
This article is the first in a series celebrating the second anniversary of CloudWeGo.
Today's sharing is mainly divided into three parts. The first is the capability upgrade of Kitex. Let's take a look at some progress in
performance
,
functionality
and
ease of use
in the past year. The second is the progress of community cooperation projects, especially two key projects,
Kitex-Dubbo
interoperability
and
configuration center integration
. The third one is to give you some spoilers about some of the things we are currently doing and planning to do.
Capability upgrade
performance
In September 2021, we published an article "
ByteDance Go RPC Framework Kitex Performance Optimization Practice
", which can be found on the CloudWeGo official website. This article introduces how to edit through the self-developed network library Netpoll and the self-developed Thrift Decoder fastCodec to optimize Kitex performance.
Since then, it has been very difficult to improve performance on the Kitex core request link. In fact, we have to work hard to avoid Kitex performance degradation while constantly adding new features.
Despite this, we have never stopped trying to optimize Kitex performance. Within Byte, we are already experimenting and promoting some performance improvements on core links, which we will introduce to you later.
Generalized calling based on DynamicGo
First, we will introduce a performance optimization that has been released: generalized calls based on DynamicGo.
Generic calling
is an advanced feature of Kitex. It can use Kitex Generic Client to directly call the API of the target service without pre-generating SDK code (that is, Kitex Client).
For example, ByteDance's internal interface testing tools, API gateways, etc. use Kitex's generalized Client, which can receive an HTTP request (the request body is in JSON format), convert it into Thrift Binary, and send it to Kitex Server.
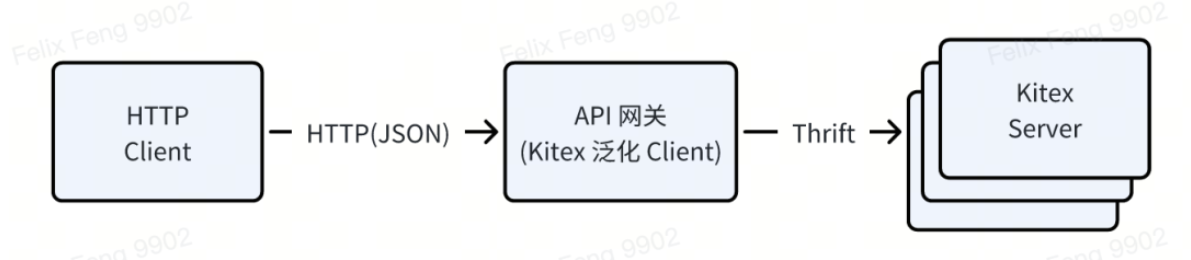
The implementation plan is to rely on a
map[string]interface{}
as a generic container, first convert json to map when requesting, and then complete the map -> thrift conversion based on Thrift IDL; the response is processed in reverse.
-
The advantage of this is that it is highly flexible and does not need to rely on pre-generated static code. You only need IDL to request the target service;
-
However, the price is poor performance. Such a generic container relies on Go's GC and memory management, which is very expensive. It not only needs to allocate a large amount of memory, but also requires multiple data copies.
Therefore, we developed DynamicGo (homepage:
http://github.com/cloudwego/dynamicgo
), which can be used to improve the performance of protocol conversion. There is a very detailed introduction in the project introduction. Here I will only introduce to you its core design idea: based on
the original byte stream
,
data processing and conversion
are completed in situ .
Through pooling technology, Dynamicgo only needs to pre-allocate memory once, and uses SIMD instruction sets such as SSE and AVX for acceleration, ultimately achieving considerable performance improvements.
