

Sharing guests:
Yang Linsan-Huixi Intelligence
About Huixi Intelligence:
Huixi Intelligence is a start-up company that makes autonomous driving chips, founded in 2022. Committed to building an innovative in-vehicle intelligent computing platform, it provides high-end intelligent driving chips, easy-to-use open tool chains and full-stack autonomous driving solutions to help car companies achieve high-quality and efficient autonomous driving mass production and delivery, and build low-cost, large-scale and automated iteration capabilities. , leading high-end smart travel in the data-driven era.
Share the outline:
- How to use Alluxio in a startup?
- The process of using Alluxio from 0-1 (research-deployment-onto production).
- Practical experience sharing.
The following is the full text version of the content shared
Share topic:
"Application and Deployment of Alluxio in Autonomous Driving Model Training"
Autonomous driving data closed loop
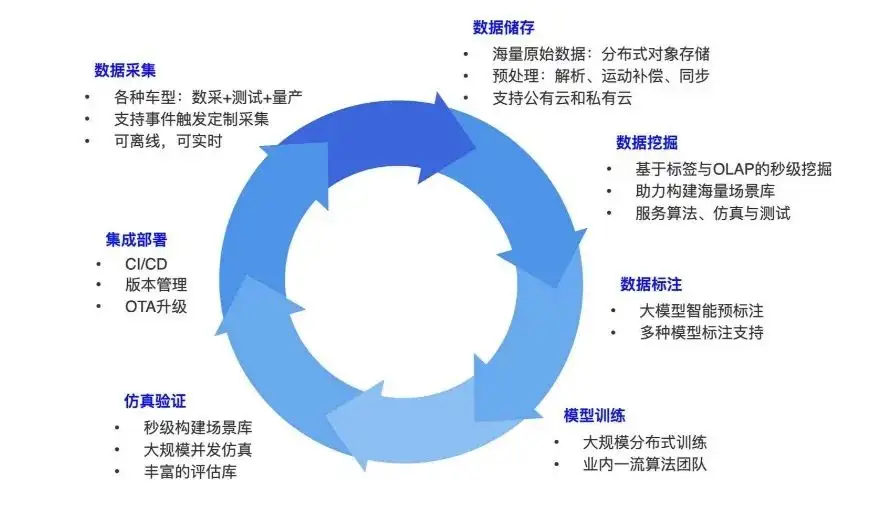
First, let me share how to build a data closed loop in autonomous driving. Everyone may know this business process. Autonomous driving will include a variety of vehicle types, such as data mining vehicles and cars running on the road with algorithms. Data collection is to collect various data from the self-driving car during the running process: for example, the camera data is pictures, and the lidar data is point clouds.
When the sensor data is collected, a car may generate several terabytes of data every day. This kind of data is stored as a whole through the base disk or other upload methods, and transferred to the object storage. After the original data is stored, there will be a pipeline for data analysis and preprocessing, such as cutting it into data frames one frame at a time, and synchronization and alignment operations may be performed between different sensor data in each frame.
After completing the data analysis, it is time to do more digging on it. Build data sets one by one. Because whether it is in algorithm, simulation or testing, a data set must be constructed. For example, if we want data on a certain night on a rainy day, at a certain intersection, or in some densely populated areas, then we will have a large number of such data requirements in the entire system, and we need to label the data and add some labels. For example, at the east gate of Tsinghua University, you need to get the longitude and latitude of this location and analyze the surrounding POIs. Then label the mined data. Common annotations include: objects, pedestrians, types of objects, etc.
This labeled data will be used for training. Typical tasks include target detection, lane line detection, or larger end-to-end models. After the model is trained, some simulation verification needs to be done. After verification, deploy it to the car, run the data, and collect more data based on this. It is such a cycle, constantly enriching data and constantly building models with better performance. This is what the entire training and data closed loop needs to do, and it is also the core thing in the current autonomous driving research and development.
Algorithm training: NAS
We focus on model training: model training mainly obtains data through data mining to generate a data set. The data set is internally a pkl file, including data, channel, and storage location. Finally, students who train on data algorithms will write their own download scripts to pull the data from the object storage to the local.
