
In search applications, traditional Keyword Search has always been the main search method. It is suitable for exact matching query scenarios and can provide low latency and good result interpretability. However, Keyword Search does not consider contextual information and may produce irrelevant results. result. In recent years, Semantic Search, a search enhancement technology based on vector retrieval technology, has become increasingly popular. It uses machine learning models to convert data objects (text, images, audio and video, etc.) into vectors. The vector distance represents the similarity between objects. If If the model used is highly relevant to the problem domain, it can often better understand the context and search intent, thereby improving the relevance of the search results. On the contrary, if the model is not highly relevant to the problem domain, the effect will be greatly reduced.
Both Keyword Search and Semantic Search have obvious advantages and disadvantages, so can the overall relevance of search be improved by combining their advantages? The answer is that simple arithmetic combinations cannot achieve the expected results for two main reasons:
-
First, the scores of different types of queries are not in the same comparable dimension, so simple arithmetic calculations cannot be performed directly.
-
Secondly, in a distributed retrieval system, the scores are usually at the shard level, and the scores of all shards need to be globally normalized.
In summary, we need to find an ideal query type to solve these problems. It can execute each query clause individually, collect query results at the shard level, and finally normalize and merge the scores of all queries to return the final result. The result is the Hybrid Search solution.
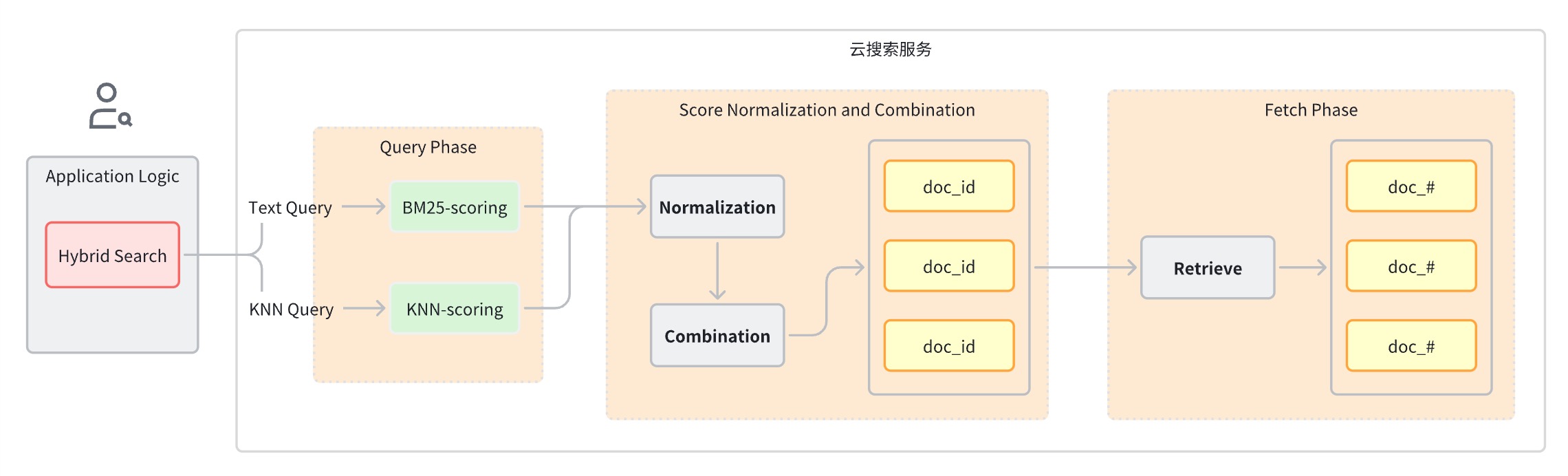
Usually a hybrid search query can be divided into the following steps:
-
Query phase: Use mixed query clauses for Keyword Search and Semantic Search.
-
Score normalization and merging stage, which follows the query stage.
-
Since each query type will provide a different range of scores, this stage performs a normalization operation on the score results of each query clause. The supported normalization methods are min_max, l2, and rrf.
-
To combine the normalized scores, the combination methods include arithmetic_mean, geometric_mean, and harmonic_mean.
-
-
Documents are reordered based on the combined ratings and returned to the user.
Implementation ideas
From the introduction of the previous principles, we can see that to implement a hybrid retrieval application, at least these basic technical facilities are required.
-
Full text search engine
-
vector search engine
-
Machine Learning Model for Vector Embedding
-
Data pipeline that converts text, audio, video and other data into vectors
-
Fusion sorting
Volcano Engine cloud search is built on the open source Elasticsearch and OpenSearch projects. It has supported complete and mature text retrieval and vector retrieval capabilities from the first day it was launched. At the same time, it has also carried out a series of functional iterations and evolutions for hybrid search scenarios, providing A hybrid search solution that works out of the box. This article will take an image search application as an example to introduce how to quickly develop a hybrid search application with the help of the Volcano Engine cloud search service solution.