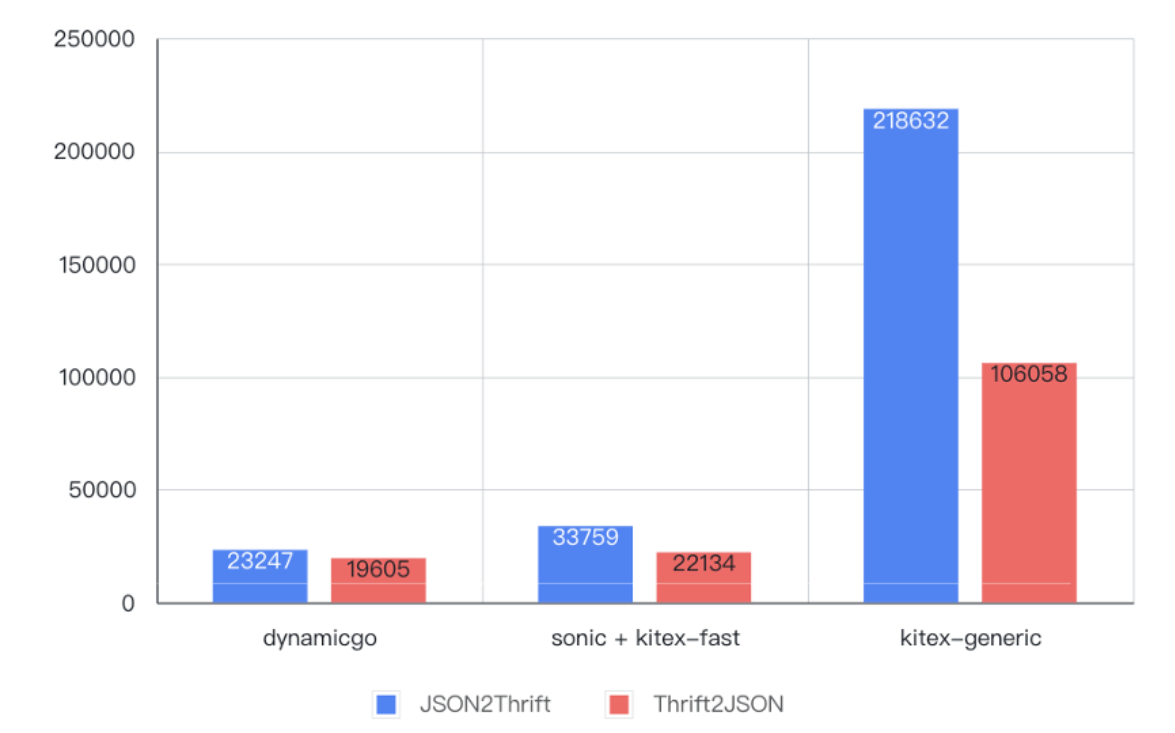
As shown in the figure below, compared with the original implementation of generalized calling, in the encoding and decoding test of 6KB data, the performance was improved by
4 to 9 times
, even
better than
the pre-generated static code.
The actual principle is very simple: generate a type descriptor based on parsing IDL, and perform the following protocol conversion process
-
Read a Key/Value pair from the JSON byte stream each time;
-
Find the Thrift field corresponding to the key according to the IDL Descriptor;
-
Complete the encoding of Value according to the Thrift encoding specification of the corresponding type, and write it to the output byte stream;
-
Loop this process until the entire JSON is processed.
In addition to optimizing JSON/Thrift protocol conversion, DynamicGo also provides the Thrift DOM method to optimize the performance of data orchestration scenarios. For example, a business team of Douyin needs to erase illegal data in the request, but only in a certain field in the request; using DynamicGo's Thrift DOM API is very suitable and can achieve a 10 times performance improvement. For details, please refer to DynamicGo's documentation. It won’t be expanded upon here.
Frugal - A high-performance JIT-based Thrift codec
Frugal is a high-performance Thrift codec based on
JIT compilation technology.
The official Thrift and Kitex default codecs are based on parsing Thrift IDL and generating the corresponding encoding and decoding Go code. Through JIT technology, we can dynamically generate encoding and decoding codes with better performance at
runtime
: generate more compact machine code, reduce cache misses, reduce branch misses, use SIMD instructions to accelerate, and use register-based function calls (Go default is based on stack).
Here are the performance indicators of the encoding and decoding tests:

可以看到,Frugal 性能显著高于传统方式。
In addition to the performance advantages, there are also additional benefits because no codec code is generated.
一方面
仓库更简洁了,我们有一个项目,生成的代码有 700MB,切换到 frugal 后只有 37M,大约只有原来的 5%,在仓库维护方面压力大幅缩小,修改 IDL 以后也不会生成一大堆实际上无法 review 的代码;另一方面 IDE 的
加载速度、项目的
编译速度也能显著提高。
In fact, Frugal was released last year, but the early version coverage at that time was not sufficient. This year we focused on optimizing its stability and fixed all known issues. The recently released v0.1.12 version can be stably used in production operations. For example, in the ByteDance e-commerce business line, the peak QPS of a certain service is about 25K. It has been fully switched to Frugal and has been running stably for several months.
Frugal currently supports Go1.16 ~ Go1.21, currently only supports AMD64 architecture, and will also support ARM64 architecture in the future; we may use Frugal as the default codec of Kitex in a future version.
Function
Kitex has been upgraded from v0.4.3 to v0.7.2 in the past year. There are more than 40 Feature-related Pull Requests, covering
command line tools
,
gRPC
,
Thrift
encoding and decoding, retries , generalized calls , and service governance configurations
.
In many aspects, here we focus on a few more important features.
Fallback - Business custom downgrade
The first is the fallback function added by Kitex in version v0.5.0.
The demand background is that when the RPC request fails and the response cannot be obtained, the business code often needs to implement some downgrade strategies.
For example, in the information flow business, if the API access layer encounters an occasional error (such as timeout) when requesting recommended services, the simple and crude approach is to tell the user that an error occurred and let the user try again, but this will result in a poor experience. A better downgrade strategy is to try to return some popular items. Users will have almost no idea about it and the experience will be much better.
