New Year approached, apart from anything else, give you a big brother in the first thanks to a

recently next to IOS students leave at home Hey hey hey, the sun and I all alone, shivering in the corner, although the company's air conditioner to 28 ℃, I still can not melt the ice heart of

Here you may ask your company to two people?
Ha ha ha ha, who'd much, but for the topic of the opening of Chanel, Ferrari closed, I really can not get embarrassed.

Nothing else, a lonely little sisters of the Internet to see dance. Suddenly, one-hour long years have been like hands clutching the sand, silent loss, but lonely but as maggots tarsal bones, still stubborn lingering around the I's.
How to do it? Loneliness is not possible alone, only write BUG , ah bah, write code to maintain this way of life.
Today to talk about those things Python Download Video
Download Video Well, nothing more than file I / O.

python download video files three-step : get the video url, request link for streaming video, write to the local file is saved
to write a demo:
import requests
print("开始下载")
url = 'https://vdept.bdstatic.com/65796c493957364e51574e65504b757a/474c6d4464633277/37715aae880a70427da12d5d682d3a534b3947470869ecc29530cc310a944c1ac684c3ab83e07d18f65784748120987a.mp4?auth_key=1578908333-0-0-a70ed19862afa01935265e5a32906867'
r = requests.get(url, stream=True)
with open('test.mp4', "wb") as mp4:
for chunk in r.iter_content(chunk_size=1024 * 1024):
if chunk:
mp4.write(chunk)
print("下载结束")
点击运行,等待一会儿
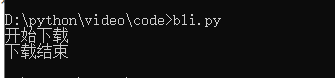
然后点击打开保存的mp4文件,就可以愉快的看小姐姐跳舞了。
(当然,这段代码也适用于大多数有色网站)

呵,朕真是个天才

正当我准备掏空B站的时候,发现B站的视频链接要么复制出来就403,要么异于常人
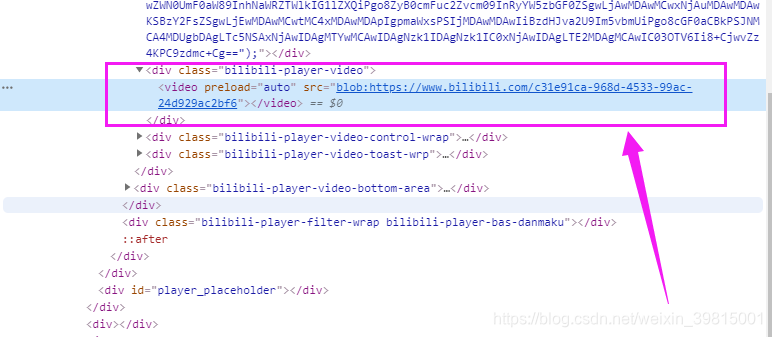
我一惊,此时必有蹊跷。
把这个链接复制出来一访问,呵,事情果然没有这么简单

这是为什么,难道是B站混入了奸细?我赶紧打开腾讯视频,爱奇艺看了一下,发现都存在这种情况。

最后发现链接前面的blob有点面生,google了一圈,得出结论:Blob URL / Object URL是一种伪协议,允许Blob和File对象用作图像,下载二进制数据链接等的URL源。生产场景往往是对切片格式的视频 m3u8 地址进行 blob 格式处理,其实并不是为了加密,因为浏览器还是会解析 blob 并去 get 请求对应的 m3u8 地址,使用 blob uri 的好处在于可以在一定层度上干扰爬虫。
简单的说,就是不能F12直接拿到视频的真实地址了

