
1. Introduction to new product launch business
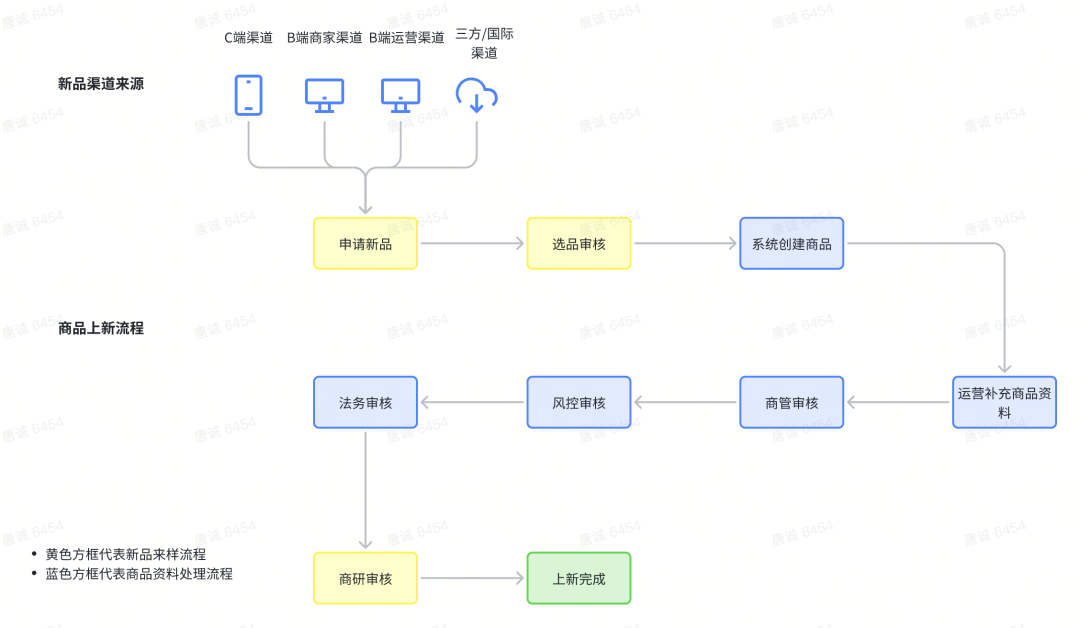
Product listing means putting a new product on the Dewu platform. A complete product listing process starts with submitting new product applications from various sources and channels. It needs to go through multiple rounds of review by different roles, mainly including:
-
Product selection review: Determine whether it meets the shelf requirements based on the information submitted in the new product application;
-
Product data review: Review of product data for accuracy and completeness, including multiple rounds of business management, risk control, and legal review;
-
Business research review: Business research review is a judgment on the product’s ability to identify and support on the platform, which is also a feature of the Dewu business.
In these rounds of review, the product selection review and business research review belong to the new product sampling process. They only appear in the new business of the product. They determine whether the product can be sold on the Dewu platform; the product data review belongs to the product data processing. process, he determines whether the current product information meets the requirements for display on the C-side.
Therefore, in the system implementation, the state flow of the new product incoming sample process and the product data processing process must be involved. The former involves the new product incoming sample table, and the latter is mainly the product SPU main table. This article focuses on the flow and state machine of the new product incoming sample process. Access, the source channel attribute of the new product sampling process is very obvious, and there are big or small differences in the business logic and processes of different channels.
2. Why consider accessing a state machine?
-
There are a large number of status enumeration values, and the conditions for their transfer are unclear. To understand the business process, you must study the code carefully, and the cost of getting started and maintaining it is high.
-
The transfer of states is completely arbitrarily specified by the code, and there are risks in arbitrarily transferring between states.
-
Some state transfers do not support idempotence, and repeated operations may cause unexpected consequences.
-
The cost and risk of transferring new and modified states are high, the scope of code modifications is uncontrollable, and testing requires regression of the entire process.