Its end-to-end process is summarized as follows:
-
Configure and create related objects
-
Ingestion Pipeline: Supports automatically calling the model to store image conversion vectors into the index
-
Search Pipeline: Supports automatic conversion of text query statements into vectors for similarity calculation
-
k-NN index: the index where the vector is stored
-
-
Write the image dataset data to the OpenSearch instance, and OpenSearch will automatically call the machine learning model to convert the text into an Embedding vector.
-
When the client initiates a hybrid search query, OpenSearch calls the machine learning model to convert the incoming query into an Embedding vector.
-
OpenSearch performs hybrid search request processing, combines Keyword Seach and Semantic Seach scores, and returns search results.
Plan actual combat
Environmental preparation
-
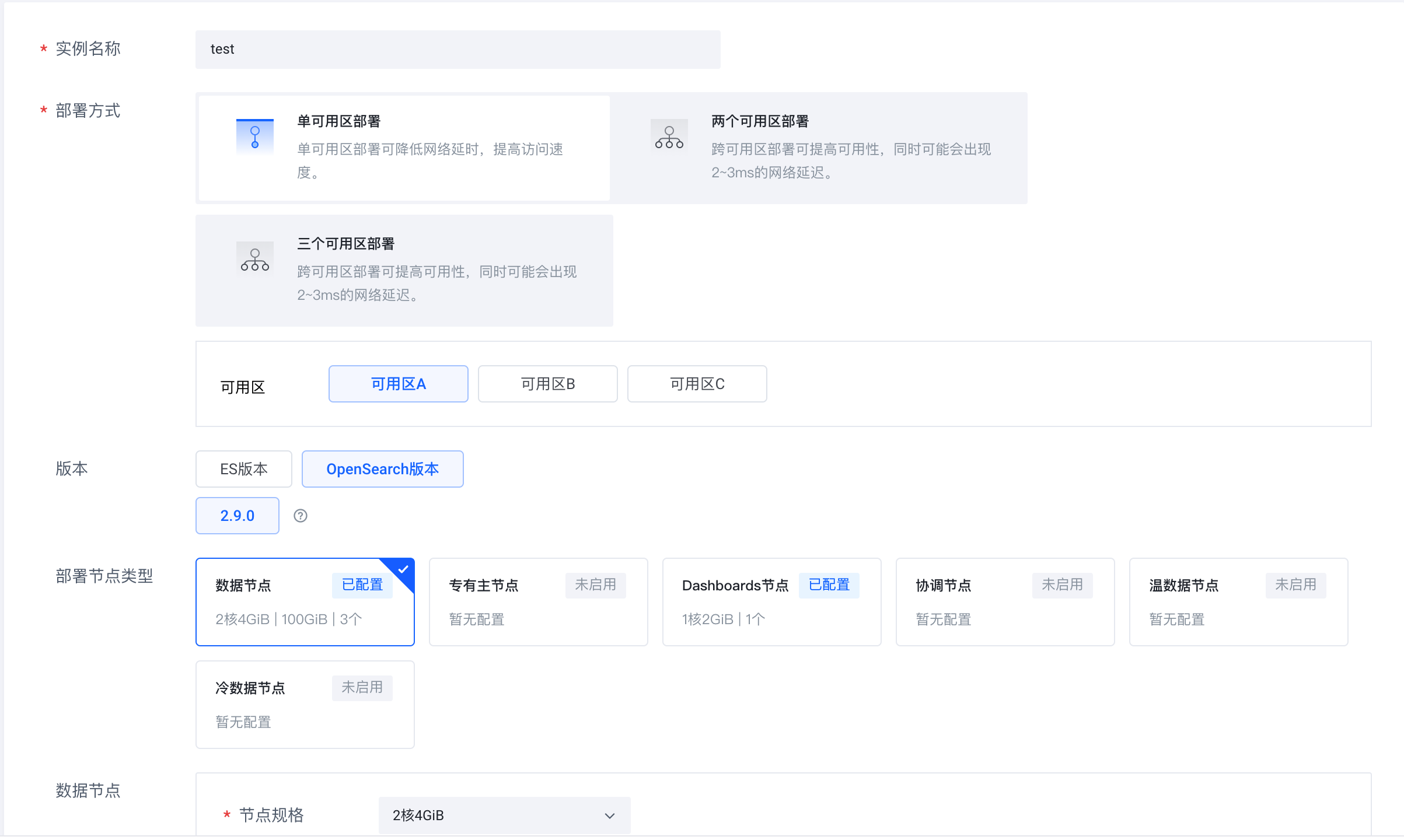
Log in to the Volcano Engine cloud search service (https://console.volcengine.com/es), create an instance cluster, and select OpenSearch 2.9.0 as the version.
