This article is compiled from the 81st issue of Meituan Technology Salon "Meituan's Exploration and Practice in the Field of Advertising Algorithms" (Bilibili video). The article first introduces Meituan's information flow advertising business and the current status of estimation technology, and then focuses on sharing the specific practice of information flow advertising estimation in Meituan, focusing on multiple dimensions such as decision paths, ultra-long and ultra-wide modeling, and full restoration modeling. Finally, there are some summaries and prospects, which I hope will be helpful or inspiring to everyone.

1 Current Status of Information Stream Advertising Business and Estimation Technology
1.1 Characteristics of Information Stream Advertising Business
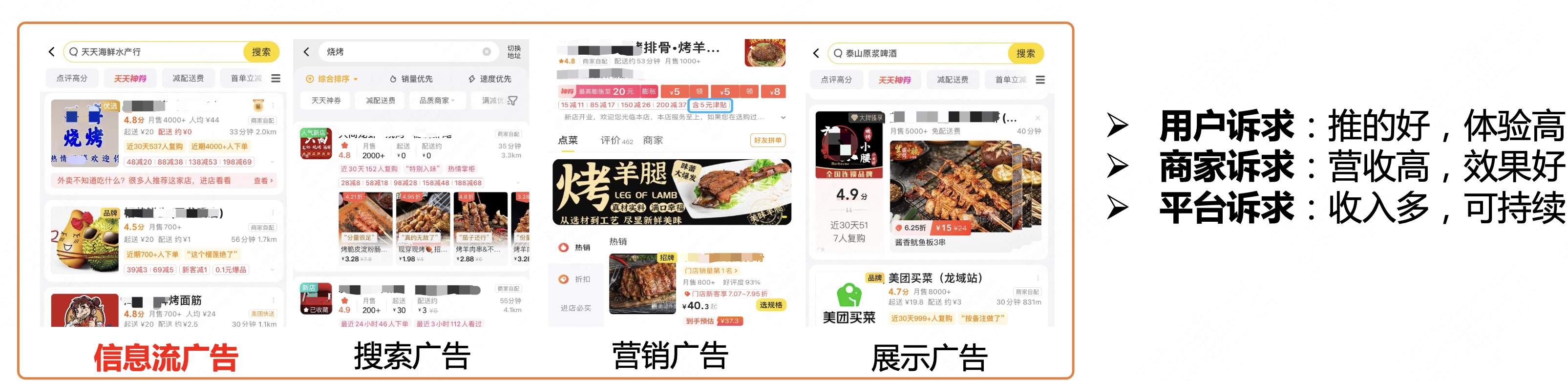
At present, Meituan Takeaway’s advertising mainly includes information flow advertising, search advertising, marketing advertising, display advertising, etc. The takeaway business has typical business characteristics:
- Strong consistency in user behavior : Users have clear dining intentions and generally complete their dining within 10 minutes, with a high UV conversion rate.
- Rich information displayed : Card information covers a variety of information such as ratings, reviews, discounts, and delivery, which has a strong impact on user decisions.
- Lots of text information : In e-commerce scenarios, products often play a large role as candidate images. In takeout scenarios, merchants are more complex candidates. Text information such as merchant names, reviews, and popular dishes can influence users' decisions.
1.2 Technology Overview and Evolution Stages
Here we will first introduce the current status of estimation technology. From a technical perspective, the following figure shows the overall process of the advertising delivery system:

In general, the food delivery advertising system is similar to our search and promotion system in the industry, including recall, rough ranking, fine ranking, and various mechanisms. However, the biggest difference between food delivery advertising and the industry is recall, because it is based on location-based services (LBS), and this process itself has certain constraints. Therefore, we will invest more computing power and resources in fine ranking and mechanism levels in order to maximize the improvement of the overall link.
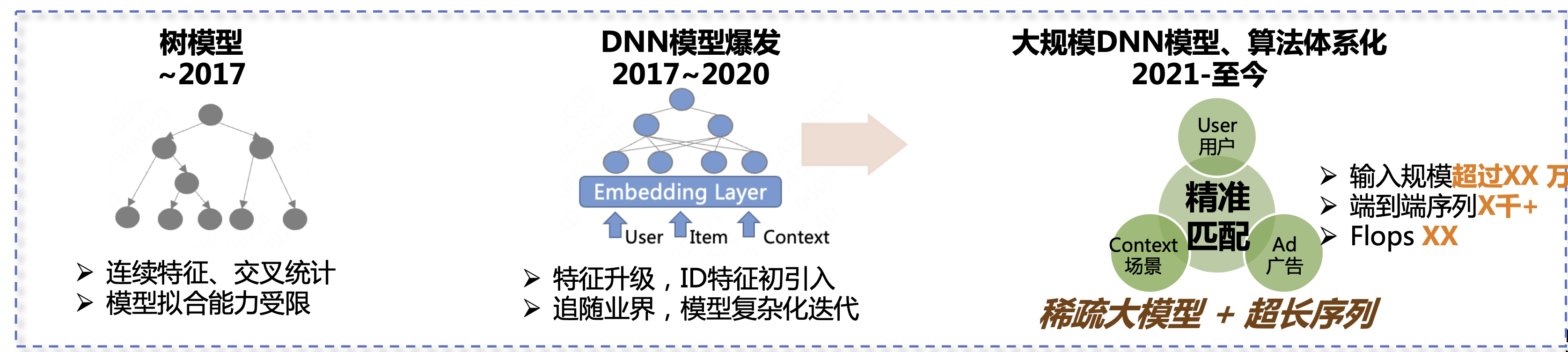
In the past six or seven years, the home advertising prediction algorithm has gone through three stages of development. The first stage was the tree model, including continuous features, cross statistics, etc. The model fitting ability was relatively limited at that time. The second stage was from 2017 to 2020. During this stage, the DNN model began to explode. We upgraded the features and began to follow the industry's pace, introducing more complex models to continuously improve business results. The third stage is from 2021 to the present. Our main direction is sparse large models + ultra-long sequences to further improve business results.
1.3 Estimation of the current state of technology
At the information flow advertising prediction technology level, the main exploration directions are user direction, link direction and NLP direction (as shown in the figure below). Of course, if this picture is more comprehensive, it will also include cross-direction, multi-scenario multi-target and so on. The reason why other directions were not chosen is mainly because in terms of cross-direction, we found that with the continuous development of the Internet industry, user behaviors will become more and more numerous and more complex, and the cross-direction can only bring Context-level deep learning capabilities, and it cannot continue to be the source of effect. On the other hand, although cross-technology is also developing, the development direction is also from ID matching to Sequence Matching, and the cross-model capabilities of simply tiling category features are limited. Taking into account many factors, we did not iterate cross-direction as a long-term direction.