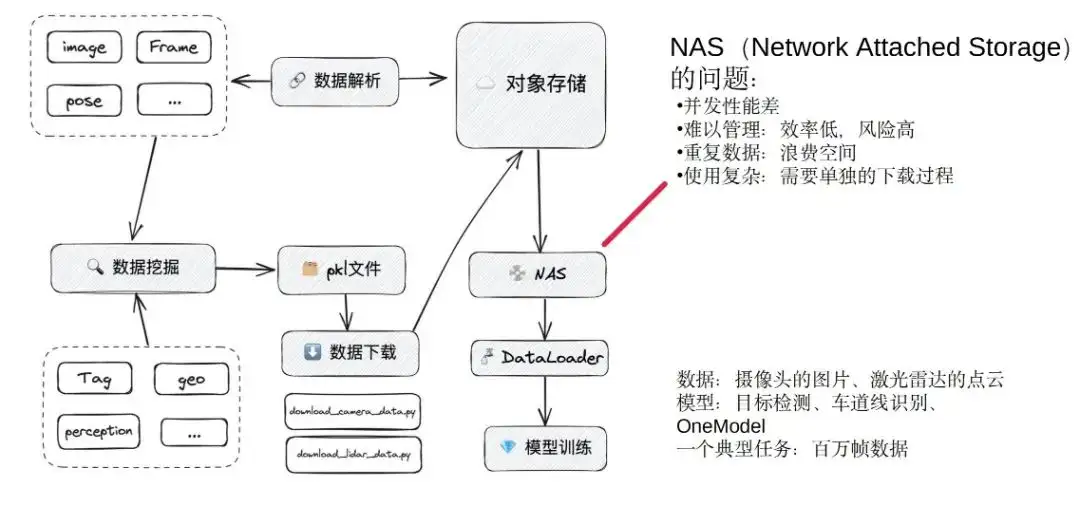
Before we chose Alluxio, we used the NAS system to act as a cache, pulling object storage data to the NAS, and finally using different models to load the data for training. This is the approximate training process before using Alluxio.
One of the biggest problems in NAS:
- Concurrency performance is relatively poor - we can understand NAS as a large hard disk, which is quite sufficient when only a few tasks are running together. However, when there are dozens of training tasks being performed simultaneously and many models are being trained, stucks often occur. There was a time when we were very stuck and the R&D team was complaining every day. It is so stuck that the availability and concurrency performance are very poor.
- Difficulty in management - everyone uses their own downloaded script, and then downloads the desired data to their own directory. Another person may download another pile of data by himself and put it in another directory of the NAS. This will make it difficult to clean up when the NAS space is full. At that time, we basically communicated in person or in WeChat groups. On the one hand, the efficiency is extremely low, and relying on group message management will lag behind. On the other hand, manual removal may also lead to some risks. We have had situations where other people's data sets were deleted when removing data. This will also cause errors in the online task area, which is another pain point.
- Waste of space - Data downloaded by different people are placed in different directories. It is possible that the same frame of data will appear in several data sets, resulting in a serious waste of space.
- It is very complicated to use - because the file formats in pkl are different, the download logic is also different, and everyone has to write the download program separately.
These are some of the difficulties and problems we faced when using NAS before. In order to solve these problems, we did research. After research, we focused on Alluxio. I found that Alluxio can provide a relatively unified cache. The cache can improve our training speed and reduce management costs. We will also use the Alluxio system to deal with the problem of dual computer rooms. Through unified namespace and access methods, on the one hand, our system design can be simplified, and on the other hand, the code implementation will also become very simple.