-
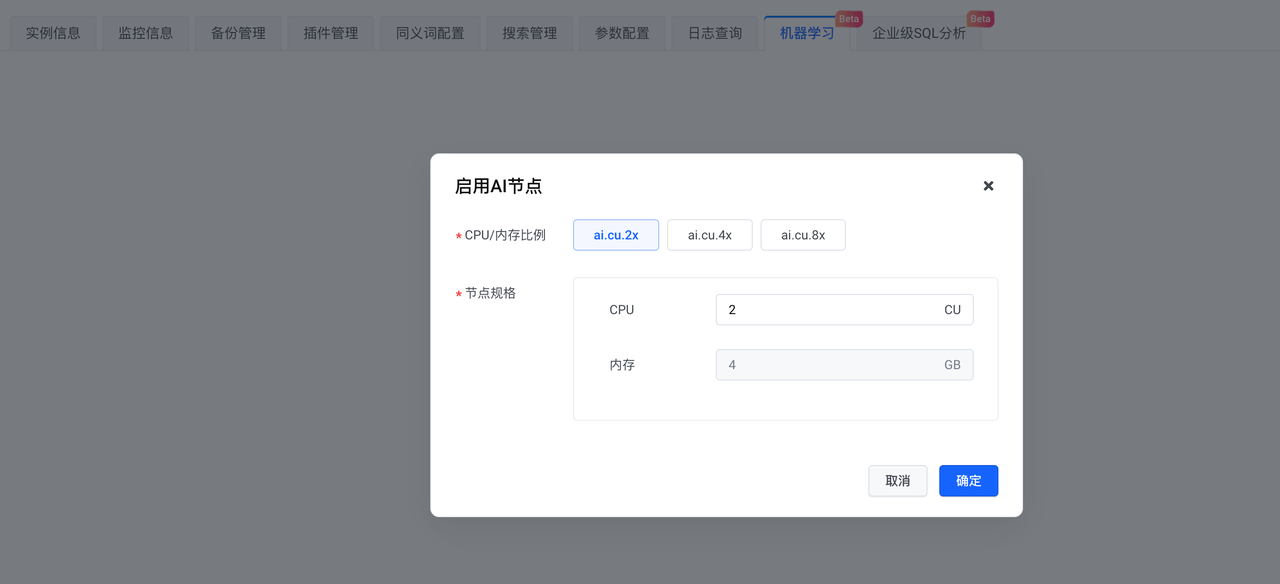
After the instance is created, enable the AI node.
-
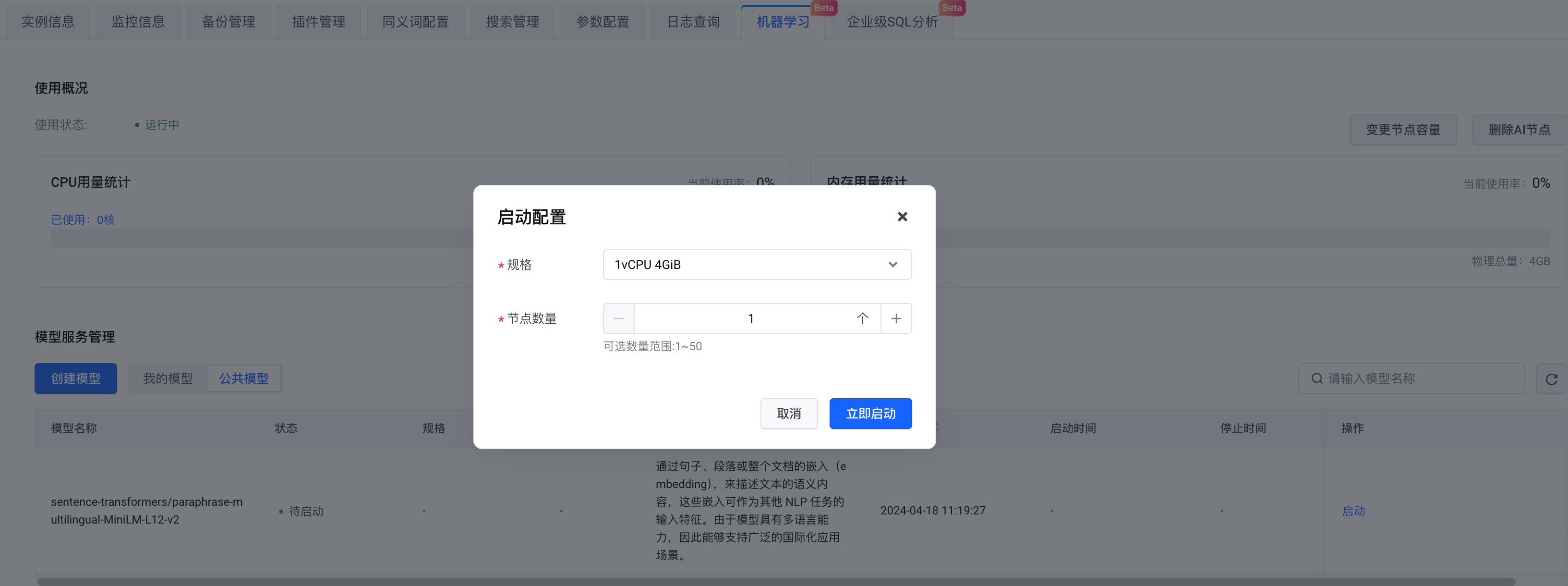
In terms of model selection, you can create your own model or choose a public model. Here we select the public model . After completing the configuration, click Start Now .