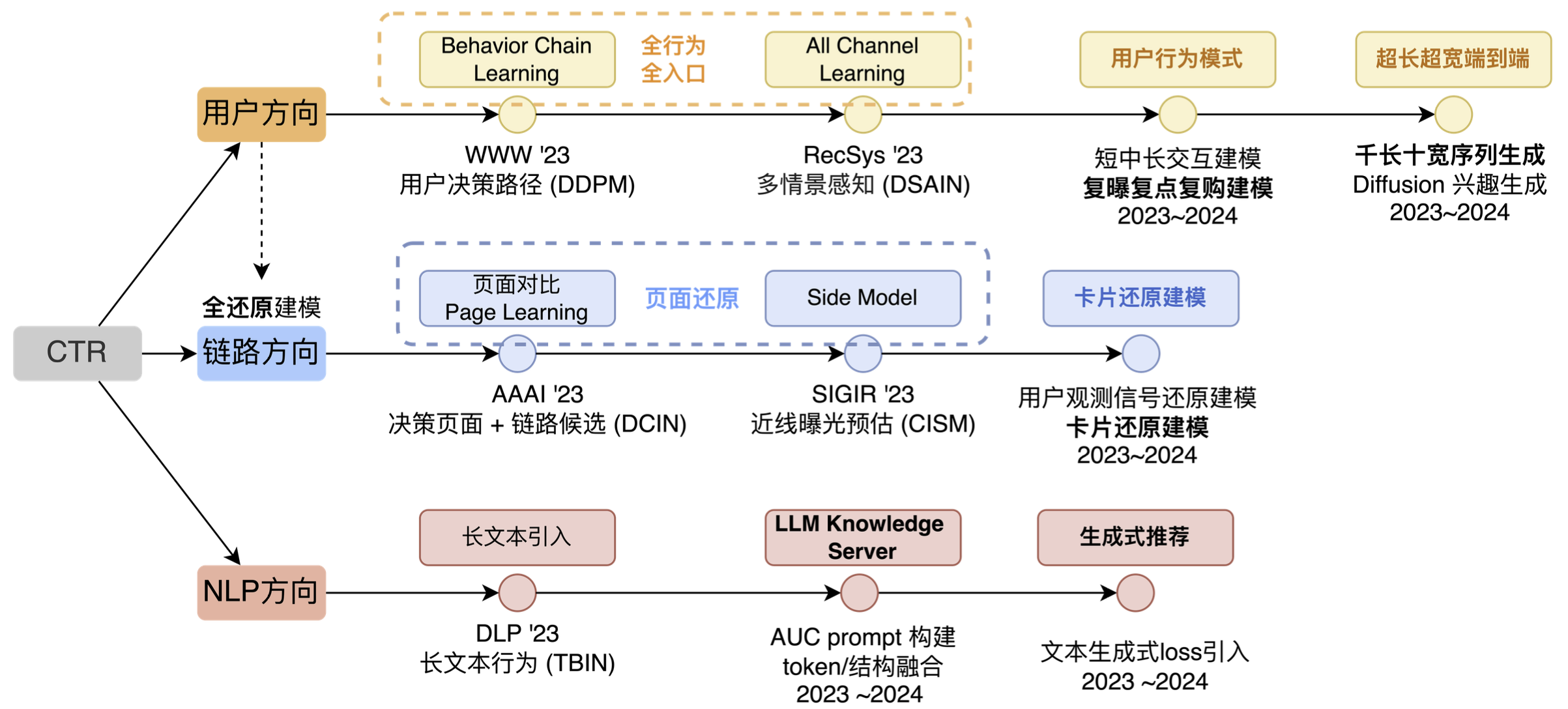
Another direction is multi-scenario. In fact, we have done some iterations in this direction before and brought a wave of results, but later we found that this technology is more suitable for linking multiple small scenarios. If the business you serve only has 1~2 relatively large scenarios, and the user demand differences, display forms, and candidate supply differences of these scenarios themselves are not very different, then the technical capabilities and functions of this direction cannot be fully utilized.
Our overall idea is to match users' elements, pages, paths, and interests in the long term. In essence, we are doing work related to user matching at different levels. Among them, element matching and page matching belong to the link direction. The reason is that the link direction is more about solving "invisible problems" and then using this "seen" information to do corresponding modeling, so we list the link direction separately.
- In terms of users, we have roughly gone through three stages. In the first stage, we expanded from the original single-point, single-entry behavior to full behavior and full entry; the second stage was to explore more behavioral patterns based on existing inputs; in the third stage, we mainly did some automated pattern extraction, or made the network's ability to automatically fit behaviors stronger.
- In the link direction, we focus on two things: page restoration and card restoration. We use algorithms and engineering capabilities to restore what users "see" into model decisions.
- In the field of NLP, we used to have a direction called multimodality, but objectively speaking, with the popularity of LLM, external technologies have also given us more input, so we have listed LLM IN CTR separately as a major technical direction.
2. The Practice of Information Stream Advertising in Meituan
2.1 Overview of User Modeling Ideas
The overall user direction is broken down into three reverse directions. The first is the timeline, the second is the space line, and the third is the behavior pattern under the combined effect of time and space. When we were breaking down, we also referred to the main iterative methods of the industry and academia, including Session modeling, ultra-long behavior modeling, multi-behavior modeling, and long-term and short-term modeling. Based on academia and industry, combined with business problems and characteristics, we better combined technology and business, and came up with the following technical breakdown.
在时间线上,我们认为长短期的多Level融合更加重要。一方面是用户兴趣在不同级别"片段" 上关注点有显著差异,比如页面倾向比较、路径上的兴趣更连续、用户会连续吃一段时间轻食等,我们需要将这种在不同级别片段上的用户行为模式提取出来。因此,一方面我们通过更多页面和路径的方式将短期和长期进行联合;同时,我们通过增加日、周级别的中期兴趣,将短中、短长进行交互,增强时间线行为上的连接。另一方面,在模型上增加一些端到端的方式,自动化的将行为规律挖掘出来。这是时间线要解决的关键问题。
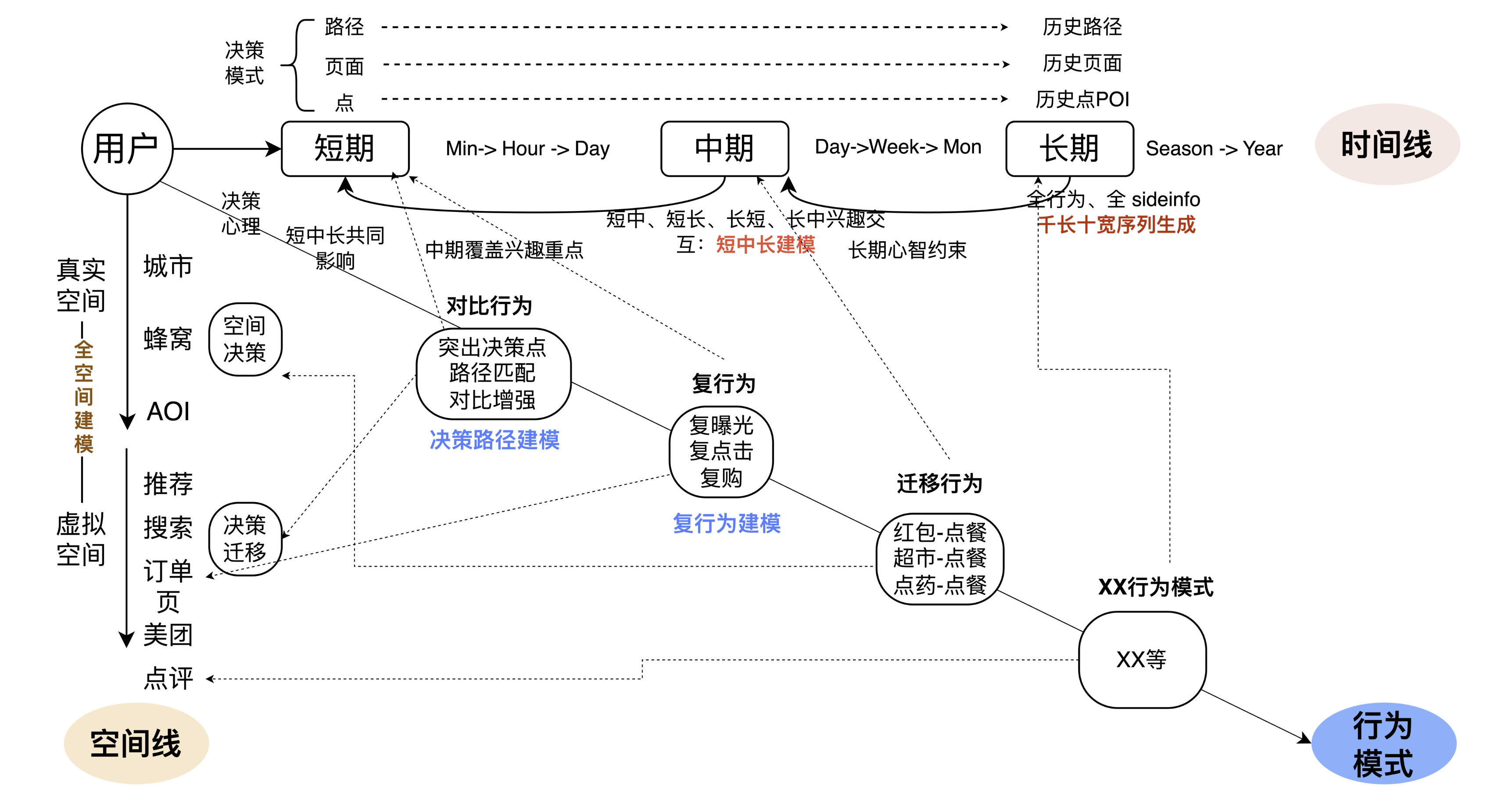
在空间线上,真实物理空间维度下,我们面对的问题比较明确,在不同的位置下,比如上班的时候和在家的时候,人的兴趣其实是不完全一样的,我们根据空间的位置为大家进行推荐。在虚拟空间下,比如用户在使用美团App和大众点评App等不同入口,人的兴趣和意图也会发生较大变化。一个显著的例子是,用户在首页和会员入口上对优惠的关注区别较大。空间线解决的问题是结合真实空间、虚拟空间,去判断用户的真实的意图或者行为模式。
The third line is to integrate with the business. For example, if a user performs some operations on the App (receives a red envelope), what impact will this behavior have on ordering food? In essence, the model understands the impact of the user's operations on the subsequent behavior, and then the model can learn different user behavior patterns and better predict user behavior. The above is our overall idea of user modeling.