The problem with the old version of Kitex is that the business-customized middleware cannot be implemented in the middleware after the built-in middleware such as circuit breaker and timeout. The only way is to modify the business code directly, which is quite intrusive and requires modifying every method. Called, easy to miss. When adding business logic that calls a certain method, there is no mechanism to ensure that it will not be missed.
Through the new fallback function,
the business is allowed to specify a fallback method when initializing the client to implement the downgrade strategy
.
Here is a simple usage example:

This method specified when initializing the client will be called before the end of each request. The context, request parameters, and response of this request can be obtained. Based on this, a custom downgrade strategy can be implemented, thus converging the implementation of the strategy.
Thrift FastCodec - supports unknown fields
In actual business scenarios, a request link often involves multiple nodes.
Taking the link A -> B -> C -> D as an example, a certain struct of node A needs to be transparently transmitted to node D through B and C. In the previous implementation, if a new field is added to A, for example
Extra
, I
need to use the new
IDL
to regenerate the code of all nodes
and redeploy it to get the value of the Extra field in node D. The entire process is complex and the update cycle is relatively long. If the intermediate node is a service of another team, cross-team coordination is required, which is very laborious.
In Kitex v0.5.2, we implemented the Unknown Fields feature in our self-developed fastCodec, which can solve this problem very well.
For example, in the same link A -> B -> C -> D, the codes of nodes B and C remain unchanged (as shown in the figure below). When parsing, it is found that there is a field
id=2
, and the corresponding field cannot be found in the struct. So this unexported
_unknownFields
field (actually an alias of a byte slice) is written;

The A and D services are regenerated with the new IDL (as shown in the figure below) and include
Extra
the field. Therefore, when parsing
id=2
the field, you can write to this
Extra
field, and the business code can be used normally.

In addition, we also performed a performance optimization on this feature in v0.7.0, using "
no
serialization
" (direct copying of byte streams) to improve the encoding and decoding performance of unknown fields by about
6 to 7
times.
Session delivery mechanism based on GLS
Another feature worth introducing to you is also related to long links.
Within Byte, we use LogID to track the entire call chain, which requires all nodes in the link to transparently transmit this ticket as required. In our implementation, LogID is not placed in the request body, but is transparently transmitted in the form of metadata.
Take the link A -> B -> C as an example. When A calls B's
A_Call_B
method, the incoming LogID will be stored in the handler input parameter
ctx
. When B requests C, the correct usage is to pass this
ctx
to
client
C.B_Call_C
the method. Only in this way can the LogID be passed on.

But the actual situation is often that the code requesting the C service is packaged in multiple layers, and
the transparent transmission of ctx is easily missed
; the situation we encountered is more troublesome. The request for the C service is
completed by a third-party library
, and the library's The interface does not support incoming code
ctx
, and such code transformation is very costly and may require coordination of multiple teams to complete.
In order to solve this pain point, we introduced a session transfer mechanism based on GLS (goroutine local storage). The specific plan is:
-
On the Kitex Server side, after receiving the request, it first backs up the context in GLS, and then calls the Handler, which is the business code;
-
When calling the client in the business code to send a request, first check whether the input ctx contains the expected ticket. If not, take it out from the GLS backup and then send the request.
Here is a specific example:

illustrate:
-
ContextBackupTurn on the switch when initializing the server -
Specify one when initializing Client
backupHandler -
Before each request is made, this handler will be called to check whether the input parameters include
LogID -
ctxIf it is not included, read it from the backup , merge it into the currentctxone and return it (returnuseNewCtx =truemeans Kitex should use this newctxone to send the request)
After turning on the above settings, even if the business code uses the wrong context, the entire link can be connected in series.
Finally, let’s introduce the async parameter of server initialization, which solves the problem of sending requests in a new goroutine in the handler. Since they are not the same goroutine, Local Storage cannot be shared directly; we learn from pprof's mechanism of coloring goroutines and pass the backup
ctx
to the new goroutine, thus realizing the ability to implicitly pass tickets in
asynchronous
scenarios
.
Ease of use
In addition to high performance and rich functionality, we also pay great attention to improving Kitex's ease of use.
Documentation | Documentation
As we all know, there are two things that programmers hate most: one is writing documentation, and the other is others not writing documentation. Therefore, we attach great importance to reducing the start-up cost of writing documents and work hard to promote document construction.
Within ByteDance, Kitex’s documents are organized in the form of Feishu knowledge base, which can be better integrated into Feishu’s search and facilitate Byte employees’ inquiries; because Feishu documents are easy to update, they are more updated than official website documents. Timely; when new features are developed, documents are often written in the Feishu knowledge base first, and some are not synchronized to the official website in time. Various reasons have led to the growing differences between the inner and outer branches.
