
Sharing guest:
Fu Qingwu - big data architect of OPPO data architecture group
在OPPO的实际应用中,我们将自研的Shuttle与Alluxio完美结合,使得整个Shuttle Service的性能得到显著提升,基本上实现了性能翻倍的效果。通过这一优化,我们成功降低了约一半的系统压力,同时吞吐量也直接翻倍。这样的结合不仅解决了性能问题,更为OPPO的服务体系注入了新的活力。
Full text version sharing content↓
Sharing topic: "Alluxio's Practice in Data&AI Lake and Warehouse Integration"
Data&AI integrated data lake warehouse architecture
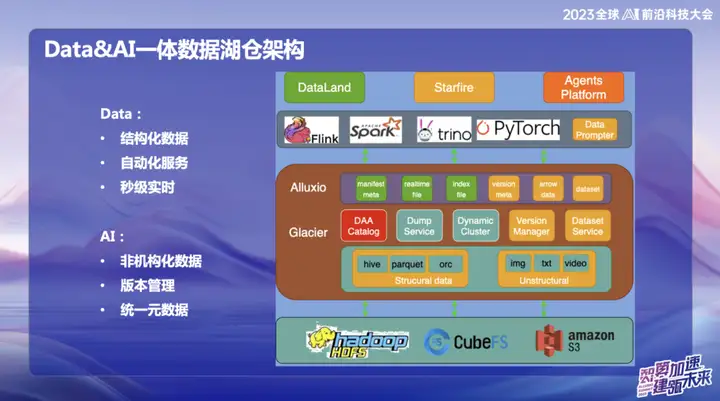
The picture above shows OPPO’s current overall architecture, which is mainly divided into two parts:
1、Data
2、AI
In the data field, OPPO mainly focuses on structured data, that is, data that is usually processed using SQL. In the field of AI, the main focus is on unstructured data. In order to achieve unified management of structured and unstructured data, OPPO has established a system called Data and Catalog, which is managed in the form of Catalog metadata. At the same time, this is also a data lake service, in which the upper data access layer uses Alluxio distributed cache.
Why did we choose to use Alluxio?
Because of the large scale of OPPO's domestic computer room, the amount of idle memory on the computing nodes is considerable. We estimate that on average about 1PB of memory is idle every day, and we hope to make it fully utilized through this distributed memory management system. The orange part represents the management of unstructured data. Our goal is to use data lake services to make unstructured data as easy to manage as structured data and provide acceleration for AI training.
DAA-Catalog
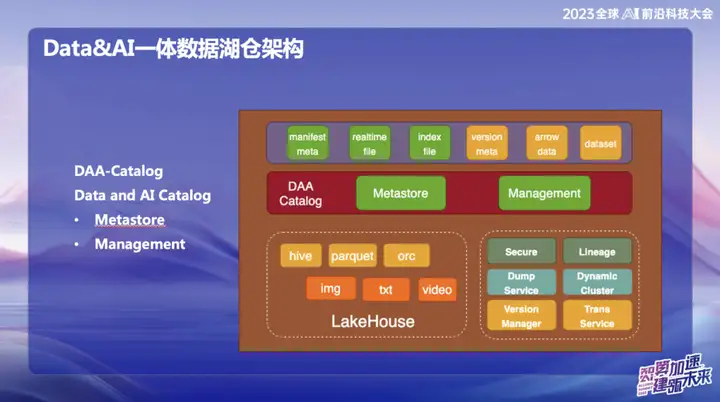
DAA-Catalog, or Data and AI Catalog, is the goal pursued by our team at the bottom of the data architecture. We chose this name because OPPO is committed to competing with the best companies in the industry. Currently, we believe that Databricks is one of the most outstanding companies in the field of Data&AI. Whether it is technology, advanced concepts or business models, Databricks has performed well.
Inspired by Databricks' Unicatalog, we see that Databricks' Service data and AI training process mainly revolve around Unity Catalog. Therefore, we decided to build DAA-Catalog to pursue our goal of competing with the best in the industry in the data lake warehousing space.
Specifically, this functionality is divided into two main modules:
- Metastore (metadata storage) : This part is responsible for the management of metadata, and the underlying layer is based on Iceberg metadata management. Includes concurrent commits and lifecycle management. At the same time, we use Down Service for management, because our data will first enter Alluxio's huge memory cache pool, and realize real-time insertion and query of each record.
