
OpenAI releases ChatGPT-4o, which means that human-computer interaction has entered a new era. Chat-GPT4o is a new model trained end-to-end across text, vision, and audio, with all inputs and outputs processed by the same neural network. This is also telling everyone that GenAI connects unstructured data, and cross-modal interactions between unstructured data are becoming increasingly easier.
According to IDC predictions, by 2025, more than 80% of the total global data will be unstructured data, and vector databases are an important component for processing unstructured data. Looking back at the history of vector databases, in 2019, Zilliz launched Milvus for the first time and proposed the concept of vector databases. The explosion of large language models (LLM) in 2023 has officially pushed vector databases from behind the scenes to the front, and thus caught up with the rapid development train.
As a related technical personnel, I can clearly feel the speed of vector database advancement in terms of technological development, and witness how vector database gradually evolves from simple ANNS ( https://zilliz.com.cn/glossary/%E8%BF%91% E4%BC%BC%E6%9C%80%E8%BF%91%E9%82%BB%E6%90%9C%E7%B4%A2%EF%BC%88anns%EF%BC%89) Shell Becoming more varied and complex. Today, I would like to discuss the development direction of vector databases from a technical perspective.
The development direction of technology must follow the changing trend of products, and the latter is determined by demand. Therefore, following the changing context of user needs can help us find the direction and purpose of technological changes. As AI technology matures, the use of vector databases has gradually moved from experimentation to production, from auxiliary products to main products, and from small-scale applications to large-scale deployment. This creates a large number of different scenarios and problems, and also promotes the corresponding technologies to solve these problems. Below we will discuss it from two aspects: cost and business needs.
01. Cost
The call for hot and cold storage in the AIGC era
Cost has been one of the biggest obstacles to wider use of vector databases. This cost comes from two points:
-
Storage. In order to ensure low latency, most vector databases need to cache all data in memory or local disk. In this era of AI, which is often on the order of tens of billions, it means tens or hundreds of terabytes of resource consumption.
-
For computing, data needs to be divided into many small fragments to meet the engineering requirements of distributed support for large-scale data sets. Each shard needs to be retrieved separately and circumvented, which brings about a larger query calculation amplification problem. If tens of billions of data are divided into 10G shards, there will be 10,000 shards, which means that the calculation will be magnified 10,000 times.
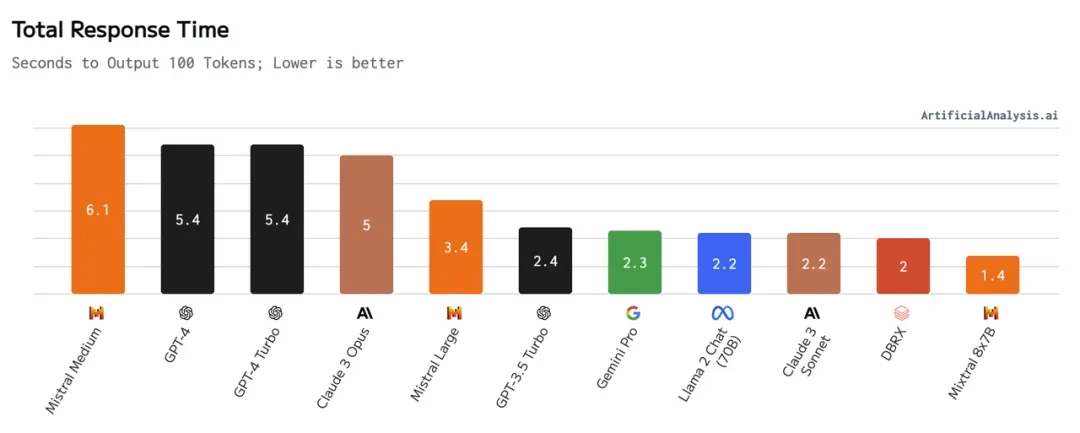 Response time of mainstream LLM, source: https://artificialanalysis.ai/models
Response time of mainstream LLM, source: https://artificialanalysis.ai/models
In the RAG wave brought by AIGC, a single RAG user (or a single tenant of the ToC platform) has extremely low sensitivity to delays. The reason is that compared to the latency of several milliseconds to hundreds of milliseconds in vector databases, the latency of large models as the core of the link generally exceeds the second level. In addition, the cost of cloud object storage is much lower than that of local disk and memory. There is an increasing need for a technology that can:
-
From a storage point of view, when querying, the data is placed in the cheapest cloud object as cold storage. When needed, it is loaded to the node and converted into hot storage to provide query.
-
From a computational point of view, the data required for each query is narrowed down in advance without expanding to global data to ensure that the hot storage will not be penetrated.
