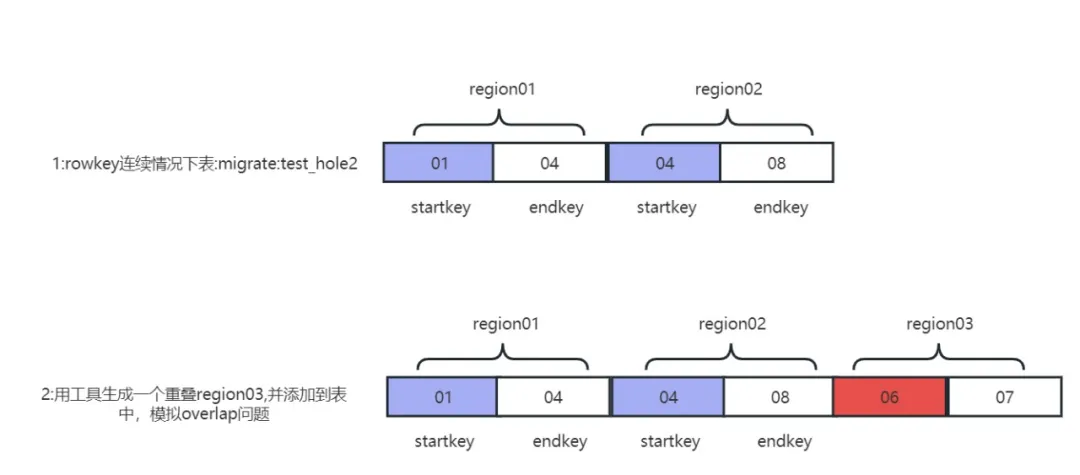
overlap problem recurrence
1) Generate a Region shard with overlapping rowkey ranges:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=createRegion -DRegion.startkey=06 -DRegion.endkey=07 hbase-meta-tool-0.0.1.jar
2) Move the overlap problem Region to the table directory:
sudo -uhdfs hdfs dfs -mv /tmp/.tmp/data/migrate/test_hole2/c8662e08f6ae705237e390029161f58f /hbase/data/migrate/test_hole2
3) Delete the meta table information of the normal table migrate:test_hole2:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
4) Reconstruct the overlap problem table metadata information:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
5) After restarting the cluster, hbck reported that the Region overlapped c8662e08f6ae705237e390029161f58f, and the overlap problem was successfully reproduced.

Method 1: Repair overlaps and holes with one click
Suitable for cases where the number of folds does not exceed 64, the self-developed tool hbase-meta-tool can be used to merge the ranges of adjacent regions with rowkey intersections, and generate new regions if there are holes or missing ranges, so that the problem can be repaired. Principle of problem repair As shown in the picture:
1) Fix cluster overlap and hole problems:
java -jar -Dfix.operator= fixOverlapAndHole hbase-meta-tool-0.0.1.jar
Method 2: Large-scale folding repair
Suitable for large-scale folding of more than thousands or tens of thousands of cases to repair server-side abnormality, take the following repair methods
1) Clear the metadata of tables with folding problems in one click:
java -jar -Drepair.tableName=migrate:test1 -Dzookeeper.address=zkAddress -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) Back up the original table data:
hdfs dfs -mv /hbase/data/migrate/test/ /back
3) Delete the original table and import the backup data for each Region shard:
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /back/test/region01-regionN migrate:test1
3.4 Meta table data repair
We may encounter the following difficult problems in HBase online clusters:
-
The coprocessor table is configured incorrectly, the coprocessor path cannot be found, and the jar cannot be found during loading of the Region, causing the cluster to hang repeatedly and the drop command cannot delete it;
-
The number of elements in the HBase meta table is wrong, the startcode is incorrect, the server's table cannot be found during the online process, and the table never comes online.
We need to repair the problem table independently without stopping the service without affecting other table services in the cluster.
Meta data repair of problem table
1) Assuming there is a problem with table migrate:test1, you can delete the problem table metadata with one click:
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) Read the contents of the .regioninfo folder of the hdfs table and reconstruct the correct metadata with one click:
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
3.5 meta broken
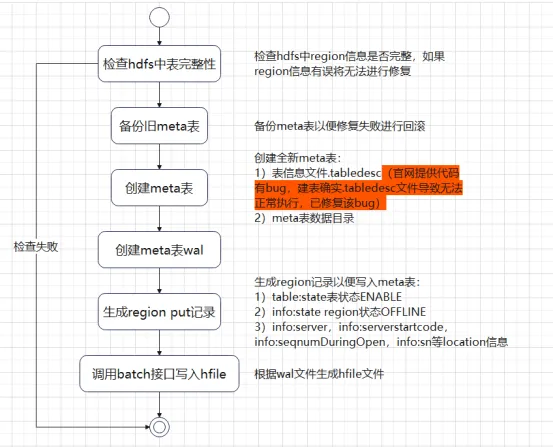
The above five situations are all repaired under the premise that the meta table is online normally. If the meta table data is damaged and cannot be online, how should we repair it? Usually we think of rebuilding the meta table and then writing the Region information into the meta table. If the cluster is offline, the HBase shell or HBase api usually cannot execute create to build the table.