- Management : This part is DOM service. Why choose Down Service? Because the data is first stored in Alluxio's memory after entering it, it achieves second-level real-time performance. During the entire process, the data will automatically sink to Iceberg through Catalog after it comes in, and the metadata is basically in Alluxio.
Why do we need to implement such a second-level real-time function?
Mainly because we found a serious problem when using Iceberg before. It basically requires a commit every 5 minutes. Each commit will generate a large number of small files, which puts a lot of pressure on the Flink computing system and the metadata of HDFS. At the same time, these files also need to be cleaned and merged manually. Through the Alluxio service, data can be directly entered into the memory, and the Down Service is also managed through the Catalog. During the entire process, data will automatically sink to Iceberg after entering it, and metadata is basically all in Alluxio.
Since OPPO has a lot of cooperation with Alluxio, we made some adjustments based on version 2.9, and the performance has been greatly improved. Reading and writing of streaming files are implemented on the data lake. Each piece of data can be treated like a commit without the need for the entire file to be committed.
Structured data acceleration
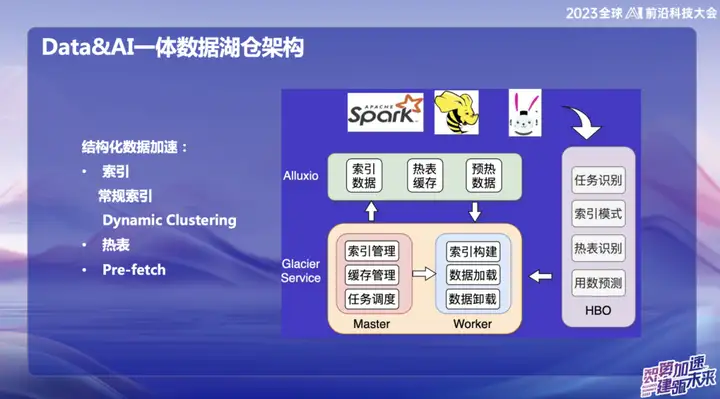
With the development of big data, many infrastructures have become quite complete, solving problems in many different scenarios. However, our focus is on how to utilize idle resources and memory more efficiently. Therefore, we are committed to starting from two aspects: one is cache acceleration, and the other is the optimization of hot tables and indexes.
We proposed a concept called "Dynamic Cluster", which is a function of dynamically aggregating data, inspired by a technology of Databricks. Although the Hallway curve is also used internally, we implemented "the order" and "incremental the order" sorting algorithms on top of it, fusing them together to form Dynamic Cluster. This innovation can dynamically aggregate data after data entry to improve query efficiency. Compared with the Hallway curve, the "order" algorithm is more efficient, but the Hallway curve is superior in real-time changes. This integration provides us with a more flexible and efficient way to query and aggregate data.
Unstructured data management
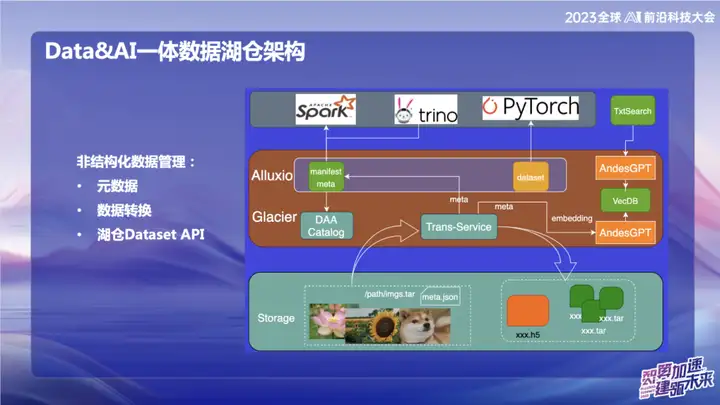
The picture above shows some of our work in the field of unstructured data, mainly related to the field of AI. Within OPPO, the tools used for AI training at the beginning are relatively old. Data is usually read directly through scripts, or the data is stored on object storage in the form of naked txt files or naked image files. With the Transfer service, we can automatically import data into the data lake and cut the packaged image data into update set format. In the field of AI, especially in the field of image processing, update set is an efficient data set interface. It is not only compatible with web data set interfaces, but can also be converted into H5 format.
