Table of contents
2. Statistics of Millions of Test Data
1. HyperLogLog
First, let’s understand two concepts:
UV: The full name is Unique Visitor, also known as independent visitor volume, which refers to the natural person who visits and browses this web page through the Internet.
If the same user visits the website multiple times within one day, only one visit will be recorded.
PV: The full name is Page View, also called page views or clicks. Every time a user visits a page on the website, PV is recorded.
If multiple PVs are recorded,
Often used to measure website traffic.
Generally speaking, UV is much larger than PV, so when measuring the number of visits to the same website, we need to consider many factors.
So we just use these two values as a reference value
It is more troublesome to do UV statistics on the server side, because in order to determine whether the user has been counted, the counted user information needs to be saved.
But if every visiting user is saved in Redis, the amount of data will be horrible, so how to deal with it?
Hyperloglog (HLL) is a probabilistic algorithm derived from the Loglog algorithm for determining the cardinality of very large sets without storing all of their
value.
For the relevant algorithm principles, please refer to: https://juejin.cn/post/6844903785744056333#heading-0
The HLL in Redis is implemented based on the string structure. The memory of a single HLL is always less than 16kb, and the memory usage is shockingly low!
As a result, the measurement results are probabilistic, with an error of less than 0.81%.
However, for UV statistics, this can be completely ignored.

2. Statistics of Millions of Test Data
Test idea: We directly use unit testing to add 1 million data to HyperLogLog to see how the memory usage and statistical effects are
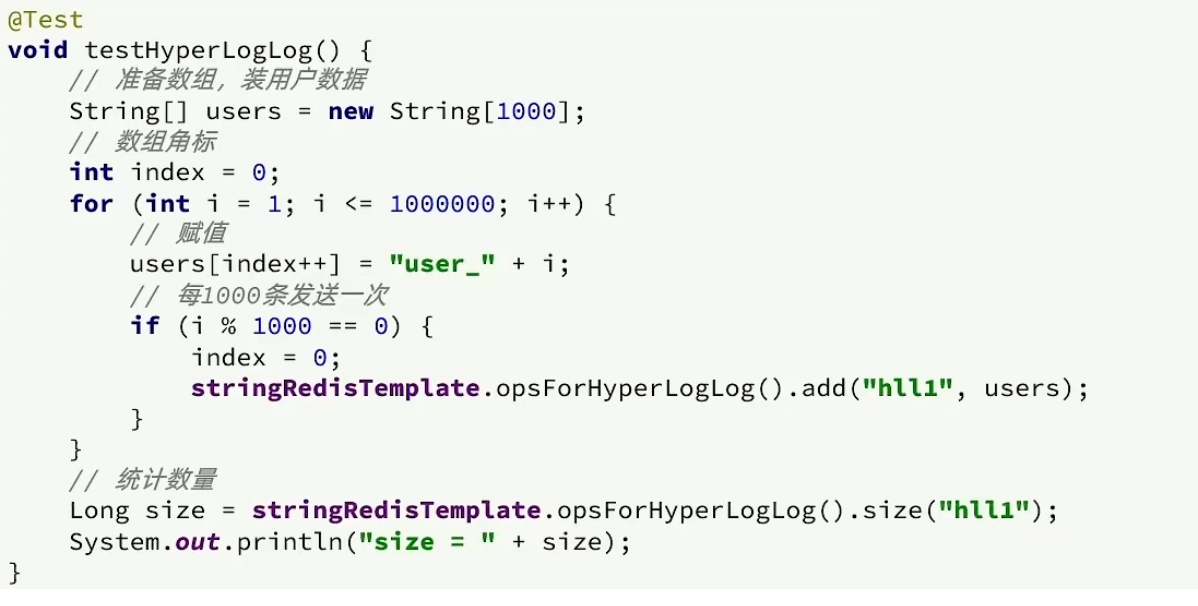
After testing: we will find that its error is within the allowable range and the memory usage is extremely small