2.1.1 Decision Path Modeling
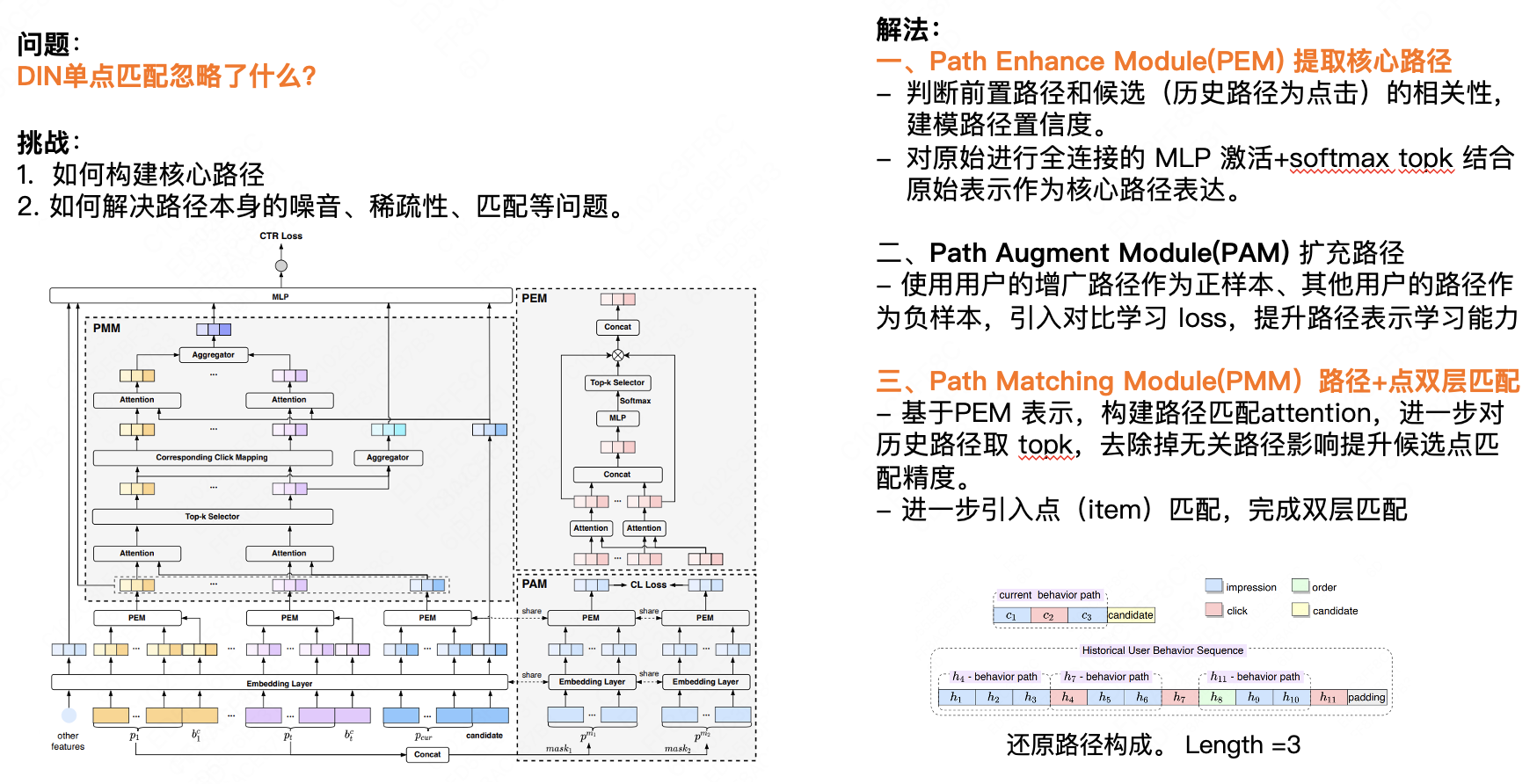
This section will introduce decision path modeling. The first core question is, what does DIN single-point matching ignore? We believe that single-point matching ignores the impact of previous behavior on the user's subsequent behavior. For most e-commerce businesses, the user's behavior over a period of time is somewhat consistent. We can predict the next behavior based on the user's historical behavior data. There are two challenges here. First, how to build the core path; second, how to solve the noise, sparsity, matching and other problems of the path itself. Our solution has three main points:
First, the Path Enhance Module (PEM) extracts the core path.
- Determine the correlation between the previous path and the candidate (historical path is click) and model the path confidence.
- The original fully connected MLP activation + Softmax Top K is combined with the original representation as the core path expression.
Second, Path Augment Module (PAM) expands the path.
- The user's augmented path is used as the positive sample and other users' paths as the negative sample. Contrastive learning loss is introduced to improve the path representation learning ability.
Third, Path Matching Module (PMM) path + point double-layer matching.
- Based on the PEM representation, we construct a path matching Attention, and further extract the Top K of historical paths to remove the influence of irrelevant paths and improve the matching accuracy of candidate points.
- Further introduce point (item) matching to complete double-layer matching.
2.1.2 User Behavior Ultra-Length and Ultra-Width Modeling
I believe many students know that ultra-long modeling is basically achieved through approximate technologies such as clustering and local hashing. The introduction of ultra-wide modeling is essentially because we need to put all the inputs together, so we need a larger and more complex model to handle things. However, in practice we have not fully implemented it because the current computing power is still unable to support it. We made a compromise, the length is at the level of 1000 (Length), and the width is currently at the level of 10+. Offline support can reach a larger scale, and the effect of reaching the level of 10,000 is also greatly improved, but the iteration efficiency and online pressure will be greatly limited.
There are also two problems here: The first question is why SIM/ETA has no effect? This direction was first proposed by e-commerce platforms. SIM is mainly hard filtering. For example, when users browse shoe-related behaviors on the website, they will also look at various other things. It can filter out products related to "shoes" through hard filtering, filter out noise unrelated to shoes, and learn users' preferences for shoes. Ordering takeout is relatively different. For a candidate hamburger, filtering out behaviors unrelated to hamburgers through hamburger categories will lose more user taste information. This is caused by business differences.
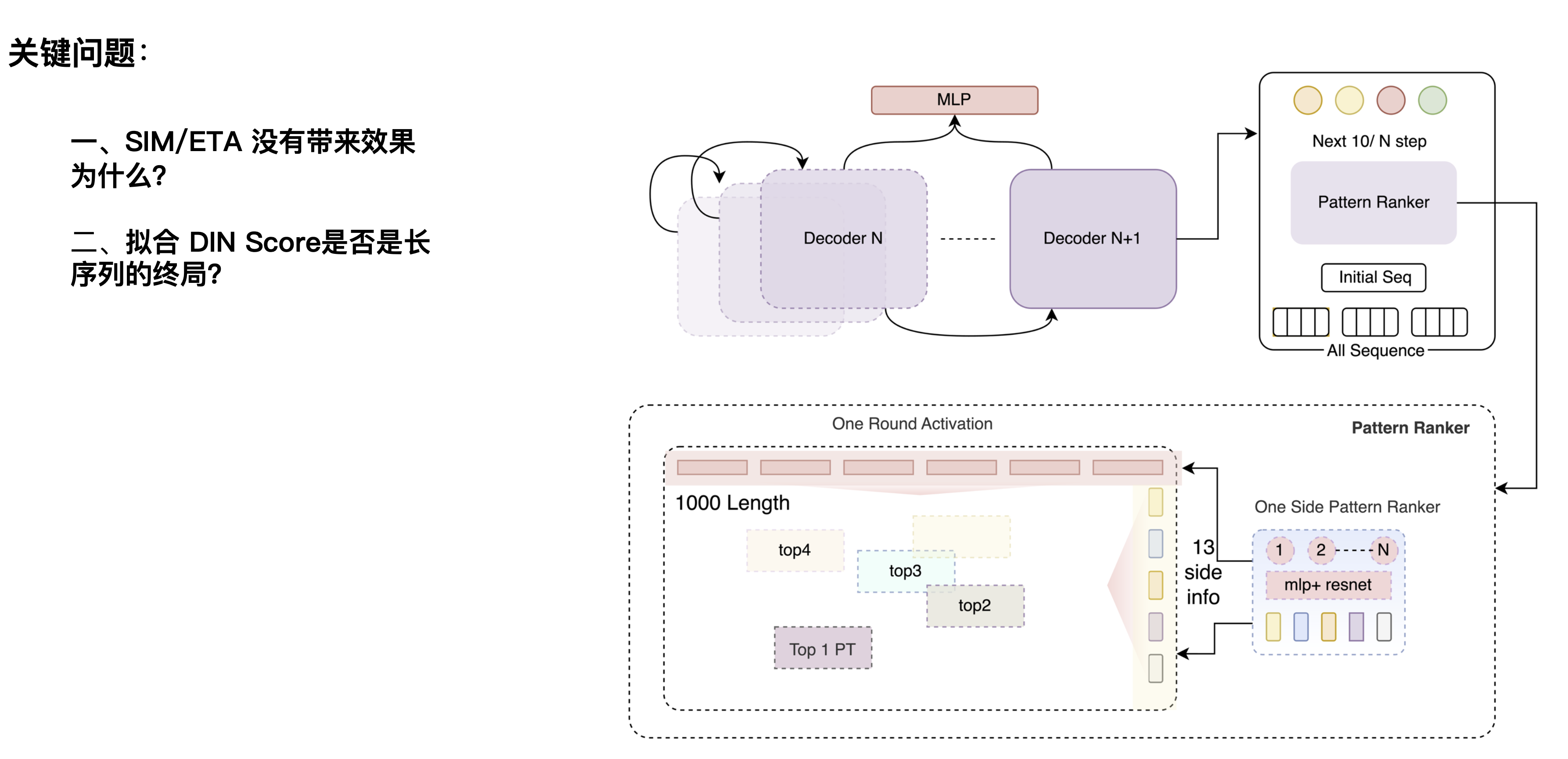
The second question is, is fitting the DIN Score the end game for long sequences? Previously, an article in the industry believed that the DIN Score is a benchmark, and that linear expansion of it can bring results, and further expansion to the level of 10,000 or 100,000 can maximize the effect. However, through experiments, the linear expansion of our CTR scenario to the ultra-long level did not bring sustained results, but instead decreased after a certain length. We believe that the DIN network's own denoising ability is not very strong, or that its structural ability to extract the Label result is not strong enough. If it is not a particularly strong network, when it is expanded to a larger level, the information it can accommodate is relatively limited.