Therefore, in the past two quarters, we have launched a new round of document optimization work: based on user feedback, we have reorganized all documents and added more examples; we have translated all documents into English and synchronized them to the official website. This work is expected to be completed this year. You can already see some updated documents on the official website, such as timeout control, Frugal, panic processing, etc. You are welcome to visit the official website and help catch bugs.
In addition, we are also building a mechanism to automatically synchronize internal documents to the official website. We hope that open source users can also get timely updated documents like internal users in the future.
Other optimizations | Miscellaneous
In addition to documentation, Kitex also does some other usability-related work.
We have released a sample project "Note Service", which demonstrates the usage of various features such as middleware, current limiting, retry, timeout control, etc. in the example, and provides reference for Kitex users through real project code. Students in need can go Check out the example here: https://github.com/cloudwego/kitex-examples/tree/main/bizdemo/easy_note.
Secondly, we are also working hard to improve the efficiency of troubleshooting. For example, we have added more specific contextual information to the error message based on daily oncall needs (such as the specific reason for the timeout error, the method name for the panic message, and the thrift codec error message. Specific field names, etc.) to quickly locate specific problem points.
In addition, Kitex command line tools continue to improve.
-
For example, many enterprise users develop on Windows. Previously, Kitex could not generate code normally under Windows. As a result, these users also needed a Linux environment to assist, which was very inconvenient. We made optimizations based on the feedback of these users.
-
We also implemented an IDL clipping tool that can identify structures that are not referenced and filter them out directly when generating code. This is very helpful for some old projects that are stuck.
community cooperation projects
In the past year, with the support of the CloudWeGo community, we have also achieved a lot of results, especially the two projects of Dubbo interoperability and configuration center integration.
Dubbo 互通 | Dubbo Intercommunication
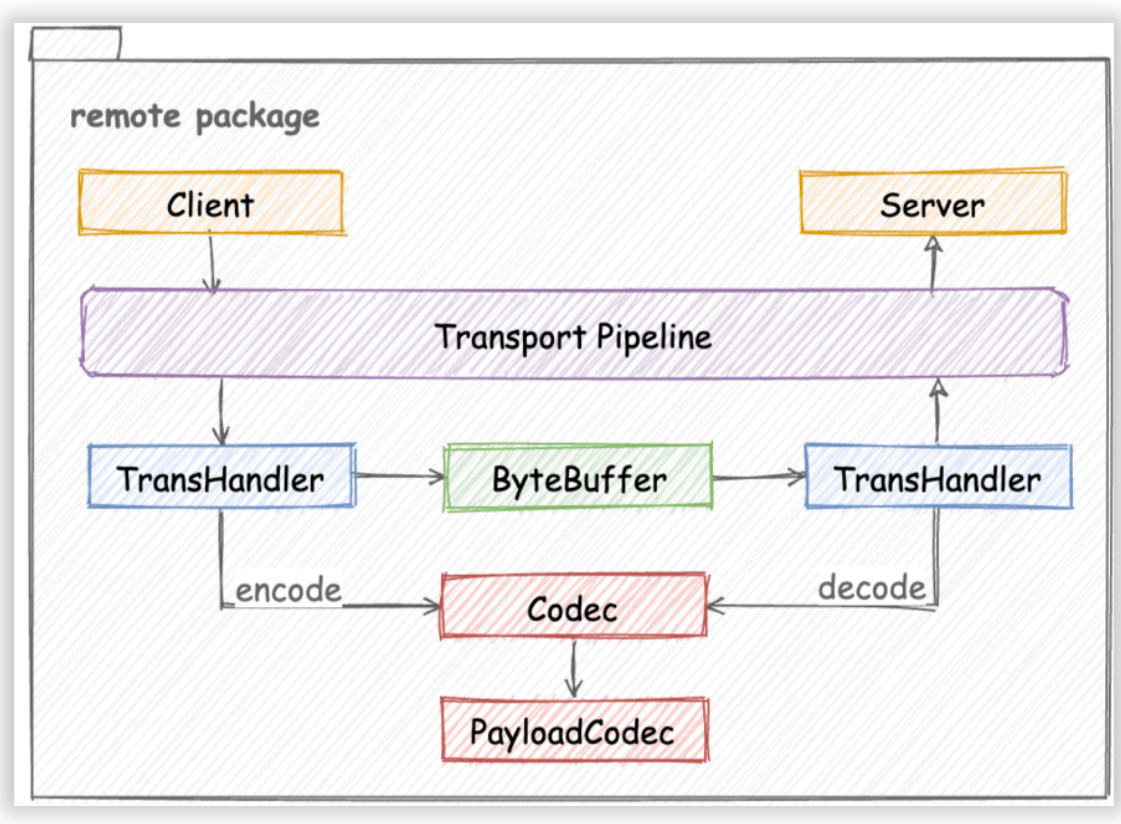
Although Kitex was originally a Thrift RPC framework, its architectural design has good scalability. As shown in the figure, when adding new protocols, the core work is to implement a corresponding protocol codec (Codec or PayloadCodec) according to the Codec interface:
The Dubbo interoperability project originated from the needs of an enterprise user. They have some peripheral services implemented by suppliers using Dubbo Java. They hope to use Kitex to request these services and reduce project management costs.