This technology can help users greatly reduce costs under acceptable latency. It is also a solution that our Zilliz Cloud (https://zilliz.com.cn/cloud) is currently preparing to launch.
Opportunities brought by hardware iteration
Hardware is the foundation of everything, and the development of hardware directly determines the direction of the development of vector database technology. How to adapt and utilize these hardware in different scenarios has become a very important development direction.
- Cost-effective GPU
Vector retrieval is a computing-intensive application, and in the past two years, there have been more and more studies using GPUs for computing acceleration. Contrary to the expensive stereotype, due to the gradual maturity of the algorithm level and the fact that vector retrieval scenarios are suitable for cheaper inference cards with lower memory latency, GPU-based vector retrieval shows excellent cost performance.
 CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge Top 100 Recall: 98% Dataset: https://github.com/zilliztech/VectorDBBench
CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge Top 100 Recall: 98% Dataset: https://github.com/zilliztech/VectorDBBench
We used Milvus, which supports GPU indexing, for testing. At only 2-3 times the cost, both index building and vector retrieval showed a performance gap of several to dozens of times. Whether it is to support high-throughput scenarios or to speed up index construction, it can greatly reduce the cost of using vector databases.
- The ever-changing ARM
Major cloud vendors are constantly launching their own CPUs based on ARM architecture, such as AWS' Graviton and GCP's Ampere. We conducted relevant tests on AWS Graviton3 and observed that compared to x86, it can provide lower-priced hardware while also delivering better performance. Moreover, these CPUs are evolving extremely fast. For example, after the launch of Graviton3 in 2022, AWS released Graviton4 with a 30% increase in computing power and a 70% increase in memory bandwidth in 2023 ( https://press.aboutamazon.com/2023/11/aws- unveils-next-generation-aws-designed-chips).
- powerful disk
Storing most of the data on the disk can help the vector database greatly increase the capacity and achieve a latency of hundreds of milliseconds. This level is enough for most, and the cost of the disk is tens or even one percent of the memory. .
Two-way rush on the model side
The model generates vectors, and the vector database supports the storage and query of vectors. As a whole, in addition to pursuing cost reduction on the vector database side, the model side is also trying to reduce the size of vectors.
For example, in the dimension of vectors, the traditional dimensionality reduction scheme introduced on vectors has a greater impact on the accuracy of queries, and the ext-embedding-3-large released by OpenAI ( https://openai.com/index/new -embedding-models-and-api-updates/) The model can control the dimension of the output vector through parameters. While reducing the vector dimension, it has little impact on the performance of downstream tasks. As for vector data types, Cohere ’s recent blog ( https://cohere.com/blog/int8-binary-embeddings) announced support for simultaneously outputting vectors of float, int8, and binary data types. For vector databases, how to adapt to these changes is also a direction that needs to be actively explored.
02.Business needs
Improve vector search accuracy
The accuracy of searches has always been an important topic. Whether due to widespread production applications or higher relevance requirements in RAG applications, vector databases are striving toward higher search quality. In this process, new technologies are constantly emerging, such as ColBERT to solve the problem of information loss caused by too large chunks, and Sparse to solve the problem of out-of-domain information retrieval. The figure below shows the evaluation results of BGE's M3-Embedding model. It can support the simultaneous output of Sparse, Dense and ColBERT vectors. The table below shows the comparison results of search quality using them for hybrid search.

For vector databases, how to use these technologies for hybrid search to improve retrieval quality is also an important development direction.
- ColBERT
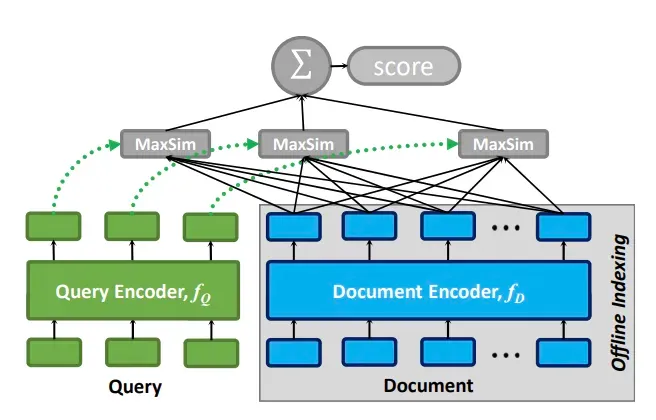
ColBERT is a retrieval model. In order to solve the problem of information loss caused by large chunks in the traditional twin-tower model, and at the same time avoid the search efficiency problem caused by the full connection of conventional retrieval models, ColBert proposed a late interaction mode based on token vectors. Vector retrieval is also introduced in ColBERTv2 to speed up the final late interaction mode.