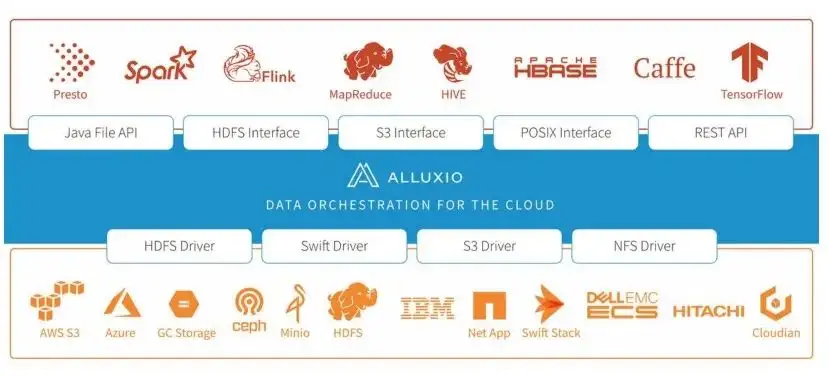
Algorithm training introduced in Alluxio
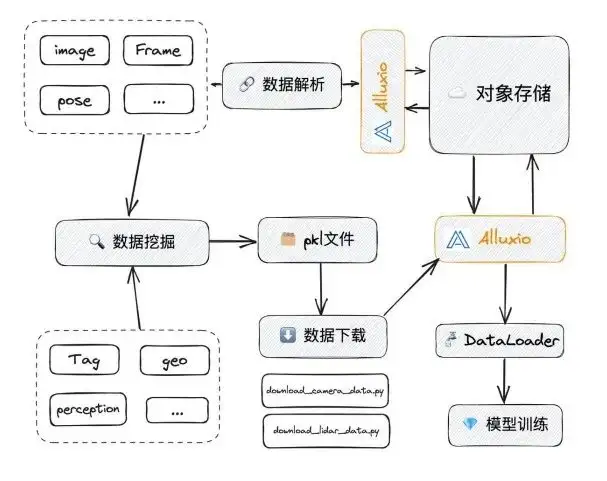
When we replace NAS with Alluxio, Alluxio can specifically solve some of the problems just mentioned:
- In terms of concurrency: NAS itself is not a fully distributed system, but Alluxio is. When the IO accessed by NAS reaches a certain speed, it will freeze. It may start to freeze when it reaches several G/s. The upper limit of Alluxio is very high. We have special tests below to illustrate this point.
- Manual cleaning or management will be very troublesome: Alluixo configures the cache eviction policy. Usually through LRU, when it reaches a threshold (such as 90%), it will automatically evict and clean the cache. The effect of this:
- Efficiency is greatly improved;
- It can avoid security issues caused by accidental deletion;
- Solved the problem of duplicate data.
In Alluxio, a file in UFS corresponds to a path in Alluxio. When everyone accesses this path, they can get the corresponding data, so that there will be no problem of duplicate data. In addition, using the above is relatively simple. We only need to access it through the FUSE interface and no longer need to download files.
The above solves the various problems we just talked about from a logical level. Let’s talk about our entire implementation process, how to realize Alluxio from 0 to 1, from the initial POC testing, to the verification of various performance, to the final deployment, operation and maintenance. Some of our practical experiences.
Alluxio deployment: single computer room
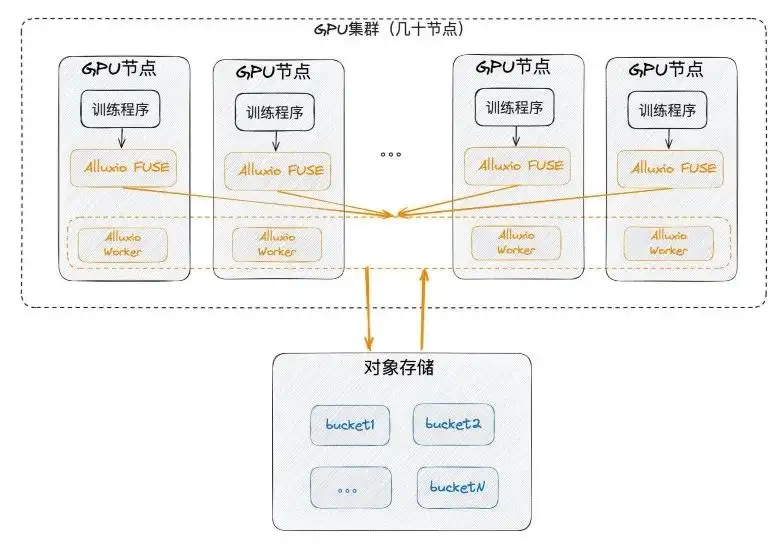
First of all, we may deploy it in a single computer room, which means it must be close to the GPU and deployed on the GPU node. At the same time, SSD, which was rarely used on the GPU before, was used to utilize each node, and then FUSE and workers were deployed together. FUSE is equivalent to the client, and the worker is equivalent to a small cache cluster with intranet communication to provide FUSE services. Finally, the worker communicates with the underlying object storage itself.
