See distributed, highly concurrent, multithreaded three words, a lot of people think that is not distributed = = high concurrency multithreading?
When the interviewer asks to highly concurrent system which means can be employed to solve, or asked how distributed systems to solve the consistency problem is not forced to look ignorant?
Indeed, at the beginning of the contact, many people will be distributed, high concurrency, multithreading will confuse the three, mistaking the so-called distributed highly concurrent systems that can simultaneously access for mass users, while the use of multi-threading means not It is that we can provide concurrent capacity systems? In fact, three of them are always attendant, but there are different emphasis.
Then I look in the end what is the difference between a distributed, highly concurrent, multithreaded these three?
What is distributed?
A more distributed concept In order to solve is to optimize a single physical server capacity and performance bottlenecks is employed. The problem areas need to be addressed very much in the different technical aspects, but also include: distributed file system, distributed cache, distributed databases, distributed computing, some terms such as Hadoop, zookeeper, MQ and other related distributed related. Conceptually, a distributed implementation in two forms:
horizontal expansion: When a machine could not carry traffic on the way by adding machine, will split the traffic to all servers, all machines can provide comparable services ;
vertical split: the front end of the demand has a variety of inquiries, could not carry a machine, different requirements may be distributed to various machines, such as machines a ticket processing request query I, B machines for processing the payment request.
What is high concurrency?
Distributed relative terms, high concurrency in the problem-solving will focus on some of the reaction it is at the same time how a small amount: such as online video service, while thousands of people to watch.
High concurrency can be distributed to resolved through technology, concurrent traffic assigned to different physical servers. But beyond that, there are also many other optimization methods: for example, using the cache system, all the static content on CDN etc; you can also use multi-threading technology to maximize service capabilities of a server.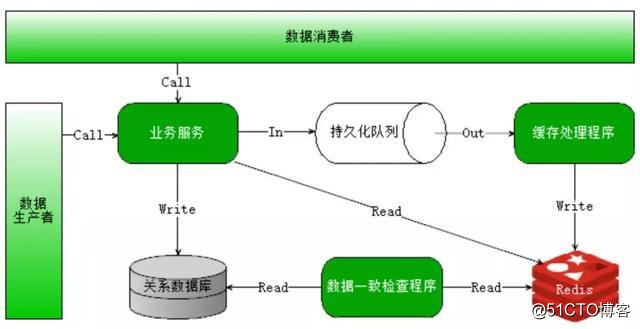
What is multi-threaded?
多线程是指从软件或者硬件上实现多个线程并发执行的技术,它更多的是解决CPU调度多个进程的问题,从而让这些进程看上去是同时执行(实际是交替运行的)。
这几个概念中,多线程解决的问题是最明确的,手段也是比较单一的,基本上遇到的最大问题就是线程安全。在JAVA语言中,需要对JVM内存模型、指令重排等深入了解,才能写出一份高质量的多线程代码。
总结一下:
分布式是从物理资源的角度去将不同的机器组成一个整体对外服务,技术范围非常广且难度非常大,有了这个基础,高并发、高吞吐等系统很容易构建;
高并发是从业务角度去描述系统的能力,实现高并发的手段可以采用分布式,也可以采用诸如缓存、CDN等,当然也包括多线程;
多线程则聚焦于如何使用编程语言将CPU调度能力最大化。
下面给大家分享一些面试官常问的分布式、高并发、多线程的面试题
1、分布式系统怎么做服务治理
针对互联网业务的特点,eg 突发的流量高峰、网络延时、机房故障等,重点针对大规模跨机房的海量服务进行运行态治理,保障线上服务的高SLA,满足用户的体验,常用的策略包括限流降级、服务嵌入迁出、服务动态路由和灰度发布等
2、对分布式事务的理解
本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
事务的ACID特性 原子性 一致性 隔离性 持久性
消息事务+最终一致性
CC提供了一个编程框架,将整个业务逻辑分为三块:Try、Confirm和Cancel三个操作。以在线下单为例,Try阶段会去扣库存,Confirm阶段则是去更新订单状态,如果更新订单失败,则进入Cancel阶段,会去恢复库存。总之,TCC就是通过代码人为实现了两阶段提交,不同的业务场景所写的代码都不一样,复杂度也不一样,因此,这种模式并不能很好地被复用。
3、如何实现负载均衡,有哪些算法可以实现?