Our goal is to make unstructured data management as convenient as structured data by processing metadata. During the data conversion process, the metadata of unstructured data is written into the Catalog. At the same time, we combined with the large model and wrote some information of the metadata into the vector database to make it easier to query the data in the lake warehouse using the large model or natural language. The goal of this integration work is to improve the management efficiency of unstructured data and make it more consistent with the management of structured data.
Unstructured Data - Metadata Management Example
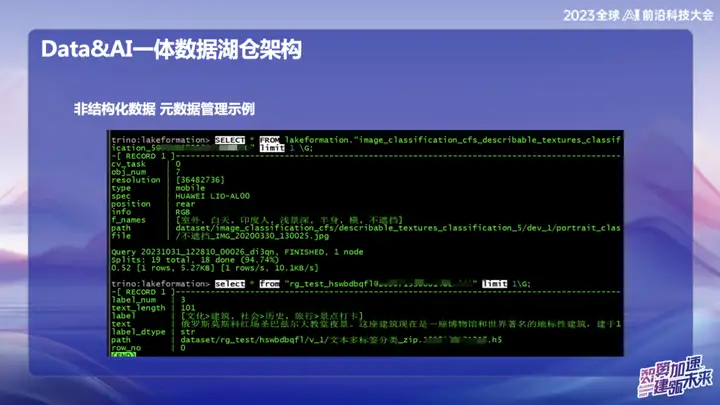
The picture above is an example of OPPO's unstructured data management, which can search the location of text and pictures like SQL.
DataPrompte r
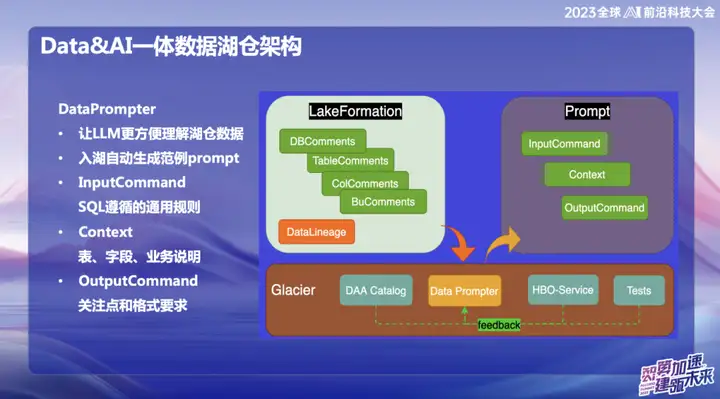
The original intention of choosing to build DataPrompter stems from the pursuit of better utilization of large models. OPPO is committed to the field of combining data with large models and has launched a product called Data Chart. Through internal chat software, users can easily query all data. For example, users can easily check the sales volume of mobile phones yesterday, or compare the sales difference with Xiaomi mobile phone sales, and perform data analysis through natural language.
During the product building process, the data tables in each field require professional business personnel to input Prompter. This brings challenges to the promotion of the entire data lake warehouse or product, because the Prompter of each table takes a long time. For example, if you want to input financial table data, you need to fill in professional and technical information such as the fields of the table, the meaning of the business domain, and expanded dimension tables in detail.
Our ultimate goal is to enable the large model to easily understand the upper-level data after the data enters the lake warehouse. During the process of data entering the lake, the business needs to display some prescribed information, combined with our accumulated experience in Data Prompter, and use some common queries provided by HBO Service to finally generate a Prompter template that makes the large model easy to understand. This combination aims to allow the model to better understand business data and make the integration of Hucang and large models smoother.