python下载视频文件三步骤,第一步就卡死了。这时,我发现一个叫you-get的东西好像挺受网友欢迎的,秉持 ‘大家好才是真的好’ 的理念查了查它的 git地址。哟,star还挺多
抱着试一试的心态阅读了you-get的文档,发现简单的令人发指
第一步,安装you-get,命令:pip3 install you-get,正常情况下,这样就已经安装好了,如果出现特殊情况,请查阅官方文档:https://github.com/soimort/you-get/wiki/%E4%B8%AD%E6%96%87%E8%AF%B4%E6%98%8E
使用起来也非常简单,以B站小姐姐跳舞视频为例:
链接:https://www.bilibili.com/video/av82238119?spm_id_from=333.5.b_64616e63655f73746172.3
页面大概是这样:
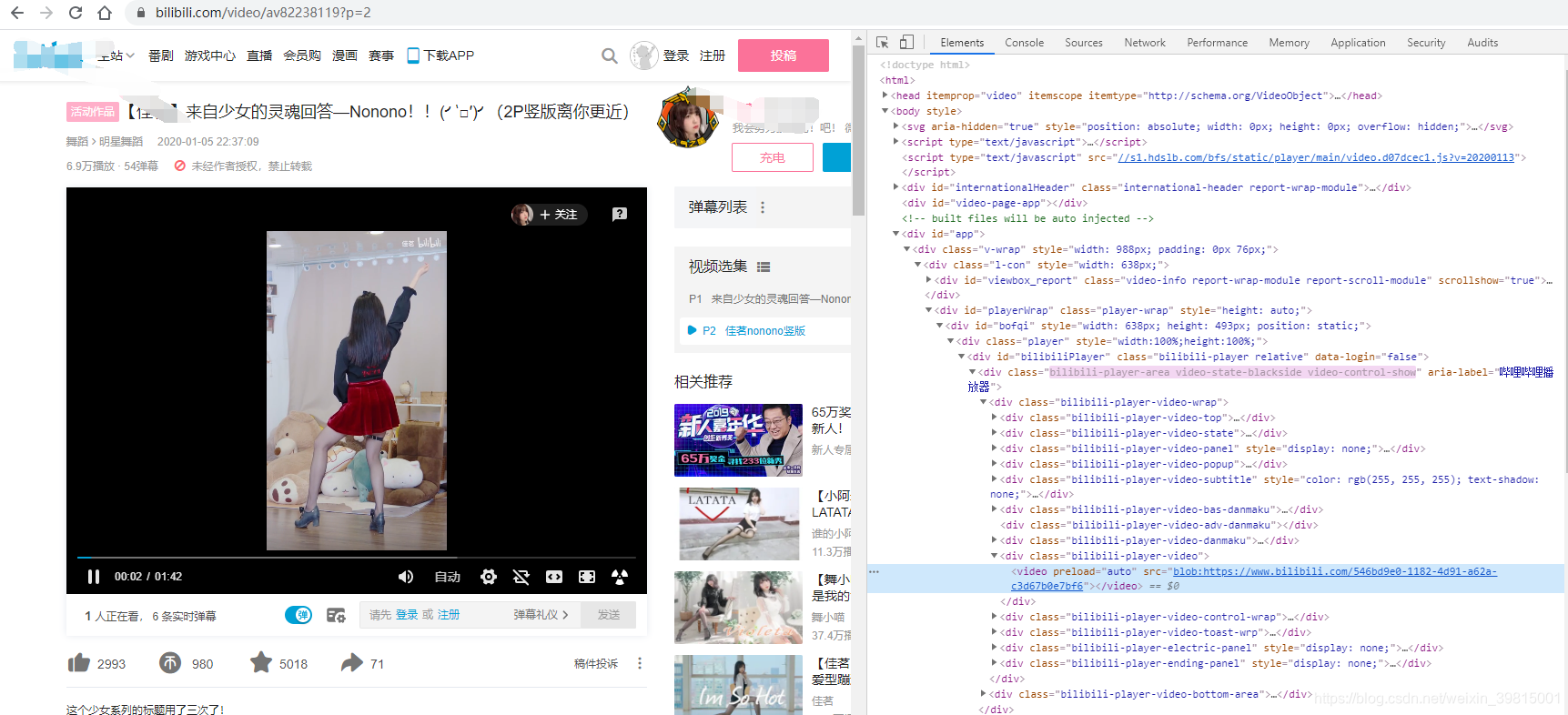
要保存这个舞蹈视频,只需要python命令行输入命令:
you-get -o D:\python\video https://www.bilibili.com/video/av82238119?spm_id_from=333.5.b_64616e63655f73746172.3
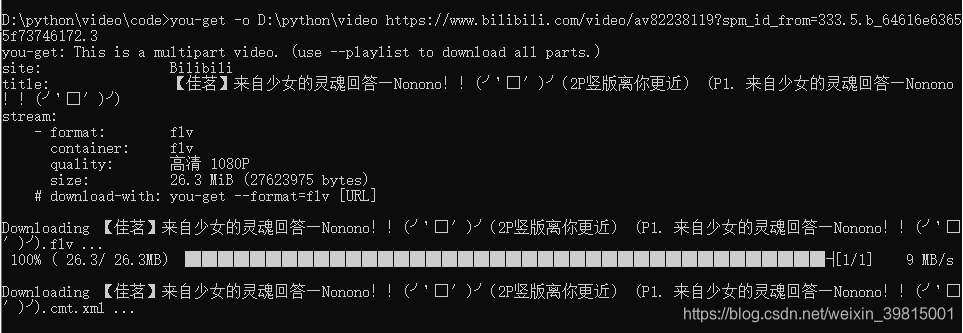
等待进度条完成,你就可以在目录 D:\python\video下找到你的小姐姐,就连弹幕也没有放过(xml文件保存该视频弹幕,另外一个是视频文件)
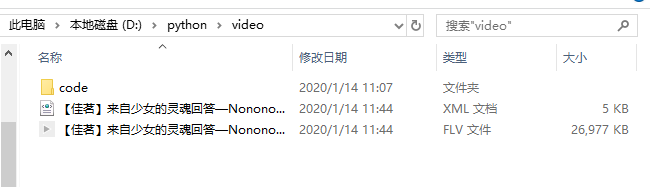
当然你也可以保存在你的隐藏文件夹或者学习资料目录下【you-get还有很多有趣的命令,支持国内外很多大型视频网站,如B站,优酷等,具体可查阅官方文档】