经常会用到以下四种算法:随机(random)、轮训(round-robin)、一致哈希(consistent-hash)和主备(master-slave)。
4、分布式集群下如何做到唯一序列号
Redis生成ID 这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
5. 什么是进程
进程是指运行中的应用程序,每个进程都有自己独立的地址空间(内存空间)。
比如用户点击桌面的IE浏览器,就启动了一个进程,操作系统就会为该进程分配独立的地址空间。当用户再次点击左边的IE浏览器,又启动了一个进程,操作系统将为新的进程分配新的独立的地址空间。目前操作系统都支持多进程。
6. 什么是线程
进程是表示自愿分配的基本单位。而线程则是进程中执行运算的最小单位,即执行处理机调度的基本单位。通俗来讲:一个程序有一个进程,而一个进程可以有多个线程。
7. 线程和进程有什么区别
线程是进程的子集,一个进程可以有很多线程,每条线程并行执行不同的任务。不同的进程使用不同的内存空间,而所有的线程共享一片相同的内存空间。
8. 多线程的几种实现方式
(1) 继承Thread类创建线程
Thread类本质上是实现了Runnable接口的一个实例,代表一个线程的实例。启动线程的唯一方法就是通过Thread类的start()实例方法。start()方法将启动一个新线程,并执行run()方法。这种方式实现多线程比较简单,通过自己的类直接继承Thread,并重写run()方法,就可以启动新线程并执行自己定义的run()方法。
(2) 实现Runnable接口创建线程
如果自己的类已经继承了两一个类,就无法再继承Thread,因此可以实现一个Runnable接口
(3) 实现Callable接口通过FutureTask包装器来创建Thread线程
(4) 使用ExecutorService、Callable、Future实现有返回结果的线程
ExecutorService、Callable、Future三个接口实际上都是属于Executor框架。返回结果的线程是在JDK1.5中引入的新特征,有了这种特征就不需要再为了得到返回值而大费周折了。
可返回值的任务必须实现Callable接口;无返回值的任务必须实现Runnabel接口。
执行Callable任务后,可以获取一个Future对象,在该对象上调用get()方法就可以获取到Callable任务返回的Object了。(get()方法是阻塞的,线程无返回结果,该方法就一直等待)
9. 多线程中忙循环是什么
忙循环就是程序员用循环让一个线程等待,不像传统方法wait()、sleep()或者yied()它们都放弃了CPU控制,而忙循环不会放弃CPU,它就是在运行一个空循环。这么做的目的是为了保留CPU缓存,在多核系统中,一个等待线程醒来的时候可能会在另一个内核运行,这样会重建缓存。为了避免重建缓存和减少等待重建的时间就可以使用它了。
10. 什么是java内存模型
java内存模型定义了java虚拟机在计算机内存中的工作方式。JMM决定了一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存中,每一个线程都有一个私有的本地内存,本地内存中存储了该线程以读/写共享变量的副本。
11. 为什么要用线程池?
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
这里借用《Java并发编程的艺术》提到的来说一下使用线程池的好处:
降低资源消耗。 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
提高响应速度。 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性。 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
12、什么是乐观锁和悲观锁
1)乐观锁:就像它的名字一样,对于并发间操作产生的线程安全问题持乐观状态,乐观锁认为竞争不总是会发生,因此它不需要持有锁,将比较-替换这两个动作作为一个原子操作尝试去修改内存中的变量,如果失败则表示发生冲突,那么就应该有相应的重试逻辑。
2)悲观锁:还是像它的名字一样,对于并发间操作产生的线程安全问题持悲观状态,悲观锁认为竞争总是会发生,因此每次对某资源进行操作时,都会持有一个独占的锁,就像synchronized,不管三七二十一,直接上了锁就操作资源了。
13、高并发、任务执行时间短的业务怎样使用线程池?并发不高、任务执行时间长的业务怎样使用线程池?并发高、业务执行时间长的业务怎样使用线程池?
1)高并发、任务执行时间短的业务,线程池线程数可以设置为CPU核数+1,减少线程上下文的切换
2)并发不高、任务执行时间长的业务要区分开看:
a)假如是业务时间长集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占用CPU,所以不要让所有的CPU闲下来,可以加大线程池中的线程数目,让CPU处理更多的业务
b)假如是业务时间长集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(1)一样吧,线程池中的线程数设置得少一些,减少线程上下文的切换
c) high concurrency, long-time business execution, the key to solving this type of task is not to thread pool but in the overall architecture design, to see whether they can do business inside some of the data cache is the first step, the second is to increase server step, as setting the thread pool, thread pool to set a reference to other relevant articles. Finally, a long time business execution problems, may also need to analyze it, see if you can use the middleware to split tasks and decoupling.
Welcome to share with everyone, like articles like this one point to remember, thanks for the support!