We analyzed the meta table initialization class InitMetaProcedure and found that the meta table creation process is roughly divided into two steps:
1) Create the Region directory and .tabledesc file
2) Allocate Region and go online.
InitMetaProcedure core source code:
InitMetaProcedure
protected Flow executeFromState(MasterProcedureEnv env, InitMetaState state) throws ProcedureSuspendedException, ProcedureYieldException, InterruptedException {
try {
switch (state) {
case INIT_META_WRITE_FS_LAYOUT:
Configuration conf = env.getMasterConfiguration();
Path rootDir = CommonFSUtils.getRootDir(conf);
TableDescriptor td = writeFsLayout(rootDir, conf);
env.getMasterServices().getTableDescriptors().update(td, true);
setNextState(InitMetaState.INIT_META_ASSIGN_META);
return Flow.HAS_MORE_STATE;
case INIT_META_ASSIGN_META:
addChildProcedure(env.getAssignmentManager().createAssignProcedures(Arrays.asList(RegionInfoBuilder.FIRST_META_RegionINFO)));
return Flow.NO_MORE_STATE;
default:
throw new UnsupportedOperationException("unhandled state=" + state);
}
} catch (IOException e) {
}
private static TableDescriptor writeFsLayout(Path rootDir, Configuration conf) throws IOException {
LOG.info("BOOTSTRAP: creating hbase:meta region");
FileSystem fs = rootDir.getFileSystem(conf);
Path tableDir = CommonFSUtils.getTableDir(rootDir, TableName.META_TABLE_NAME);
if (fs.exists(tableDir) && !fs.delete(tableDir, true)) {
LOG.warn("Can not delete partial created meta table, continue...");
}
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(conf, fs, rootDir);
HRegion.createHRegion(RegionInfoBuilder.FIRST_META_RegionINFO, rootDir, conf, metaDescriptor, null).close();
return metaDescriptor;
}
We can refer to the InitMetaProcedure code logic to write corresponding tools to create tables and go online. After the meta table goes online, we only need to write the Region information of each table into meta and assign all Regions to go online to restore the normal state of the cluster. Through the above process, we found that the meta table repair process is not that complicated. However, if there are a large number of tables in the production environment or there are thousands of regions in individual large tables, then manual addition becomes very time-consuming. We will introduce the process below that has always been relatively simple. Solution (HBase 1.x hbck tool, HBase 2.x hbase-operator-tools), let’s take a look at the offline repair process.
HBase 1.x fixes
-
Stop the HBase cluster
-
sudo -u hbase hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair -fix
-
Restart the cluster to complete the repair.
HBase 2.4.8 repair method (hbase-operator-tools tool)
1) Automatically generate meta table based on hdfs path
-
Stop the HBase cluster
-
sudo -u hbase hbase org.apache.hbase.hbck1.OfflineMetaRepair -fix
-
Restart the cluster to complete the repair.
2) Single table repair method
-
Delete the HBase root directory in zookeeper
-
Delete the hdfs WALs directory where HMaster and RegionServer are located
-
After restarting the cluster, there is no data in meta and the cluster cannot enter the normal state.
-
Execute the add Region command to add the hbase:namespace, hbase:quota, hbase:rsgroup, and hbase:acl four-character tables to the cluster. After the addition is completed, the log will print the Regions followed by assigns and these tables. These Regions need to be recorded for Next assign operation.
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-tools.jar addFsRegionsMissingInMeta hbase:namespace hbase:quota hbase:rsgroup hbase:acl
- Add the print Region in the previous step online
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-hbck2.jar assigns regionid
- The business table is online (you only need to repeat steps 4-5 to gradually bring the business table online)
Precautions
(If there are many regions in the business table and the fifth region is not assigned, all the regions cannot be brought online successfully. You need to disable and enable the performance to go online normally)
Note: The hbase-operator-tools OfflineMetaRepair tool has the following bugs that need to be fixed.
1. The meta table created by the HBaseFsck createNewMeta method lacks the .tabledesc file.
before fixing:
TableDescriptor td = new FSTableDescriptors(getConf()).get(TableName.META_TABLE_NAME);
After modification:
FileSystem fs = rootdir.getFileSystem(conf);
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(getConf(), fs, rootdir);
2. The default Region state of HBaseFsck generatePuts is CLOSED because HMaster only goes online in the OFFLINE state when it restarts (if it is CLOSED, the workload of manually going online one by one is very huge)
before fixing:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.CLOSED);
After modification:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.OFFLINE);
shortcoming
1) Offline repair requires stopping the cluster service. The stop time depends on the repair time (about 10-15 minutes).