3. Status involved in the new product launch process
New product sample status enumeration
The status field corresponding to the new product sample table contains the following enumeration values (moderately simplified for convenience of explanation):
public enum NewProductShowEnum {
DRAFT(0, "草稿"),
CHECKING(1, "选品中"),
UNPUT_ON_SALE_UNPASS(2, "选品不通过"),
UNPUT_ON_SALE_PASSED(3, "商研审核中"),
UNPUT_ON_SALE_PASSED_UNSEND(4, "商品资料待审核"),
UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT(5, "鉴别不通过"),
UNPUT_ON_SALE_PASSED_SEND(6, "请寄样"),
SEND_PRODUCT(7, "商品已寄样"),
SEND_PASS(8, "寄样鉴别通过"),
SEND_REJECT(9, "寄样鉴别不通过"),
GONDOR_INVALID(10, "作废"),
FINSH_SPU(11, "新品资料审核通过"),
}
SPU status enumeration
The status field corresponding to the product SPU main table contains the following enumeration values (moderately simplified for convenience of explanation):
public enum SpuStatusEnum {
OFF_SHELF(0, "下架"),
ON_SHELF(1, "上架"),
TO_APPROVE(2, "待审核"),
APPROVED(3, "审核通过"),
REJECT(4, "审核不通过"),
TO_RISK_APPROVE(8, "待风控审核"),
TO_LEGAL_APPROVE(9, "待法务审核"),
}
The status transfer part of the SPU involved in the new product launch business process is subject to the status transfer of the product. The product status transfer is also connected to the state machine (but it is not the content discussed in this article). This article will mainly discuss the status of the new product sample table. Status transfer.
4. All events regarding new product samples
-
Save new product draft
-
Submit new product application
-
Product selection passed
-
Product selection failed
-
Resubmit after product selection is rejected
-
Initiate business research review
-
Business research review-support identification
-
Business research review-identification is not supported
-
Business research review - product information is incorrect
-
SPU review rejected for more than X days
-
Initiate sending samples
-
Sample delivery progress update
12 in total.
5. New product sample status transfer
As mentioned above, different product source channels have different new product launch processes, which means that the status flow of different channels is also different. The following is an illustration of B-side seller channels:
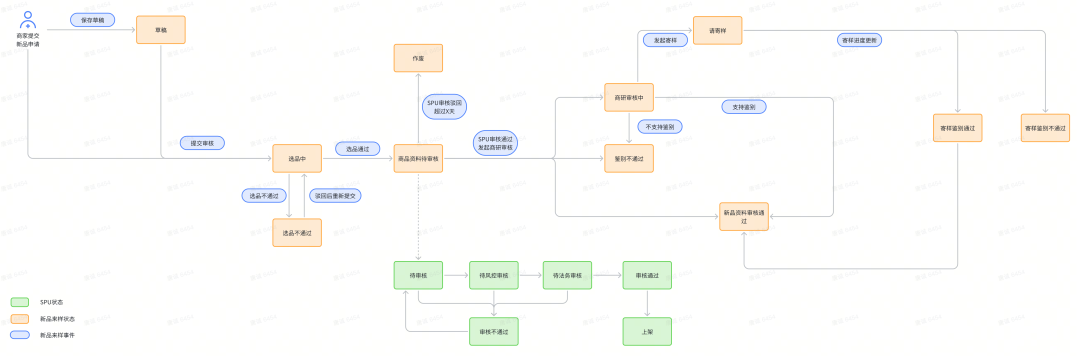
In the figure, the orange box represents the status of new product incoming samples, the green box represents the SPU status, the blue rounded box represents the event that triggers the state change, and the places connected by arrows represent the flow from the current state to the next state.
Note that when certain events are triggered, the target state that needs to be transferred to is not fixed. A series of logical judgments are required to determine the target state to which the event will eventually flow.
6. State machine technology selection
Choose Spring StateMachine as the actual state machine framework. For specific processes and details, please refer to this article https://mp.weixin.qq.com/s/TqXMtS44D4w6d1-KLxcoiQ . This article will not go into details.
7. Difficulties faced by state machine access
At present, the code for new product samples still faces the problem of code coupling between different channels, which needs to be solved together in this access. Otherwise, the cost of state machine access will be very high, the quality will be difficult to guarantee, and subsequent maintenance will be more difficult. Even if the above-mentioned state machine modifications are made under ideal conditions, without other modifications, there will still be two problems:
-
Coupling of target state judgment logic;
-
The coupling that actually performs the action.