Alluxio deployment: across computer rooms
But due to various reasons, we will still have cross-machine rooms. There are now two computer rooms, and each computer room will have corresponding S3 services and corresponding GPU computing nodes. Basically we will deploy an Alluxio in every computer room. At the same time, we should also pay attention to this process. There may be two Alluxio object stores in one computer room. If another computer room also needs to mount S3, try to make a unified plan for the bucket names, and do not overload the two. For example, if there is bucket 1 here and bucket 1 there, it will cause some problems when Alluxio is mounted.
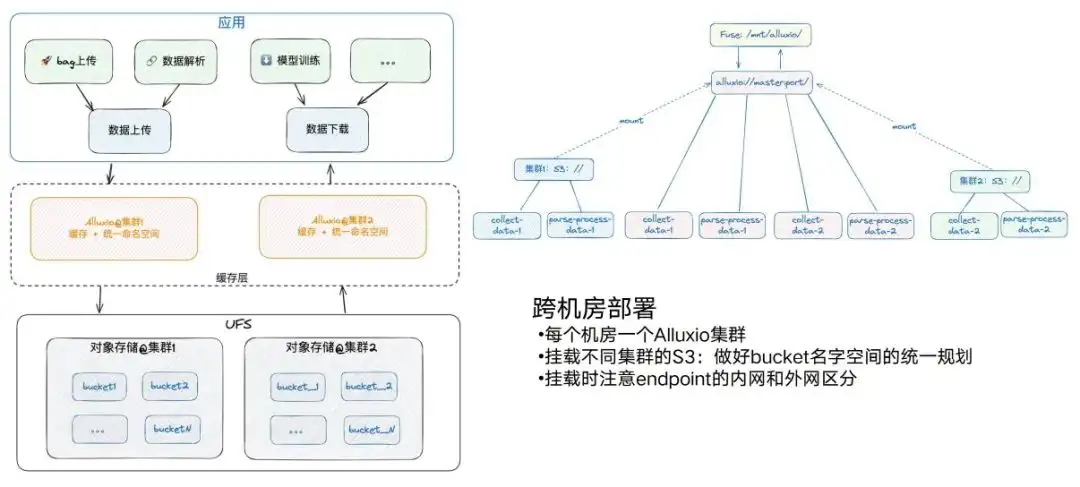
Also note that for different endpoints, pay attention to the distinction between the internal network and the external network. For example, Alluxio of cluster 1 mounts the internal network of the endpoint of cluster 1, and the external network is on the other side. Otherwise, the performance will be greatly reduced. After mounting, we can access the data of different buckets on different clusters through the same path, so that the entire architecture will become very simple. This is in terms of cross-machine room deployment.
Alluxio testing: functionality
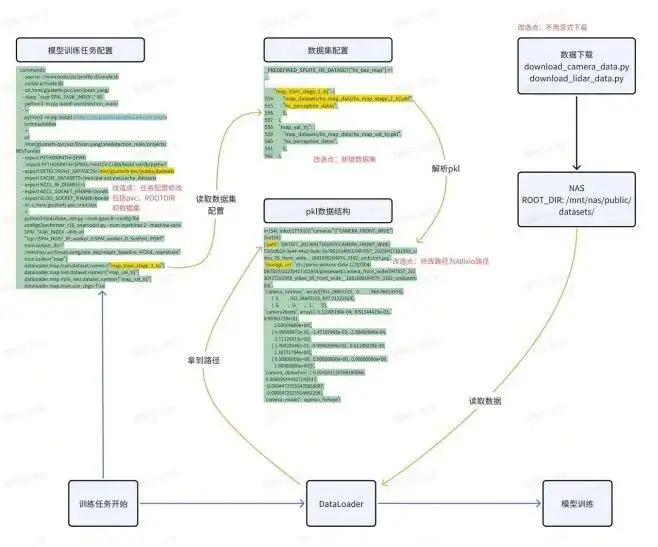
If you want to truly replace your NAS with Alluxio, you need to do a lot of functional testing before deployment. The purpose of this kind of functional testing is to make the existing algorithm process minimally modified so that algorithm students can also use it. This may depend on your actual situation. We did nearly 2-3 weeks of POC verification with Alluxio, which involved, for example:
- Configuration of accessing PVC on K8S;
- How the data set is organized;
- Configuration of job submission;
- Replacement of access paths;
- The scripting interface ultimately accessed.
