
With the development of large language model (LLM) technology, RAG (Retrieval Augmented Generation) technology has been widely discussed and researched, and more and more advanced RAG retrieval methods have been discovered. Compared with ordinary RAG retrieval, advanced RAG provides more accurate, more relevant, and richer information retrieval results through deeper technical details and more complex search strategies. This article first discusses these technologies and gives an implementation case based on Milvus.
01.Junior RAG
Definition of primary RAG
The primary RAG research paradigm represents the earliest methodology and gained importance soon after the widespread adoption of ChatGPT. Primary RAG follows the traditional process, including indexing, retrieval, and generation. It is often described as a "retrieval-reading" framework, and its workflow includes three key steps:
-
The corpus is divided into discrete chunks, and an encoder model is then used to build vector indices.
-
RAG identifies and retrieves chunks based on vector similarity between queries and indexed chunks.
-
The model generates answers based on contextual information obtained in the Retrieved Chunk.
Limitations of primary RAG
初级 RAG 在三个关键领域面临着显著挑战:"检索"、"生成"和"增强"。
There are many problems with the retrieval quality of primary RAG, such as low precision and low recall. Low precision can lead to misalignment of retrieved blocks, as well as potential issues such as hallucinations. A low recall rate will result in the inability to retrieve all relevant blocks, resulting in an insufficiently comprehensive response from LLM. Additionally, using older information further exacerbates the problem and can lead to inaccurate search results.
The quality of generated responses faces illusory challenges, that is, the answers generated by LLM are not based on the provided context, are not relevant to the context, or the responses generated have the potential risk of containing harmful or discriminatory content.
During the enhancement process, primary RAG also faces considerable challenges in how to effectively integrate the context of the retrieved passages with the current generation task. Inefficient integration can result in incoherent or fragmented output. Redundancy and duplication are also a thorny issue, especially when multiple retrieved passages contain similar information, and duplicate content may appear in the generated responses.
02. Advanced RAG
In order to solve the shortcomings of the primary RAG, the advanced RAG was born and its functions were enhanced in a targeted manner. We first discuss these techniques, which can be categorized as pre-retrieval optimization, mid-retrieval optimization, and post-retrieval optimization.
Pre-search optimization
Pre-retrieval optimization focuses on data index optimization and query optimization. Data index optimization technology aims to store data in a way that improves retrieval efficiency:
-
Sliding window: Uses overlap between blocks of data, this is one of the simplest techniques.
-
Enhance data granularity: Apply data cleaning techniques, such as removing irrelevant information, confirming factual accuracy, updating outdated information, etc.
-
Add metadata: such as date, purpose or chapter information for filtering.
-
Optimizing the index structure involves different data indexing strategies: such as adjusting the block size or using a multi-index strategy. One technique we will implement in this article is sentence window retrieval, which embeds individual sentences at retrieval time and replaces them with larger text windows at inference time.
Optimize during search
The retrieval phase focuses on identifying the most relevant context. Typically, retrieval is based on vector search, which computes semantic similarity between query and indexed data. Therefore, most search optimization techniques revolve around embedding models:
-
Fine-tune embedding models: Customize embedding models to specific domain contexts, especially for domains with developmental or rare terminology. For example,
BAAI/bge-small-enis a high-performance embedding model that can be fine-tuned. -
Dynamic embedding: adapts to the context in which words are used, unlike static embedding which uses one vector per word. For example, OpenAI's
embeddings-ada-02is a complex dynamic embedding model that captures contextual understanding. In addition to vector search, there are other retrieval techniques, such as hybrid search, which usually refers to the concept of combining vector search with keyword-based search. This search technique is beneficial if the search requires exact keyword matches.
Post-retrieval optimization
For the retrieved context content, we will encounter noise such as the context exceeding the window limit or the noise introduced by the context, which will distract attention from the key information:
-
Prompt compression: Reduce overall prompt length by removing irrelevant content and highlighting important context.
-
Re-ranking: Use a machine learning model to recalculate the relevance score of the retrieved context.