It can be simply understood that there is a very large interface in the implementation of the state machine's guard (to determine whether the prerequisites for execution are met) and action (the actual execution of the action), which contains different methods for determining the target status and executing different actions among all channels. Code, it is very difficult to read to understand what a certain channel does specifically.
The problem is concentrated in the code of the product selection review and business research review interface for new product incoming samples (this part is also the part with the most and most complex business logic for new product incoming samples). It is mixed with all the pass-fail logic, product selection and The logic of business research is all mixed together. The code is long and not readable. There are also problems with large transactions (multiple RPC calls in the transaction). Therefore, these codes need to be split while the state machine is connected. and mergers, specifically including:
-
Codes for different channels are split using strategy mode;
-
Different states and different operation event processing logic are summarized into the guard and action classes of different states & events of the state machine;
-
The same code processing logic in different channels is encapsulated into individual code modules and called in each channel.
The overall transformation method is shown in the figure below:
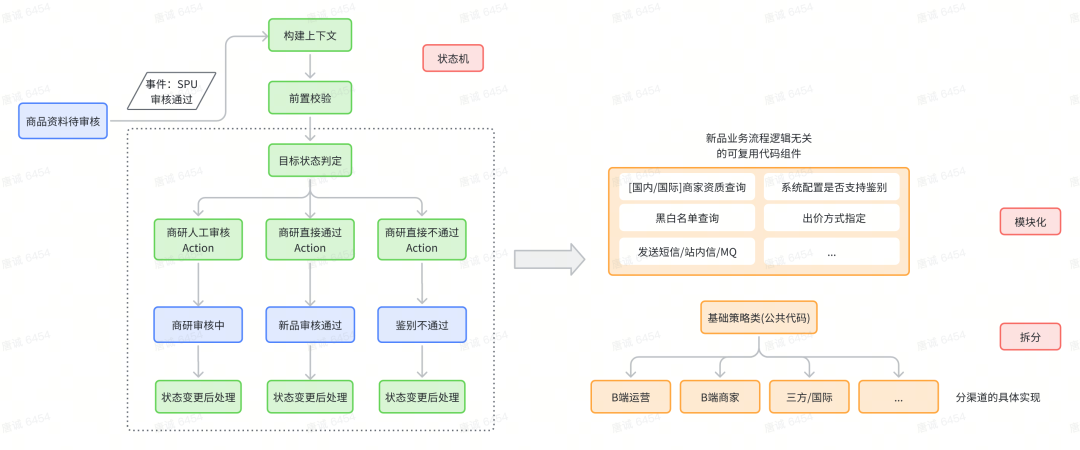
8. Expected income
As can be understood from the above, although it is a state machine access, it actually needs to complete two aspects of transformation. One is to complete the decoupling of the business code divided into channels and operations in the entire new process. This part of the transformation, were able:
-
Solve major transaction problems in the previous new product application link, such as: registration submission and new product review;
-
Business isolation between product source channels makes the scope of code changes more controllable and more conducive to testing;
-
Improve code scalability, lower the threshold for code understanding, and improve iterative development efficiency for daily needs.
The second is the access to the state machine, which can solve the state flow problem in the new product sampling process, including:
-
Unified and centralized management of status change rules to facilitate learning and later maintenance;
-
Avoid illegal and repeated status transfers;
-
It becomes easier to adjust the order between new states and state processes, and code modifications are more controllable.
9. Detailed design
The rationale for splitting by channel
Initiating new product samples from different product source channels is a process in which different roles submit new products through different terminals. The combination of roles and terminals is fixed and cannot be combined at will. Looking at the roles or terminals alone, they do not have a common business Characteristics, only when specific roles are determined can a complete business process be determined.
The ability to apply for new products in each channel is also different. For example, merchants have the most complete grasp of product information, so they can fill in a complete product information when applying for new products, and there are more business processes than other channels. In comparison, Only a small amount of product information can be filled in on the App side. Once the application is rejected, it cannot be modified and submitted. Therefore, differences between different channels are natural and may continue to exist subject to the channels themselves.
Therefore, it is reasonable and necessary to split according to channels under certain operations.
