Optimizer Optimizer for comparison pytorch1.0
Import Torch Import torch.utils.data the Data AS # provided Torch of one tool to help organize the data structure, called DataLoader, use it to package their data, batch training. Import torch.nn.functional AS F # included excitation function Import matplotlib.pyplot AS PLT the LR = 0.01 # learning rate BATCH_SIZE = 32 the EPOCH = 12 is # dummy data # Fake DataSet X = torch.unsqueeze (torch.linspace (-1,. 1, 1000), Dim =. 1 ) Y = x.pow (2) + 0.1 * torch.normal (torch.zeros (* x.size ())) # Plot DataSet plt.scatter (x.numpy (), y.numpy ()) plt.show () # DataLoader packaging developer tools used to torch their own data. # Own (numpy array or other) data format loaded into Tensor, and then put the wrapper. # Use DataLoader advantage is that they help you to effectively iteratively data # first converted into the torch can identify a Dataset # pUT iNTO dateset torch dataset torch_dataset = Data.TensorDataset (X, Y) # the dataset into DataLoader Loader = Data.DataLoader (= torch_dataset dataset, the batch_size = BATCH_SIZE, shuffle = true, num_workers = 2,) # random data disrupted (disruption better) # each optimizer optimizing a neural network # default network in the form of # default network class net (torch.nn.Module): DEF the __init__ (Self) : Super (Net, Self).the __init__ () self.hidden = torch.nn.Linear (. 1, 20 is) # hidden Layer self.predict = torch.nn.Linear (20 is,. 1) # Output Layer DEF Forward (Self, X): X = F.relu (self.hidden (X)) # Activation function for hidden Layer X = self.predict (X) # Linear Output return X # create different optimizer, which are used to train the network. loss_func used to calculate and create an error. IF the __name__ == ' __main__ ' : # Different Nets net_SGD = Net () net_Momentum = Net() net_RMSprop = Net() net_Adam = Net() nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam] # different optimizers opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR) opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8) opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9) opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99)) optimizers =[opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam] loss_func = torch.nn.MSELoss () losses_his = [[], [], [], []] # Record Loss # training / showing # Training for Epoch in Range (the EPOCH) : Print ( ' Epoch: ' , Epoch) for the STEP, (B_X, b_y) in the enumerate (Loader): # for the each Training the STEP # belonged to his neural network for each optimizer, optimize for nET, opt, l_his in ZIP (Nets, optimizers, losses_his): the Output= net(b_x) # get output for every net loss = loss_func(output, b_y) # compute loss for every net opt.zero_grad() # clear gradients for next train loss.backward() # backpropagation, compute gradients opt.step() # apply gradients l_his.append(loss.data.numpy()) # loss recoder labels = ['SGD', 'Momentum', 'RMSprop', 'Adam'] for i, l_his in enumerate(losses_his): plt.plot(l_his, label=labels[i]) plt.legend(loc='best') plt.xlabel('Steps') plt.ylabel('Loss') plt.ylim((0, 0.2)) plt.show()
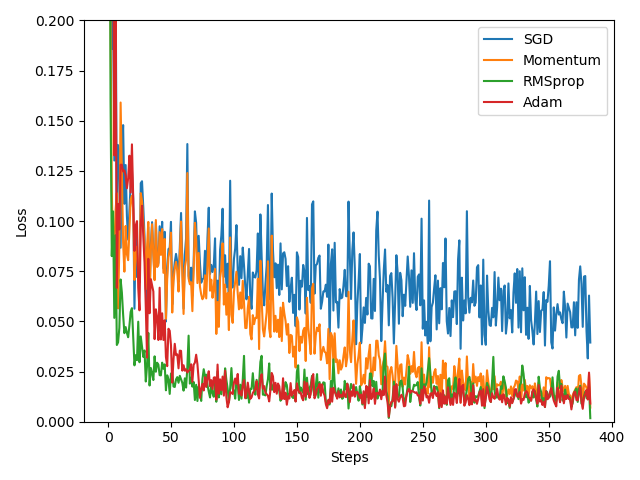
# SGD is the most common optimizer, it can be said there is no acceleration effect, while Momentum is SGD improved version, which adds momentum principle behind RMSprop is Momentum upgraded version.
# While Adam is RMSprop upgrade. Adam effect seems to be almost over RMSprop. so not the more advanced optimizer, the better the results.
# in their experiments you can try different optimizer, the optimizer to find the most suitable for your data network.