This project has received enthusiastic support from students in the community, and many students have participated in this project. In particular, @DMwangnima, who is responsible for one of the core tasks, is also a developer of the Dubbo community. Since he is familiar with Dubbo, the development process has avoided many detours.
Regarding the specific implementation plan, we adopted a different idea from Dubbo official. According to the analysis of the hessian2 protocol, its basic type system basically overlaps with Thrift, so we generated the Kitex Dubbo-Hessian2 project scaffolding based on Thrift IDL.
In order to quickly implement the function in the first phase, we directly borrowed the hessian2 library of the Dubbo-go framework for serialization and deserialization, and implemented Kitex's own DubboCodec by referring to Dubbo official documentation and Dubbo-Go source code;
In October we have completed the first version of the code. The project address is
https://github.com/kitex-contrib/codec-dubbo
. Interested users can try it out according to the above document. In terms of specific use, it can be compared with Kitex Similar to Thrift, write the Thrift IDL, use the kitex command line to generate scaffolding (note that the Protocol needs to be specified as hessian2), and then specify DubboCodec in the code where the client and server are initialized, and you can start writing business code.
This not only lowers the user threshold, but also uses IDL to manage interface-related information, making maintainability better.
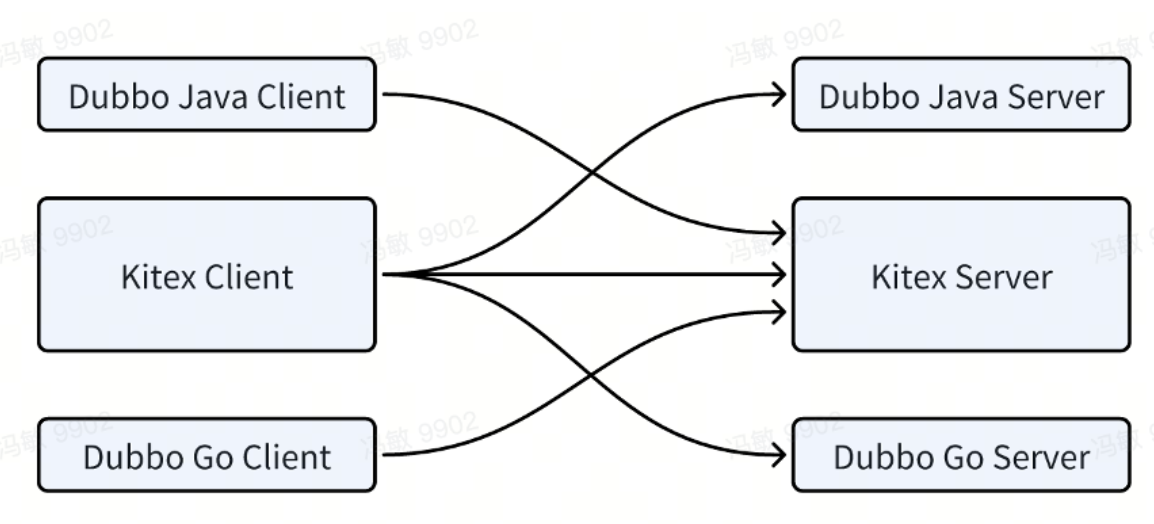
At present, we have been able to achieve interoperability between Kitex and Dubbo-Java, Kitex and Dubbo-Go :
Future plan:
-
The first is to improve compatibility with dubbo-java and allow users to specify the corresponding Java type in IDL annotations.
-
The second is the connection with the registration center. Although Kitex already has a corresponding registration center module, the specific data format is inconsistent with Dubbo. This area still needs some modifications, and the relevant work is about to be completed.
-
Finally, there is the performance issue. There is currently a big gap compared with Kitex Thrift. Because the dubbo-go-hessian2 library is completely based on reflection, there is still a lot of room for optimization in performance. It is planned to implement Hessian2's FastCodec to solve the performance bottleneck of encoding and decoding.
During the advancement of this project, we deeply experienced the positive impact of cross-community cooperation. Kitex absorbed the achievements of the Dubbo community and also discovered areas where the Dubbo-go project could be improved. The compatibility and performance solutions mentioned above The plan is also expected to benefit the dubbo community.
I would also like to express my special thanks to the community contributors to this project, @DMwangnima, @Lvnszn, @ahaostudy, @jasondeng1997, @VaderKai and other students, for spending a lot of their spare time to complete this project.
Config Center Integration | Config Center Integration
Another key project of community cooperation is "Configuration Center Integration".