Business operations are decoupled by channel
Common interface for business operations
Single records of many important nodes in new product samples (batch operations will also be converted to single processing) business operations (such as submitting new product applications, product selection review, business research review) can be abstracted into " request preprocessing -> operation verification" -> Execute business logic -> Persistence operations -> Related post-processing actions ", so a common interface class is designed to carry the execution process of different business operations for new products and samples from different channels:
public interface NspOperate<C> {
/**
* 支持的商品来源渠道
* @return
*/
Integer supportApplyType();
/**
* 支持的操作类型
* @return
*/
String operateCode();
/**
* 请求预处理
* @param context
*/
void preProcessRequest(C context);
/**
* 校验
* @param context
*/
void verify(C context);
/**
* 执行业务逻辑
* @param context
*/
void process(C context);
/**
* 执行持久化
* @param context
*/
void persistent(C context);
/**
* 后处理
* @param context
*/
void post(C context);
}
Some notes:
-
Each event of the subsequent state machine corresponds to the operation type of the interface one-to-one. In addition, other operation types can also be defined for scenarios that do not involve state transfer (for example: editing new product applications, creating SPUs based on new product applications).
-
The definition of the process method is relatively broad. In different business operations, the actual execution content may be very different. For example, when submitting a new product review, you may only perform some data assembly actions, while in a business research review, you need to analyze the goals after this operation. Judgment of status. Therefore, subclasses can further split and define new methods to be implemented based on their own business needs.
-
The persistent persistence method is defined separately to support adding transactions only to this method. The current system code actually has a similar design, but the transaction is too broad, including the entire execution process such as verification and business processing. It may include various RPC calls, which is also one of the important reasons for large transactions. Therefore, it is clear here that the implementation of this method only reads and writes DB operations and does not contain any business logic.
-
Each implementation of this interface uses "product source channel + operation type" to form a unique key for Spring Bean management. At the same time, in order to take into account that some operations do not distinguish the product source, it is allowed to define a special applyType (such as -1) to represent the current Implementation supports all channels. When obtaining the implementation, optimize to obtain the implementation of the current channel. If not found, try to find the implementation of all channels:
public NspOperate getNspOperate(Integer applyType, String operateCode) {
String key = buildKey(applyType, operateCode);
NspOperate nspOperate = operateMap.get(key);
if (Objects.isNull(nspOperate)) {
String generalKey = buildKey(-1, operateCode);
nspOperate = operateMap.get(generalKey);
}
AssertUtils.throwIf(Objects.isNull(nspOperate), "NspOperate not found! key = " + key);
return nspOperate;
}
Business operation implementation class
According to the current business scenario, in order to facilitate the reuse of some codes, the implementation of business operations has up to three levels of inheritance relationships:
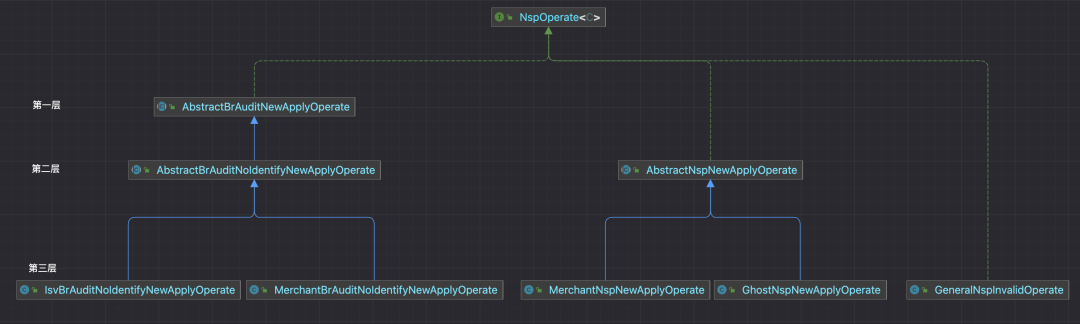
-
The first level: Dimensions for aggregating operation types (business events), such as business research review, where you can define common codes and custom methods in business research review, such as: general input parameter verification for business research review, fields are not Empty and the like.
-
Second level: Specific to the operation type dimension (business events), such as business research review - supports identification, business research review - does not support identification, etc. Here you can define the common codes of all product source channels under the operation type dimension. For example: the reason is required when identification is not supported, and business research review calls a series of judgment logic from multiple systems.