Post-search optimization techniques include:
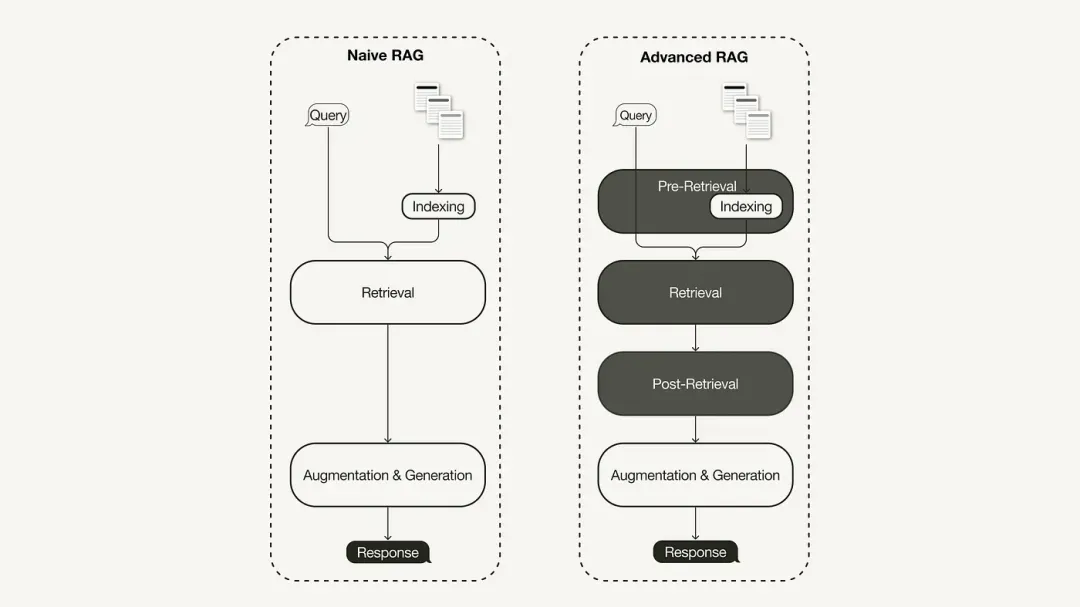
03. Implement advanced RAG based on Milvus + LlamaIndex
The advanced RAG we implemented uses OpenAI's language model, the BAAI rearrangement model hosted on Hugging Face, and the Milvus vector database.
Create Milvus index
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext
vector_store = MilvusVectorStore(dim=1536,
uri="http://localhost:19530",
collection_name='advance_rag',
overwrite=True,
enable_sparse=True,
hybrid_ranker="RRFRanker",
hybrid_ranker_params={"k": 60})
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes,
storage_context=storage_context
)
Index optimization example: sentence window retrieval
We use SentenceWindowNodeParser in LlamaIndex to implement sentence window retrieval technology.
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
SentenceWindowNodeParser performs two operations:
It separates the document into separate sentences, which are embedding.
For each sentence, it creates a context window. If you specify window_size = 3, then the resulting window will contain three sentences, starting with the sentence before the embedded sentence and spanning to the sentence after it. This window will be stored as metadata. During retrieval, the sentence that best matches the query is returned. After retrieval, you need to replace the sentence with the entire window from the metadata by defining a MetadataReplacementPostProcessorand using it in the list.node_postprocessors
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
Search optimization example: hybrid search
Implementing hybrid search in LlamaIndex requires only two parameter changes to the query engine, provided that the underlying vector database supports hybrid search queries. Milvus version 2.4 did not support hybrid search before, but in the recently released version 2.4, this feature is already supported.
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", #Milvus 2.4开始支持, 在2.4版本之前使用 Default
)
Post-retrieval optimization example: Re-ranking
Adding a re-ranking to advanced RAG requires only three simple steps:
First, define a re-ranking model using Hugging Face BAAI/bge-reranker-base.
In the query engine, add the reorder model to node_postprocessorsthe list.
Increase in the query engine similarity_top_kto retrieve more context fragments, which can be reduced to top_n after rearrangement.
from llama_index.core.postprocessor import SentenceTransformerRerank
rerank = SentenceTransformerRerank(
top_n = 3,
model = "BAAI/bge-reranker-base"
)
...
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors = [rerank],
...,
)
For detailed implementation code, please refer to Baidu Netdisk link: https://pan.baidu.com/s/1Cj_Fmy9-SiQFMFNUmO0OZQ?pwd=r2i1 Extraction code: r2i1
The pirated resources of "Qing Yu Nian 2" were uploaded to npm, causing npmmirror to have to suspend the unpkg service. Zhou Hongyi: There is not much time left for Google. I suggest that all products be open source. Please tell me, time.sleep(6) here plays a role. What does it do? Linus is the most active in "eating dog food"! The new iPad Pro uses 12GB of memory chips, but claims to have 8GB of memory. People’s Daily Online reviews office software’s matryoshka-style charging: Only by actively solving the “set” can we have a future. Flutter 3.22 and Dart 3.4 release a new development paradigm for Vue3, without the need for `ref/reactive `, no need for `ref.value` MySQL 8.4 LTS Chinese manual released: Help you master the new realm of database management Tongyi Qianwen GPT-4 level main model price reduced by 97%, 1 yuan and 2 million tokens