Alluxio helps to enter the lake in real time in seconds
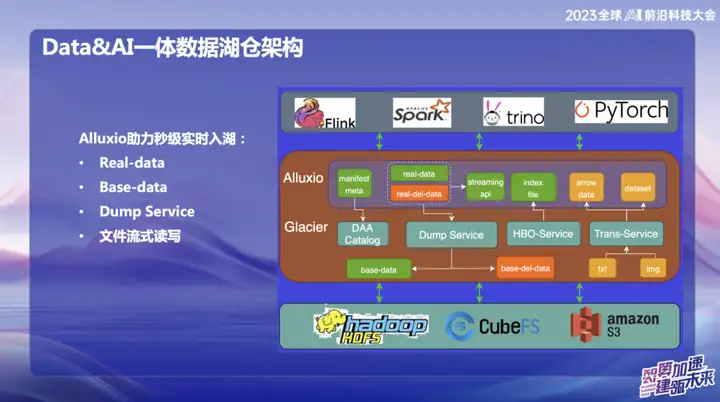
Alluxio helps to enter the lake in real time in seconds, which is mainly divided into:
1、Real-data
2、Base-data
3、Dump Service
4. File streaming reading and writing
Alluxio’s practice in Hucang architecture
Alluxio combined with Spark RSS
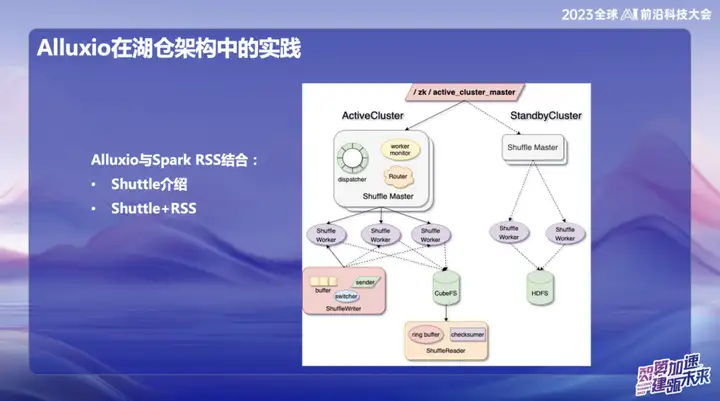
We initially chose to combine Alluxio with the Spark RSS service through the self-developed Spark Shuttle Service and open source it in the name of Shuttle. Initially, our underlying base was based on a distributed file system, but then we encountered some performance issues, so we found Alluxio.
Shuttle与Alluxio的完美结合使得整个Shuttle Service的性能得到了显著提升,基本上实现了性能翻倍的效果。通过这一优化,我们成功降低了约一半的系统压力,同时吞吐量也直接翻倍。这次的结合不仅解决了性能问题,更为我们的服务体系注入了新的活力。
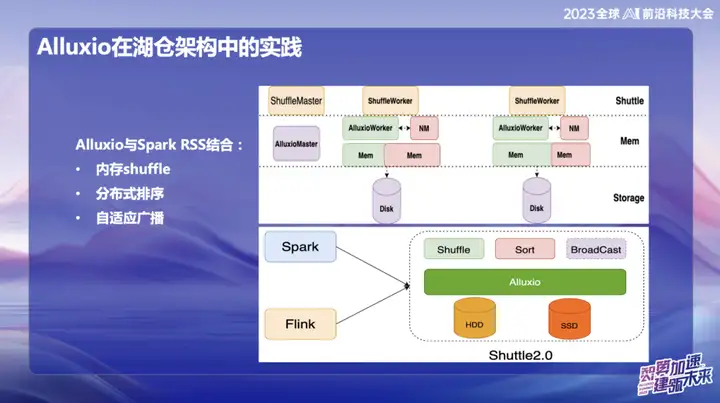
In OPPO's subsequent research and development, the framework based on Alluxio+Shuttle has achieved more innovations. We optimize both the Shuttle operator and the broadcast operator to the memory data level. Through efficient memory data interaction, especially when processing single-point Reduce, when the data is skewed, the sorting operation that originally took up to 50 minutes can be migrated. After adopting the new solution, the processing time was successfully reduced to less than 10 minutes. This optimization not only greatly improves processing efficiency, but also effectively alleviates the impact of data skew on system performance.