-
The third layer: Specific implementation at the product source channel level, you can reuse the code in the parent class.
Not every business operation requires these three layers of implementation. In actual use, three situations will occur, such as:
-
There is only one layer: samples of new products are invalidated, regardless of the source channel of the product. All channels use the same logic, and only one implementation class is enough.
-
There are only two levels: submit a new product application and distinguish between different product source channels.
-
There are three levels: new product commercial research review. Commercial research review is also divided into multiple operation types (business events), such as: commercial research review - supports identification, commercial research review - does not support identification, commercial research review - initiates sample sending, etc., each Each commodity source channel has its own implementation under each operation type.
State machine access
State machine definition
Judging from the status flow diagram above, the status flow of new products and samples is relatively clear, but in fact there will be some minor differences in the status process of each channel. In order to avoid incomplete splitting of source channels, comprehensive considerations are also taken. The cost of state machine configuration is not high, so it is decided that each channel builds its own state machine configuration.
Taking the C-side channel as an example, the configuration of the state machine is as follows:
@Configuration
@Slf4j
@EnableStateMachineFactory(name = "newSpuApplyStateMachineFactory")
public class NewSpuApplyStateMachineConfig extends EnumStateMachineConfigurerAdapter<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> {
public final static String DEFAULT_MACHINEID = "spring/machine/commodity/newspuapply";
@Resource
private NewSpuApplyStateMachinePersist newSpuApplyStateMachinePersist;
@Resource
private NspNewApplyAction nspNewApplyAction;
@Resource
private NspNewApplyGuard nspNewApplyGuard;
@Bean
public StateMachinePersister<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> newSpuApplyMachinePersister() {
return new DefaultStateMachinePersister<>(newSpuApplyStateMachinePersist);
}
@Override
public void configure(StateMachineConfigurationConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> config) throws Exception {
config.withConfiguration().machineId(DEFAULT_MACHINEID);
}
@Override
public void configure(StateMachineStateConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> config) throws Exception {
config.withStates()
.initial(NewProductShowEnum.STM_INITIAL)
.state(NewProductShowEnum.CHECKING)
.state(NewProductShowEnum.UNPUT_ON_SALE_UNPASS)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.choice(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.choice(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT)
.state(NewProductShowEnum.OTHER_UNPASS_FOR_SPU_STUDYER)
.state(NewProductShowEnum.FINSH_SPU)
.state(NewProductShowEnum.GONDOR_INVALID)
.states(EnumSet.allOf(NewProductShowEnum.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> transitions) throws Exception {
transitions.withExternal()
//提交新的新品申请
.source(NewProductShowEnum.STM_INITIAL)
.target(NewProductShowEnum.CHECKING)
.event(NewSpuApplyStateMachineEventsEnum.NEW_APPLY)
.guard(nspNewApplyGuard)
.action(nspNewApplyAction)
//选品不通过
.and().withExternal()
.source(NewProductShowEnum.CHECKING)
.target(NewProductShowEnum.UNPUT_ON_SALE_UNPASS)
.event(NewSpuApplyStateMachineEventsEnum.OM_PICK_REJECT)
.guard(nspOmRejectGuard)
.action(nspOmRejectAction)
//选品通过
.and().withExternal()
.source(NewProductShowEnum.CHECKING)
.target(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.event(NewSpuApplyStateMachineEventsEnum.OM_PICK_PASS)
.guard(nspOmPassGuard)
.action(nspOmPassAction)
//发起商研审核
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.target(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.event(NewSpuApplyStateMachineEventsEnum.START_BR_AUDIT)
.and().withChoice()
.source(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.first(NewProductShowEnum.UNPUT_ON_SALE_PASSED, nspStartBrAuditWaitAuditStatusDecide, nspStartBrAuditWaitAuditChoiceAction)
.then(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT, nspStartBrAuditRejctStatusDecide, nspStartBrAuditRejctChoiceAction)
.last(NewProductShowEnum.FINSH_SPU, nspStartBrAuditFinishChoiceAction)
//商研审核-支持鉴别
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.FINSH_SPU)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_ALL)
.guard(nspBrAuditSupportAllGuard)
.action(nspBrAuditSupportAllAction)
//商研审核-商品信息有误
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.OTHER_UNPASS_FOR_SPU_STUDYER)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_WRONG_INFO)
.guard(nspBrAuditWrongInfoGuard)
.action(nspBrAuditWrongInfoAction)
//商研审核-不支持鉴别
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE)
.guard(nspBrAuditRejectGuard)
.action(nspBrAuditRejectAction)
;
}
}
The status of the state machine is completely mapped with the status field in the new product sample DB table, and the state machine events are completely matched with the events in the above figure. In the new product samples, there are some scenarios that require a series of logical judgments to arrive at the target state after receiving an event. Here, the Choice State of the state machine will be used to complete the judgment and transfer of the target state.