当然,这种半自动的方式必然不能够满足朕旺盛的精力,这种方式的话,搬空B站得到何年何月啊。

想了想,还是写个python文件吧。那么问题来了,python文件里怎么调用you-get呢?
示例:
from you_get import common
common.any_download(url='https://www.bilibili.com/video/av82238119?spm_id_from=333.5.b_64616e63655f73746172.3',info_only=False,output_dir=r'D:\python\video',merge=True)
试运行一下,嘿嘿嘿,居然跑起来了,接下来的事情就好办了,比如我要B站小姐姐跳舞视频,示例步骤如下:
第一步:找到B站跳舞板块url
第二部:拿到页面,解析出每一个视频页面url
第三部:使用 you-get 获取视频
说搞就搞,只见朕以行云流水、水底捞月、月朗星稀之势,一气呵成的完成了第一版
运行一下,呵,啥也没有
经过一番调试发现,B站的视频列表是通过接口异步加载的,打开F12可以看到,也可以复制Xpath路径,但是直接请求页面是拿不到数据的。接口如下,返回数据格式是json,其中的arcurl就是咱们需要的视频播放页面url
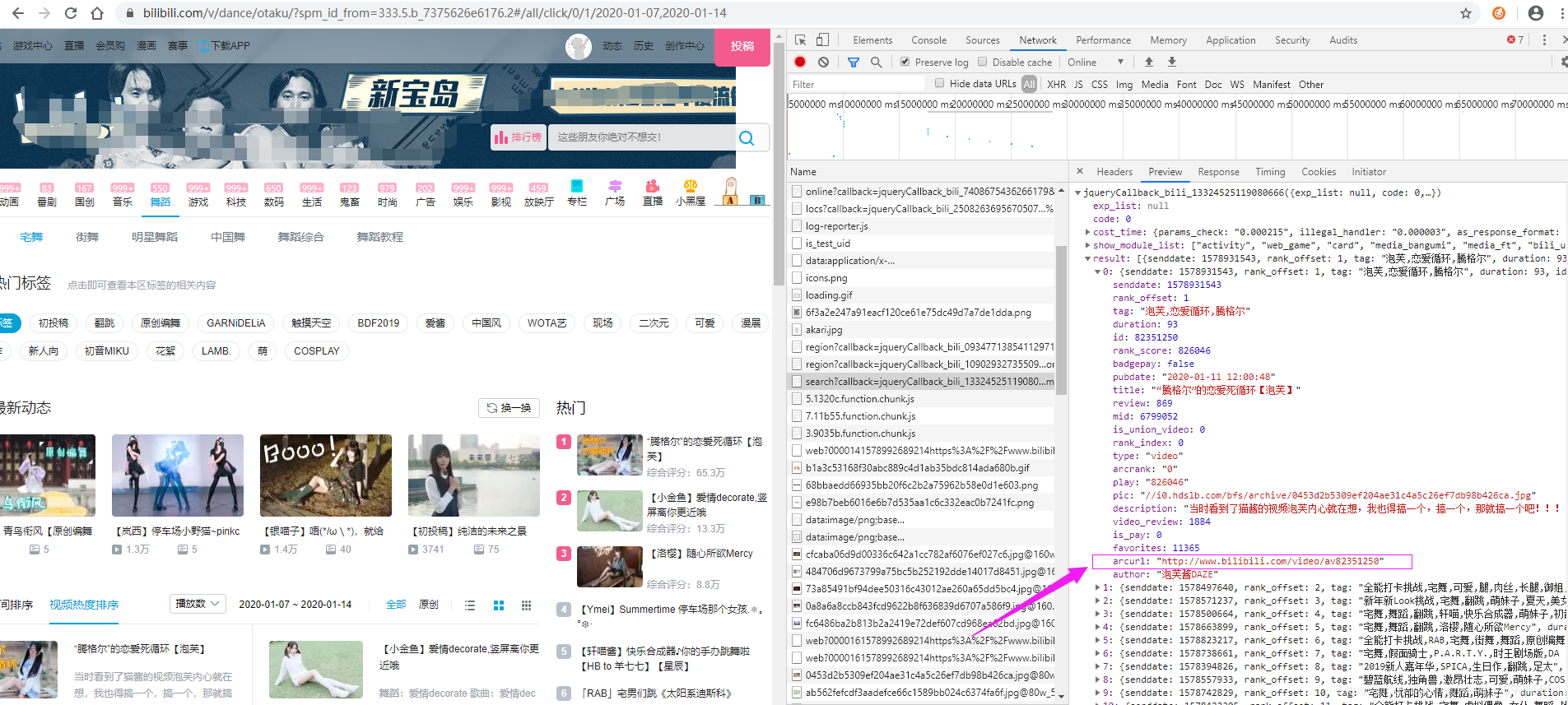
明白了这些之后就好办了,先试试宅舞板块,视频热度排第一页的舞蹈拿下来欣赏一下,代码如下:
import requests
import random
import json
from you_get import common
#常用请求代理
header_list = [