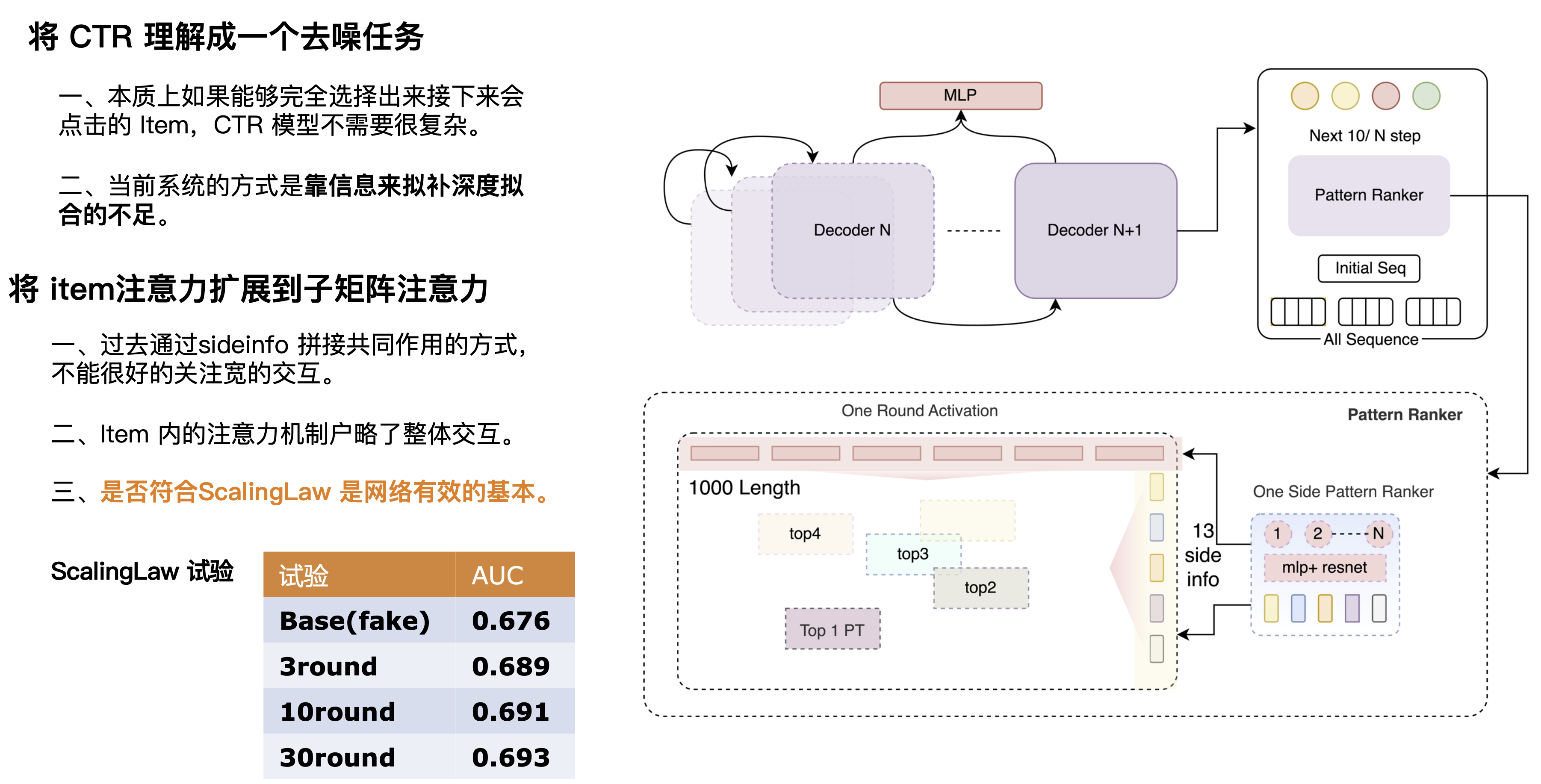
We can understand CTR as a denoising task, which is essentially the process of matching users and candidates based on user history and current scenarios. We found that if we can accurately predict or remove all noise, such as matching the crossing information Label POI with the Target, a simple network can also have a high AUC. Therefore, we believe that the perfect CTR network should be a combination of a strong prediction network + a weak matching network. The prediction network should be a very powerful network that can perform multi-layer superposition and extract information to obtain a more accurate prediction result to match the Target. So we designed a multi-layer decoder, and each layer of the decoder can integrate information. By continuously selecting effective matrices and repeatedly superimposing effective information, the information can be made more accurate. Here we did a set of Scaling Law experiments to verify the effectiveness of the results by superimposing multiple rounds of networks. It can be seen that as the number of rounds increases, the network's ability to learn user behavior (AUC increases layer by layer) also increases.
2.2 Full restoration modeling
First of all, what is full restoration modeling? One definition we give is to restore what users see and get. The CTR task is to determine whether the user clicks based on the information the user sees. The most important point is to include all the information seen into the model. In the past, simple modeling through ID representation ignored the context and displayed information, resulting in a large information GAP.