- Sparse
Traditional dense vectors are good at capturing semantic information, but since the model can only learn the knowledge in the training data during model training, the dense vector has limited expressive ability for new vocabulary or professional terms not covered by the training data. And this is very common in practical applications. General model fine-tuning can solve this problem to a certain extent, but the cost is high and real-time performance will face challenges.
At this time, the sparse vector generated by BM25 based on traditional keyword matching performs well. In addition, models such as SPLADE and BGE's M3-Embedding try to encode more information while retaining the keyword matching capabilities of sparse vectors to further improve retrieval quality.
In fact, the industry has been using hybrid recall systems based on keyword retrieval and vector retrieval for a long time. It has gradually become a consensus to integrate a new generation of sparse vectors in vector databases and support hybrid retrieval capabilities. Milvus also officially supports the sparse vector retrieval capability in version 2.4.
Further optimize the vector database for offline scenarios
At present, almost all vector databases focus on online scenarios, including RAG ( https://zilliz.com.cn/blog/ragbook-technology-development), image search (https://zilliz.com.cn/ use-cases/image-similarity-search), etc.
Online scenarios are characterized by small volume, high frequency, and high requirements on latency. Even the most cost-sensitive and performance-least-important scenarios often require seconds-level latency.
In fact, vector retrieval plays an important role in many offline scenarios of large-scale data processing. For example, batch processing tasks such as data deduplication and feature mining, or search and recommendation systems that use vector similarity as one of the recall signals, usually use vector retrieval as an offline pre-computation step and perform feature updates regularly. These offline scenarios are characterized by batch queries, large amounts of data, etc., and the time-consuming requirements of the tasks may be minutes or even hours.
In order to support offline scenarios, vector databases need to solve many new problems. Here are a few examples:
-
Computing efficiency: Many offline scenarios require efficient batch queries on large amounts of data, such as the offline computing part of some search and recommendation scenarios. This scenario does not require the delay of individual data, but requires overall higher computational efficiency than the online scenario. To better support this type of problem, capabilities such as GPU indexing that increase computational density need to be supported.
-
Large returns: Data mining often uses vector retrieval to help the model find a certain type of scene. This usually requires returning a large amount of data. How to deal with the bandwidth problems caused by these returned results and the algorithm efficiency of large topK searches are the key to supporting such scenarios.
If the above challenges can be solved, the vector database can widely support applications in more scenarios, not just online applications.
Richer vector database features adapt to more industry needs
As vector databases are more and more widely used in production, many different usage methods have emerged and are also used in different industries. These requirements that are highly relevant to industries and specific scenarios guide the vector database to support more and more features.
-
Biopharmaceutical industry: Binary vectors are usually used to express drug molecular formulas for retrieval.
-
Risk control industry: Need to find the most outlier vector, not the most similar vector.
-
Range Search function: allows users to set a similarity threshold and return all results with a similarity higher than the threshold. It can ensure that the returned results have high relevance even when the number of results cannot be estimated.
-
Groupby and Aggregation functions: For larger pairs of unstructured data (movies, articles), we usually produce vectors in segments, such as a frame or a piece of text. In order to search for results that meet the requirements through these segmented vectors, the vector database needs to support Groupby and the ability to aggregate the results.
-
Support multi-modal models: The trend of model development toward multi-modal models will produce vectors with different distributions, making it difficult to meet retrieval needs under existing algorithms.
The above-mentioned improved functions for various industries highlight the dynamic development characteristics of vector databases. The vector database will be continuously upgraded and optimized to introduce richer features to meet the complex needs of AI applications in various industries.
03. Summary
The vector database has experienced a rapid maturity process in the past year, and there has been great development in terms of usage scenarios and the capabilities of the vector database itself. In the increasingly visible AI era, this trend will only accelerate. I hope these personal summaries and analyzes can serve as inspiration, provide some ideas and inspiration for the development of vector databases, and let us embrace more exciting changes in the future.
How much revenue can an unknown open source project bring? Microsoft's Chinese AI team collectively packed up and went to the United States, involving hundreds of people. Huawei officially announced that Yu Chengdong's job changes were nailed to the "FFmpeg Pillar of Shame" 15 years ago, but today he has to thank us—— Tencent QQ Video avenges its past humiliation? Huazhong University of Science and Technology’s open source mirror site is officially open for external access report: Django is still the first choice for 74% of developers. Zed editor has made progress in Linux support. A former employee of a well-known open source company broke the news: After being challenged by a subordinate, the technical leader became furious and rude, and was fired and pregnant. Female employee Alibaba Cloud officially releases Tongyi Qianwen 2.5 Microsoft donates US$1 million to the Rust Foundation