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"}
]
# 主函数
if __name__ == "__main__":
base_url = 'https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank&order=click©_right=-1&cate_id=20&page=1&pagesize=20&jsonp=jsonp&time_from=20200107&time_to=20200114&_=1578992689153'
headers = random.choice(header_list)
# 获取页面信息
response = requests.get(url=base_url, headers=headers)
# 获取请求状态码
code = response.status_code
if code == 200:
urls_json = json.loads(response.content)
for i in urls_json['result']:
print(i['arcurl'])
common.any_download(url=i['arcurl'],info_only=False,output_dir=r'D:\python\video',merge=True)
print('the end!')
运行文件,得如下结果:
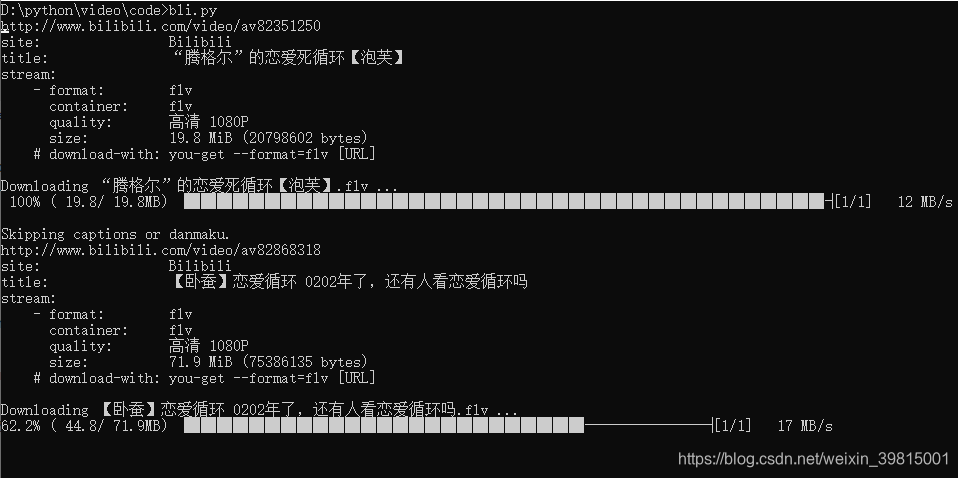
打开保存目录看看:
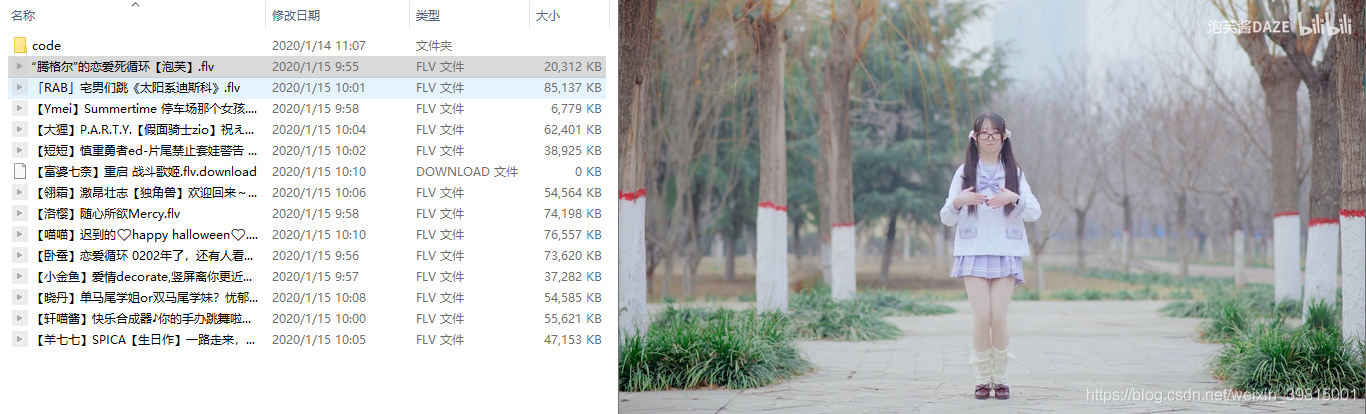
哟西,这谁顶得住啊