Kitex provides dynamically configurable service management capabilities, including client timeout, retry, circuit breaker, and server current limiting.
These service governance capabilities are heavily used within Byte. Microservice developers can edit these configurations on Byte's self-built service governance configuration platform. The granularity is refined to this five-tuple, and it takes effect in quasi-real time. ,These capabilities are very helpful to improve the SLA of ,microservices.
However, we communicated with enterprise users and found that these capabilities are usually only very simple to use, with coarse granularity and poor timeliness. They may only be hard-coded specified configurations, or configured through simple files, and require a restart to take effect.
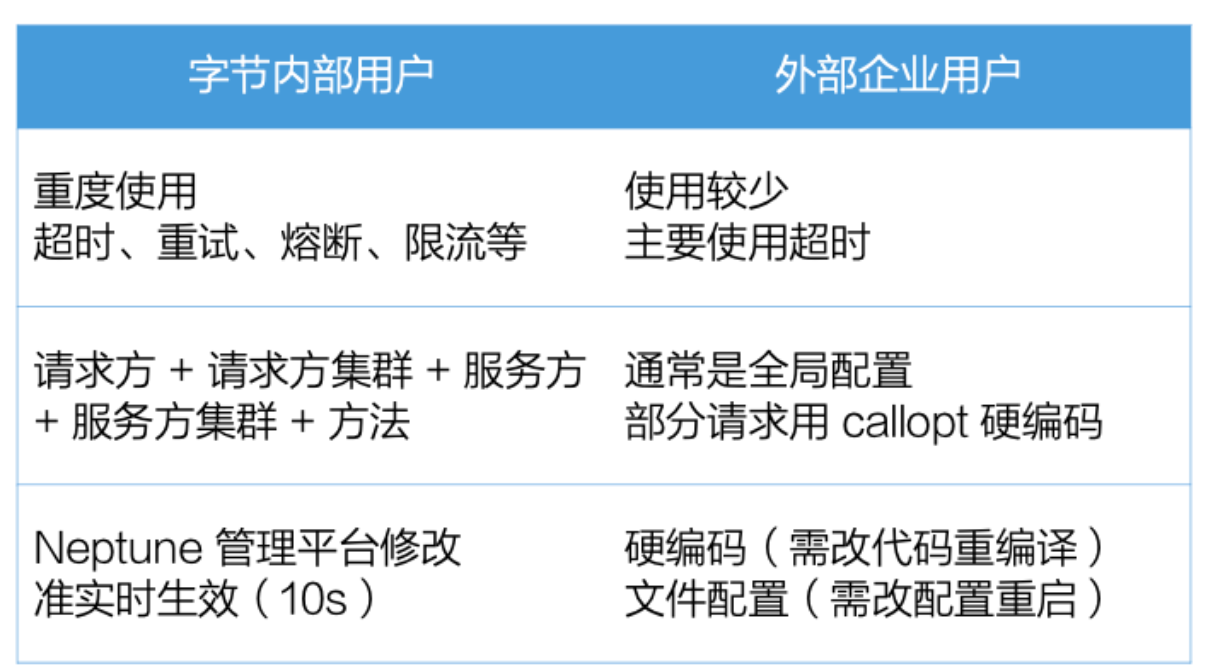
In order to allow users to better use Kitex's service governance capabilities, we launched the configuration center integration project so that Kitex can
dynamically obtain service governance configurations
from the user's configuration center and take effect in near real-time.
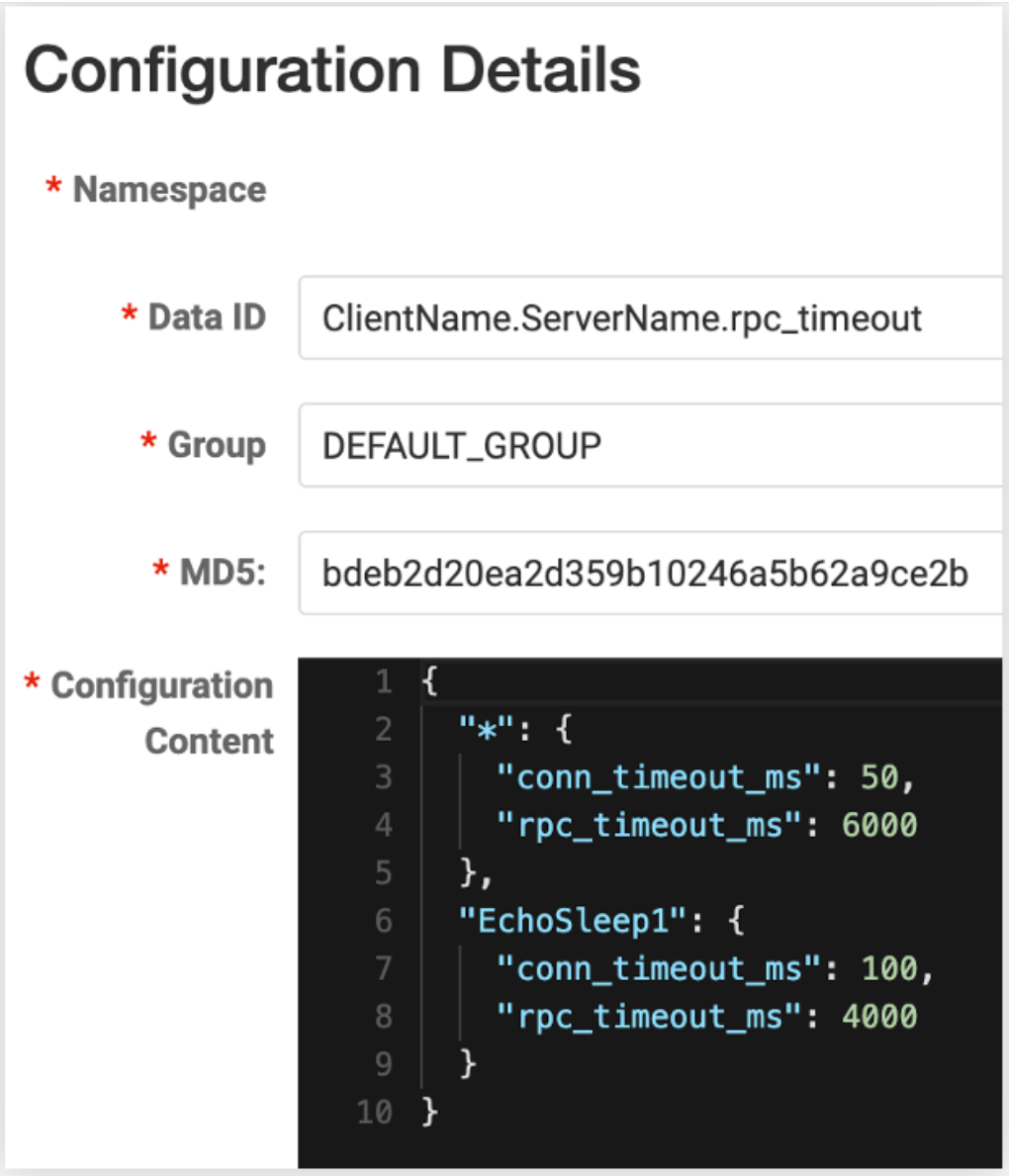
We have released the v0.1.1 version of config-nacos (note: it has been updated to v0.3.0 as of the time of publishing, thanks to @whalecold for his continued investment). By adding client to the existing Kitex project
NacosClientSuite
, it can be easily
made Kitex
loads the corresponding service governance configuration from
N
acos .

Since we use the watch capability provided by the nacos client itself, we can receive configuration change notifications in quasi-real time, so the timeliness is also very high and there is no need to restart the service.
In addition, we have also reserved the ability to modify the configuration granularity. For example, the default configuration granularity is client + server. Just fill in the data id of Nacos in this format; users can also specify the template of this data id, for example, add Computer rooms, clusters, etc., so as to adjust these configurations more finely.