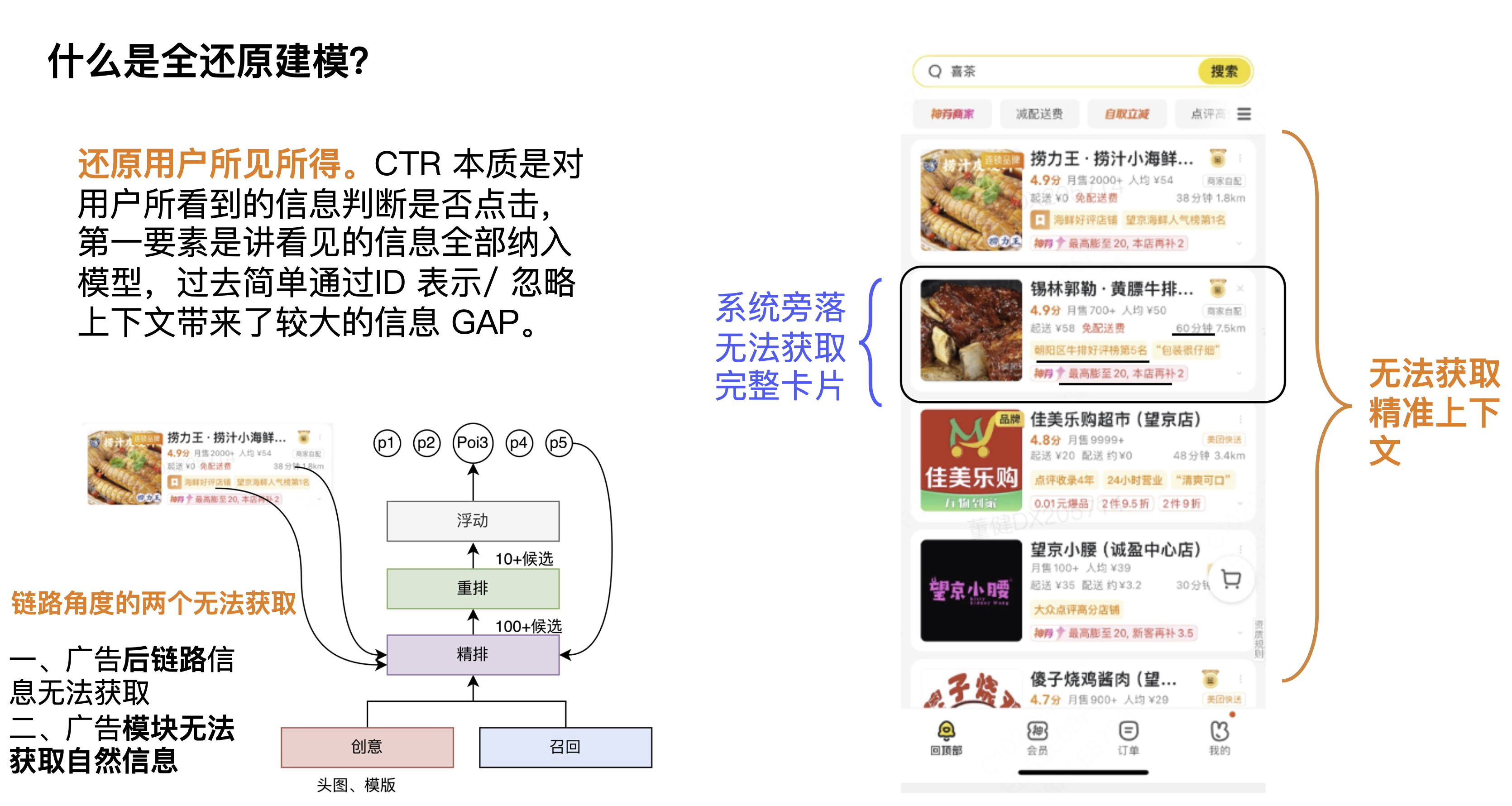
From the first perspective, context cards cannot be obtained. Context information is very important for the CTR of the current candidate and the current card. Some students may think that re-ranking can solve this problem, but we always believe that context information belongs to link information. We believe that each module needs to learn context information. Of course, each module may have different learning focuses, and in fact, they can all bring certain effects. From the second perspective, from the perspective of computing power, because the computing power on the estimation side is relatively high, the scope of its influence will be larger, and it can actually bring more effect space.
Looking at the figure in the lower left corner, from the perspective of the link, there are two things that cannot be obtained for the estimation module and the advertising module. The first is that the post-link information of the advertisement cannot be obtained, which includes the displayed delivery information, delivery fees, accurate discount information, etc. The second is that the natural information cannot be obtained, which includes the natural context. Therefore, from another perspective, restoration is about how to break the constraints of the link to use the traversal information.
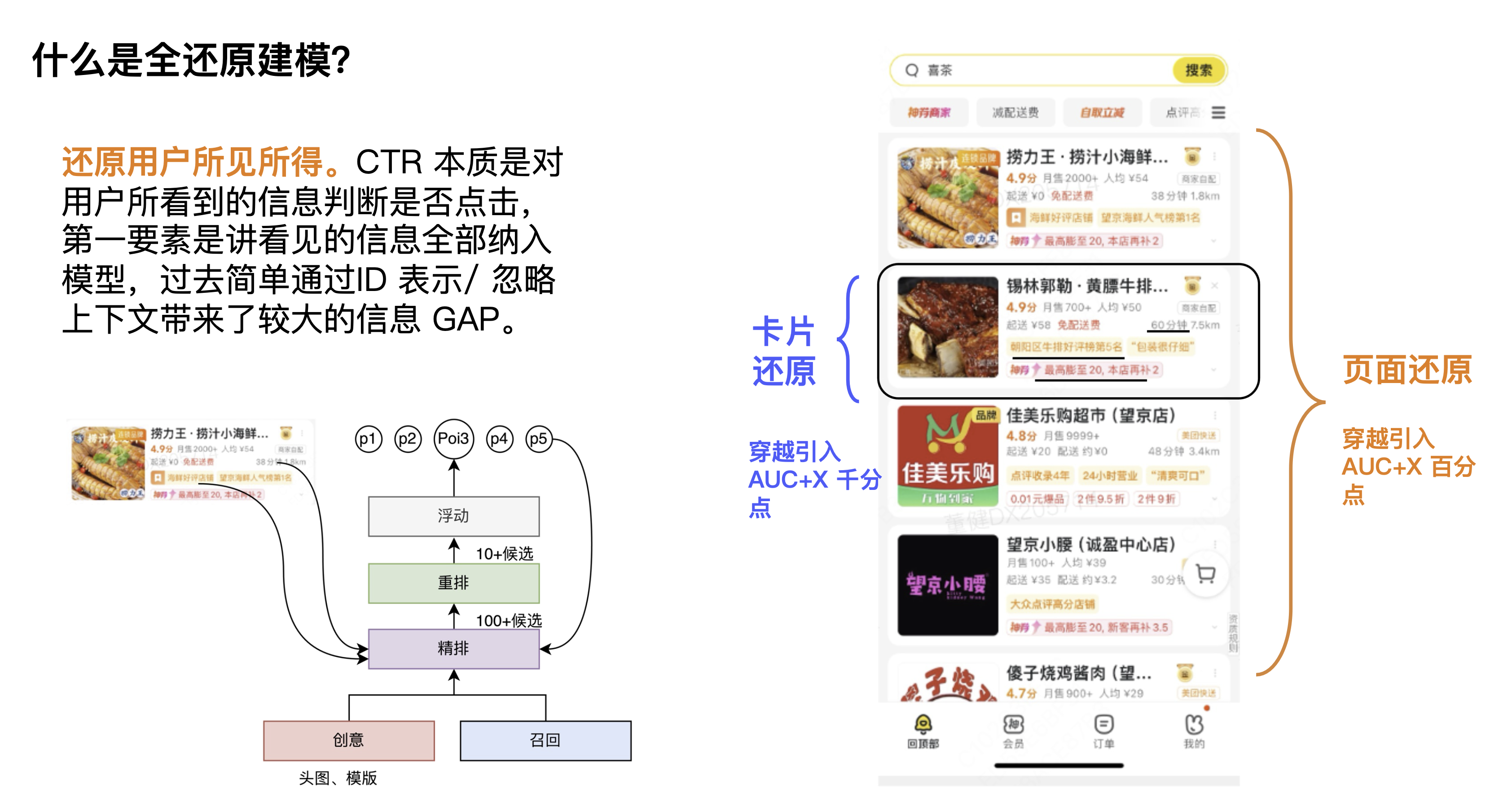
These are some of the problems faced by full restoration modeling, which can actually be summarized into two directions: card restoration and page restoration. In the early days, we made a spatial judgment. We put the card and page information in full and observed the improvement in AUC to judge the overall space. The results showed that the page information was at the percentage level and the card information was several thousandths.