Many of the problems encountered above may need to be verified. At least we need to select a typical task through it, and then make some modifications, and finally replace the NAS with Alluxio relatively smoothly.
Alluxio Test: Performance
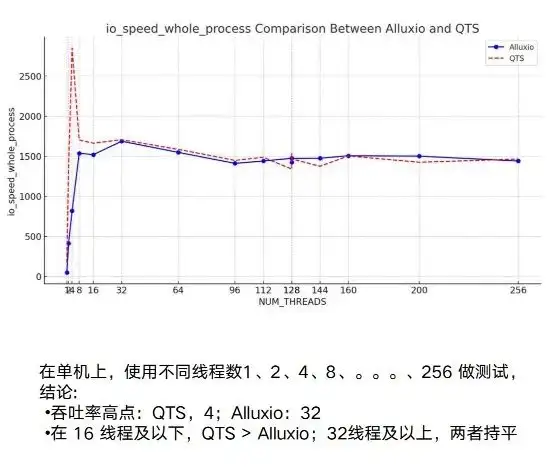
Next, on this basis, some performance tests will be done. In this process, we have done relatively sufficient testing, whether it is a single machine or multiple machines. On a single machine, the performance of Alluxio and the original NAS is basically the same.
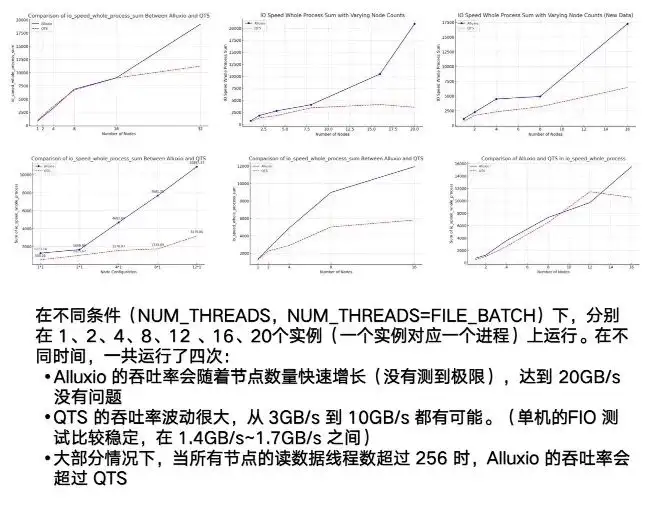
In fact, what truly embodies the advantages of Alluxio is its multi-host and distributed capabilities. You can see NAS or our example of QTS, which has a very obvious point: instability. The fluctuation between testing 3G and 10G will be relatively large. At the same time, it has an obvious bottleneck. When it reaches about 7/8G, it is basically stable.
In fact, what truly embodies the advantages of Alluxio is its multi-host and distributed capabilities. You can see NAS or our example of QTS, which has a very obvious point: instability. The fluctuation between testing 3G and 10G will be relatively large. At the same time, it has an obvious bottleneck. When it reaches about 7/8G, it is basically stable.
As for Alluxio, during the entire test process, as the number of running instances increases, the node can reach a very high upper limit. When we set it to 20GB/s, it still showed an upward trend. This shows that the overall concurrent and distributed performance of Alluxio is very good.