Let’s clarify which elements related to the state machine are separated independently and which ones are shared:

It can be seen that only the configuration class of the state machine is different for each channel, so the cost is not high. How the guard and action implementation classes are shared by all channels will be explained below.
Implementation of Guard and Action
As can be seen from the specific configuration of the state machine above, there are two types of state flows involved in the new product sampling process:
-
The target status after triggering the event is fixed. For example, if the product selection failure event is triggered during the product selection review, the target status of the new product application will be determined as product selection failure;
-
The target state after triggering the event needs to be judged by code logic. For this reason, the choice state is introduced in the state machine configuration. For example, in the event of initiating a commercial research review, the target state of a new product application may be that identification is not supported directly, or the new product application may be directly passed. , it may also require manual review.
In the design of Spring state machine, the responsibilities of these two types of state flows, gurad and action will be different:
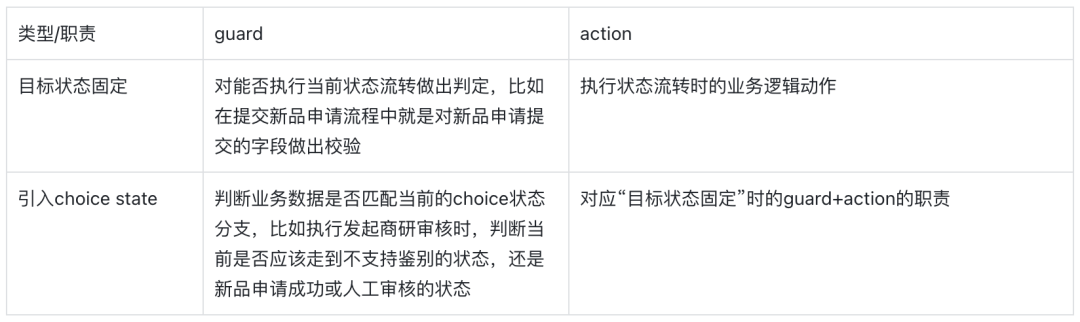
Therefore, the implementation logic of these two types of guard and action will be different.
However, for the guard and action under the same event/Choice state, different product source channels can be shared, because the business code split according to the product source channel has been implemented, and only needs to be routed to the specific NspOperate in the implementation Business implementation class is enough. Examples are given below:
Guard with fixed target state:
@Component
public class NspNewApplyGuard extends AbstractGuard<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected boolean process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.NEW_APPLY.getCode()); //固定的事件code
//做请求的预处理
nspOperate.preProcessRequest(ctx);
//对业务数据做校验,校验不通过即抛出异常
nspOperate.verify(ctx);
//正常执行完上述2个方法,代表是可以执行的
return Boolean.TRUE;
}
}
In guard, you only need to obtain the NspOperate implementation class based on the product source and fixed event code, and call the preProcessRequest and verify methods of NspOperate to complete the verification.
Action with fixed target state:
@Component
public class NspNewApplyAction extends AbstractSuccessAction<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, CategorySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected void process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.NEW_APPLY.getCode()); //固定的事件code
//执行业务逻辑
nspOperate.process(ctx);
//持久化
nspOperate.persistent(ctx);
//后处理
nspOperate.post(ctx);
}
}
In the action, the NspOperate implementation class is also obtained based on the product source and fixed event code, and the last few methods of NspOperate are called to complete the business operation.