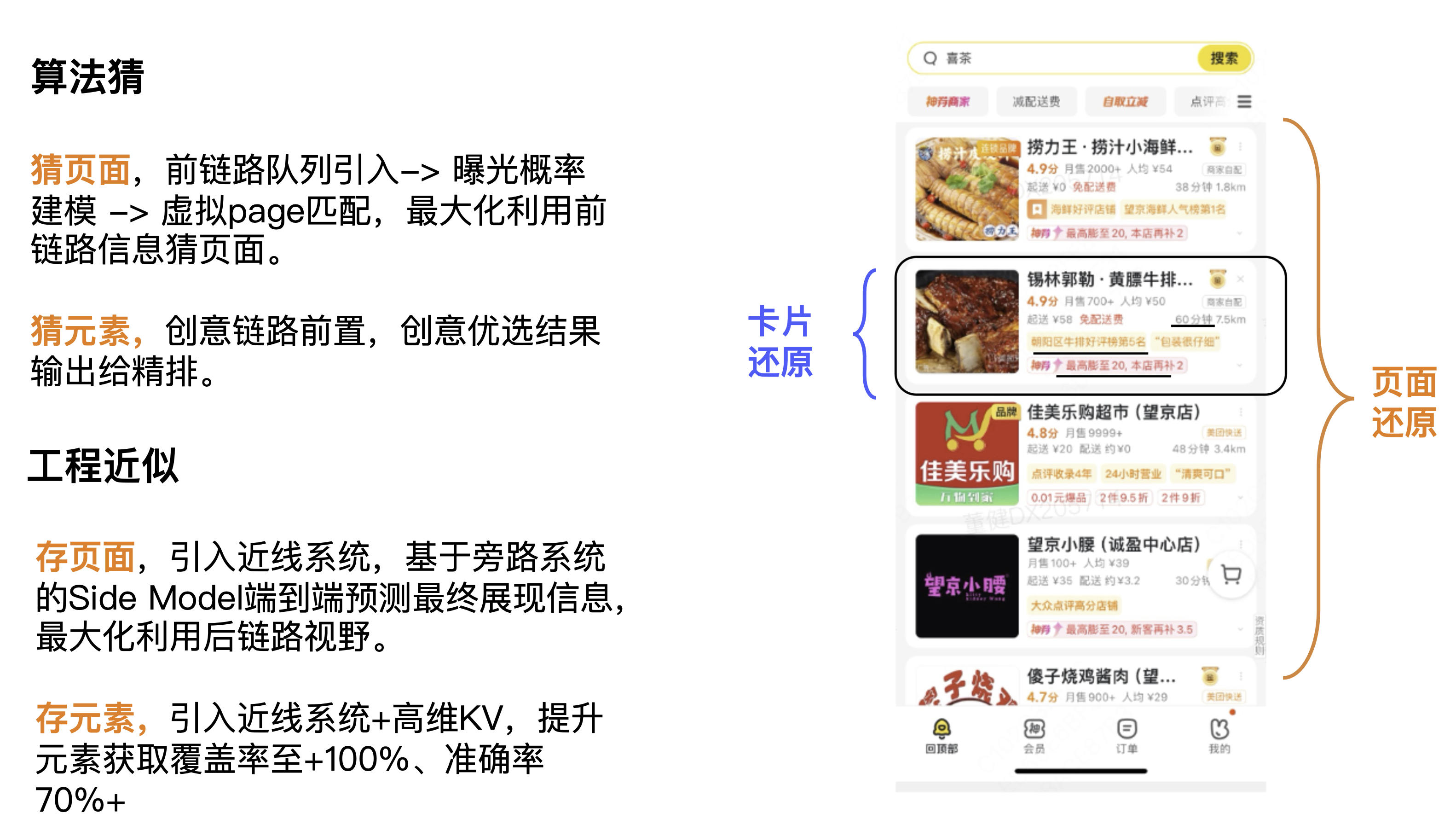
Overall solution
Here we expand on page restoration and card restoration. First of all, from a conceptual point of view, we mainly solve it from two dimensions: algorithm and engineering. At the algorithm level, the first is to guess the page, maximizing the use of the front-link information to guess the page; the second is to guess the element, with the creative link in front, and the creative optimization results output to the fine ranking. At the engineering level, the first is to store the page, introduce a near-line system, and use the Side Model of the bypass system to predict the final display information end-to-end, maximizing the use of the back-link vision. The second is to store elements, introducing a near-line system + high-dimensional KV to increase the element acquisition coverage to +100% and the accuracy to 70%+.
As mentioned above, context information has a great impact on the final click. Since the CTR module cannot obtain the context, the solution in the past was to introduce rearrangement to model a small range of queues, which reduces the impact of context link information. Next, we face the following challenges:
- The context includes two parts: set and sequence. How to build a context prediction module?
- How do Simulated contexts interact with candidates?
- How to further improve the accuracy of Simulated Page through distillation?
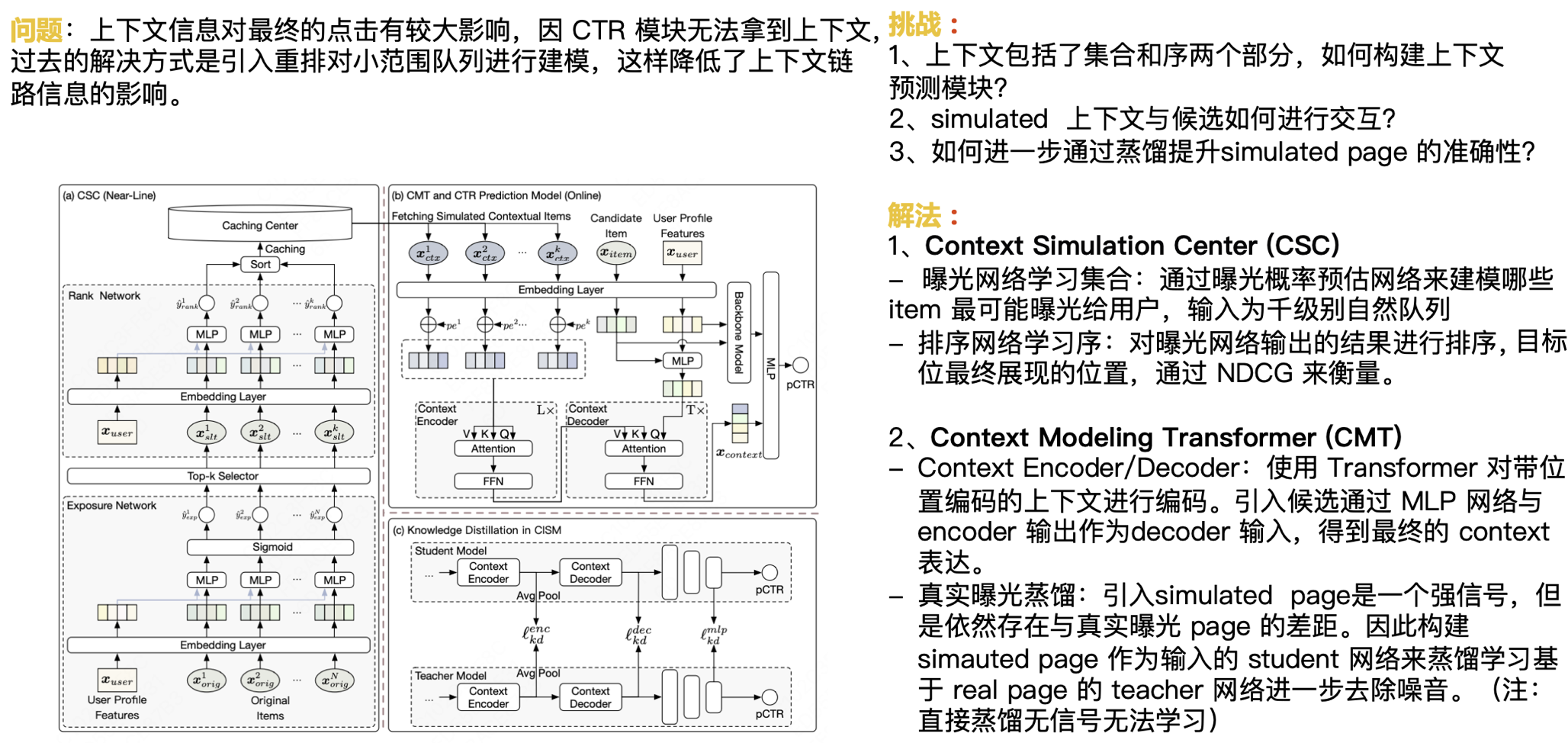
Our solution is:
Context Simulation Center(CSC)
- Exposure network learning set: Use the exposure probability estimation network to model which items are most likely to be exposed to users, with the input being a natural queue of thousands.
- Sorting network learning sequence: Sort the results of the exposure network output, and the final display position of the target position is measured by NDCG.
Context Modeling Transformer (CMT)
- Context Encoder/Decoder: Use Transformer to encode the context with position encoding. Introduce candidates through the MLP network and the Encoder output as the Decoder input to obtain the final Context expression.
- Real exposure distillation: The introduction of simulated page is a strong signal, but there is still a gap with the real exposure page. Therefore, the Student network with simulated page as input is constructed to distill and learn the Teacher network based on real page to further remove noise. (Note: direct distillation cannot learn without signal)
We introduced caching and prediction configuration strategies, combined with real distillation, to help us further improve the results, which belongs to the page restoration part.