Alluxio landing: adjusting parameters and adapting the environment
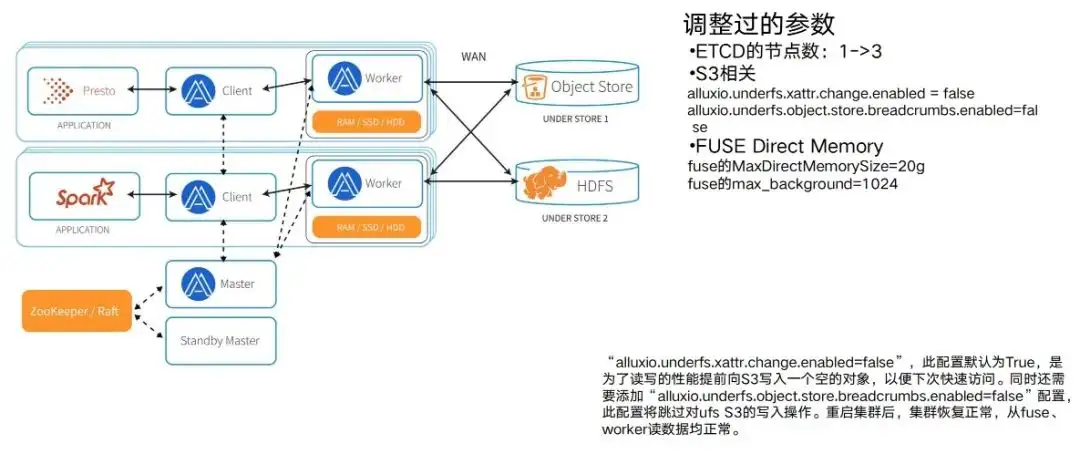
After completing the functional verification and performance testing, it is time to actually deploy the Alluxio cluster. After deployment, a process of parameter adjustment and adaptation is required. Because during the test, only some typical tasks were used. After actually using the Alluxio environment, you will find that as the tasks increase, there will be a process of parameter adjustment and adaptation. It is necessary to match the corresponding parameters on Alluxio with the actual operating environment before its performance can be fully utilized. Therefore, there will be a process of running, operating and maintaining, and adjusting parameters.
We have gone through some typical parameter adjustment processes, such as:
- The nodes of ETCD are listed here. It is 1 at the beginning, and then changes to 3. This ensures that it is one ETCD that is hung up, and the entire cluster is not hung up.
- There are also S3 related ones. For example, when Alluxio is implemented, it will let S3 generate a relatively long access path, and write some blanks by default in the middle path nodes to give it better performance. But in this case, the S3 under our training task has permission control and they are not allowed to write this kind of data. Faced with this kind of conflict, parameter adjustment is also needed.
- There are also capabilities like the concurrency intensity that the FUSE node itself can tolerate. Including the size of the Direct Memory it uses, it actually has a lot to do with the actual concurrency intensity of the entire business. It actually has a lot to do with the amount of data that can be accessed at one time. There is also a parameter adjustment process, and so on. Different problems may be encountered in different environments. This is also the reason to choose Alluxio Enterprise Edition. Because Alluxio will have very strong support during the enterprise version, it can adjust and cooperate when encountering problems 24/7. Only with mutually coordinated cycles can the entire cluster run more smoothly.
Alluxio implementation: operation and maintenance
Our team's earliest operation and maintenance classmate only had one person, who was responsible for a lot of underlying Infra maintenance and related work. When I wanted to deploy Alluxio, the resources on the operation and maintenance side were actually not enough, so it was equivalent to me also doing part-time work. Half operation and maintenance. From the perspective of operating and maintaining something yourself, it is important to keep a lot of records and knowledge about operation and maintenance, especially for a novice. For example, how to solve the problem better next time and whether you have had such experience before.
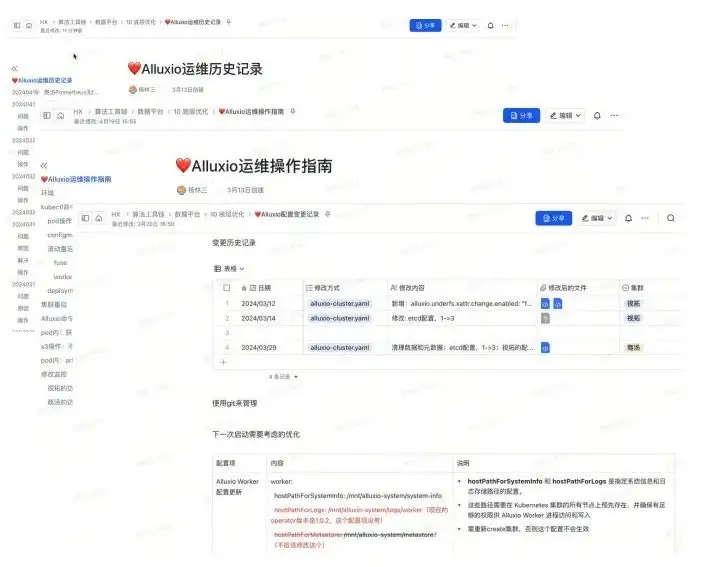
Based on our environment at that time, three documents will be maintained.