Guard in Choice state:
Guard needs to determine the target status based on the current channels and events. Here, a separate interface is abstracted for guard to implement calls. If similar logic is needed in NspOperate, this separate interface can also be referenced, so there will be no code duplication:
public interface NspStatusDecider<C, R> {
/**
* 支持的商品来源渠道
* @return
*/
Integer supportApplyType();
/**
* 支持的操作类型
* @return
*/
String operateCode();
/**
* 判定目标状态
* @param context
*/
R decideStatus(C context);
}
@Component
public class NspBrAuditNoIdentifyGuard extends AbstractGuard<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected boolean process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspStatusDecider<NewSpuApplyContext, Result> nspStatusDecider = newSpuApplyOperateHelper.getNspStatusDecider(applyType, NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE.getCode()); //固定的事件code
//判定目标状态
Result result = nspStatusDecider.decideStatus(ctx);
ctx.setResult(result); //将判定结果放入上下文,其他的guard可以引用结果,避免重复判断
return Result.isSuccess(result); //根据判定结果决定是否匹配当前guard对应的目标状态
}
}
Action in Choice state:
@Component
public class NspBrAuditNoIdentifyAction extends AbstractSuccessAction<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, CategorySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected void process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE.getCode()); //固定的事件code
//做请求的预处理
nspOperate.preProcessRequest(ctx);
//对业务数据做校验
nspOperate.verify(ctx);
//执行业务逻辑
nspOperate.process(ctx);
//持久化
nspOperate.persistent(ctx);
//后处理
nspOperate.post(ctx);
}
}
The only difference from the action with a fixed target state is that the preProcessRequest and verify methods of NspOperate are executed.
Instead of using different guard and action implementations between different channels, use separate strategy classes to divide different channel implementations for the following two considerations:
-
It is possible to replace the state machine implementation, so the code related to the state machine implementation is not expected to be coupled with the business logic code;
-
In scenarios that do not involve state machines, there is also a need to split logic by channel, such as new product application editing, etc.
Linkage with SPU status flow during product launch process
When the new product sample enters the "Product Information Pending Review" status, the SPU state machine process will take over the subsequent SPU status flow. When the SPU status reaches "Audit Passed", the new product sample status will flow to the commercial research and review stage. During this period, each information and status change of the SPU needs to be notified of new product incoming samples (through MQ or in-application event), and then corresponding business processing is performed on the new product incoming sample records.
Subsequent extended analysis
For future changes that may be involved in the new product application process, evaluate the scalability of this transformation.
Add new product source channels
Just configure a new state machine to implement various business operations and events for the new channel without affecting existing channels.
Added status node for new product samples
Just modify the state machine configuration and add new events and corresponding implementation classes.
Adjust the order between states for new product incoming samples
Modify the state machine configuration and evaluate the modification of the business operation implementation classes involved. The scope of modification is clear and controllable.
10. Summary
We use the strategy model to decouple the business logic of different product source channels, retain commonalities, and implement their own differentiated logic to provide scalability for future changes in business requirements; through the introduction of state machines, we clarify and standardize the status of the new product process. Flow ensures that the status is transferred correctly and legally, while laying a solid foundation for future business process changes.
On the one hand, this transformation solves the stubborn problems in the current implementation and reduces the difficulty of getting started with the existing code. On the other hand, it also takes into account development efficiency. In the future, whether it is adding new source channels or modifying business processes, the scope of code modifications can be guaranteed. It is controllable and measurable without adding extra workload, and can support the business more effectively, safely and stably.
* Text/Sweet Orange
This article is original to Dewu Technology. For more exciting articles, please see: Dewu Technology official website
Reprinting without the permission of Dewu Technology is strictly prohibited, otherwise legal liability will be pursued according to law!
High school students create their own open source programming language as a coming-of-age ceremony - sharp comments from netizens: Relying on the defense, Apple released the M4 chip RustDesk. Domestic services were suspended due to rampant fraud. Yunfeng resigned from Alibaba. In the future, he plans to produce an independent game on Windows platform Taobao (taobao.com) Restart web version optimization work, programmers’ destination, Visual Studio Code 1.89 releases Java 17, the most commonly used Java LTS version, Windows 10 has a market share of 70%, Windows 11 continues to decline Open Source Daily | Google supports Hongmeng to take over; open source Rabbit R1; Docker supported Android phones; Microsoft’s anxiety and ambitions; Haier Electric has shut down the open platform