We plan to complete the integration with common configuration centers. There are more detailed instructions in this issue https://github.com/cloudwego/kitex/issues/973. Everyone is welcome to watch.
Current progress is:
-
Modules such as file, apollo, etcd, and zookeeper have submitted PRs and are under review;
-
consul's plan has been submitted;
Interested students can also join in to review, test and verify these extension modules.
future outlook
Finally, let me give you some spoilers on some of the directions we are currently trying.
merge deployment
Affinity Deployment | Affinity Deployment
Most of our previous optimizations were within the service, but as the number of optimization points gradually decreased, we began to consider other goals, such as optimizing the network communication overhead of RPC requests.
The specific plans are as follows:
-
The first is affinity scheduling. By modifying the containerized scheduling mechanism, we try to schedule the Client and Server to the same physical machine;
-
So we can use same-machine communication to reduce overhead.
At present, the same-machine communication we have implemented includes the following three types:
-
Unix Domain Socket has better performance than standard TCP Socket, but not much;
-
ShmIPC (https://github.com/cloudwego/shmipc-go), inter-process communication based on shared memory, can directly omit the transmission of serialized data, and only needs to tell the receiver the memory address;
-
Finally, there is the "black technology" RPAL , which is the abbreviation of Run Process As Library. We work with Byte's kernel team to put two processes in the same address space through a customized kernel. When certain conditions are met, Next, we may not even need to do serialization;
At present, we have enabled this capability on more than 100 services and have achieved some performance gains. For services with better effects, it can save about 5~10% of CPU and reduce time consumption by 10~70%; of course, in practice Performance depends on some characteristics of the service, such as packet size.
Compile-time merging | Service Inline
Another idea is compile-time merging.