- Operation and maintenance history documents : For example, what problems occurred on which day? What is the root cause of these problems and what is their solution? What are the specific operations?
- Operation documentation : For example, if we operate and maintain K8S, what are the steps to restart it, what are the operations, how to read the logs when problems occur, how to troubleshoot, and which task and work should be run on to see the data corresponding to FUSE. , monitoring, etc. These are some commonly used operations.
- Configuration changes: Because Alluxio is in the process of adjusting parameters. At different times, you may encounter different configuration files and yaml files, and you may need to make some backups. You can use Git to manage it, or you can simply use document management. This way it is possible to trace back to the current configuration and historical configuration versions.
On this basis, we will also have some related supporting construction to better use Alluxio. R&D students think Alluxio is quite easy to use after using it. But when multitasking, some supporting construction needs are exposed. For example, we need to resize the image and reduce the image from high-definition 4K to 720P to support more task caching.
The training data set is synchronized across clusters for better data preloading. These are all centered around the systematic construction that Alluxio needs to do.
Alluxio landing: making progress together
As we continue to use Alluxio, we will also find some areas worthy of improvement. By giving feedback to Alluxio, we have promoted the iteration of the entire product. Here are a few points in particular:
From the students who develop algorithms, what they care about is:
- Stability: It must be stable during operation. It cannot hinder the training of the entire system because of something crashing in Alluxio. There may be some operation and maintenance tips here, such as trying not to restart FUSE as much as possible. As mentioned just now, restarting FUSE means that its access path will fail and an IO error will occur when reading data files.
- Determinism: For example, Alluxio previously suggested that data does not need to be preloaded, that is, it does not need to be read once before pre-training, but only needs to be read once during the first epoch. However, because R&D has a release cycle, he needs to know exactly how long it will take to preload. If he reads it through the first epoch, it is difficult to estimate the entire training time. This actually also extends to how to cache through a file list. This also puts some demands on Alluxio.
- Controllability: Although Alluxio can provide automated LRU-based cache eviction and cache cleaning. But in fact, R&D still hopes that some data that has been cached can be proactively cleaned. So can you also let Alluxio free this data by providing a file list? This is also our need to use Alluxio directly and in a very controllable way in addition to indirect use.
From the operation and maintenance side, some requirements will also be raised:
- Configuration center: Alluxio itself can provide a configuration center to save the configuration history. When adding a function to implement changes to configuration items, budget in advance what impact this change will have;
- Trace tracks the running process of a command: Another more realistic requirement. For example, we now find a problem: the delay when accessing a UFS file at the bottom is relatively high. What is the reason? We may not be able to see the reason by looking at the FUSE logs, so we need to look at the worker logs corresponding to the location. This is actually a very time-consuming and troublesome process, and the problem often cannot be solved, requiring Alluxio's online customer service support. Can Alluxio add a Trace command to trace the time-consuming issues of FUSE, work, and reading from UFS when accessing the entire link? This will actually be of great help to the entire operation and maintenance process or troubleshooting process.
- Intelligent monitoring: Sometimes the things we monitor are things we already know. For example, if there is a problem with Direct Memory, let's configure a monitoring item. But next time a new problem pops up in my log, it might be a hidden problem that happens quietly without anyone knowing. We hope to automatically monitor this situation.
We made various suggestions to Alluxio through work order feedback. It is hoped that Alluxio can provide more powerful functions during the product iteration process. Make the entire R&D, operation and maintenance matters more satisfying.
summary
First, Alluxio provides very good usability compared to NAS in terms of caching acceleration for the entire autonomous driving model training. For us it will also be about a 10x improvement. The cost reduction comes from two parts:
- Product procurement cost is low;
- NAS may have 20%-30% redundant storage, which Alluxio can solve.
From the perspective of maintainability, it can automatically clean data, which is more timely and safer. In terms of ease of use, it can access data more conveniently through FUSE.
Second, I also shared how Huixi deploys Alluxio from 0 to 1 and operates and maintains a system.
The above is my sharing, thank you all.