2) If there are problems such as Region overlap and holes, they need to be processed manually before executing the OfflineMetaRepair offline repair command.
4. hbase-operator-tools tool
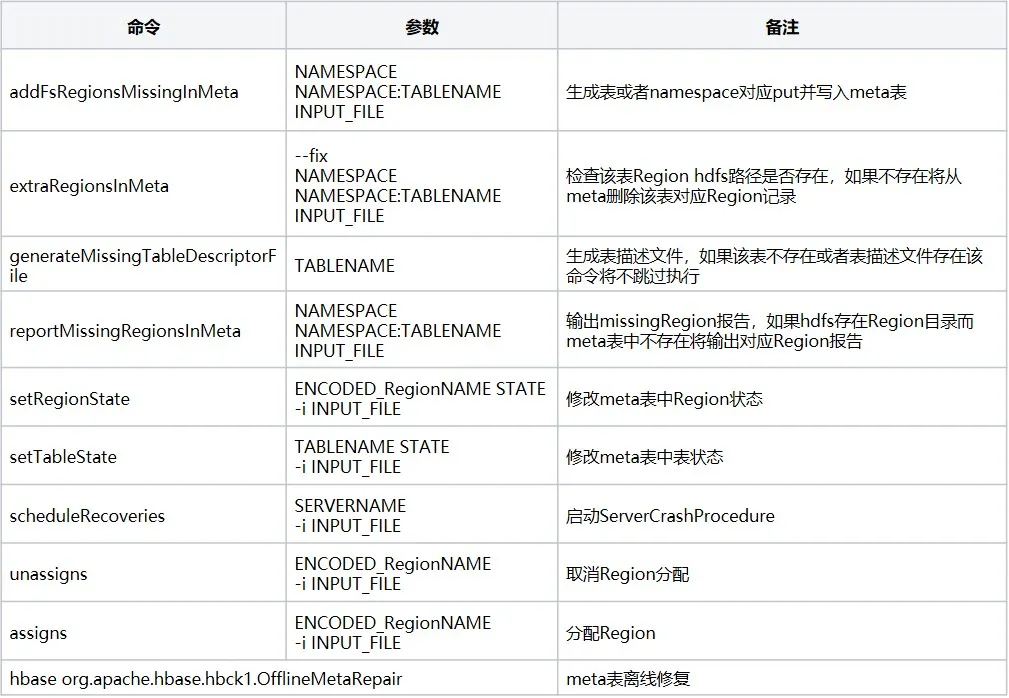
hbase-operator-tools is a set of tools in HBase used to assist HBase administrators in managing and maintaining HBase clusters. hbase-operator-tools provides a series of tools, including backup and recovery tools, Region management tools, data compression and movement tools, etc., which can help administrators better manage HBase clusters and improve the stability and reliability of the cluster. You need to compile the source code before you can use it. The source code git address . Common commands are as follows:
5. Summary
The data accuracy of the HBase meta table is crucial to the normal operation of the HBase cluster. How to ensure that the meta table data is correct and how to quickly repair the data after it is damaged is extremely important. If you do not have a comprehensive understanding of meta, you will be at a loss every time the cluster fails. . This article mainly focuses on the analysis of the meta table structure loading process, common problems and related repair methods. We can roughly divide the above repair methods into the following two categories:
-
Online repair : The meta table can be repaired normally through hbck and self-developed tools to ensure data integrity.
-
Offline repair : The meta table cannot go online normally. The meta table is reconstructed based on the Region information in HDFS to restore the HBase service.
If the cluster scale is relatively large and the offline repair time is relatively long, the cluster needs to stop services for a long time. In most cases, the business cannot tolerate it. Table-level repairs can be performed based on the actual situation (unless the meta table file is damaged and cannot be brought online normally). It is recommended to perform hbck checks on the cluster regularly. Once meta information inconsistency occurs, repair it as soon as possible to avoid the spread of the problem (for example, if the meta information has been messed up and the cluster restarts and the messed up Region will fail to assign, other Regions will not be able to go online normally). If the regular inspection finds that there is meta information mess in the business table, restart it directly. The meta table deletes the table information and adds the Region back to the meta table based on the hdfs path information (the addFsRegions-MissingInMeta command can correctly add the Region to the meta table based on the hdfs path).
Reference article:
High school students create their own open source programming language as a coming-of-age ceremony - sharp comments from netizens: Relying on the defense, Apple released the M4 chip RustDesk. Domestic services were suspended due to rampant fraud. Yunfeng resigned from Alibaba. In the future, he plans to produce an independent game on Windows platform Taobao (taobao.com) Restart web version optimization work, programmers’ destination, Visual Studio Code 1.89 releases Java 17, the most commonly used Java LTS version, Windows 10 has a market share of 70%, Windows 11 continues to decline Open Source Daily | Google supports Hongmeng to take over; open source Rabbit R1; Docker supported Android phones; Microsoft’s anxiety and ambitions; Haier Electric has shut down the open platform