At this point, the OpenSearch instance and the machine learning service that hybrid search relies on are ready.
Dataset preparation
Use Amazon Berkeley Objects Dataset (https://registry.opendata.aws/amazon-berkeley-objects/) as the data set. The data set does not need to be downloaded locally and is directly uploaded to OpenSearch through code logic. See the code content below for details.
Steps
Install Python dependencies
pip install -U elasticsearch7==7.10.1
pip install -U pandas
pip install -U jupyter
pip install -U requests
pip install -U s3fs
pip install -U alive_progress
pip install -U pillow
pip install -U ipythonConnect to OpenSearch
# Prepare opensearch info
from elasticsearch7 import Elasticsearch as CloudSearch
from ssl import create_default_context
# opensearch info
opensearch_domain = '{{ OPENSEARCH_DOMAIN }}'
opensearch_port = '9200'
opensearch_user = 'admin'
opensearch_pwd = '{{ OPENSEARCH_PWD }}'
# remote config for model server
model_remote_config = {
"method": "POST",
"url": "{{ REMOTE_MODEL_URL }}",
"params": {},
"headers": {
"Content-Type": "application/json"
},
"advance_request_body": {
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
}
}
# dimension for knn vector
knn_dimension = 384
# load cer and create ssl context
ssl_context = create_default_context(cafile='./ca.cer')
# create CloudSearch client
cloud_search_cli = CloudSearch([opensearch_domain, opensearch_port],
ssl_context=ssl_context,
scheme="https",
http_auth=(opensearch_user, opensearch_pwd)
)
# index name
index_name = 'index-test'
# pipeline id
pipeline_id = 'remote_text_embedding_test'
# search pipeline id
search_pipeline_id = 'rrf_search_pipeline_test'-
Fill in the OpenSearch link address and username and password information. model_remote_config is the remote machine learning model connection configuration, which can be viewed in the model call information . Copy all remote_config configurations in the call information to model_remote_config .
-
In the Instance Information- > Service Access section, download the certificate to the current directory.
-
Given an index name, Pipeline ID, and Search Pipeline ID.
Create Ingest Pipeline
Create an Ingest Pipeline, specify the machine learning model to be used, convert the specified fields into vectors and embed them back. As follows, convert
the caption
field into a vector and store it in
caption_embedding
.
# Create ingest pipeline
pipeline_body = {
"description": "text embedding pipeline for remote inference",
"processors": [{
"remote_text_embedding": {
"remote_config": model_remote_config,
"field_map": {
"caption": "caption_embedding"
}
}
}]
}
# create request
resp = cloud_search_cli.ingest.put_pipeline(id=pipeline_id, body=pipeline_body)
print(resp)Create Search Pipeline
Create the Pipeline required for querying and configure the remote model.
Supported normalization methods and weighted sum methods:
-
Normalization method:
min_max,l2,rrf -
Weighted summation method:
arithmetic_mean,geometric_mean,harmonic_mean
The rrf normalization method is selected here.