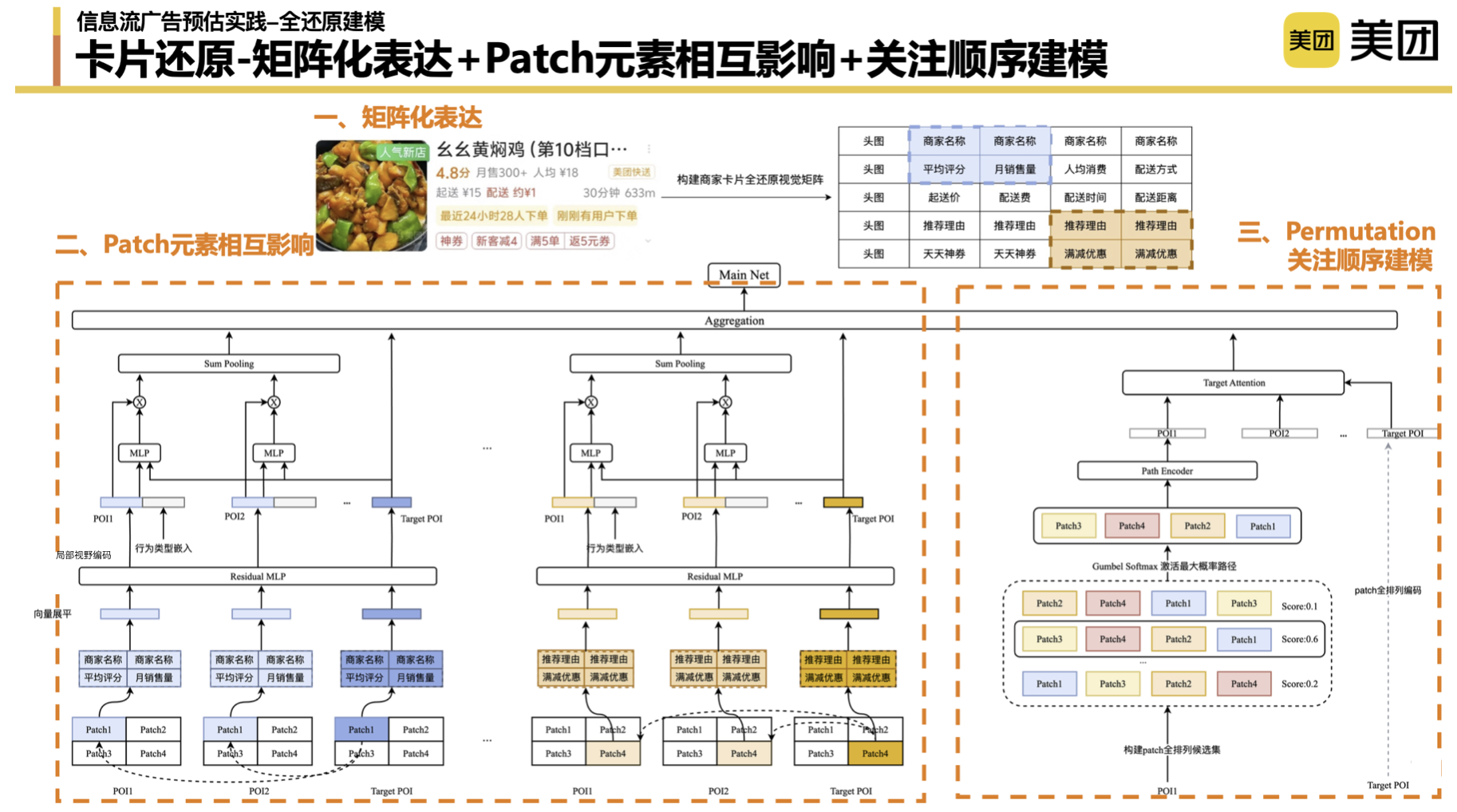
The overall idea of card restoration is divided into three parts: the first part is to get the card information; the second part is to compose the cards that users see; the third part is to match historical interests through cards.
Thinking about the card solution : Due to the serial and parallel nature of the modules in the search and promotion system, we cannot obtain some data. In the early stage, we have been thinking about whether there is an "ultimate solution". In the early stage, we used a pure tiling (pure ID) method to restore the information seen by users, but is there a better way? For example, directly introduce the pictures that users see. However, the current technical capabilities do not support the complete recording of the entire picture, let alone the complete and accurate modeling expression of the picture information. In the end, we chose to form cards through a matrix to simulate the information seen by users.
Matrix expression, patch-level modeling : First, we used matrix expression to form the shape of the card and build the upper and lower element relationship that the user sees. At the representation level, different matrix construction methods will have a certain impact on the results, which will not be expanded here. Secondly, we also borrowed some ideas from the image field and introduced the concept of patch to help us turn images into tokens to further learn the mutual influence between different display elements. In the process of practice, we also need to adjust some parameters, such as whether the patch is 2*2 or 3*3. Including stride, we found that the shorter the stride setting, the better the effect. We also did many experiments in the entire patch-level matching process. The preliminary conclusion is that the matching of single-position patches and global patches has a better final effect.
Attention order modeling : Sequence modeling is to further simulate the user's browsing order based on which elements the user pays attention to. In theory, we cannot get this part of data without eye monitoring. Here, we did a little trick to fully arrange the matrix of these four patches, list all the patch-level paths of the user, and let the model learn the implicit scores of different arrangements and combinations. The patch sequence combination with the highest activation score is aggregated into an attention order expression through the Encoder to further match it with the attention order combination of the Target's POI.
2.3 LLM in CTR
Finally, let me share the application of large models in CTR. We did some preliminary research and found that the overall ideas of many technical teams are similar. The figure below shows the comparison between CTR tasks and NLP tasks. You can see that there are big differences from input to model architecture, to learning mode and task mode. NLP tasks are natural language tokenization + large-scale Transformer + understanding and reasoning capabilities, while CTR tasks are ID input + manually designed network + strong memory capabilities. At the same time, for CTR, most businesses only use their own business data and lack external knowledge and the ability to understand the entire task.
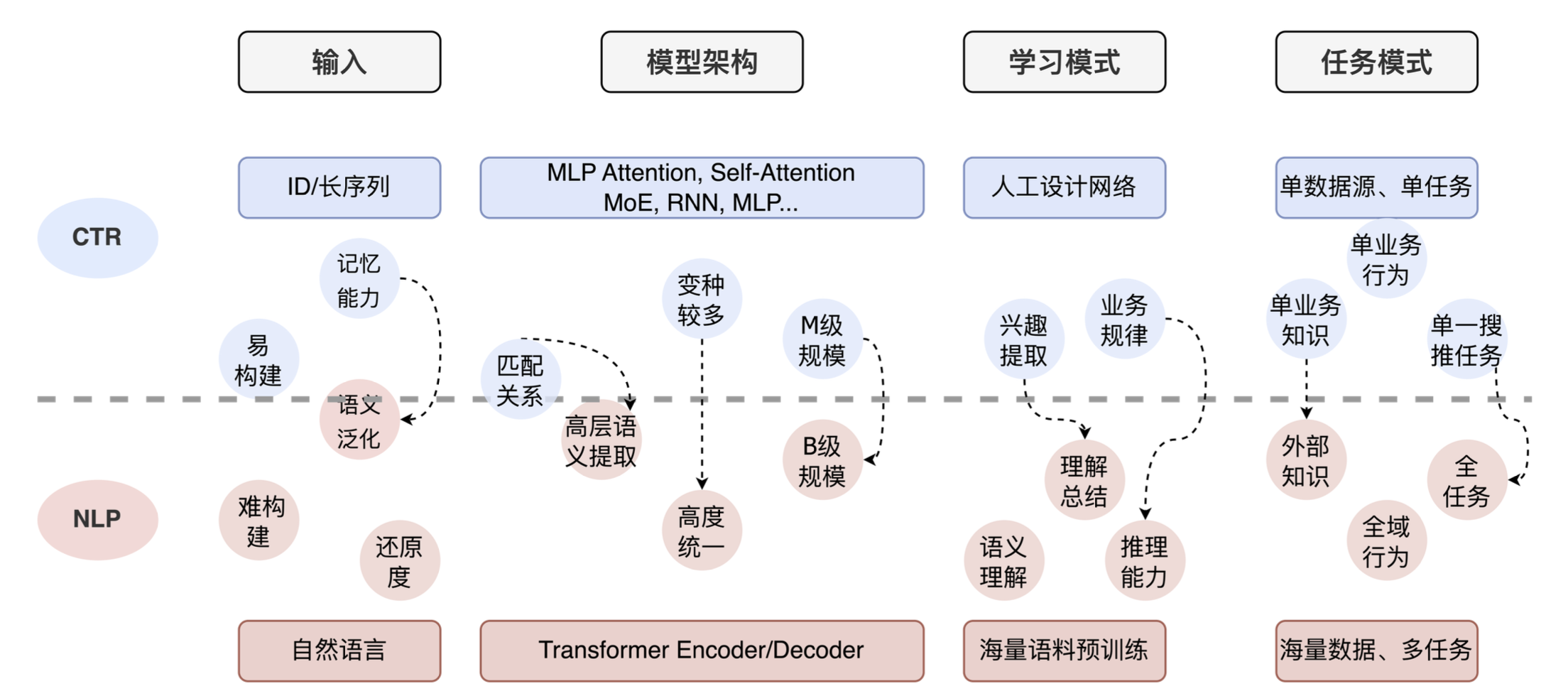
So based on the above aspects, we have done three aspects of work:
- The first layer, knowledge injection, is to put external, real, and current CTR-deficient knowledge into the model. Many companies are doing this part of the work, which mainly requires prompt engineering capabilities. Because the generated results may not be what CTR needs, we need to do a good job of adaptation. According to the characteristics of CTR, high-frequency words and low-frequency words can be distinguished. At the same time, some post-processing work related to prompt fusion is also needed to improve the matching degree with CTR tasks.