本着能搞它一页宅舞,就能掏空它的原则。分析分析接口规律,简单封装几个方法:
import queue
import requests
import re
import random
import time
import os
import json
from you_get import common
#常用请求代理
header_list = [
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"}
]
#获取视频播放页url
def get_urls(base_url,start_page_num,queue):
while True:
#生成请求代理信息
headers = random.choice(header_list)
#组装接口url
page_url = base_url + str(start_page_num)
# 获取页面信息
response = requests.get(url=page_url, headers=headers)
# 获取请求状态码
code = response.status_code
if code == 200:
urls_json = json.loads(response.content)
if urls_json['result']:
for i in urls_json['result']:
queue.put(i['arcurl'])
print(i['arcurl'])
else:
break
start_page_num += 1
print('Get url done!')
#下载视频并保存
def get_vedio(save_dir,queue):
while not queue.empty():
#休息一下,wo也不知道太快会发生什么
#time_num = 5
#time.sleep(time_num)
# Queue队列的get方法用于从队列中提取元素
vedio_page_url = queue.get()
queue.task_done()
common.any_download(url=vedio_page_url,info_only=False,output_dir=save_dir,merge=True)
# 主函数
if __name__ == "__main__":
# 小说章节基地址
base_url = 'https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank&order=click©_right=-1&cate_id=20&pagesize=20&jsonp=jsonp&time_from=20200107&time_to=20200114&_=1578992689153&page='
#从第几页开始
start_page_num = 1
#视频保存目录,请将目录写在引号里面,第一个r不能省略
save_dir = r'D:\python\video'
# 用Queue构造一个先进先出队列
video_urls_queue = queue.Queue()
#获取视频播放页url
get_urls(base_url,start_page_num,video_urls_queue)
#下载视频并保存
get_vedio(save_dir,video_urls_queue)
print('the end!')
看着自己的 ‘ 学习文件盘 ’ 慢慢被充满,露出了猥琐帅气的笑容 。。。。
心想,B站之流也不过如此

呵呵
The end!
人最大的对手,往往不是别人,而是自己的懒惰。
别指望撞大运,运气不可能永远在你身上,任何时候都要靠本事吃饭。
你必须拼尽全力,才有资格说自己的运气不好。