# Create search pipeline
import requests
search_pipeline_body = {
"description": "post processor for hybrid search",
"request_processors": [{
"remote_embedding": {
"remote_config": model_remote_config
}
}],
"phase_results_processors": [ # normalization and combination
{
"normalization-processor": {
"normalization": {
"technique": "rrf", # the normalization technique in the processor is set to rrf
"parameters": {
"rank_constant": 60 # param
}
},
"combination": {
"technique": "arithmetic_mean", # the combination technique is set to arithmetic mean
"parameters": {
"weights": [
0.4,
0.6
]
}
}
}
}
]
}
headers = {
'Content-Type': 'application/json',
}
# create request
resp = requests.put(
url="https://" + opensearch_domain + ':' + opensearch_port + '/_search/pipeline/' + search_pipeline_id,
auth=(opensearch_user, opensearch_pwd),
json=search_pipeline_body,
headers=headers,
verify='./ca.cer')
print(resp.text)Create k-NN index
-
Configure the pre-created Ingest Pipeline into the index.default_pipeline field;
-
At the same time, configure the properties and set caption_embedding to knn_vector. Here we use hnsw in faiss.
# Create k-NN index
# create index and set settings, mappings, and properties as needed.
index_body = {
"settings": {
"index.knn": True,
"number_of_shards": 1,
"number_of_replicas": 0,
"default_pipeline": pipeline_id # ingest pipeline
},
"mappings": {
"properties": {
"image_url": {
"type": "text"
},
"caption_embedding": {
"type": "knn_vector",
"dimension": knn_dimension,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
},
"caption": {
"type": "text"
}
}
}
}
# create index
resp = cloud_search_cli.indices.create(index=index_name, body=index_body)
print(resp)Load dataset
Read the data set into memory and filter out some of the data that needs to be used.
# Prepare dataset
import pandas as pd
import string
appended_data = []
for character in string.digits[0:] + string.ascii_lowercase:
if character == '1':
break
try:
meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_" + character + ".json.gz",
lines=True)
except FileNotFoundError:
continue
appended_data.append(meta)
appended_data_frame = pd.concat(appended_data)
appended_data_frame.shape
meta = appended_data_frame
def func_(x):
us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]
return us_texts[0] if us_texts else None
meta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))
meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]
print(f"#products with US English title: {len(meta)}")
meta.head()
image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")
dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")
dataset.head()Upload dataset
Upload the data set to Opensearch and pass in image_url and caption for each piece of data. There is no need to pass in
caption_embedding
, it will be automatically generated through the remote machine learning model.
# Upload dataset
import json
from alive_progress import alive_bar
cnt = 0
batch = 0
action = json.dumps({"index": {"_index": index_name}})
body_ = ''
with alive_bar(len(dataset), force_tty=True) as bar:
for index, row in (dataset.iterrows()):
if row['path'] == '87/874f86c4.jpg':
continue
payload = {}
payload['image_url'] = "https://amazon-berkeley-objects.s3.amazonaws.com/images/small/" + row['path']
payload['caption'] = row['item_name_in_en_us']
body_ = body_ + action + "\n" + json.dumps(payload) + "\n"
cnt = cnt + 1
if cnt == 100:
resp = cloud_search_cli.bulk(
request_timeout=1000,
index=index_name,
body=body_)
cnt = 0
batch = batch + 1
body_ = ''
bar()
print("Total Bulk batches completed: " + str(batch))Hybrid search query
Take querying
shoes
as an example. The query contains two query clauses, one is
match
query and the other is
remote_neural
query. When querying, specify the previously created Search Pipeline as a query parameter. The Search Pipeline will convert the incoming text into a vector and store it in
the caption_embedding
field for subsequent queries.
# Search with search pipeline
from urllib import request
from PIL import Image
import IPython.display as display
def search(text, size):
resp = cloud_search_cli.search(
index=index_name,
body={
"_source": ["image_url", "caption"],
"query": {
"hybrid": {
"queries": [
{
"match": {
"caption": {
"query": text
}
}
},
{
"remote_neural": {
"caption_embedding": {
"query_text": text,
"k": size
}
}
}
]
}
}
},
params={"search_pipeline": search_pipeline_id},
)
return resp
k = 10
ret = search('shoes', k)
for item in ret['hits']['hits']:
display.display(Image.open(request.urlopen(item['_source']['image_url'])))
print(item['_source']['caption'])Hybrid search display

The above is taking the image search application as an example to introduce the practical process of how to quickly develop a hybrid search application with the help of the Volcano Engine cloud search service solution. Welcome everyone to log in to the Volcano Engine console to operate!
The Volcano Engine cloud search service is compatible with Elasticsearch, Kibana and other software and commonly used open source plug-ins. It provides multi-condition retrieval, statistics, and reports of structured and unstructured text. It can achieve one-click deployment, elastic scaling, simplified operation and maintenance, and quickly build logs. Analysis, information retrieval analysis and other business capabilities.
{{o.name}}
{{m.name}}