- The second level, thinking injection, is to introduce the structural capabilities of the big model, or to introduce the judgment process of the big model.
- The third layer is paradigm iteration. Recently, Meta seems to have pointed out a way for generative recommendations. When we were exploring this direction last year, the main idea was to change the form of the input and replace it with a smaller-scale token, probably only tens of thousands in size, to solve the large-scale Softmax problem. Then, through the Transform superposition method, combined with aggregation semantics, from model fusion to end-to-end autoregression, the data can be run through. We found that if the input is particularly noisy, the Transformer cannot handle it well, but for a relatively semantically clear information, the Transformer's performance in understanding the context is not bad, so we first did a layer of semantic aggregation to reduce the noise of the input Token sequence. In general, we have brought a wave of improvements to business results through small-scale tokens, semantic aggregation, and the Transformer architecture.
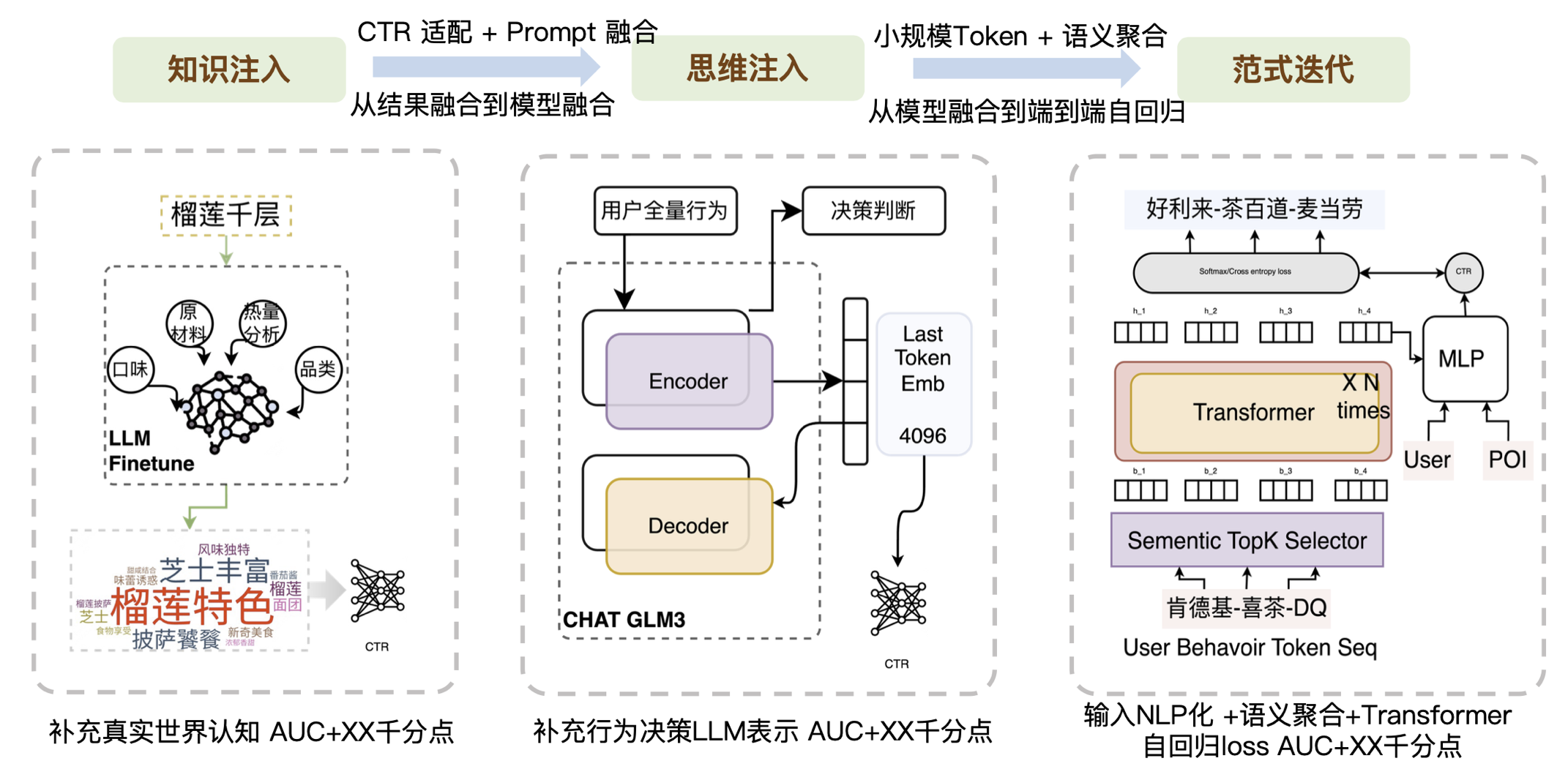
To sum up, the essence is to make up for the capabilities that CTR does not have through a large model. We divide the capabilities that CTR currently does not have into knowledge capabilities, generalization capabilities, and reasoning capabilities. Correspondingly, we also list some of the results of our attempts as shown in the following figure:

03 Summary and Outlook
In general, the essence of prediction is to discover the real needs of users. On the one hand, we refer to the industry, and on the other hand, we go deep into the business to explore more user behavior patterns. We are also exploring whether there are more automated ways to solve various user problems. Restoration modeling is an improvement brought about by the joint efforts of algorithms and engineering. Ultimately, the combination of algorithms and engineering can bring greater changes.
The combination of big models and recommendations is gaining more and more attention, but objectively speaking, this is still a long-term task. At this time, we still need to find a feasible path and continuously optimize and improve it. If we completely rely on a "big trick" to solve all problems, it will be very difficult. End-to-end recommendation big models are everyone's common expectation, but on this basis, we believe that input scale is the guarantee of effect, and computing power is the guarantee of the above two. Only the strong combination of software and hardware can win the future.
| Reply to keywords such as [2023 New Year's Goods], [2022 New Year's Goods], [2021 New Year's Goods], [2020 New Year's Goods], [2019 New Year's Goods], [2018 New Year's Goods], and [2017 New Year's Goods] in the menu bar dialog box of the Meituan official account to view the collection of technical articles of the Meituan technical team over the years.

| This article is produced by Meituan's technical team and the copyright belongs to Meituan. You are welcome to reprint or use the content of this article for non-commercial purposes such as sharing and communication. Please indicate "Content reprinted from Meituan's technical team" . This article may not be reproduced or used commercially without permission. For any commercial behavior, please send an email to [email protected] to apply for authorization.
The situation is getting more and more inward-looking. The daily and weekly reports of every detail are too difficult for IT workers! How to break the deadlock? AMD open-sources the first small language model AMD-135M. It's National Day, and I'm back to my hometown in Anhui, but how can I access the network of the Hangzhou company? The Hongmeng native version of "Honor of Kings" starts a limited deletion test. The Shanghai Stock Exchange tested the bidding trading system today and received 270 million orders: the overall performance is normal, which is twice the historical peak. Apple may launch its first smart display and supporting operating system homeOS in 2025. FFmpeg 7.1 "Péter" is released. Zhipu AI announced that all models will be available at a minimum of 10% off. Open Source Daily | Rust has significantly reduced Android vulnerabilities; OpenAI plans to increase the subscription fee for ChatGPT; AI companies make money much faster than SaaS companies; there is no eternal king in the IT industry; who is in control of OpenAI now? Redis 7.4.1 is released