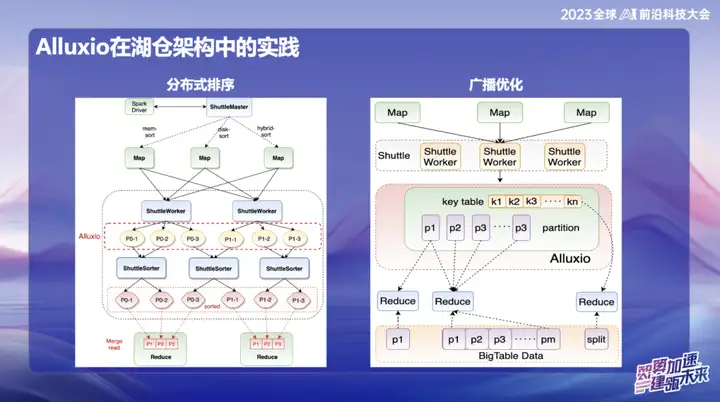
广播成果非常显著,特别是在Spark中,默认广播大小为10M,因为所有的广播数据都必须在Java端存放,在经过Java序列化后容易发生膨胀,进而引发OOM(Out of Memory)问题,这在线上环境中经常发生。
为了解决这个问题,我们目前将广播数据存放到Alluxio中。这样一来,几乎可以广播任意大小的数据,最大可达10个G。这一创新在OPPO线上已经有多个案例成功实施,对提升效率产生了显著的影响。
Alluxio application practice on public cloud/hybrid cloud
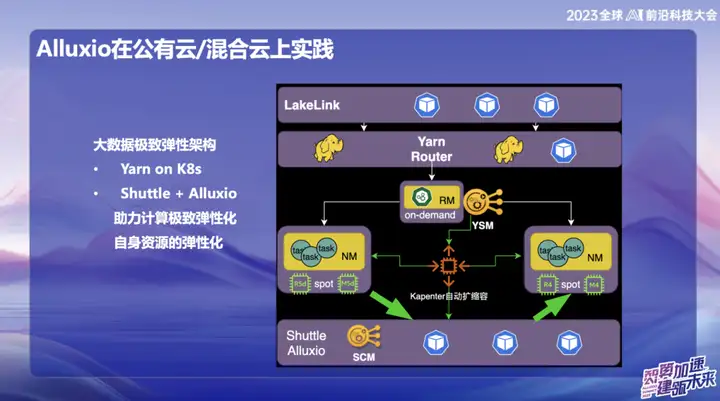
In OPPO's public cloud big data system, especially in Singapore, we mainly use AWS as the infrastructure. In the early stages, we used the elastic computing service (EMR) provided by AWS. However, in recent years, the overall economic situation of the industry has been less optimistic, and many companies are pursuing cost reduction and efficiency improvement. Faced with this trend, we have proposed self-developed solutions in the overseas public cloud field, using elastic resources on the cloud to build a new architecture. The core of this innovative solution relies on the combination of Alluxio+Shuttle, which provides key support for our big data system.

Alluxio+Shuttle解决方案的显著优势在于,Alluxio集群并非被Shuttle独占,它可以为其他服务提供支持,包括数据缓存和元数据缓存。在公有云中,我们深知S3上的List操作在提交时非常耗时,通过结合Alluxio和开源的Magic commit、 Shuttle的方案,我们取得了显著的降本效果,大约降低了计算成本的80%。
In a hybrid cloud environment, we provide services to AI teams. Since there is object storage at the bottom of the data lake, we used the GPU card on Alibaba Cloud during the training process, and also combined it with self-built GPU resources. Due to the limited bandwidth and high cost of dedicated lines, an effective cache layer is required for data copying. Initially, we adopted a solution provided by the storage team, but its scalability and performance were not ideal. After introducing Alluxio, we have achieved several times IO acceleration in multiple scenarios, providing more efficient support for data processing.
Outlook

OPPO's cluster scale has reached tens of thousands of units in China, forming a quite large scale. We plan to dig deeper into memory resources in the future to more fully utilize the internal storage space. The team has both the real-time computing framework Flink and the offline processing framework Spark. The two can learn from each other's application experience of Alluxio to achieve in-depth integrated development of Alluxio and the data lake.
In the wave of combining big data and machine learning, we keep up with industry trends. Deeply integrate the data architecture with artificial intelligence (AI) from the bottom to provide high-quality services for AI as the top priority. This integration is not only a technological advancement, but also a strategic plan for future development.
Finally, we will further explore the advantages of Alluxio to help us reduce costs in public cloud environments. This not only involves technical optimization, but also includes more effective management of cloud computing resources, providing solid support for the company's sustainable development.
The pirated resources of "Qing Yu Nian 2" were uploaded to npm, causing npmmirror to have to suspend the unpkg service. Zhou Hongyi: There is not much time left for Google. I suggest that all products be open source. Please tell me, time.sleep(6) here plays a role. What does it do? Linus is the most active in "eating dog food"! The new iPad Pro uses 12GB of memory chips, but claims to have 8GB of memory. People’s Daily Online reviews office software’s matryoshka-style charging: Only by actively solving the “set” can we have a future. Flutter 3.22 and Dart 3.4 release a new development paradigm for Vue3, without the need for `ref/reactive `, no need for `ref.value` MySQL 8.4 LTS Chinese manual released: Help you master the new realm of database management Tongyi Qianwen GPT-4 level main model price reduced by 97%, 1 yuan and 2 million tokens