The starting point of this solution is that we found that although microservices improve the efficiency of team collaboration, they also increase the overall complexity of the system, especially in terms of service deployment, resource occupation, communication overhead, etc.
Therefore, we hope to implement a solution that allows the business to be developed in the form of microservices and deployed in the form of single services, commonly known as having both.
Then we came up with this plan - we developed a tool that can merge the git repo of two microservices together, isolate potentially conflicting resources through namespace, and then compile it into an executable program for deployment .
Currently, within ByteDance, there are dozens of services connected. The most effective service can save about 80% of CPU and reduce latency by up to 67%. Of course, the actual performance also depends on the characteristics of the service, such as request Bag size.
The above is our attempt at affinity.
Serialization
In terms of serialization, we are still making some efforts and attempts.
Frugal - SSA Backend
首先是 Frugal,前面介绍过它的性能已经显著优于传统的 Thrift 编解码代码,但它还有提升空间。
The current implementation of Frugal uses Go to directly generate the corresponding assembly code. We have also applied some optimization methods in the specific implementation, such as generating more compact code, reducing branches, etc. However, we cannot make full use of existing compiler optimization technology by writing it ourselves.
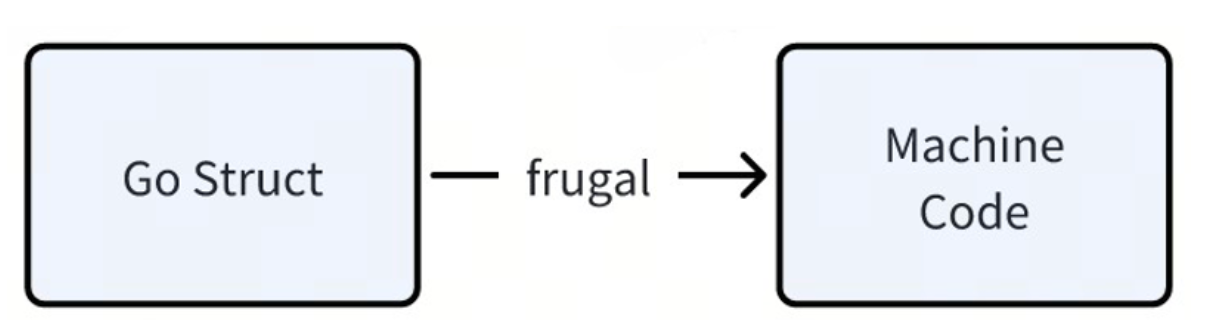
We plan to reconstruct Frugal to generate an SSA-compliant LLVM IR (Intermediate Representation) based on go struct, so that we can make full use of LLVM's compilation optimization capabilities.

It is expected that after this transformation, the performance can be improved by at least 30%.
On-demand Serialization | On-demand Serialization
Another direction of exploration is on-demand serialization, which can be divided into three parts.
The first is before compilation. We have currently released an IDL clipping tool that can identify types that are not referenced; however, the referenced types may not be needed. For example, two services A and B depend on the same type, but one of the fields may be A. Required, B does not need. We consider adding user annotation capabilities to this tool, allowing users to specify unnecessary fields, thereby further reducing serialization overhead.
The second is compilation. The idea is to obtain the fields that actually violate the business code reference and prune them based on the compiler's compilation report. The specific scheme and correctness still require some verification.
Finally, after compilation, at runtime, the business is also allowed to specify unnecessary fields, thereby saving encoding and decoding overhead.
Summary | Summary
Finally, let’s review the overall situation:
In terms of capability upgrading,
-
Kitex has optimized the performance of generalization calls through DynamicGo, and the high-performance Frugal codec has been stabilized and can be used in production environments;
-
In the past year, fallback was added to facilitate businesses to implement customized downgrade strategies, and the unkown fields and session delivery mechanisms were used to solve the problem of long link transformation;
-
We have also improved the usability of Kitex through document optimization, demo projects, troubleshooting efficiency improvements, and enhanced command line tools;
In terms of community cooperation,
-
We support Dubbo's hessian2 protocol through the Kitex-Dubbo interoperability project, which can interoperate with Dubbo Java and Dubbo-Go frameworks, and there are subsequent optimizations that can also feed back to the Dubbo community;
-
In the configuration center integration project, we released the Nacos extension to facilitate user integration, and are currently continuing to promote the docking of other configuration centers;
There are still some directions for exploration in the future.
-
In terms of merged deployment, through affinity deployment and compilation and merging, we can not only retain the benefits of microservices, but also enjoy the advantages of some monoliths not serving services;
-
In terms of serialization, we continue to further optimize Frugal and achieve on-demand serialization capabilities through all aspects of compilation before, during and after compilation;
The above is a review and outlook on Kitex on the occasion of the second anniversary of CloudWeGo. I hope it will be helpful to everyone, thank you.
{{o.name}}
{{m.name}}